
すべてのラップトップと電話にカメラが搭載されたため、tensoflowモデルを使用して頭と目の位置を分析できます。また、SIGGRAPH 2020に関する新しい記事では、写真測量を使用したデータセットを視差効果に便利にする方法について説明しています。
おそらくニューラルネットワーク用のTensorflowライブラリがあり、PythonおよびJavaScript言語で動作することを誰もが知っています。ニューラルネットワークの畳み込みプロセスはかなり並列化されたかなり重い計算であり、CPUだけでなくPython用のCUDAやJavaScript用のWebGL / WebGPUにもバージョンがあります。おもしろいですが、NVidiaがない場合、OpenGLをサポートする公式ビルドがないため、Javascript言語でのTensorflowの公式ビルドはPCでより速く動作します。幸運なことに、TF 2.0にはモジュール式のアーキテクチャーが備わっているので、本質的なことだけを考え、それを実行する言語について考えることはできません。コンバーター1.0-> 2.0もあります。
現在、公式の顔認識モデルには、facemeshとblazefaceの2つがあります。 1つ目は顔の表情やマスクに適しており、2つ目はより速く、目や耳、口などの四角形や特徴的な点を簡単に決定します。したがって、私は軽量版-blazefaceを採用しました。なぜ不要な情報なのか?一般に、既存のモデルをさらに縮小することは可能かもしれません。目の位置に加えて、他には何も必要ないからです。
現在、ブラウザーには5つのバックエンド(cpu、wasm、webgl、wasm-simd、webgpu)があります。最初のCPUは遅すぎるため、今のところ使用すべきではありません。最後の2つは革新的であり、提案の段階にあり、フラグの下で機能しているため、エンドカスタマーのサポートはありません。したがって、私はWebGLとWASMの2つから選択しました。
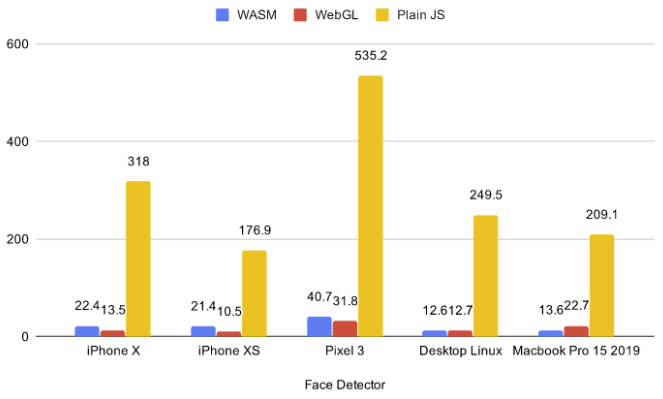
既存のベンチマークから、小規模モデルの場合、WASMがWebGLよりも高速に動作する場合があることがわかります。さらに、視差は3Dシーンで使用でき、WASMバックエンドをそれらで実行することで、個別のラップトップビデオカードがニューラルネットワークと3Dシーンを同時にエクスポートしないため、WASMがより適切に機能することに気付きました。これを行うために、.glbに75のチャプターがある簡単なシーンを撮りました。リンクはクリック可能で、WASMがあります。

リンクをたどった場合、ブラウザがビデオカメラへのアクセス許可を要求したことにおそらく気づいたでしょう。問題は、ユーザーが「いいえ」をクリックするとどうなるかです。この場合は何もロードせず、フォールバックしてマウス/ジャイロを制御することをお勧めします。ESMバージョンのtfjs-coreとtfjs-converterが見つからなかったため、動的インポートの代わりに、モジュールが読み込まれる順序が重要であるfetchInjectライブラリを使用して、かなり不気味な構造に落ち着きました。
クリープ構造
, (Promise.All), , , .
fetchInject([
'https://cdn.jsdelivr.net/npm/@tensorflow-models/blazeface@0.0.5/dist/blazeface.min.js'
], fetchInject([
'https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-converter@2.0.1/dist/tf-converter.min.js',
'https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-backend-wasm@2.0.1/dist/tfjs-backend-wasm.wasm'
], fetchInject([
'https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-core@2.0.1/dist/tf-core.min.js'
]))).then(() => {
tf.wasm.setWasmPath('https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-backend-wasm@2.0.1/dist/tf-backend-wasm.min.js');
//some other code
}
視線の位置を見つけるために、私は2つの目の間の平均を取ります。また、三角形の辺が類似しているため、頭までの距離がビデオの目と目の距離に比例することは容易に理解できます。モデルから取得した目の位置のデータは非常にノイズが多いため、計算を行う前に、EMA(指数移動平均)を使用して平滑化しました。
pos = (1 - smooth) * pos + smooth * nextPos;
または別の方法で書く:
pos *= 1 - smooth;
pos += nextPos * smooth;
したがって、カメラの中心を持つ特定の球面座標系での座標x、y、zを取得します。さらに、xとyはカメラの画角によって制限され、zは頭から頭までのおおよその距離です。小さな回転角度でしたがって、xとyは角度として解釈できます。
pushUpdate({
x: (eyes[0] + eyes[2]) / video.width - 1,
y: 1 - (eyes[1] + eyes[3]) / video.width,
z: defautDist / dist
});
写真測量
出版物SIGGRAPH 2020から設定されたかなりおもしろい日付。レイヤードメッシュ表現を使用した没入型ライトフィールドビデオ。彼らは、カメラを特定の範囲で動かすために特別に写真を作りましたが、これは視差のアイデアに理想的に適合しています。視差の例。

ここでは3Dシーンがレイヤーで作成され、テクスチャが各レイヤーに適用されます。彼らが写真測量を作成した装置は、同じくらい面白そうです。彼らはそれぞれ10kルーブルの47台の安価なYi 4Kアクションカメラを購入し、三角形のグリッドが3倍になった二十面体の形をした半球に配置しました。その後、全員を三脚の上に置き、カメラを同期させて撮影しました。
