
では最初の部分、私はシミュレータは、一般的にあるものについて、同様のシミュレーションレベルについて話しました。ここで、その知識に基づいて、少し深く掘り下げて、フルプラットフォームシミュレーション、トラックの組み立て方法、後でどうするか、時計回りのマイクロアーキテクチャエミュレーションについてお話します。
完全なプラットフォームシミュレータ、または「現場の1人は戦士ではない」
ネットワークカードなどの特定のデバイスの動作を調査したり、このデバイスのファームウェアやドライバを作成したりする必要がある場合は、そのようなデバイスを個別にモデル化できます。ただし、他のインフラストラクチャから分離して使用することは、あまり便利ではありません。対応するドライバを起動するには、中央処理装置、メモリ、データ転送のためのバスへのアクセスなどが必要です。さらに、ドライバーにはオペレーティングシステム(OS)とネットワークスタックが必要です。さらに、別個のパケットジェネレーターと応答サーバーが必要になる場合があります。
完全なプラットフォームシミュレーターは、BIOSやブートローダーからOS自体、および同じネットワークスタック、ドライバー、ユーザーレベルのアプリケーションなどのさまざまなサブシステムまで、すべてを含む完全なソフトウェアスタックを実行するための環境を作成します。これを行うには、ほとんどのコンピューターデバイス(プロセッサとメモリ、ディスク、入出力デバイス(キーボード、マウス、ディスプレイ)、および同じネットワークカード)のソフトウェアモデルを実装します。
以下は、Intel x58チップセットのブロック図です。このチップセットのフルプラットフォームコンピューターシミュレーターでは、IOH(入力/出力ハブ)およびICH(入力/出力コントローラーハブ)内にあるものを含め、リストされているほとんどのデバイスを実装する必要があります。これらは、ブロック図には詳しく描かれていません。しかし、実際に示しているように、ソフトウェアで使用されないデバイスの数は少なくありません。そのようなデバイスのモデルを作成する必要はありません。

ほとんどの場合、フルプラットフォームシミュレータはプロセッサの命令レベルで実装されます(ISA、前の記事を参照))。これにより、シミュレータ自体を比較的迅速かつ安価に作成できます。ISAレベルは、たとえば、API / ABIレベルが頻繁に変更されるのとは異なり、多かれ少なかれ一定のままであるため、優れています。さらに、命令レベルでの実装により、いわゆる変更されていないバイナリソフトウェアを実行できます。つまり、実際のハードウェアで使用されているとおりに、変更なしでコンパイル済みのコードを実行できます。つまり、ハードドライブのコピー(「ダンプ」)を作成し、それをフルプラットフォームシミュレーターのモデルのイメージとして指定して、できあがりです。-OSやその他のプログラムは、追加のアクションなしでシミュレータにロードされます。
シミュレーターのパフォーマンス

上記のように、システム全体、つまりそのすべてのデバイスをシミュレートするプロセスそのものは、かなり遅い作業です。これらすべてを非常に詳細なレベル(たとえば、マイクロアーキテクチャーまたは論理)で実装すると、実装が非常に遅くなります。しかし、命令のレベルは適切な選択であり、OSとプログラムをユーザーが快適に操作するのに十分な速度で実行できるようにします。
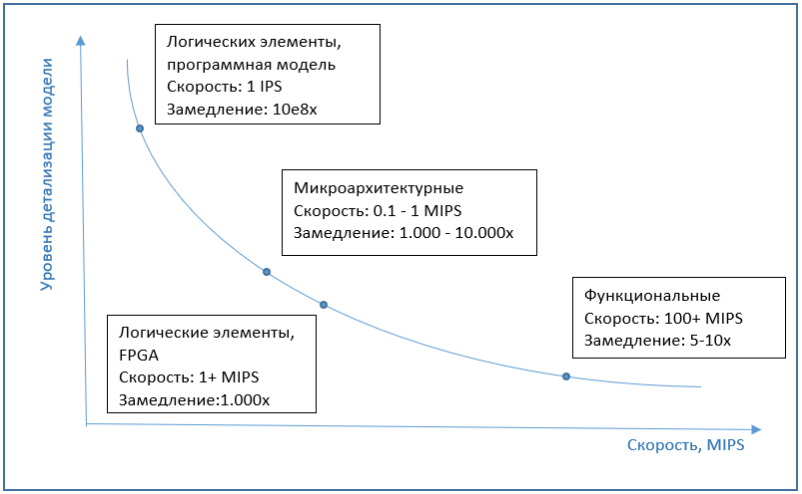
ここでは、シミュレーターのパフォーマンスのトピックに触れるだけで適切です。通常、IPS(1秒あたりの命令数)、より正確にはMIPS(数百万IPS)で測定されます。つまり、1秒あたりにシミュレーターによって実行されるプロセッサ命令の数です。同時に、シミュレーション速度は、シミュレーション自体が実行されているシステムのパフォーマンスにも依存します。したがって、元のシステムと比較して、シミュレータの「スローダウン」について話す方が正しいかもしれません。
QEMU、VirtualBox、VmWare Workstationなど、市場で最も一般的なフルプラットフォームシミュレータは優れたパフォーマンスを発揮します。シミュレーターで作業が行われていることがユーザーに気付かれない場合もあります。これは、プロセッサに実装された特別な仮想化機能、バイナリ変換アルゴリズム、その他の興味深いことに起因しています。これは別の記事のすべてのトピックですが、要するに仮想化は最新のプロセッサのハードウェア機能であり、シミュレータが命令をシミュレートするのではなく、実際のプロセッサに直接送信して実行できます(もちろん、シミュレータとプロセッサのアーキテクチャが類似している場合)。バイナリ変換は、ゲストマシンコードをホストコードに変換し、その後、実際のプロセッサで実行することです。結果として、シミュレーションは5〜10回ごとにわずかに遅くなります。通常、実際のシステムと同じ速度で動作します。これは多くの要因に影響されますが。たとえば、数十のプロセッサを搭載したシステムをシミュレートしたい場合、速度はすぐに数十倍低下します。一方、最近のバージョンのSimicsなどのシミュレータは、マルチプロセッサホストハードウェアをサポートし、シミュレートされたコアを実際のプロセッサコアに効率的に並列化します。最近のバージョンでは、Simicsなどのシミュレータはマルチプロセッサホストハードウェアをサポートし、シミュレーションされたコアを実際のプロセッサのコアに効果的に並列化します。最近のバージョンのSimicsのようなシミュレータは、マルチプロセッサホストハードウェアをサポートし、シミュレートされたコアを実際のプロセッサコアに効率的に並列化します。
マイクロアーキテクチャシミュレーションの速度について説明すると、通常、シミュレーションを行わない通常のコンピュータでの実行よりも数桁、約1000〜10000倍遅くなります。また、論理要素のレベルでの実装は、数桁も遅くなります。したがって、FPGAはこのレベルでエミュレータとして使用され、パフォーマンスを大幅に向上させることができます。
以下のグラフは、シミュレーション速度のモデルの詳細に対するおおよその依存関係を示しています。
クロックバイサイクルシミュレーション
実行速度は遅いですが、マイクロアーキテクチャシミュレータは一般的です。各命令の実行時間を正確にシミュレートするには、プロセッサの内部ブロックのモデリングが必要です。これは誤解を招く可能性があります-思われるので、なぜ各命令の実行時間を拾い上げてプログラムしないのですか?ただし、同じ命令の実行時間は呼び出しごとに異なる場合があるため、このようなシミュレータは非常に不正確に機能します。
最も単純な例は、メモリアクセス命令です。要求されたメモリの場所がキャッシュで利用可能な場合、実行時間は最小限になります。キャッシュにそのような情報がない場合(「キャッシュミス」、キャッシュミス)、これにより命令の実行時間が大幅に増加します。したがって、正確なシミュレーションにはキャッシュモデルが必要です。ただし、キャッシュモデルはこれに限定されません。プロセッサは、データがキャッシュにない場合、メモリからデータが受信されるのを待つだけではありません。代わりに、次の命令の実行を開始し、メモリからの読み取り結果に依存しないものを選択します。これは、プロセッサのダウンタイムを最小限に抑えるために必要な、いわゆるアウトオブオーダー実行(OOO)です。対応するプロセッサブロックのシミュレーションは、命令の実行時間を計算するときにこれをすべて考慮するのに役立ちます。実行されているこれらの命令の中で、メモリからの読み取り結果を待っている間に、条件付き分岐操作が発生する場合があります。現時点で条件を満たした結果が不明の場合、プロセッサは実行を停止せず、「仮定」を行い、対応する遷移を実行し、遷移の場所から命令を先制的に実行し続けます。分岐予測子と呼ばれるこのようなブロックは、マイクロアーキテクチャシミュレータにも実装する必要があります。
以下の図は、プロセッサの主要ブロックを示しています。知る必要はありません。マイクロアーキテクチャの実装の複雑さを示すためにのみ示しています。
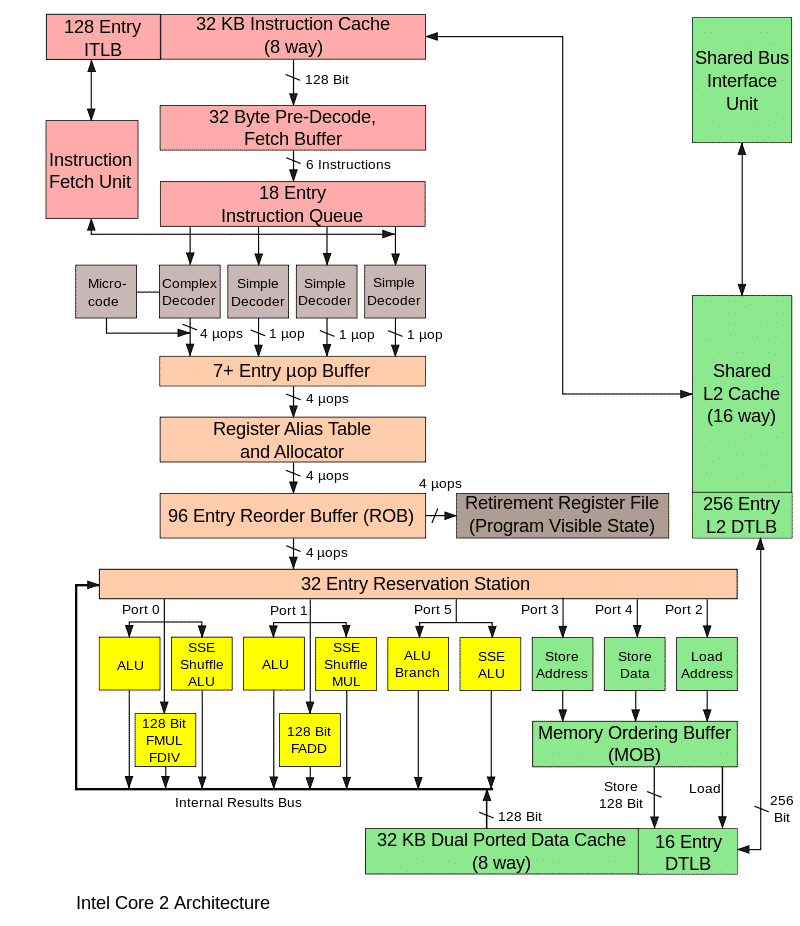
実際のプロセッサでのこれらすべてのユニットの動作は、モデルでも同様に発生する特別なクロック信号によって同期されます。このようなマイクロアーキテクチャシミュレータは、サイクルアキュレートと呼ばれます。その主な目的は、開発中のプロセッサーのパフォーマンスを正確に予測したり、特定のプログラム(ベンチマークなど)の実行時間を計算したりすることです。値が必要よりも低い場合は、アルゴリズムとプロセッサブロックを調整するか、プログラムを最適化する必要があります。
上記のように、サイクルごとのシミュレーションは非常に遅いため、プログラムの実行の実際の速度を見つけて、プロトタイプがシミュレーションされるデバイスの将来のパフォーマンスを推定する必要があるプログラムの動作の特定のポイントを調べる場合にのみ使用されます。
同時に、機能シミュレーターを使用して、プログラムの残りの時間をシミュレートします。この組み合わせ使用は実際にどのように発生しますか?まず、機能シミュレーターが起動し、OSと調査中のプログラムを実行するために必要なすべてがロードされます。結局のところ、OS自体や、プログラムの起動の初期段階、その構成などには興味がありません。ただし、これらの部分をスキップして、プログラムの実行を途中から直接実行することもできません。したがって、これらの準備手順はすべて、機能シミュレーターで実行されます。プログラムが私たちの興味のある瞬間まで実行された後、2つの可能なオプションがあります。モデルをサイクルごとに置き換えて、実行を続けることができます。実行可能コードが使用されるシミュレーションモード(つまり、通常のコンパイル済みプログラムファイル)、実行駆動シミュレーションと呼ばれます。これは最も一般的なシミュレーションオプションです。別のアプローチも可能です-トレース駆動シミュレーション。
トレースベースのシミュレーション
2つのステップがあります。機能シミュレーターまたは実際のシステムを使用して、プログラムアクションログが収集され、ファイルに書き込まれます。このようなログはトレースと呼ばれます。調査対象に応じて、実行可能な命令、メモリアドレス、ポート番号、割り込みに関する情報をトレースに含めることができます。
次のステップは、サイクルごとのシミュレーターがトレースを読み取り、そこに書き込まれているすべての命令を実行するときに、トレースを「再生」することです。最後に、特定のプログラムの実行時間と、このプロセスのさまざまな特性(キャッシュヒットの割合など)を取得します。
トラックを操作する重要な機能は決定論です。つまり、前述のようにシミュレーションを開始することにより、同じアクションのシーケンスを繰り返し再現します。これにより、モデルのパラメーター(キャッシュ、バッファー、およびキューのサイズ)を変更し、さまざまな内部アルゴリズムを使用するか、それらを調整することにより、特定のパラメーターがシステムパフォーマンスにどのように影響し、どのオプションが最良の結果をもたらすかを調査できます。これはすべて、実際のハードウェアプロトタイプを作成する前に、プロトタイプデバイスモデルで実行できます。
このアプローチの複雑さは、アプリケーションを事前に実行してトレースを収集する必要があることと、トレースに伴う巨大なファイルサイズにあります。プラスには、対象のデバイスまたはプラットフォームの一部のみをシミュレーションするだけで十分であるという事実が含まれますが、実行シミュレーションには通常、完全なモデルが必要です。
そこで、この記事では、フルプラットフォームシミュレーションの機能を検証し、さまざまなレベルでの実装速度、ビートシミュレーション、トレースについて説明しました。次の記事では、個人的な目的と大企業での開発の両方の目的で、シミュレーターを使用するための主なシナリオについて説明します。