
Kubernetesを使用する場合、クラウドコストをどのように節約できますか?唯一の正しいソリューションは存在しませんが、この記事では、リソースをより効率的に管理し、クラウドコンピューティングのコストを削減するのに役立ついくつかのツールについて説明します。
この記事はAWSのKubernetesに焦点を当てて作成しましたが、他のクラウドプロバイダーにも(ほぼ)同じように適用されます。私のクラスターにはすでに自動スケーリングが構成されていると想定しています(cluster-autoscaler)。リソースを削除してデプロイメントをスケールダウンすることで節約できるのは、ワーカーノード(EC2インスタンス)の数も削減される場合のみです。
この記事では以下について説明します。
- 未使用のリソースのクリーンアップ(kube-janitor)
- 営業時間外のダウンスケーリング(kube-downscaler)
- 水平自動スケーリング(HPA)の使用、
- リソースのオーバーブッキングの削減(kube-resource-report、VPA)
- スポットインスタンスを使用する
未使用のリソースをクリーンアップする
テンポの速い環境での作業は素晴らしいです。私たちは技術組織が加速することを望んでいます。より速いソフトウェア配信は、より多くのPR展開、プレビュー環境、プロトタイプ、および分析ソリューションも意味します。Kubernetesにデプロイ可能なすべてのもの。テスト展開を手動でクリーンアップする時間があるのは誰ですか?1週間前に実験を削除することを忘れがちです。私たちが閉鎖するのを忘れたという事実のため、クラウド法案は最終的に上昇します:

(Henning Jacobs:
Zhiza:(
引用)Corey Quinn:
神話:AWSアカウントはユーザー数の
関数です
。Fact :AWSアカウントはエンジニアの数の関数です。Ivan Kurnosov(応答で):
実際の事実: AWSアカウントは、無効化/削除を忘れたものの数に応じた機能です。)
Kubernetes Janitor(kube-janitor)は、クラスターのクリーンアップに役立ちます。用務員の構成は、グローバルとローカルの両方で柔軟に使用できます。
- クラスタ全体の一般的なルールは、PR /テスト展開の最大存続可能時間(TTL)を決定できます。
- 個々のリソースにjanitor / ttlで注釈を付けることができます。たとえば、7日後にスパイク/プロトタイプを自動的に削除します。
一般的なルールはYAMLファイルで定義されます。そのパスは、パラメーター
--rules-fileを介してkube-janitorに渡されます。-pr-2日間で名前に含まれるすべての名前空間を削除するためのルールの例を次に示します。
- id: cleanup-resources-from-pull-requests
resources:
- namespaces
jmespath: "contains(metadata.name, '-pr-')"
ttl: 2d次の例では、2020年のすべての新しいDeployment / StatefulSetのDeploymentおよびStatefulSetポッドでのアプリケーションラベルの使用を規制しますが、同時に、このラベルなしで1週間、テストを実行できます。
- id: require-application-label
# deployments statefulsets "application"
resources:
- deployments
- statefulsets
# . http://jmespath.org/specification.html
jmespath: "!(spec.template.metadata.labels.application) && metadata.creationTimestamp > '2020-01-01'"
ttl: 7dkube-janitorが実行されているクラスターで、時間制限付きのデモを30分間実行します。
kubectl run nginx-demo --image=nginx
kubectl annotate deploy nginx-demo janitor/ttl=30mコストが上昇するもう1つの原因は、永続的なボリューム(AWS EBS)です。Kubernetes StatefulSetを削除しても、永続ボリューム(PVC-PersistentVolumeClaim)は削除されません。未使用のEBSボリュームは、毎月数百ドルのコストにつながる可能性があります。Kubernetes Janitorには、未使用のPVCをクリーニングする機能があります。たとえば、このルールは、ポッドによってマウントされておらず、StatefulSetまたはCronJobによって参照されていないすべてのPVCを削除します。
# PVC, StatefulSets
- id: remove-unused-pvcs
resources:
- persistentvolumeclaims
jmespath: "_context.pvc_is_not_mounted && _context.pvc_is_not_referenced"
ttl: 24hKubernetes Janitorは、クラスターをクリーンな状態に保ち、クラウドコンピューティングの成長が遅いコストを防ぐのに役立ちます。デプロイと設定の手順については、kube-janitor READMEに従ってください。
営業時間外のスケーリングの削減
通常、テストシステムと中間システムは、勤務時間中にのみ機能する必要があります。バックオフィス/管理ツールなどの一部の本番アプリケーションでは、限られた可用性が必要であり、夜間に無効になる場合があります。
Kubernetesダウンスケーラー(kube - downscaler)を使用すると、ユーザーとオペレーターは営業時間外にシステムをダウンスケールできます。デプロイメントとStatefulSetは、ゼロレプリカまでスケーリングできます。 CronJobは一時停止されている可能性があります。 Kubernetes Downscalerは、クラスター全体、1つ以上の名前空間、または個々のリソースに対して構成できます。 「アイドル時間」または「稼働時間」のセットを設定できます。たとえば、夜間と週末にスケーリングを可能な限り減らすには:
image: hjacobs/kube-downscaler:20.4.3
args:
- --interval=30
#
- --exclude-namespaces=kube-system,infra
# kube-downscaler, Postgres Operator,
- --exclude-deployments=kube-downscaler,postgres-operator
- --default-uptime=Mon-Fri 08:00-20:00 Europe/Berlin
- --include-resources=deployments,statefulsets,stacks,cronjobs
- --deployment-time-annotation=deployment-time週末のクラスターワーカーノードのスケーリングのグラフを次に示します。ワーカーノードを

13から4にスケールダウンすると、AWSの請求額にかなりの違いが生じます。
しかし、クラスタが「アイドル」のときに作業する必要がある場合はどうなりますか?アノテーションdownscaler / exclude:trueを追加することで、特定のデプロイメントを永続的にスケーリングから除外できます。YYYY-MM-DD HH:MM(UTC)形式の絶対タイムスタンプを含むdownscaler / exclude-untilアノテーションを使用して、デプロイメントを一時的に除外できます。必要に応じて、
downscaler/force-uptimeたとえばnginxダミーを実行して、注釈付きのポッドをデプロイすることにより、クラスター全体を縮小できます。
kubectl run scale-up --image=nginx
kubectl annotate deploy scale-up janitor/ttl=1h #
kubectl annotate pod $(kubectl get pod -l run=scale-up -o jsonpath="{.items[0].metadata.name}") downscaler/force-uptime=trueデプロイ手順と追加オプション については、README kube-downscalerを参照してください。
水平自動スケーリングを使用する
多くのアプリケーション/サービスは動的なロードスキームを扱います。それらのモジュールはアイドル状態の場合もあれば、フル稼働で動作している場合もあります。最大のピーク負荷に対処するために一定の炉床で運転するのは経済的ではありません。 Kubernetesは、HorizontalPodAutoscaler(HPA)リソースによる水平自動スケーリングをサポートしています。多くの場合、CPU使用率はスケーリングに適した指標です。
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: my-app
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
averageUtilization: 100
type: UtilizationZalandoは、スケーリング用のカスタムメトリックを簡単に接続するためのコンポーネントを作成しました。Kube メトリックアダプター(kube-metrics-adapter)は、水平ハーススケーリング用のカスタムおよび外部メトリックを収集および維持できるKubernetesのユニバーサルメトリックアダプターです。 Prometheusメトリック、SQSキュー、その他のカスタマイズに基づくスケーリングをサポートします。たとえば、アプリケーション自体がJSON in /メトリックとして表すカスタムメトリックのデプロイメントをスケールアップするには、次を使用します。
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa
annotations:
# metric-config.<metricType>.<metricName>.<collectorName>/<configKey>
metric-config.pods.requests-per-second.json-path/json-key: "$.http_server.rps"
metric-config.pods.requests-per-second.json-path/path: /metrics
metric-config.pods.requests-per-second.json-path/port: "9090"
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicas: 1
maxReplicas: 10
metrics:
- type: Pods
pods:
metric:
name: requests-per-second
target:
averageValue: 1k
type: AverageValueHPAで水平自動スケーリングを設定することは、ステートレスサービスのパフォーマンスを向上させるためのデフォルトアクションの1つである必要があります。Spotifyには、HPAの経験とベストプラクティスが記載されたプレゼンテーションがあります。
リソースの冗長性を減らす
Kubernetesのワークロードは、「リソースリクエスト」を通じてCPU /メモリ要件を決定します。 CPUリソースは仮想コアで測定されるか、より頻繁には「ミリコア」で測定されます。たとえば、500mは50%のvCPUを意味します。メモリリソースはバイト単位で測定され、通常のサフィックスを使用できます。たとえば、500Miは500メガバイトを意味します。リソースリクエストはワーカーノードの容量を「ロック」します。つまり、4つのvCPUを持つノードで1000mのCPUリクエストを持つモジュールは、他のモジュールで使用できる3つのvCPUのみを残します。[1]
スラック(余剰)-これは、要求されたリソースと実際の使用の違いです。たとえば、2 GiBのメモリを要求するが200 MiBのみを使用するポッドには、約1.8 GiBの「過剰」なメモリがあります。過剰はお金がかかります。概して、1 GiBの過剰なメモリコストは、月あたり約10ドルと見積もることができます。[2]
Kubernetesリソースレポート(kube-resource-report)は過剰な予備を表示し、節約の可能性を特定するのに役立ちます:

Kubernetesリソースレポートアプリケーションおよびチームごとに集計された超過を示します。これにより、リソース要求を削減できる場所を見つけることができます。生成されたHTMLレポートは、リソースの使用状況のスナップショットのみを提供します。適切なリソースリクエストを判断するには、時間の経過に伴うCPU /メモリの使用状況を確認する必要があります。これは、「典型的な」高CPU使用率サービスのGrafanaダイアグラムです。すべてのポッドは
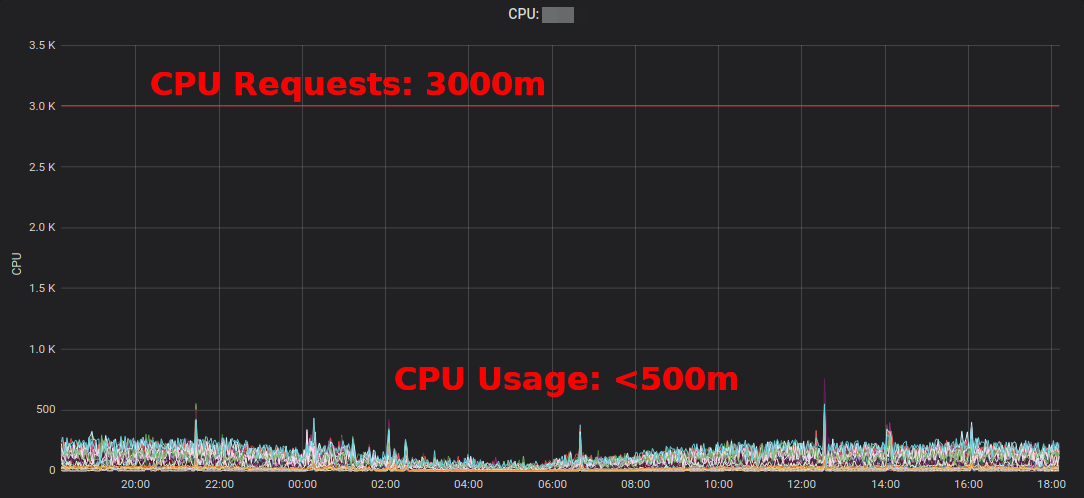
、要求された3 CPUコアよりも大幅に少ないCPU要求を使用しています。
「EC2インスタンスの平均CPU使用率は、多くの場合、1桁のパーセント範囲で変動します」とCorey Quinnは書いています。 EC2の場合、正しいサイズを見積もることは悪い決断になる可能性がありますYAMLファイル内の一部のKubernetesリソースリクエストを変更することは簡単で、大幅な節約が可能です。
しかし、本当にYAMLファイルの値を変更してほしいですか?いいえ、機械はそれをはるかにうまく行うことができます! Kubernetes 垂直ポッドオートスケーラー(VPA)はまさにそれを行います。ワークロードに合わせてリソースリクエストと制約を適応させます。これは、時間の経過とともにVPAによって適応されたPrometheus CPU(細い青い線)クエリグラフの例です

。Zalandoは、インフラストラクチャコンポーネントのすべてのクラスターでVPAを使用します。重要ではないアプリケーションでもVPAを使用できます。
ゴルディロックスby Fairwindは、ネームスペース内の各デプロイメントのVPAを作成し、ダッシュボードにVPA推奨を表示するツールです。これは、開発者がアプリケーションに正しいCPU /メモリリクエストを設定するのに役立ちます。2019年にVPAに関する

小さなブログ投稿を書きました。最近、CNCFエンドユーザーコミュニティでVPA についての議論がありました。
EC2スポットインスタンスの使用
最後に重要なことですが、AWS EC2のコストは、スポットインスタンスをKubernetesワーカーノードとして使用することで削減できます[3]。スポットインスタンスは、オンデマンドの価格と比較して最大90%の割引で利用できます。 EC2スポットでのKubernetesの実行は適切な組み合わせです。可用性を高めるにはいくつかの異なるインスタンスタイプを指定する必要があります。つまり、同じまたはより低い価格でより大きなノードを取得でき、コンテナ化されたKubernetesワークロードで増加した容量を使用できます。
EC2スポットでKubernetesを実行するにはどうすればよいですか?いくつかのオプションがあります。SpotInst(現在はSpotと呼ばれています。理由は聞かないでください)などのサードパーティのサービスを使用するか、クラスターにSpot AutoScalingGroup(ASG)を追加するだけです。たとえば、以下は、複数のインスタンスタイプを持つ「容量が最適化された」スポットASGのCloudFormationスニペットです。
MySpotAutoScalingGroup:
Properties:
HealthCheckGracePeriod: 300
HealthCheckType: EC2
MixedInstancesPolicy:
InstancesDistribution:
OnDemandPercentageAboveBaseCapacity: 0
SpotAllocationStrategy: capacity-optimized
LaunchTemplate:
LaunchTemplateSpecification:
LaunchTemplateId: !Ref LaunchTemplate
Version: !GetAtt LaunchTemplate.LatestVersionNumber
Overrides:
- InstanceType: "m4.2xlarge"
- InstanceType: "m4.4xlarge"
- InstanceType: "m5.2xlarge"
- InstanceType: "m5.4xlarge"
- InstanceType: "r4.2xlarge"
- InstanceType: "r4.4xlarge"
LaunchTemplate:
LaunchTemplateId: !Ref LaunchTemplate
Version: !GetAtt LaunchTemplate.LatestVersionNumber
MinSize: 0
MaxSize: 100
Tags:
- Key: k8s.io/cluster-autoscaler/node-template/label/aws.amazon.com/spot
PropagateAtLaunch: true
Value: "true"KubernetesでSpotを使用する際の注意事項:
- インスタンスの停止時にノードをドレインするなどして、スポット補完を処理する必要がある
- Zalando はノードプールの優先順位を使用して公式のクラスター自動スケーリングを分岐しました
- スポットノードは、スポットで実行するワークロードの「登録」を受け入れるように強制できます。
概要
ここで紹介するツールのいくつかが、クラウドコンピューティングの費用を削減するのに役立つことを願っています。ほとんどのコンテンツは、私のDevOps Gathering 2019 YouTubeトークとスライドにも掲載されています。
Kubernetesでクラウドコストを節約するためのベストプラクティスは何ですか?Twitter(@try_except_)でお知らせください。
[1]実際には、予約されたシステムリソースによってホストの帯域幅が減少するため、使用可能なvCPUは3つ未満になります。Kubernetesは、物理ノードの容量と「割り当てられた」リソース(ノードの割り当て可能)を区別します。
[2]計算例:8 GiBのメモリを搭載したm5.largeの1つのコピーは、1か月あたり〜84 USD(eu-central-1、オンデマンド)、つまり 1/8ノットのブロッキングは、月額約10ドルです。
[3]リザーブドインスタンス、貯蓄プランなど、EC2アカウントを削減する方法は他にもたくさんあります。ここではこれらのトピックについては説明しませんが、必ず確認してください。
コースの詳細をご覧ください。