前提条件
ページ分割されたテキスト内のフレーズを検索するタスクは、各ページの関連係数を計算し、係数の降順でリストをソートすることだけに削減されます。
基本的なアプローチに従って計算するプロセスでは、各ページがシンボルごとの分析にかけられ、最適化の可能性がそこにあります。

係数を計算するとき、検索文字列とデータの一致する文字のグループが分析されますが、グループは単語内でのみ形成できます。一方、「長い」単語(パート2)の重要性を過大評価する問題を考慮して、可能な解決策として、「検索フレーズの関連性を、それに含まれる単語の関連性の平均として計算し、独立して計算する」ことが提案されました。インデックスを使用すると、この特定のアプローチと同等の結果が生成されます。
インデックス
索引付けの考え方は新しいものではなく、次のとおりです-テキスト内の単語が繰り返されているため、計算量を減らすことができます。これを行うには、検索を実行するテキストで最初にインデックスを生成する必要があります。最も単純なケースでは、インデックスはテキスト内のすべての単語のテーブルであり、単語に加えて、単語が出現するページに関するデータが含まれています。 L.N.の小説のテキストに基づくインデックステーブルのフラグメントトルストイの「戦争と平和」(合計で約5万語が含まれています)を図に示します。

リクエストを処理する過程で、検索文字列はまず単語に分解されます。さらに、検索文字列の各単語について、インデックス内の各単語との関連性が計算されます。計算結果は「検索文字列単語」、「索引単語」、「関連性係数」、「ページ番号」の列を含む予備結果の表。テーブルには、インデックスの行、つまり単語が指定されたしきい値を超えた関連係数のみが含まれます。つまり、一致する単語を含むインデックスの各行は、この単語が出現するテキストページの数に等しい予備結果のテーブルに行を生成します。以下は、「Evening at Anna Pavlovna Sherer's」という語句を検索した予備結果の表の一部です。

次に、予備結果の表は、ページ番号、検索文字列ワード、ファクターの列でソートされます。(降順)。

並べ替えられたテーブルの行をトラバースすることにより、各ページおよび検索文字列の各単語について、このページの最も関連性の高い単語が特定されます-上記の並べ替えにより、これは、各ページ番号-検索文字列の単語の最初の単語になります。残りの行は組み合わせによって破棄されます。
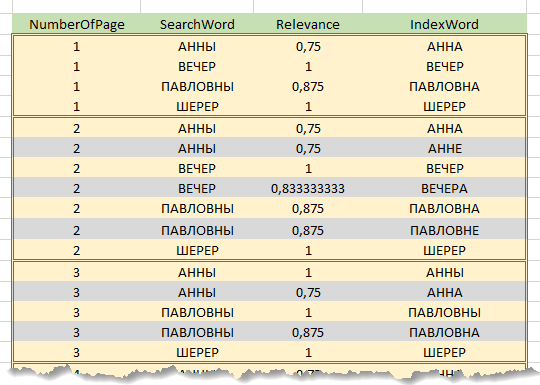
したがって、予備結果の表に含まれるテキストの各ページについて、検索文字列の各単語について、このページの最も関連性の高い単語と対応する係数が見つかります。ページ上で見つかった単語の係数の合計は、検索バーの単語数と呼ばれ、ページの関連性の係数になります。

たとえば、上の図では、「アンナパブロヴナシェラーズの夕方」という行(前置詞「y」は考慮されていません)によって検索が実行され、灰色で強調表示された行は走査中に破棄されます。ページ1の関連係数は、(0.75 + 1 + 0.875 + 1)/ 4 = 0.906、ページ2-0.906、3-0.75になります。
利点
インデックス作成に費やされた時間を考慮に入れない場合、その結果は再利用され、その評価の合計がパート1で再現される計算の総量が考慮されます。、データ文字列の長さの倍数:
 ;
;
インデックスを使用することによる利益は比率の倍数になると言えます。
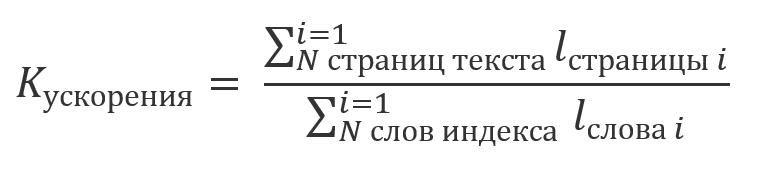
たとえば、デモスタンドtextradar.ruでは、小説「戦争と平和」のテキストはそれぞれ2000文字の1488ページに分割されています。 52156の要素で構成されるインデックスの単語のシンボルの総数は434060です。つまり、インデックス付けによるゲインは約7になります。

索引付けを使用して取得した結果は、前述のアプローチのいずれかを使用せずに取得した結果と同等であるため、テキストの索引付けされた部分と索引付けされていない部分の検索結果を一緒に処理することが可能になります。索引付けは比較的コストのかかる操作であり、通常はスケジュールに従って実行されるため、テキストの一部に索引が付けられ、一部はまだ索引付けされていない可能性があります。この場合、計算量の節約は、インデックス化されたテキストの合計サイズにおけるシェアの倍数になります。
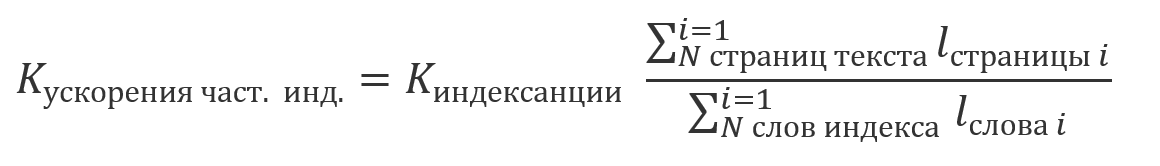
インデックスを使用すると、検索速度が向上するだけでなく、他にも多くの可能性が開かれます。たとえば、索引付けから得られた統計を使用して、まれな単語の重要性を高め、検索フレーズの重要な単語がより頻繁に見つかるテキストのページを強調表示できます。シノニムを使用してインデックステーブルを拡張することもできます。
これで、TextRadarの説明に特化した出版物のサイクルが終わります。当初の予定よりもさらに前進するための関心と貴重なコメントをありがとうございました。
説明したアプローチを適用した結果は、ウェブサイトtextradar.ruに配置されたデモスタンドで確認できます。実装(C#ASP.NET MVC)はこちらにあります。