
アーキテクチャの観点から、IoTプラットフォームでは次のタスクを解決する必要があります。
- 受信、受信、および処理されるデータの量には、高い帯域幅、ストレージ、および計算能力が必要です。
- デバイスは広い地理的領域に分散できます
- 企業は、新しいサービスを顧客に提供できるように、アーキテクチャを常に進化させる必要があります。
IoTプラットフォームの機能の1つは、オブジェクトと信号間の独立性です。これにより、並列計算が可能になり、生産性が向上します。
センサーからのデータは、PLC、DCS、マイクロコンピューターなどのソースから収集され、接続の問題によるデータ損失を回避するために時間ドメインに保存できます。データには、時系列(イベント)、半構造化データ(ログとバイナリ)、または非構造化データ(画像)があります。時系列データとイベントは頻繁に収集されます(毎秒から数分まで)。次に、それらはネットワークを介して送信され、一元化されたデータレイクおよび時系列データベースTSDBに保存されます。データレイクは、クラウドベース、ローカルデータセンター、またはサードパーティのストレージにすることができます。
データは、単純またはスマートな設定値に基づくルールチェックメカニズムを備えた「ホットパス」と呼ばれるデータフロー分析を使用して、すぐに処理できます。高度な分析には、デジタルツイン、機械学習、深層学習、または物理ベースの分析が含まれます。このようなシステムは、さまざまなセンサーからの大量のデータ(10分から1か月)を処理できます。このデータは中間ストレージに保存されます。この分析は「コールドパス」と呼ばれ、通常、スケジューラーによって、またはデータが利用可能で多くのコンピューティングリソースを必要とするときに起動されます。高度な分析では、多くの場合、監視対象の車両モデルや運用属性などの追加情報が必要になります。これらは資産レジストリにあります。資産レジストリには、名前、シリアル番号、記号名、場所、運用機能、構成部品の履歴、製造プロセスでの役割など、資産の種類に関する情報が含まれています。資産レジストリには、各資産のディメンション、論理名、測定単位、および境界の範囲のリストを格納できます。産業部門では、この静的な情報は正しい分析モデルに不可欠です。産業部門では、この静的な情報は正しい分析モデルに不可欠です。産業部門では、この静的情報は正しい分析モデルに不可欠です。
カスタムプラットフォームを開発する理由:
- 投資収益率:少額の予算。
- テクノロジー:サプライヤーに関係なくテクノロジーを使用する。
- データの機密性;
- 統合:新しいプラットフォームまたは古いプラットフォームとの統合レベルを開発する必要性。
- その他の制限。
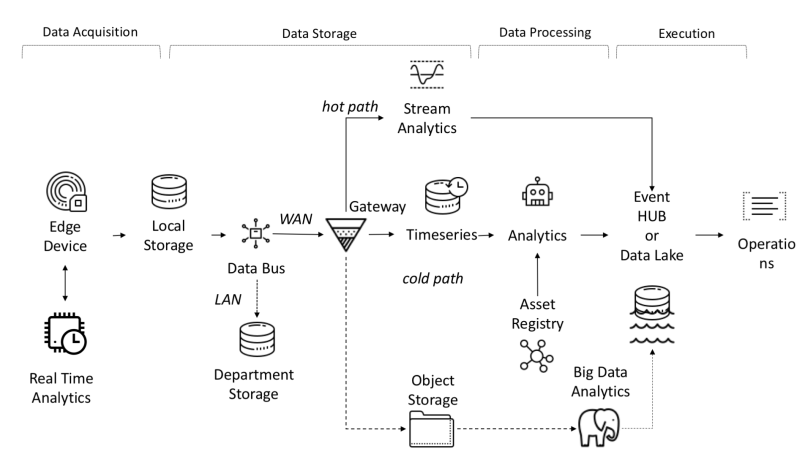
I-IoTのエンドツーエンドのデータフロー
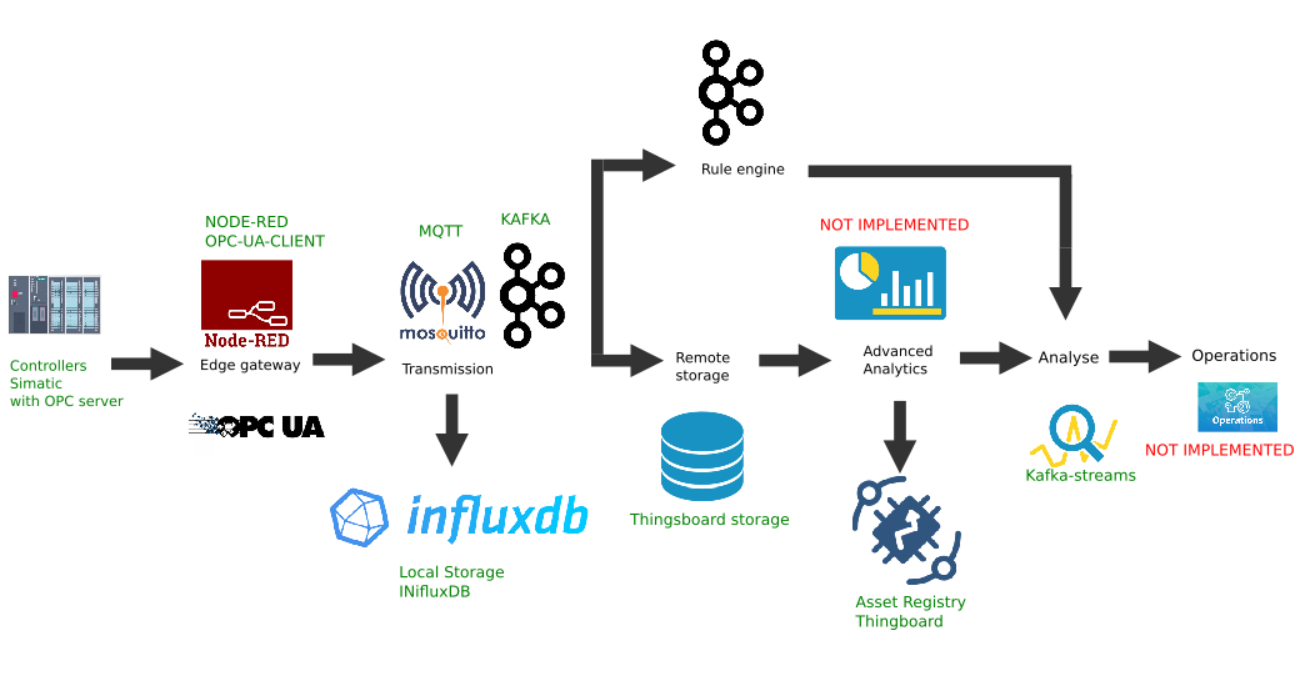
Edgeプラットフォームのカスタム実装の例
この図は、次のプラットフォームリンクの実装を示しています。
- データソース:例として、前の記事で説明したように、アクティブ化されたOPCサーバーを備えたSimatic PLCSIMAdvancedコントローラーシミュレーターが選択されています。
- node-red-contrib-opcuaプラグインがインストールされた人気のあるNode-Redプラットフォームが、境界ゲートウェイとして選択されました。
- MQTTブローカーMosquittoは、ストリーム内の他のリンク間のデータ転送のディスパッチャーとして使用されます。
- Apache Kafkaは、kafka-streamsを使用したホットパス分析として機能する分散ストリーミングプラットフォームとして使用されます。
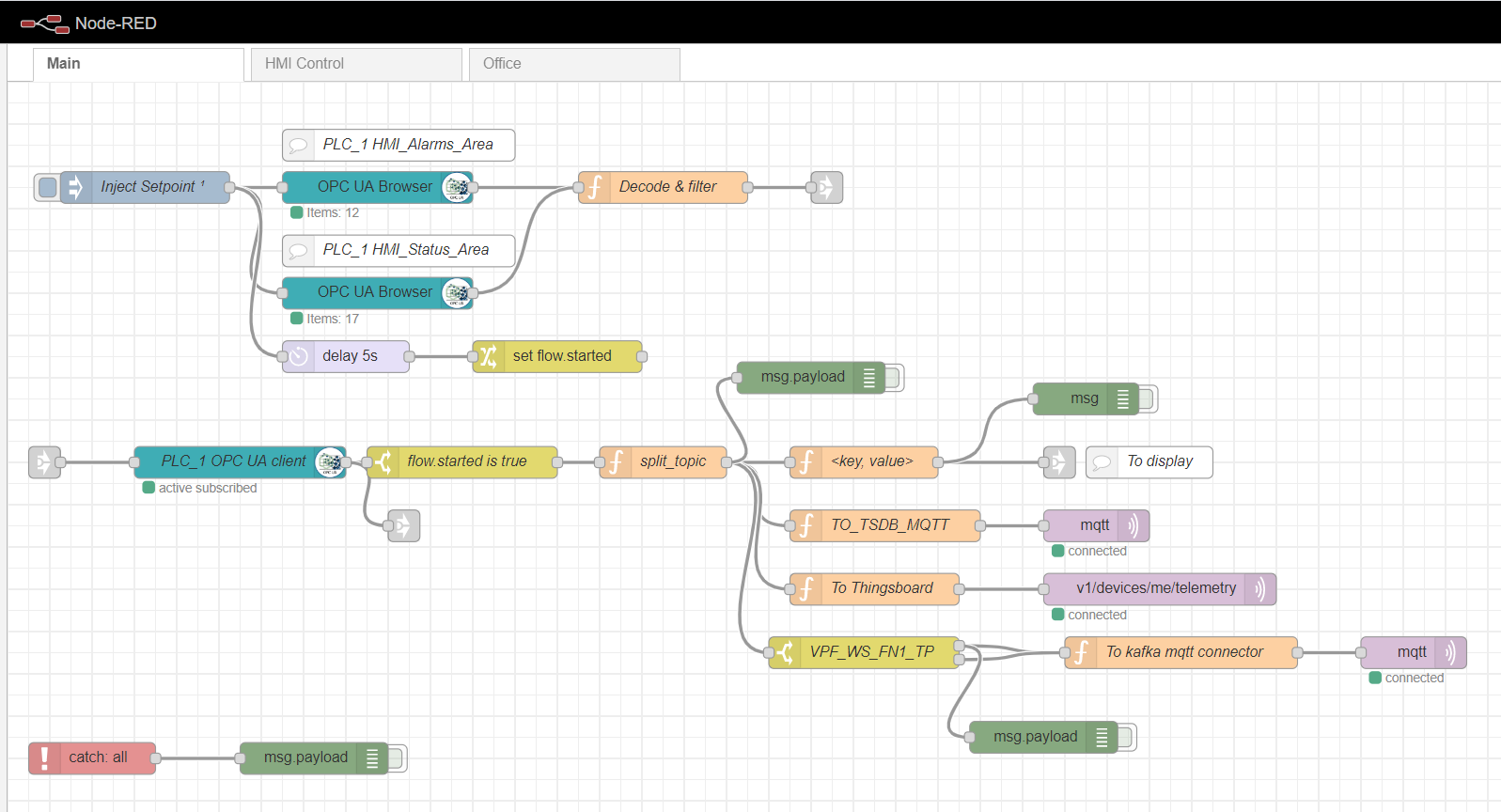
ノードレッドエッジゲートウェイ
エッジコンピューティングゲートウェイとして、さまざまなプラグインを備えたシンプルなカスタムプラットフォームであるNode-redを使用します。インダストリアルアダプタの役割は、node-red-contrib-opcuaプラグインによって果たされます。サブスクリプション方式によるコントローラーからのデータの複数の収集には、ノードOpcUa-BrowserおよびOpcUa-clientが使用されます。OPCブラウザノードでは、OPCサーバー(エンドポイント)のURLとトピックが構成されます。これにより、読み取り可能なデータブロックの名前名と名前が指定されます(例:ns = 3; s = "HMI_Alarms_Area")。OPCクライアントノードでは、OPCサーバーのURLも指定され、SUBSCRIBEとデータ更新間隔がアクションとして設定されます。
ノードレッドのメインフロー
OPCブラウザノードの設定

OPC-client

複数のデータを読み取るためにサブスクライブするには、OPCプロトコルに従って、コントローラーからタグを準備してダウンロードする必要があります。これを行うには、最初に、注入ノードを1回だけのチェックボックスで使用します。これにより、OPCブラウザーノードで指定されたデータブロックの1回の読み取りがトリガーされます。次に、データはデコード&フィルター機能によって処理されます。その後、OPCクライアントノードはサブスクライブし、コントローラーから変更データを読み取ります。ストリームのさらなる処理は、特定の実装と要件によって異なります。私の例では、データを処理して、さまざまなトピックのMQTTブローカーにさらに送信します。
HMIコントロールタブとOfficeタブは、Scadavis.ioに基づく単純なHMI実装であり、記事の前半で説明したように、ノードレッドのダッシュボードです。
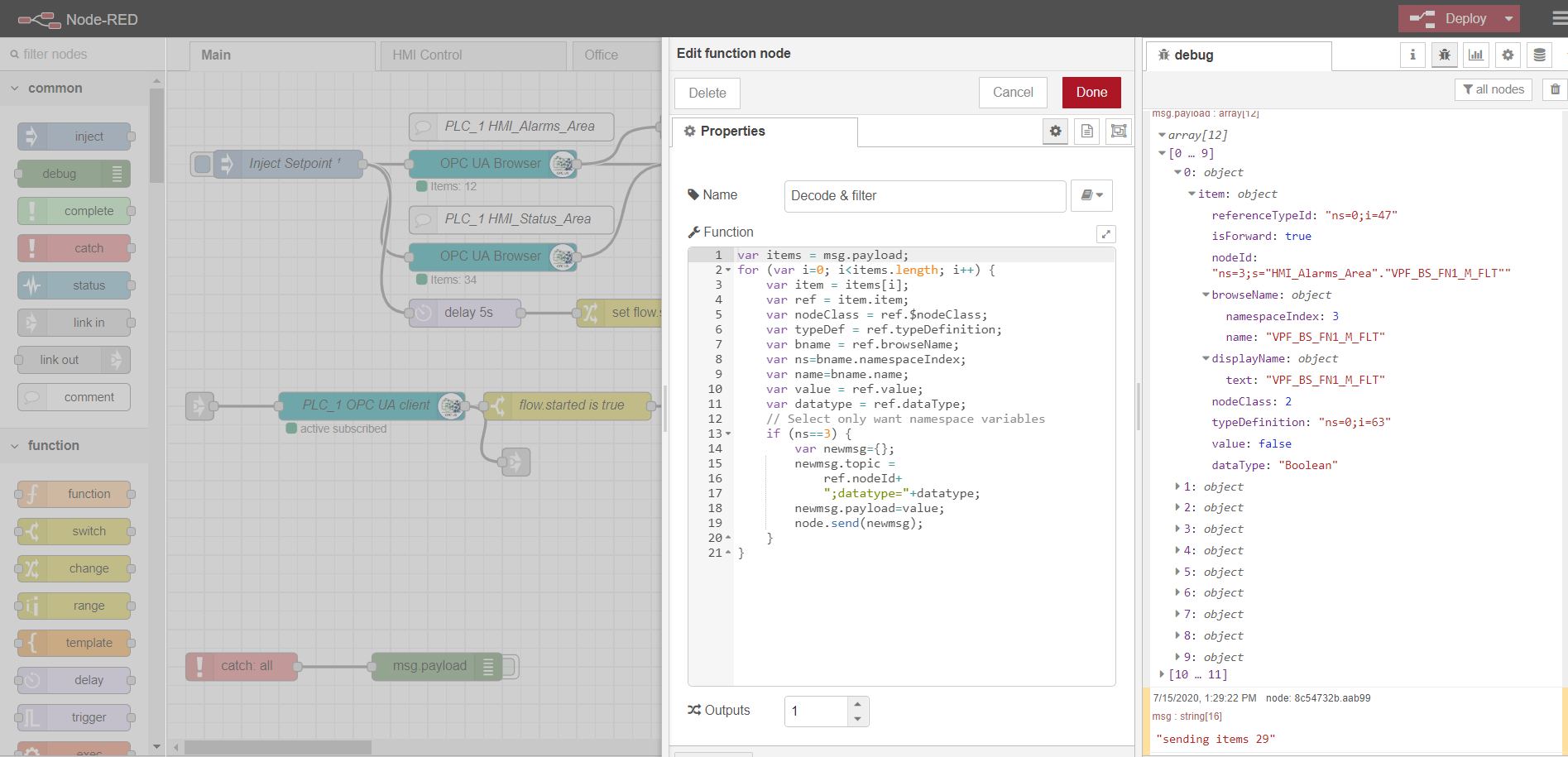
OPCブラウザノードからのデータの解析の例:
var items = msg.payload;
for (var i=0; i<items.length; i++) {
var item = items[i];
var ref = item.item;
var nodeClass = ref.$nodeClass;
var typeDef = ref.typeDefinition;
var bname = ref.browseName;
var ns=bname.namespaceIndex;
var name=bname.name;
var value = ref.value;
var datatype = ref.dataType;
// Select only want namespace variables
if (ns==3) {
var newmsg={};
newmsg.topic =
ref.nodeId+
";datatype="+datatype;
newmsg.payload=value;
node.send(newmsg);
}
}
MQTTブローカー
任意の実装をブローカーとして使用できます。私の場合、Mosquittoブローカーはすでにインストールおよび構成されています。ブローカーは、エッジゲートウェイと他のプラットフォーム参加者の間でデータを転送する機能を実行します。負荷分散と分散アーキテクチャの例があります(ここのように)。この場合、暗号化なしでデータ転送を行う1つのmqttブローカーに制限します。
時系列データのローカルストレージ
時系列データをNoSql時系列データベースに記録して保存すると便利です。InfluxDataスタックは、私たちの目的にはうまく機能します。このスタックには4つのサービスが必要です
。InfluxDBは、TICK(Telegraf、InfluxDB、Chronograf、Kapacitor)スタックの一部であるオープンソースの時系列データベースです。高負荷のデータ処理用に設計されており、データを操作するためのSQLのようなクエリ言語InfluxQLを提供します。
Telegrafは、外部IoTシステム、センサーなどからメトリックとイベントを収集してInfluxDBに送信するためのエージェントです。 mqttトピックからデータを収集するように構成されています。
Kapacitorは、InfluxDB 1.xの組み込みデータエンジンであり、InfluxDBプラットフォームに統合されたコンポーネントです。このサービスは、さまざまな設定値とアラームを監視するように構成できます。また、Kafka、電子メールなどの外部システムにイベントを送信するためのハンドラーをインストールすることもできます。
Chronografは、InfluxDBプラットフォームのユーザーインターフェイスおよび管理コンポーネントです。リアルタイムの視覚化でダッシュボードをすばやく作成するために使用されます。
スタックのすべてのコンポーネントは、ローカルで実行することも、Dockerコンテナを設定することもできます。
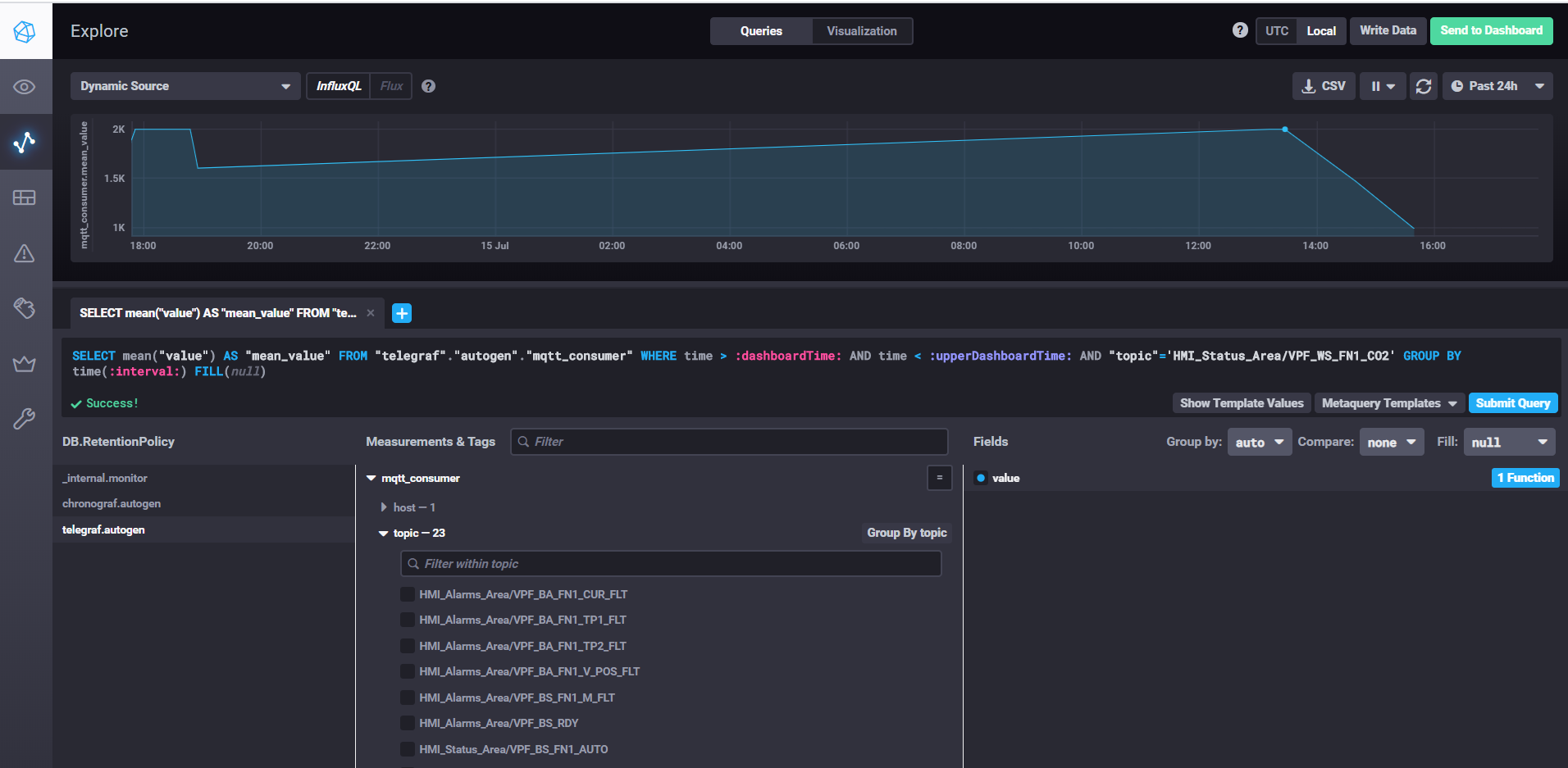
Chronografを使用したデータの取得とダッシュボードのカスタマイズ
InfluxDBを起動するには、influxdコマンドを実行するだけです。influxdb.conf設定で、保存場所やその他のプロパティを指定できます。デフォルトでは、データは.influxdbディレクトリのユーザーディレクトリに保存されます。
telegrafを開始するには、コマンドtelegraf -config telegraf.confを実行する必要があります。ここで、設定でメトリックとイベントのソースを指定できます。mqttの例では、次のようになります。
# # Read metrics from MQTT topic(s)
[[inputs.mqtt_consumer]]
servers = ["tcp://192.168.1.107:1883"]
qos = 0
topics = ["HMI_Status_Area/#", "HMI_Alarms_Area/#"]
data_format = "value"
data_type = "float"
サーバープロパティで、mqttブローカーへのURLを指定します。確認なしでデータを書き込むのに十分な場合、qosは0のままにすることができます。トピックプロパティで、データを読み取るトピックのmqttマスクを指定します。たとえば、HMI_Status_Area /#は、HMI_Status_Areaプレフィックスが付いているすべてのトピックを読み取ることを意味します。したがって、各トピックのテレグラフは、データベースに独自のメトリックを作成し、そこでデータを書き込みます。
kapacitorを起動するには、kapacitord -configkapacitor.confコマンドを実行する必要があります。プロパティはデフォルトのままにしておくことができ、クロノグラフを使用してさらに設定を行うことができます。
chronografを開始するには、同じ名前のchronografコマンドを実行するだけです。 Webインターフェイスが利用可能になりますlocalhost:8888 /
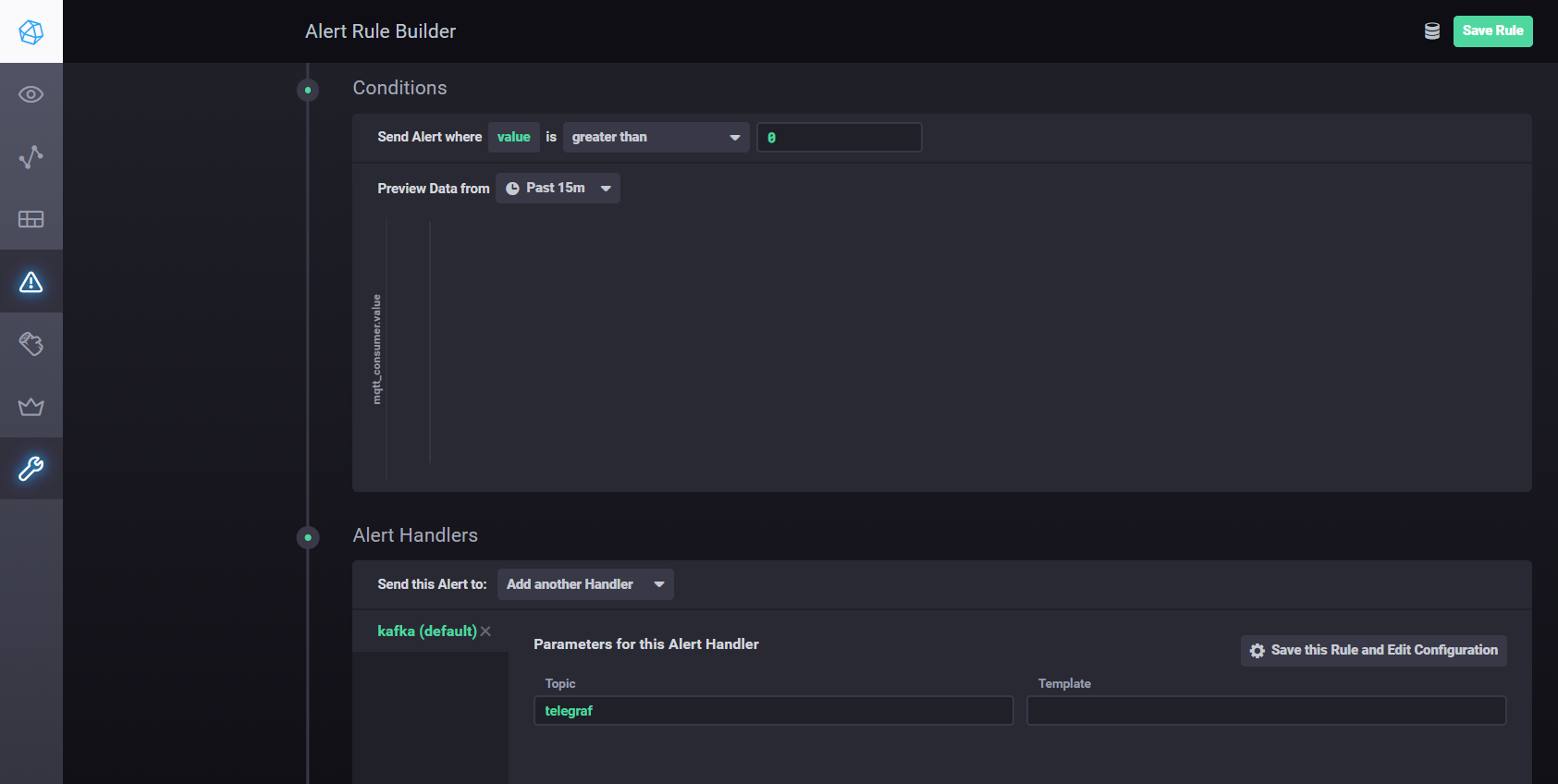
Kapacitorを使用して設定とアラームを構成するには、次を使用できます。マニュアル。つまり、Chronografの[アラート]タブに移動し、[アラートルールの作成]ボタンを使用して新しいルールを作成する必要があります。インターフェイスは直感的で、すべてが視覚的に行われます。kafkaなどへの処理結果の送信を設定します。条件セクションにハンドラーを追加する必要があります
Kapacitorハンドラー設定
ApacheKafkaを使用した分散ストリーミング
提案されたアーキテクチャでは、データ収集を処理から分離し、スケーラビリティとレイヤーの独立性を向上させる必要があります。キューを使用してこの目標を達成できます。実装はJavaMessage Service(JMS)またはAdvanced Message Queuing Protocol(AMQP)にすることができますが、この場合はApacheKafkaを使用します。 Kafkaは、ほとんどの分析プラットフォームでサポートされており、非常に高いパフォーマンスとスケーラビリティを備え、優れたKafkaストリームライブラリを備えています。
Node-red node-red-contrib-kafka-managerプラグインを使用して、Kafkaと対話できます。ただし、収集とデータ処理の分離を考慮して、MosquittoトピックをサブスクライブするMQTTプラグインをインストールします。 MQTTプラグインはこちらから入手できます。
コネクタを構成するには、kafka-connect-mqtt-1.1-SNAPSHOT.jarおよびorg.eclipse.paho.client.mqttv3-1.0.2.jarライブラリ(または別のバージョン)をkafka / libs /ディレクトリにコピーします。次に、/ configディレクトリに、次の内容のプロパティファイルmqtt.propertiesを作成する必要があります。
name=mqtt
connector.class=com.evokly.kafka.connect.mqtt.MqttSourceConnector
tasks.max=1
kafka.topic=streams-measures
mqtt.client_id=mqtt-kafka-123456789
mqtt.clean_session=true
mqtt.connection_timeout=30
mqtt.keep_alive_interval=60
mqtt.server_uris=tcp://192.168.1.107:1883
mqtt.topic=mqtt
以前にzookeeper-serverとkafka-serverを起動したので、次のコマンドを使用してコネクタを起動できます。
connect-standalone.bat …\config\connect-standalone.properties …\config\mqtt.properties
mqttトピック(mqtt.topic = mqtt)から、データはKafkaトピックストリーム-メジャー(kafka.topic =ストリーム-メジャー)に書き込まれます。
簡単な例として、kafka-streamsライブラリを使用してmavenプロジェクトを作成できます。
kafka-streamsを使用すると、ホット分析とストリーミングデータ処理のためのさまざまなサービスとシナリオを実装できます。
現在の温度をその期間の設定値と比較する例。
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> source = builder.stream("streams-measures");
KStream<Windowed<String>, String> max = source
.selectKey((String key, String value) -> {
return getKey(key, value);
}
)
.groupByKey()
.windowedBy(TimeWindows.of(Duration.ofSeconds(WINDOW_SIZE)))
.reduce((String value1, String value2) -> {
double v1=getValue(value1);
double v2=getValue(value2);
if ( v1 > v2)
return value1;
else
return value2;
}
)
.toStream()
.filter((Windowed<String> key, String value) -> {
String measure = tagMapping.get(key.key());
double parsedValue = getValue(value);
if (measure!=null) {
Double threshold = excursion.get(measure);
if (threshold!=null) {
if(parsedValue > threshold) {
log.info(String.format("%s : %s; Threshold: %s", key.key(), parsedValue, threshold));
return true;
}
return false;
}
} else {
log.severe("UNKNOWN MEASURE! Did you mapped? : " + key.key());
}
return false;
}
);
final Serde<String> STRING_SERDE = Serdes.String();
final Serde<Windowed<String>> windowedSerde = Serdes.serdeFrom(
new TimeWindowedSerializer<>(STRING_SERDE.serializer()),
new TimeWindowedDeserializer<>(STRING_SERDE.deserializer(), TimeWindows.of(Duration.ofSeconds(WINDOW_SIZE)).size()));
// the output
max.to("excursion", Produced.with(windowedSerde, Serdes.String()));
資産レジストリ
実際、資産レジストリはEdgeプラットフォームの構造コンポーネントではなく、クラウドIoT環境の一部です。ただし、この例は、EdgeとCloudがどのように相互作用するかを示しています。
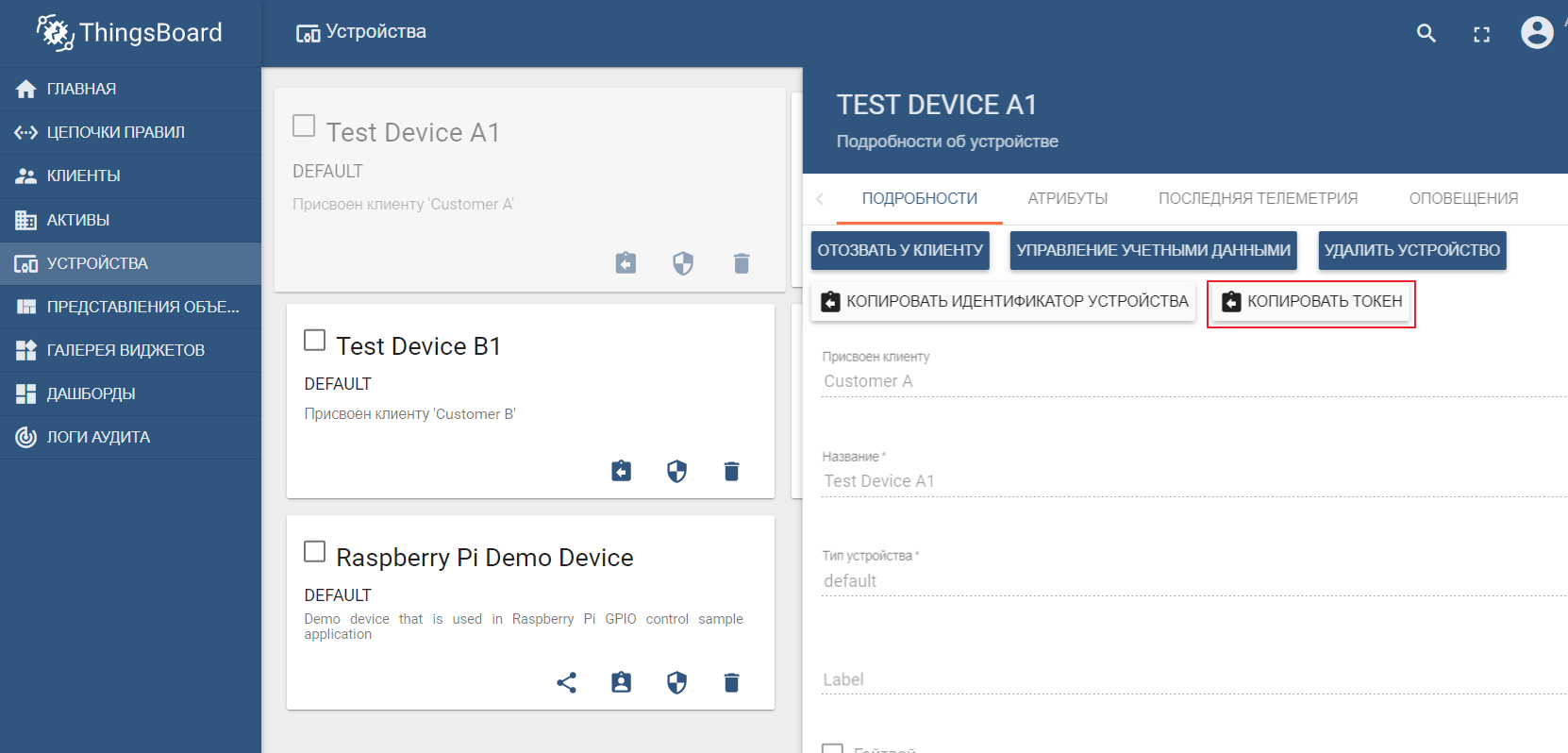
資産レジストリとして、人気のあるThingsBoard IoTプラットフォームを使用します。このプラットフォームのインターフェースも、非常に直感的です。デモデータでインストール可能です。プラットフォームは、ローカル、ドッカー、または既製のクラウド環境を使用してインストールできます。
デモデータセットには、値を送信できるテストデバイス(新しいデバイスを簡単に作成できます)が含まれています。デフォルトでは、ThingsBoardは独自のmqttブローカーで始まり、そこに接続してデータを送信する必要がありますjson形式で。テストデバイスA1からThingsBoardにデータを送信するとします。これを行うには、A1_TEST_TOKENをログインとして使用してlocalhost:1883のThingBoardブローカーに接続する必要があります。これは、デバイス設定からコピーできます。次に、トピックv1 / devices / me / telemetryにデータを公開できます。{「温度」:26}
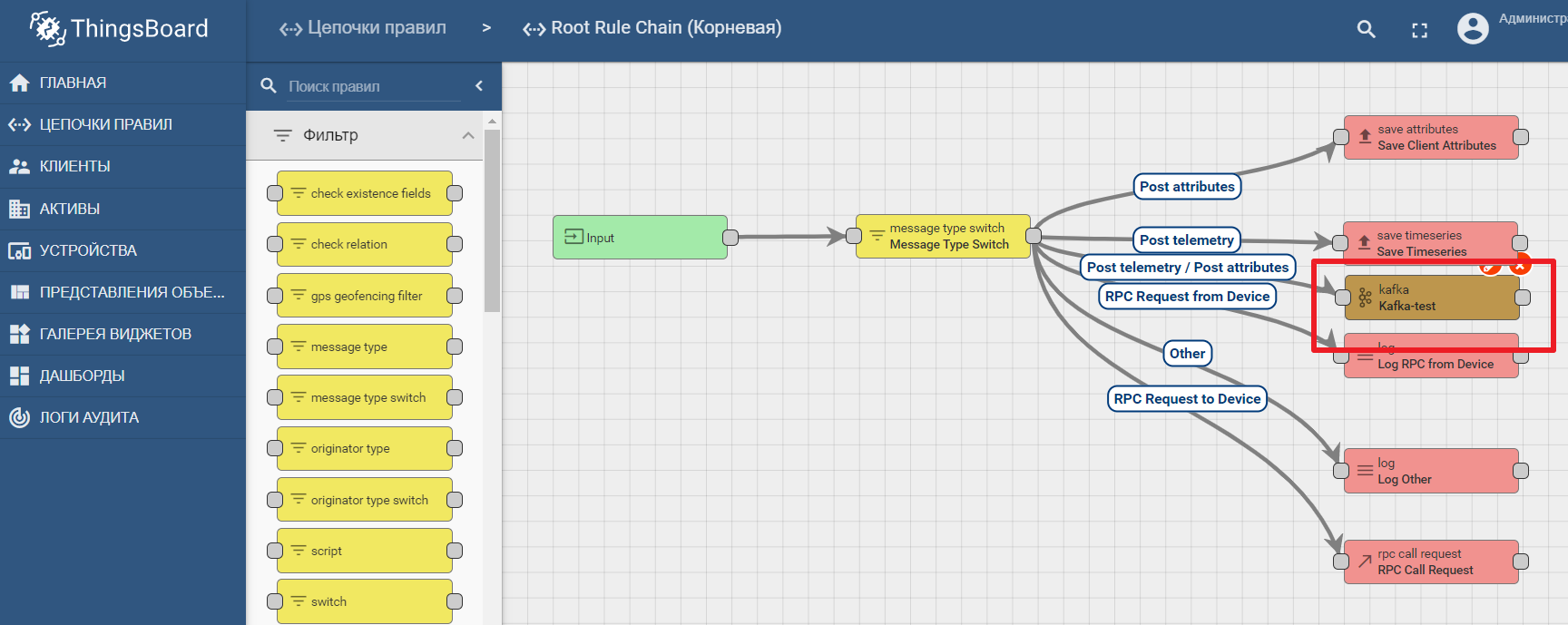
プラットフォームのドキュメントには、Kafkaでデータ転送と処理分析を設定するためのマニュアルが含まれています-Kafka、Kafka Streams、ThingsBoardを使用したIoTデータ分析
Thingsboardでkafkaノードを使用する例
結論
最新のITテクノロジーとオープンプロトコルにより、あらゆる複雑なシステムを設計できます。エッジプラットフォームは、産業環境とクラウドベースのIoTプラットフォーム間の接続ポイントです。これはマクロコンポーネントに分解でき、その中でエッジゲートウェイが重要な役割を果たし、デバイスからIoTデータハブへのデータの転送を担当します。オープンデータストリーミングツールは、効率的な分析とエッジコンピューティングを可能にします。