パート2
この記事では、次のことを学びます。
- 約ImageNet大規模視覚認識チャレンジ(ILSVRC)
- 存在するCNNアーキテクチャについて:
- LeNet-5
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- 新しいネットワークアーキテクチャでどのような問題が発生したか、後続のネットワークアーキテクチャによってどのように解決されたかについて:
- 勾配問題の消失
- 爆発的な勾配の問題
ILSVRC
ImageNet大規模視覚認識チャレンジは、研究者が写真のオブジェクト検出と分類のためにグリッドを比較する毎年恒例のコンテストです。
この競争は、以下の開発の推進力でした:
-ニューラルネットワークアーキテクチャ
-
今日まで使用されている個人的な方法と実践このグラフは、分類アルゴリズムが時間の経過とともにどのように進化したかを示しています:
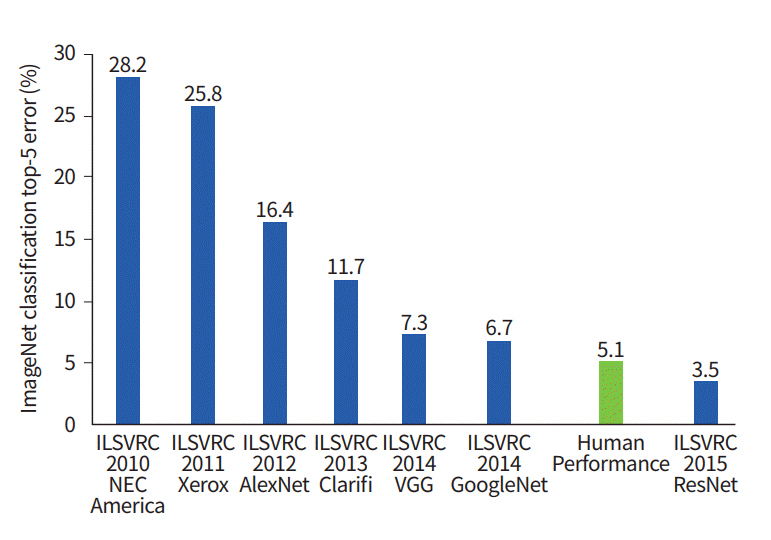
x軸上-年とアルゴリズム(2012年以降-畳み込みニューラル通信網)。
y軸は、上位5つのエラーからのサンプルのエラーのパーセンテージです。
トップ5エラーは、モデルを評価する方法です。モデルは特定の確率分布を返し、トップ5確率の中にクラスの真の値(クラスラベル)がある場合、モデルの答えは正しいと見なされます。したがって、(1-top-1エラー)はおなじみの精度です。
CNNアーキテクチャ
LeNet-5
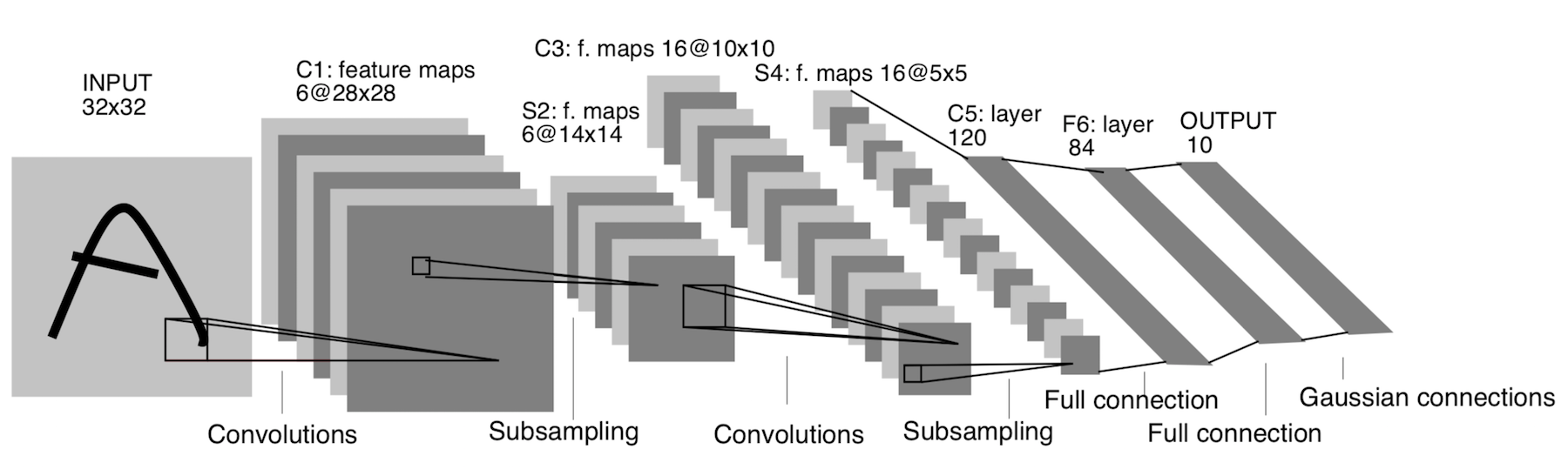
1998年に登場!手書きの文字や数字を認識するように設計されています。ここでのサブサンプリングとは、プーリングレイヤーを指します。
アーキテクチャ:
CONV 5x5、ストライド= 1
POOL 2x2、ストライド= 2
CONV 5x5、ストライド= 1
POOL 5x5、ストライド= 2
FC(120、84 )
FC(84、10)
現在、このアーキテクチャには歴史的な意味しかありません。このアーキテクチャは、最新の深層学習フレームワークに手作業で簡単に実装できます。
AlexNet

写真は複製されません。AlexNetアーキテクチャは当時1つのGPUデバイスに適合していなかったため、ネットワークの「半分」が一方のGPUで実行され、もう一方がもう一方のGPUで実行されていたため、このようにアーキテクチャが示されています。
2012年に登場しました。そのまさにILSVRCの突破口は彼女から始まりました-彼女は当時のすべての最先端モデルを打ち負かしました。その後、人々はニューラルネットワークが実際に機能することに気づきました:)
アーキテクチャより具体的に:

AlexNetアーキテクチャをよく見ると、14年間(LeNet-5の登場以来)、レイヤーの数を除いてほとんど変更が行われていないことがわかります。
重要:
- 元の227x227x3の画像を取得し、その寸法(高さと幅)を下げますが、チャネル数を増やします。アーキテクチャのこの部分は、オブジェクト(エンコーダ)の元の表現を「エンコード」します。
- ReLU. ReLu .
- 60 .
- .
:
- Local Response Norm — , . batch-normalization.
- - , — - FLOPs, .
- FC 4096 , (Fully-connected) 4096 .
- Max Pool 3x3s2 , 3x3, = 2.
- Conv 11x11s4、96のようなレコードは、コンボリューションレイヤーに11x11xNcフィルター(ステップ= 4)があることを意味し、そのようなフィルターの数は96です。このようなフィルターの数は次のレイヤー(同じNc)のチャネル数になります。初期画像には3つのチャネル(R、G、B)があると想定しています。
VGGNet
アーキテクチャ:
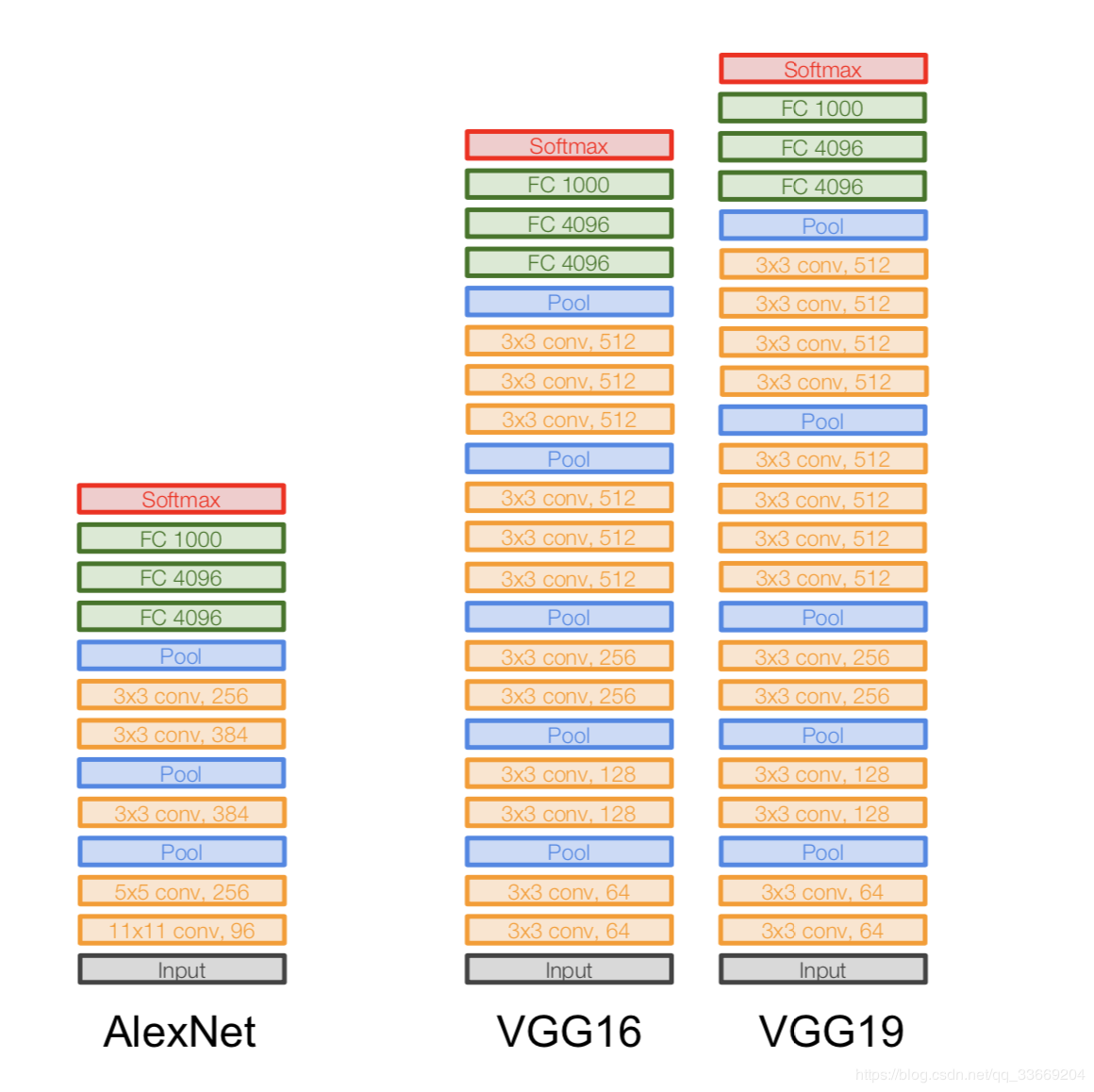
2014年に導入されました。
2つのバージョン-VGG16とVGG19。基本的な考え方は、大きなもの(11x11と5x5)の代わりに小さなもの(3x3)を使用することです。大きな畳み込みを使用する直感は単純です。隣接するピクセルからより多くの情報を取得したいのですが、小さなフィルターをより頻繁に使用する方がはるかに優れています。
そしてそれが理由です:
- . , . .. , , .
- => .
- — , — , — , .
重要:
-エラー逆伝播アルゴリズムについてニューラルネットワークをトレーニングする場合、順方向伝播のすべての段階(畳み込み、プール)でオブジェクト表現(私たちにとっては元の画像)を保持することが重要です(順方向パスとは、画像を入力にフィードして出力に移動するときです。結果に)。オブジェクトのこの表現は、メモリの点でコストがかかる可能性があります。見てみましょう。
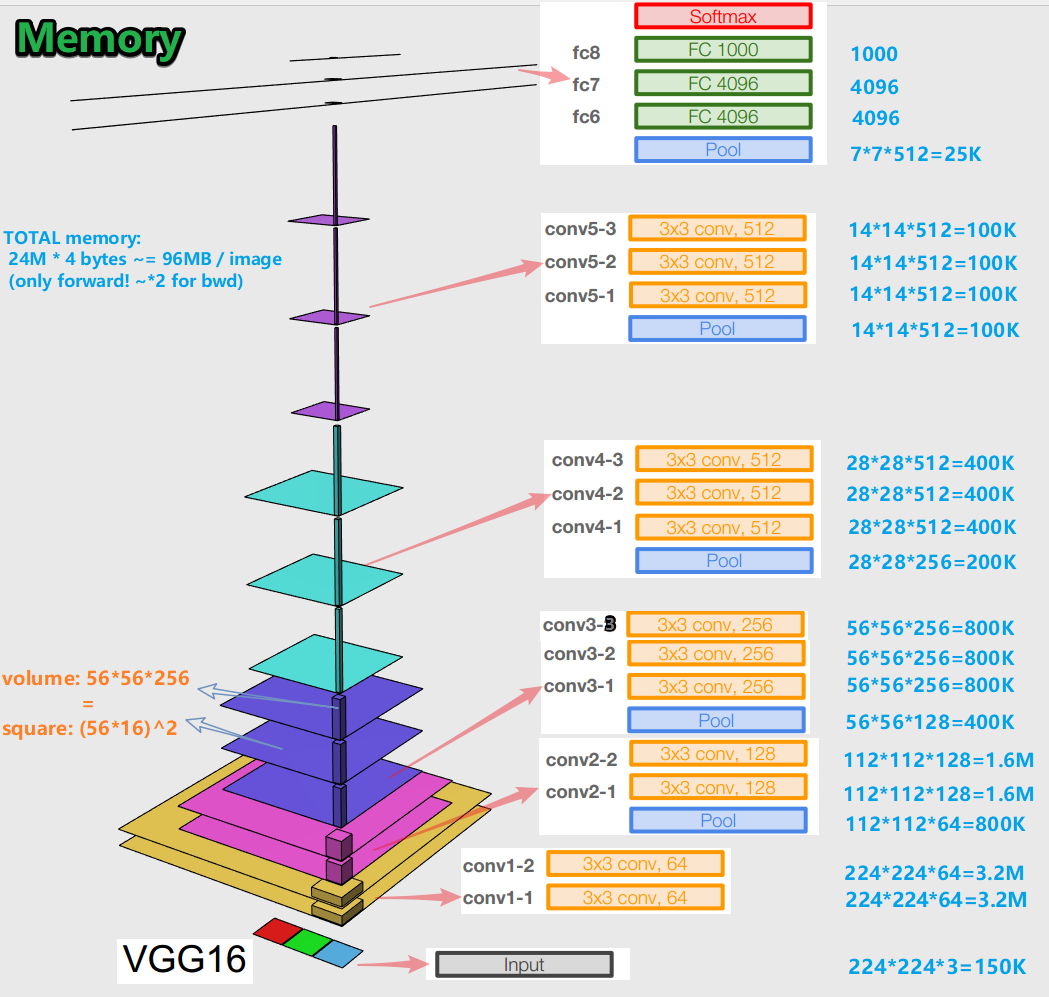
画像あたり約96MBであることがわかります。これは、フォワードパスの場合です。後方パス(写真のbwd)の場合(勾配の計算中)は、約2倍です。興味深い図が浮かび上がります。トレーニングされたパラメーターの最大数は完全に接続されたレイヤーにあり、最大のメモリは畳み込みレイヤーとプーリングレイヤーの後のオブジェクト表現によって占められています。 C-相乗効果。
-ネットワークには、16層のバリエーションで1億3800万の学習パラメーターがあり、19層のバリエーションで1億4300万のパラメーターがあります。
GoogLeNet
アーキテクチャ:
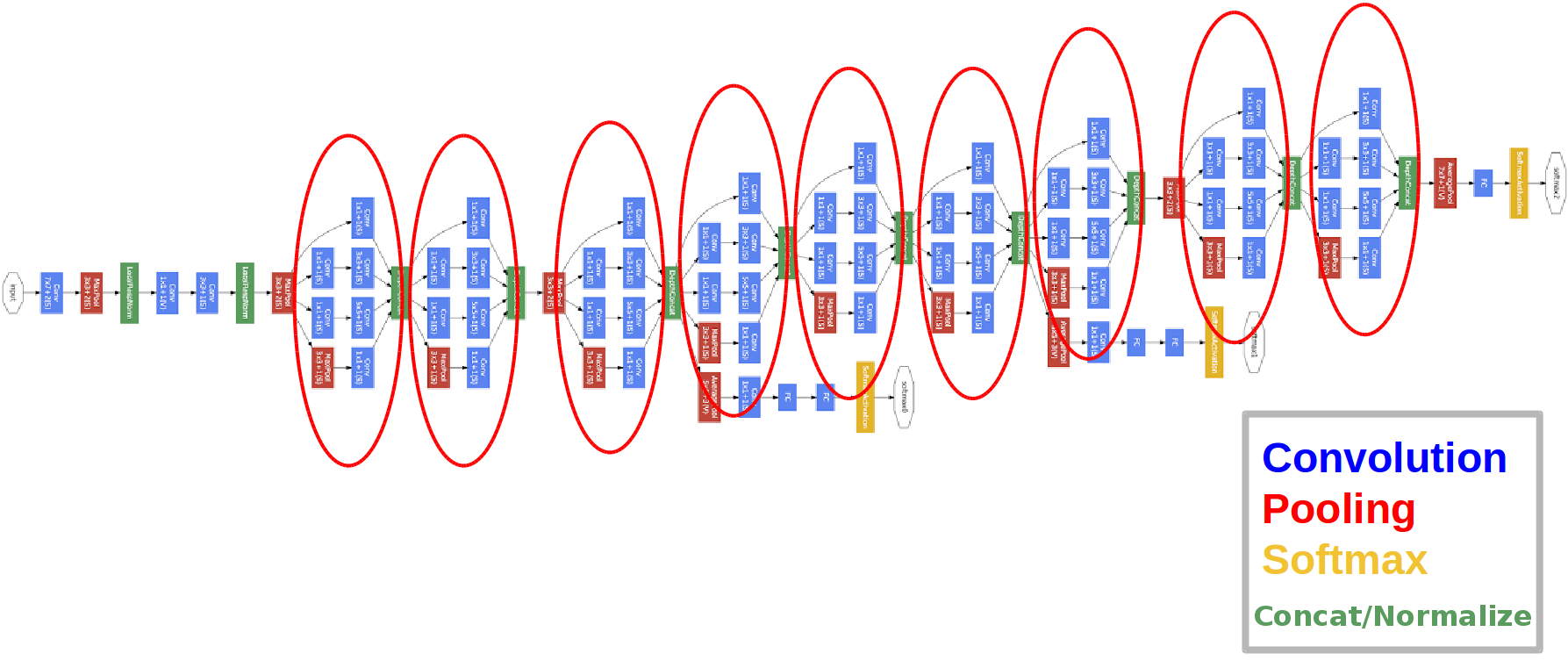
2014年に導入されました。
赤い円は、いわゆるインセプションモジュールです。
それを詳しく見てみましょう。
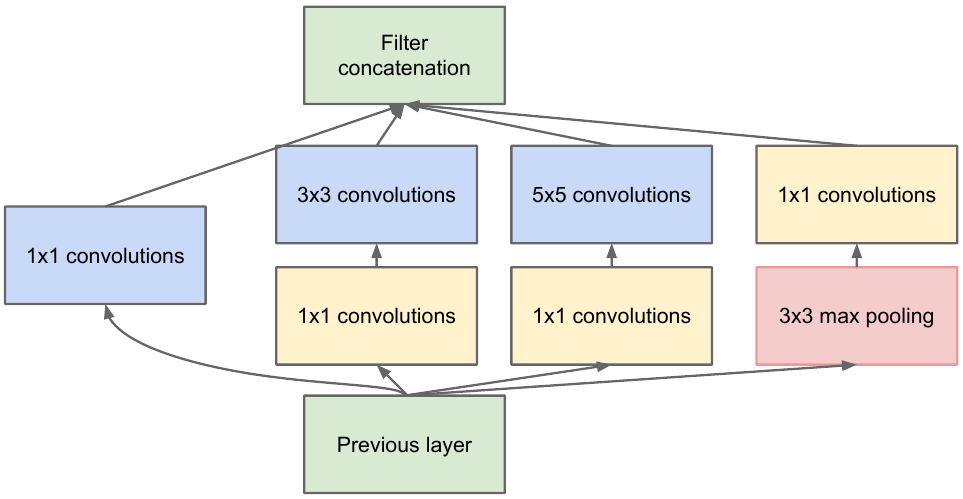
前のレイヤーからフィーチャマップを取得し、さまざまなフィルターを使用していくつかの畳み込みを適用してから、結果のレイヤーを連結します。直感は単純です。さまざまなサイズのフィルターを使用して、機能マップのさまざまな表現を取得したいと考えています。畳み込み1x1は、そのような各開始ブロックの後にチャネル数をそれほど増加させないために使用されます。それら。フィーチャマップに多数のチャネルがあり、フィーチャマップの高さと幅を変更せずにこの数を減らしたい場合は、1x1コンボリューションを使用します。
ネットワークには3つの分類子ブロックもあります。そのうちの1つは次のようになります(右側のブロック)。

この構造では、エラーの逆伝播中に出力層から入力層に「より良い」勾配が到達します。
なぜ2つの追加のネットワーク出力が必要なのですか?これは、いわゆるについてのすべてだ消勾配問題:
一番下の行は、エラーをbackpropagatingとき、勾配が自明にゼロに傾向があるということです。ネットワークが深くなるほど、この現象の影響を受けやすくなります。なぜそれが起こるのですか?バックワードパスを行うと、出力から入力に移動し、複雑な関数の勾配を計算します。複雑な関数の派生物(チェーンルール)本質的に乗算です。したがって、出力から入力までの途中でいくつかの値を乗算すると、ゼロに近い数値が満たされ、その結果、ニューラルネットワークの重みは実質的に更新されません。これは、出力が一定の範囲にあるシグモイドアクティベーション関数の問題の一部です。この問題は、ReLuアクティベーション機能を使用することで部分的に解決されます。なぜ部分的に?トレーニングされたパラメータの値と、すべてのフィーチャマップでの入力オブジェクトの表現を保証する人は誰もいないためです。
重要:
- ネットワークには22のレイヤーがあります(これは以前のネットワークよりもわずかに多いです)。
- トレーニングされたパラメータの数は500万に等しく、これは前の2つのネットワークの数分の1です。
- 1x1バンドルの外観。
- 開始ブロックが使用されます。
- 完全に接続されたレイヤーの代わりに、1x1のコンボリューションが深さを減らし、その結果、完全に接続されたレイヤーといわゆるグローバルアベガレプーリングの次元を減らします(詳細はこちらをご覧ください)。
- アーキテクチャには3つの出力があります(最終的な答えが重要視されます)。
ResNet
アーキテクチャ(ResNet-34バリアント):
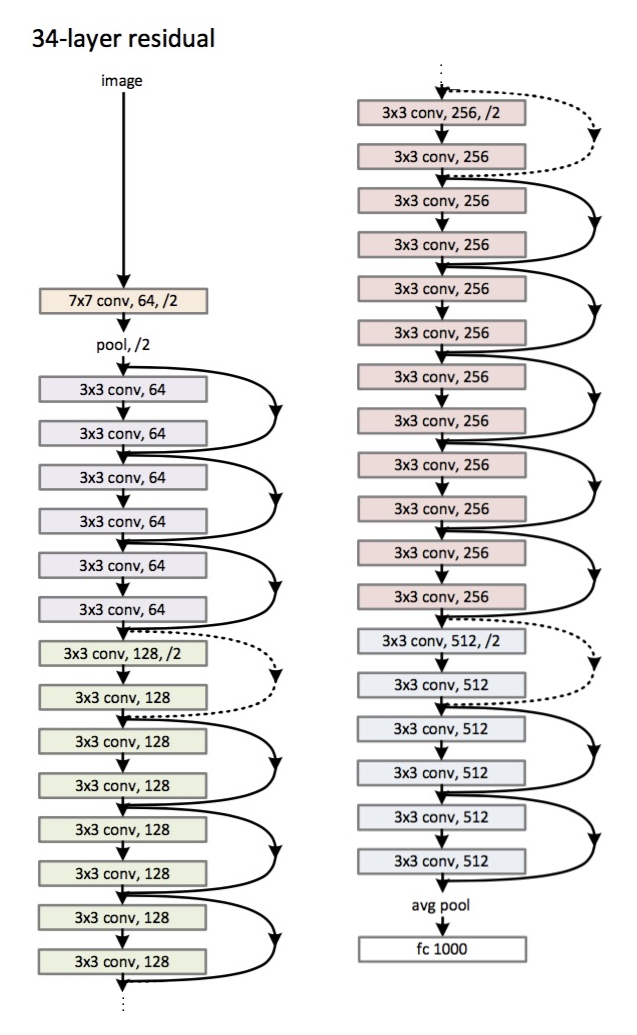
2015年に導入されました。
主な革新は、多数のレイヤーといわゆる残留ブロックです。これらのブロックは、フェージング勾配の問題に対処するために使用されます。このような残差ブロック間の接続は、ショートカット(図の矢印)と呼ばれます。ここで、これらのショートカットを使用すると、勾配が必要なすべてのパラメーターに到達し、それによってネットワークがトレーニングされます:)
重要:
- 完全に接続されたレイヤーの代わりに-平均的なグローバルプーリング。
- 残りのブロック。
- ネットワークは、ImageNetデータセット上の画像の認識において人間を上回っています(トップ5エラー)。
- バッチ正規化が初めて使用されました。
- 重みを初期化する手法が使用されます(直感:重みの特定の初期化から、ネットワークはより速く、より良く収束(学習)します)。
- 最大深度は152層です!
小さな逸脱
勾配のフェージングの問題は、すべての深い神経ネットワークに関連しています。
また、その拮抗薬である爆発勾配問題もあります。これは、すべての深部神経ネットワークにも関連しています。一番下の行は名前から明らかです-勾配が大きくなりすぎて、NaN(数ではなく無限大)が発生します。解決策は明らかです-勾配の値を制限するか、そうでなければ-その値を減らす(正規化する)。この手法は「クリッピング」と呼ばれます。
結論
2019年に、アーキテクチャの新しいファミリであるEfficientNetに関する記事が登場しました。ここでは
、機械学習に関連するさまざまなタスクや分野の最新の傾向に従うことをお勧めします。このリソースでは、タスク(たとえば、画像分類)とデータセット(たとえば、ImageNet)を選択し、特定のアーキテクチャの品質とそれらに関する追加情報を確認できます。たとえば、FixEfficientNet-L2グリッドは、ImageNetデータセットの画像分類で名誉ある1位になります(トップ1の精度)。 次の記事では、転移学習、オブジェクト検出、セグメンテーションについて説明します。