
Pythonでデータサイエンスの問題を解決するのは簡単ではありません
どうして?既存のツールは時系列に関連する問題の解決にはあまり適していないため、これらのツールを相互に統合することは困難です。 Scikit-learnのメソッドは、データが表形式で構造化されており、各列が独立した均等に分散されたランダム変数で構成されていることを前提としています。これは時系列データとは関係ありません。statsmodelsのように、機械学習用のモジュールがあり、時系列で動作するパッケージは、お互いにあまり良い友達ではありません。さらに、データを時間間隔でトレーニングセットとテストセットに分割するなど、時系列での多くの重要な操作は、既存のパッケージでは利用できません。
同様の問題を解決するために、sktimeが作成されました。

GitHubのSktimeライブラリロゴ
Sktimeは、時系列を操作するために特別に設計されたPythonのオープンソースマシン学習ツールキットです。このプロジェクトは、英国経済社会研究評議会、消費者データ研究、およびアランチューリング研究所によって開発および資金提供されているコミュニティです。
Sktimeは、時系列の問題を解決するためにscikit-learnAPIを拡張します。時系列回帰、予測、分類の問題を効率的に解決するために必要なすべてのアルゴリズムと変換ツールが含まれています。このライブラリには、他の一般的なライブラリにはない時系列の特別な機械学習アルゴリズムと変換方法が含まれています。
Sktimeは、scikit-learnと連携し、相互に関連する時系列の問題にアルゴリズムを簡単に適合させ、複雑なモデルを構築するように設計されています。使い方?多くの時系列問題は、何らかの形で相互に関連しています。ある問題を解決するために適用できるアルゴリズムは、それに関連する別の問題を解決するために適用できることがよくあります。この考えは削減と呼ばれます。たとえば、時系列回帰のモデル(系列を使用して出力値を予測する)は、時系列予測問題(出力値を予測する-将来受信される値)に再利用できます。
プロジェクトの主なアイデア:「Sktimeは、時系列を使用して、理解しやすく統合可能な機械学習を提供します。scikit-learnおよびモデル共有ツールと互換性のあるアルゴリズムがあり、学習タスクの明確な分類、明確なドキュメント、および友好的なコミュニティによってサポートされています。」
この記事では、sktimeのユニークな機能のいくつかに焦点を当てます。
時系列の正しいデータモデル
Sktimeは、パンダデータフレームの形式で時系列にネストされたデータ構造を使用します。
一般的なデータフレームの各行には、独立した均等に分散されたランダム変数(ケース)と列(異なる変数)が含まれています。sktimeメソッドの場合、Pandasデータフレームの各セルに時系列全体を含めることができるようになりました。この形式は、多次元、パネル、および異種データに対して柔軟性があり、Pandasとscikit-learnの両方でメソッドを再利用できます。
以下の表の各行は、列Xに時系列の配列を含み、列Yにクラス値を含む観測値です。sktimeエバリュエーターとトランスフォーマーは、このような時系列の操作に長けています。
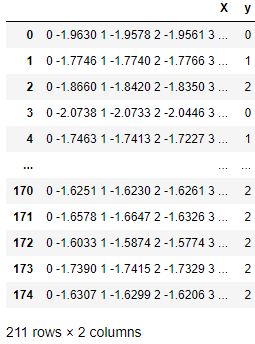
ネイティブのsktime互換時系列データ構造。
次の表では、scikit-learnメソッドの必要に応じて、Xシリーズの各要素が個別の列に移動されています。寸法はかなり高いです-251列!さらに、列の時間順序は、表形式の値で機能する学習アルゴリズムによって無視されます(ただし、時系列分類および回帰アルゴリズムで使用されます)。
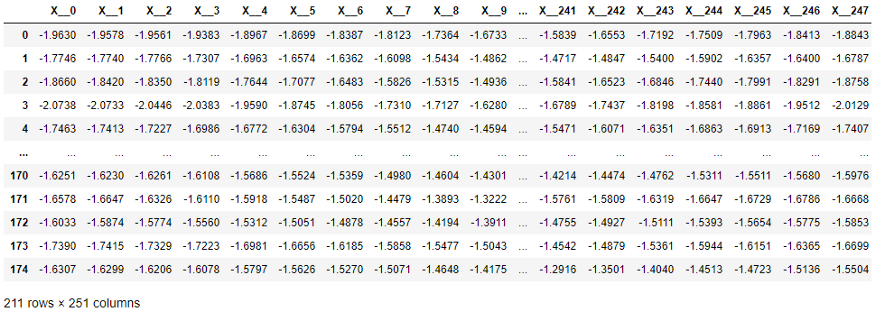
scikit-learnに必要な時系列データ構造。
複数のジョイントシリーズのタスクをモデリングするには、sktimeと互換性のあるネイティブの時系列データ構造が理想的です。scikit-learnが期待する表形式のデータでトレーニングされたモデルは、多くの機能で行き詰まります。
sktimeは何ができますか?
GitHub ページによると、sktimeは現在次の機能を提供しています。
- 時系列分類、回帰分析、および予測のための最新のアルゴリズム(ツールキット
tsmlからJavaに移植)。 - 時系列トランスフォーマー:単一シリーズの変換(たとえば、トレンド除去またはデシーズン化)、機能としてのシリーズの変換(たとえば、機能の抽出)、および複数のトランスフォーマーを共有するためのツール。
- 変圧器とモデルのパイプライン。
- モデルの設定;
- モデルのアンサンブル。たとえば、分類と時系列回帰のための完全にカスタマイズ可能なランダムフォレスト、多次元問題のためのアンサンブル。
API sktime
前述のように、sktimeは、クラス
fit、predictおよびへの基本的なAPIscikit -learnメソッドをサポートしますtransform。
評価者クラス(またはモデル)の場合、sktimeは
fit、モデルをトレーニングする方法と、predict新しい予測を生成する方法を提供します。sktimeの
評価者は、共変量と分類子scikit-learnを展開し、時系列で機能するこれらのメソッドの類似物を提供します。 クラスの場合、sktimeトランスフォーマーはメソッドを提供し、シリーズデータを変換します。利用可能な変換にはいくつかのタイプがあります。
fittransform
- , , ;
- , (, );
- (, );
- , , , (, ).
次の例は、GitHubの予測ガイドを応用したものです。この例のシリーズ(Box-Jenkins航空会社のデータセット)は、1949年から1960年までの1か月あたりの国際航空機乗客数を示しています。
まず、データをロードしてトレーニングスイートとテストスイートに分割し、グラフを作成します。でsktime -これらのタスクを簡単に実行するための2つの便利な機能してい
temporal_train_test_splitforたデータと時間のセットで分離されているplot_ysテストと学習サンプルに基づいてプロットし、。
from sktime.datasets import load_airline
from sktime.forecasting.model_selection import temporal_train_test_split
from sktime.utils.plotting.forecasting import plot_ys
y = load_airline()
y_train, y_test = temporal_train_test_split(y)
plot_ys(y_train, y_test, labels=["y_train", "y_test"])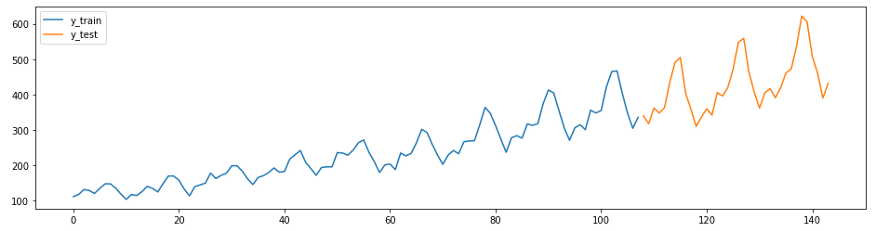
複雑な予測を行う前に、単純なベイジアンアルゴリズムを使用して取得した値と予測を比較すると便利です。良いモデルはこれらの値を超える必要があります。でsktime方法持っている
NaiveForecasterベースライン予測を作成するためのさまざまな戦略を持つが。
以下のコードと図は、2つの素朴な予測を示しています。 Forecaster c
strategy = “last”は、常にシリーズの最後の値を予測します。
Forecaster s
strategy = “seasonal_last”は、特定のシーズンのシリーズの最後の値を予測します。この例の季節性は“sp=12”、つまり12か月に設定されています。
from sktime.forecasting.naive import NaiveForecaster
naive_forecaster_last = NaiveForecaster(strategy="last")
naive_forecaster_last.fit(y_train)
y_last = naive_forecaster_last.predict(fh)
naive_forecaster_seasonal = NaiveForecaster(strategy="seasonal_last", sp=12)
naive_forecaster_seasonal.fit(y_train)
y_seasonal_last = naive_forecaster_seasonal.predict(fh)
plot_ys(y_train, y_test, y_last, y_seasonal_last, labels=["y_train", "y_test", "y_pred_last", "y_pred_seasonal_last"]);
smape_loss(y_last, y_test)
>>0.231957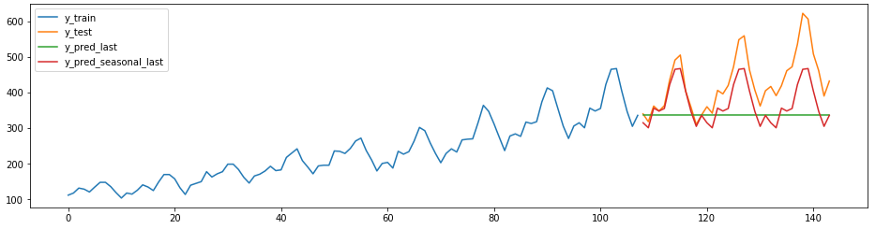
次の予測スニペットは、既存のsklearnリグレッサを簡単に、正しく、最小限の労力で予測タスクに適合させる方法を示しています。下記の方法である
ReducedRegressionForecasterからsktimeモデルを使用してシリーズを予測するにはsklearnRandomForestRegressor。内部的には、sktimeはトレーニングデータを12のウィンドウに分割して、リグレッサーがトレーニングを続行できるようにします。
from sktime.forecasting.compose import ReducedRegressionForecaster
from sklearn.ensemble import RandomForestRegressor
from sktime.forecasting.model_selection import temporal_train_test_split
from sktime.performance_metrics.forecasting import smape_loss
regressor = RandomForestRegressor()
forecaster = ReducedRegressionForecaster(regressor, window_length=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_ys(y_train, y_test, y_pred, labels=['y_train', 'y_test', 'y_pred'])
smape_loss(y_test, y_pred)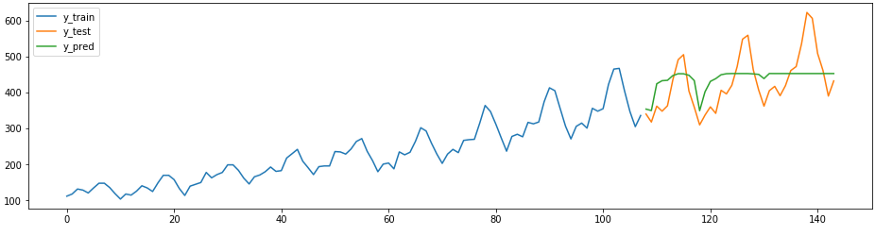
でsktimeまた、例えば、予測の独自のメソッドを持っています
AutoArima。
from sktime.forecasting.arima import AutoARIMA
forecaster = AutoARIMA(sp=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_ys(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"]);
smape_loss(y_test, y_pred)
>>0.07395319887252469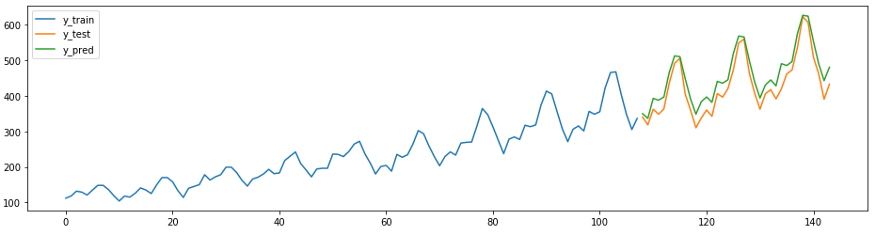
sktime 予測機能について詳しくは、こちらのチュートリアルをご覧ください。
時系列分類
また、
sktime時系列をさまざまなグループに分類するためにも使用できます。
以下のコード例では、単一の時系列の分類は、scikit-learnでの分類と同じくらい簡単になっています。唯一の違いは、上で説明したネストされた時系列データ構造です。
from sktime.datasets import load_arrow_head
from sktime.classification.compose import TimeSeriesForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X, y = load_arrow_head(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y)
classifier = TimeSeriesForestClassifier()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
accuracy_score(y_test, y_pred)
>>0.8679245283018868例はpypi.org/project/sktimeから取得されました。TimeSeriesForestClassifierに
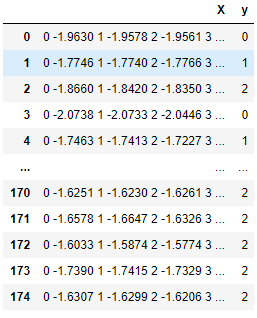
渡されたデータ
シリーズ分類の詳細については、sktimeの単変量および多変量分類のチュートリアルを参照してください。
追加のsktimeリソース
Sktimeの詳細については、ドキュメントと例について次のリンクを参照してください。
- APIの詳細な説明:sktime.org
- sktime GitHub ( );
- ;
- Sktime: Markus Löning, Anthony Bagnall, Sajaysurya Ganesh, Viktor Kazakov, Jason Lines, Franz Király (2019): “sktime: A Unified Interface for Machine Learning with Time Series”
. .