
この記事では、VK会話からすべての写真を並べ替えて特定の人物を見つけるために、顔認識用のニューラルネットワークを作成する体験について説明します。ニューラルネットワークの作成経験がなく、Pythonに関する最小限の知識がない。
前書き
セルゲイという名前の友人がいます。彼は、変わった方法で自分の写真を撮り、会話に送り込むのが大好きで、これらの写真に企業のフレーズを添えています。それで、不和の夜の1つで、私たちはアイデアを思いつきました。VKでパブリックを作成し、そこでセルゲイの引用を投稿することができました。延期の最初の10件の投稿は簡単でしたが、その後、手で会話してすべての添付ファイルを確認しても意味がないことが明らかになりました。そのため、このプロセスを自動化するためにニューラルネットワークを作成することが決定されました。
予定
- 会話から写真へのリンクを取得する
- 写真をダウンロード
- ニューラルネットワークの作成
開発を始める前に
, Python pip. , 0, ,
1.写真へのリンクを取得する
したがって、会話からすべての写真を取得したいので、messages.getHistoryAttachmentsメソッドは、会話または会話の資料を返す私たちに適しています。
2019年2月15日以降、Vkontakteは、モデレートに合格しなかったアプリケーションのメッセージへのアクセスを拒否しました。回避策のオプションのうち、サードパーティのメッセンジャーからトークンを取得するのに役立つvkhostを提供できます。
vkhostで受信したトークンを使用して、Postmanを使用して必要なAPIリクエストを収集できます。もちろん、それなしですべてをペンで埋めることができますが、わかりやすくするためにそれを使用
します。パラメータを入力します。
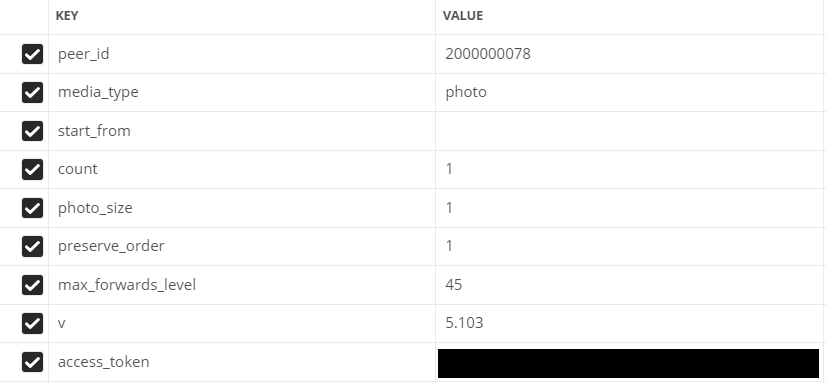
- peer_id-宛先識別子
会話の場合:2,000,000,000 +会話ID(アドレスバーに表示されます)。
ユーザーの場合:ユーザーID。 - media_type-メディアタイプ
私たちの場合、写真
- start_from-複数のアイテムを選択するためのオフセット。
とりあえず空のままにしておきましょう。
- count-受信したオブジェクトの数
最大200、それは私たちが使用する量です
- photo_sizes-配列内のすべてのサイズを返すフラグ
1または0。1を使用します
- keep_order-添付ファイルを元の順序で返す必要があるかどうかを示すフラグ
1または0。1を使用します
- v-vkapiバージョン
1または0。1を使用します
Postmanの入力フィールド
コードの記述に移動
便宜上、すべてのコードはいくつかの個別のスクリプトに分割されます。
会話/ダイアログに200枚未満の写真がある 場合、jsonモジュール(データをデコードするため)とリクエストライブラリ(httpリクエストを行うため)を使用します
コードリスト
import json
import requests
val = 1 #
Fin = open("input.txt","a") #
# GET API response
response = requests.get("https://api.vk.com/method/messages.getHistoryAttachments?peer_id=2000000078&media_type=photo&start_from=&count=10&photo_size=1&preserve_order=1&max_forwards_level=45&v=5.103&access_token=_")
items = json.loads(response.text) # JSON
# GET ,
for item in items['response']['items']: # items
link = item['attachment']['photo']['sizes'][-1]['url'] # ,
print(val,':',link) #
Fin.write(str(link)+"\n") #
val += 1 #
写真が200枚以上ある場合
import json
import requests
next = None #
def newfunc():
val = 1 #
global next
Fin = open("input.txt","a") #
# GET API response
response = requests.get(f"https://api.vk.com/method/messages.getHistoryAttachments?peer_id=2000000078&media_type=photo&start_from={next}&count=200&photo_size=1&preserve_order=1&max_forwards_level=44&v=5.103&access_token=_")
items = json.loads(response.text) # JSON
if items['response']['items'] != []: #
for item in items['response']['items']: # items
link = item['attachment']['photo']['sizes'][-1]['url'] # ,
print(val,':',link) #
val += 1 #
Fin.write(str(link)+"\n") #
next = items['response']['next_from'] #
print('dd',items['response']['next_from'])
newfunc() #
else: #
print(" ")
newfunc()リンクをダウンロードする時が来ました
2.画像のダウンロード
写真をダウンロードするには、urllibライブラリを使用します
import urllib.request
f = open('input.txt') #
val = 1 #
for line in f: #
line = line.rstrip('\n')
# "img"
urllib.request.urlretrieve(line, f"img/{val}.jpg")
print(val,':','') #
val += 1 #
print("")
すべての画像をダウンロードするプロセスは、特に写真が8330の場合、最速ではありません。この場合のスペースも必要です。写真の数が私のものと同じかそれ以上の場合は、1.5〜2 GBを解放することをお勧めします。

大まかな作業は終了しました。これで、自分で始めることができます。興味深い-ニューラルネットワークを書く
3.ニューラルネットワークの作成
多くの異なるライブラリとオプションを調べた後、顔認識ライブラリを使用することが決定されました
それは何ができますか?
ドキュメントから、
写真の検索面の最も基本的な機能が写真内の
任意の数の人を見つける可能性があることを考慮してください、

個々の写真のあいまいな識別にも対処
できます

私たちにとって最も適切な方法は人の識別です
トレーニング
ライブラリの要件のうち、Python3.3以降またはPython2.7が必要です。
ライブラリに関しては、上記の顔認識とPILを使用して画像を操作します。
顔認識ライブラリはWindowsで公式にサポートされていませんが、私にとっては機能しました。すべてがmacOSとLinuxで安定して動作します。
何が起こっているのかの説明
まず、写真のさらなる検証がすでに行われている人物を検索するための分類子を設定する必要があります。
正面から見た人のできるだけ鮮明な写真を選択することをお勧めします。写真をアップロードするとき、ライブラリは画像を人の顔の特徴(鼻、目、口、あご)の座標に分解します。

さて、問題は小さいです。分類器と比較したい写真に同様の方法を適用するだけです。次に、ニューラルネットワークに顔の特徴を座標で比較させます。
まあ、実際のコード自体:
import face_recognition
from PIL import Image #
find_face = face_recognition.load_image_file("face/sergey.jpg") #
face_encoding = face_recognition.face_encodings(find_face)[0] # ,
i = 0 #
done = 0 #
numFiles = 8330 # -
while i != numFiles:
i += 1 #
unknown_picture = face_recognition.load_image_file(f"img/{i}.jpg") #
unknown_face_encoding = face_recognition.face_encodings(unknown_picture) #
pil_image = Image.fromarray(unknown_picture) #
#
if len(unknown_face_encoding) > 0: #
encoding = unknown_face_encoding[0] # 0 ,
results = face_recognition.compare_faces([face_encoding], encoding) #
if results[0] == True: #
done += 1 #
print(i,"-"," !")
pil_image.save(f"done/{int(done)}.jpg") #
else: #
print(i,"-"," !")
else: #
print(i,"-"," !")
ビデオカードで詳細な分析を実行することもできます。このためには、model = "cnn"パラメータを追加し、適切な人物を検索する画像のコードフラグメントを変更する必要があります。
unknown_picture = face_recognition.load_image_file(f"img/{i}.jpg") #
face_locations = face_recognition.face_locations(unknown_picture, model= "cnn") # GPU
unknown_face_encoding = face_recognition.face_encodings(unknown_picture) # 結果
GPUはありません。時間の経過とともに、ニューラルネットワークは1時間40分で8330枚の写真を調べて並べ替えると同時に、142枚の写真を見つけ、そのうち62枚は目的の人物の画像でした。もちろん、ミームや他の人々には誤検知がありました。CGPU。処理時間は17時間22分とはるかに長く、230枚の写真が見つかりました。そのうち99枚が必要な人物です。 結論として、その作業は無駄に行われなかったと言えます。8330枚の写真を並べ替えるプロセスを自動化しました。これは、自分で並べ替えるよりもはるかに優れています。 ソースコード全体をgithubからダウンロードすることもできます。