
過去3年間、Nvidiaは、シェーダーに使用される通常のコアに加えて、追加のコアがインストールされるグラフィックチップを作成してきました。テンソルコアと呼ばれるこれらのコアは、世界中の何千ものデスクトップ、ラップトップ、ワークステーション、およびデータセンターですでに使用されています。しかし、彼らは何をし、何のために使われているのでしょうか?それらはグラフィックカードでも必要ですか?
今日は、テンソルとは何か、そしてテンソルカーネルがグラフィックスと深層学習の世界でどのように使用されているかを説明します。
短い数学のレッスン
テンソルカーネルが何をしていて、何に使用できるかを理解するために、まずテンサーとは何かを理解します。すべてのマイクロプロセッサは、実行するタスクに関係なく、数値に対して数学的な操作(加算、乗算など)を実行します。
これらの番号は互いに特定の意味を持つため、グループ化する必要がある場合があります。たとえば、チップがデータを処理してグラフィックをレンダリングする場合、スケーリング係数として単一の整数値(たとえば、+ 2または+115)を処理したり、フロートのグループ(+ 0.1、-0.5、+ 0.6)を3D空間内のポイントの座標。 2番目のケースでは、3つのデータ項目すべてがポイント位置に必要です。
テンソル相互に関連する他の数学オブジェクト間の関係を記述する数学オブジェクトです。それらは通常、数字の配列として表示され、その寸法を以下に示します。

最も単純なテンソルタイプの次元はゼロで、単一の値で構成されます。それ以外の場合は、スカラーと呼ばれます。次元の数が増えると、他の一般的な数学的構造に遭遇します。
- 1次元=ベクトル
- 2次元=マトリックス
厳密に言えば、スカラーはテンソル0 x 0、ベクトルは1 x 0、マトリックスは1 x 1ですが、GPUのテンソルコアを簡単に参照するために、テンサーはマトリックスの形式でのみ検討します。
行列に対して実行される最も重要な数学的操作の1つは、乗算(または積)です。データの4つの行と列を持つ2つのマトリックスが互いにどのように乗算されるかを見てみましょう。
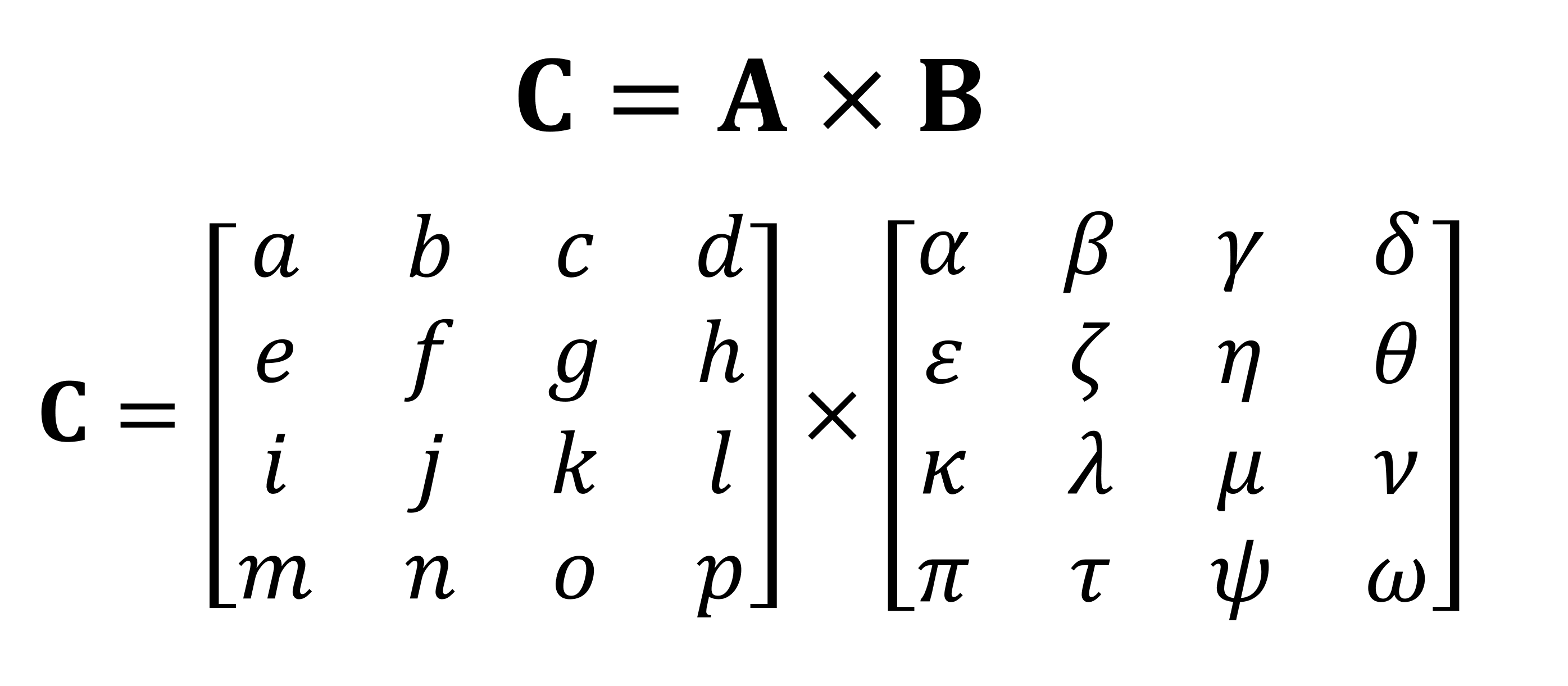
乗算の最終結果は、常に最初のマトリックスと同じ行数と2番目のマトリックスと同じ列数になります。これら2つの配列をどのように乗算しますか?このような:
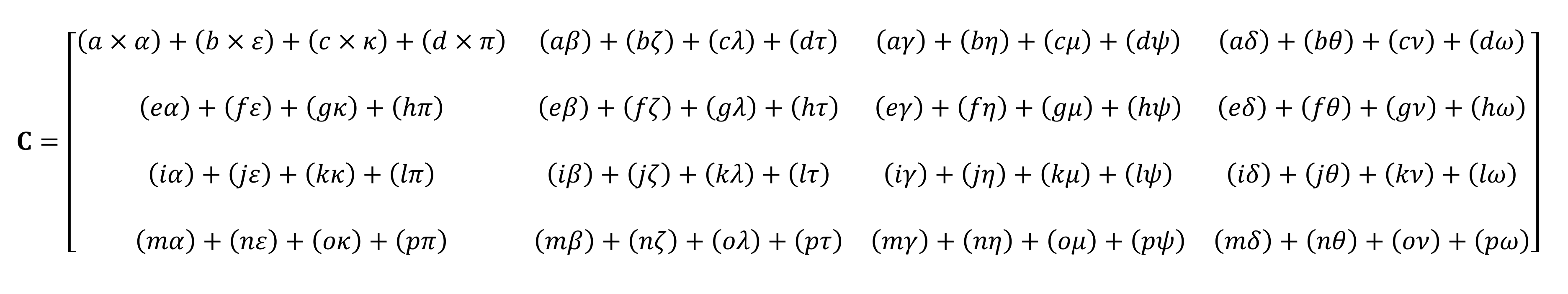
指でそれを計算することはできません。
ご覧のとおり、行列の「単純な」積の計算は、小さな乗算と加算の束全体で構成されています。最新の中央処理ユニットはこれらの操作の両方を実行できるため、最も単純なテンサーはすべてのデスクトップ、ラップトップ、またはタブレットで実行できます。
ただし、上記の例には、64の乗算と48の加算が含まれています。各小さな製品は、他の3つの小さな製品に追加する前にどこかに保存する必要がある値を提供し、最終的なテンソル値を後で保存できるようにします。したがって、行列乗算は数学的に単純ですが、計算コストが高くなります。 -多くのレジスタを使用する必要があり、キャッシュは一連の読み取りおよび書き込み操作に対応できる必要があります。

AVX拡張機能を最初に導入したIntelSandy Bridgeアーキテクチャ
長年にわたり、AMDおよびIntelプロセッサには、プロセッサが複数の数値を同時に処理できるようにするさまざまな拡張機能(MMX、SSE、および現在はAVX-すべてSIMD、単一命令複数データ)があります。浮動小数点; これはまさにマトリックス乗算に必要なものです。
ただし、SIMD操作を処理するために特別に設計された特殊なタイプのプロセッサがあります。それはグラフィックス処理ユニット(GPU)です。
通常の計算機よりも賢いですか?
グラフィックスの世界では、大量の情報をベクトルの形で同時に送信および処理する必要があります。 GPUは並列処理機能を備えているため、テンソル処理に最適です。最新のGPUはすべて、GEMM(General Matrix Multiplication)と呼ばれる機能をサポートしています。
これは「接着」操作であり、2つのマトリックスが乗算され、その結果が別のマトリックスに累積されます。マトリックスの形式には重要な制限があり、それらはすべて各マトリックスの行と列の数に関連しています。

GEMMの行と列の要件:マトリックスA(mxk)、マトリックスB(kxn)、マトリックスC(mxn)
マトリックスの操作を実行するために使用されるアルゴリズムは、通常、マトリックスが正方形の場合に最適に機能します(たとえば、10 x 10の配列が機能します)。 50 x 2)よりも優れており、サイズがかなり小さい。ただし、そのような操作専用に設計された機器で処理した場合でも、パフォーマンスは向上します。
2017年12月、Nvidiaは新しいVoltaアーキテクチャを備えたGPUを備えたグラフィックカードをリリースしました。これはプロの市場を対象としていたため、このチップはGeForceモデルでは使用されませんでした。テンソル計算のみを実行するコアを備えた最初のGPUになったため、これはユニークでした。

GV100Voltaチップを搭載したNvidiaTitanVグラフィックカード。はい、Crysisを実行できます。Nvidiaの
テンソルコアは、FP16値(16ビットの浮動小数点数)またはFP32を追加したFP16乗算を含む4 x 4マトリックスを使用して、クロックサイクルあたり64GEMMを実行するように設計されています。このようなテンサーはサイズが非常に小さいため、実際のデータセットを処理する場合、カーネルは大きなマトリックスの小さな部分を処理し、最終的な答えを作成します。
1年も経たないうちに、NvidiaはTuringアーキテクチャをリリースしました。今回は、テンソルコアもGeForceモデルにインストールされました消費者レベル。 INT8(8ビット整数値)などの他のデータ形式をサポートするようにシステムが改善されましたが、それ以外はVoltaと同じように機能しました。

今年の初めに、AmpereアーキテクチャがA100データセンターGPUでデビューし、今回はNvidiaがパフォーマンスを改善し(64ではなく256 GEMM /サイクル)、新しいデータ形式を追加し、非常に高速なスパーステンソル(多数のマトリックスを含むマトリックス)を処理する機能を追加しました。ゼロ)。
プログラマーは、Volta、Turing、Ampereチップのテンソルコアに非常に簡単にアクセスできます。コードは、APIとドライバーにテンソルコアを使用するように指示するフラグを使用するだけでよく、データタイプはコアでサポートされている必要があり、マトリックスの寸法は8の倍数である必要があります。実行時これらの条件はすべて、機器によって処理されます。
それはすべて素晴らしいことですが、GEMMの処理においてTensorコアは通常のGPUコアよりもどれだけ優れていますか?
Voltaが発表されたとき、Anandtechは3枚のNvidiaカードで数学テストを実行しました。Pascalラインナップの中で最も強力な新しいVoltaと、古いMaxwellカードです。
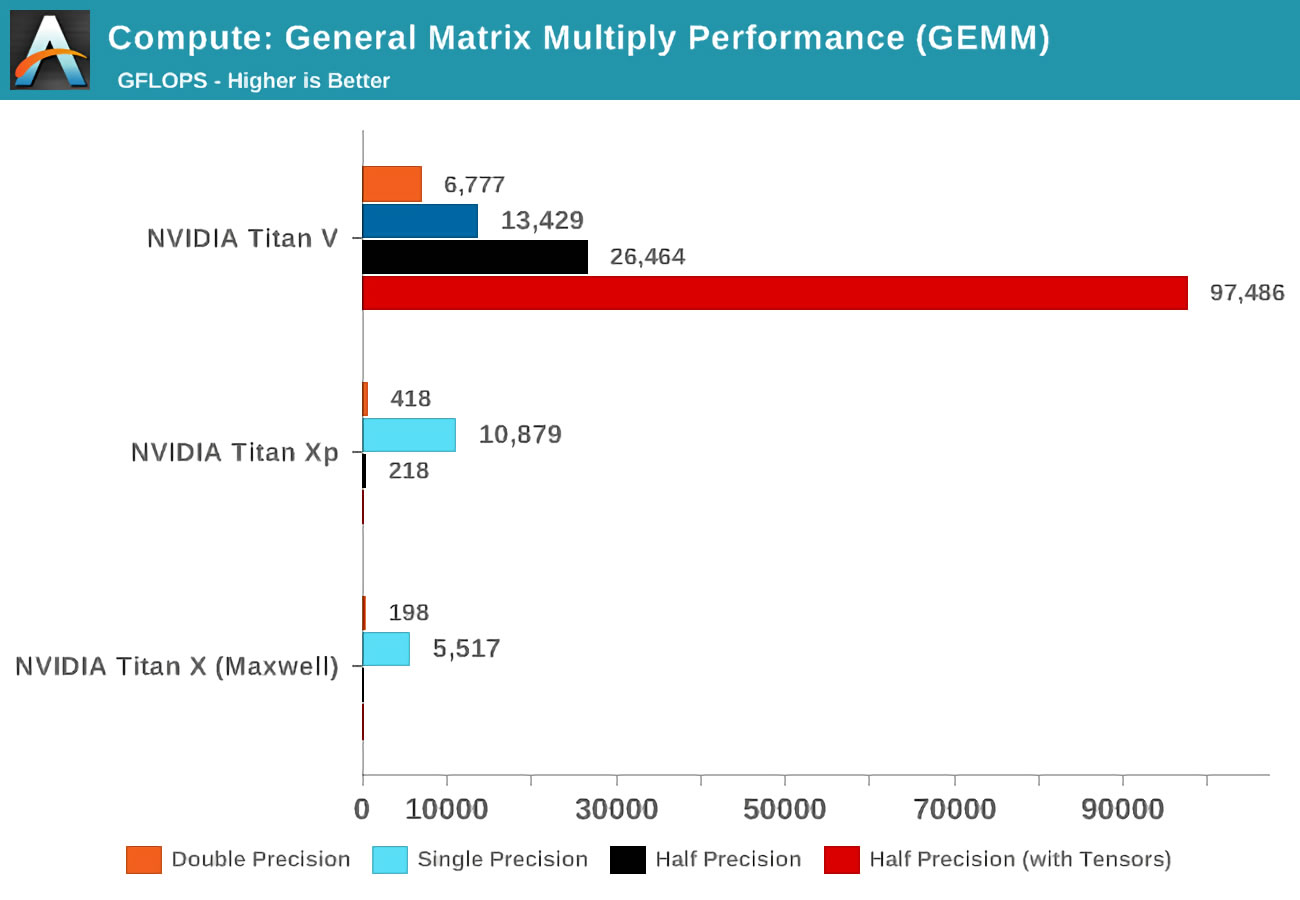
精度(精度) の概念は、マトリックス内の浮動小数点数に使用されるビット数を指します。double(double)は64、single(single)-32などを示します。横軸は、1秒あたりに実行される浮動小数点操作の最大数、または略してFLOPです(1つのGEMMは3つのFLOPであることに注意してください)。
いわゆるCUDAカーネルの代わりにテンソルカーネルを使用した場合の結果を見てください!明らかに、彼らはこの仕事で素晴らしいですが、テンソルカーネルで何ができるでしょうか?
すべてをより良くする数学
テンソルコンピューティングは、物理学と工学において非常に有用であり、流体力学、電磁気学、天体物理学におけるあらゆる種類の複雑な問題を解決するために使用されますが、そのような数を処理するために使用されたコンピューターは、通常、中央処理ユニットからの大きなクラスターのマトリックスに対して操作を実行しました。
テンサーが人気のあるもう1つの分野は、機械学習、特にそのサブセクション「深層学習」です。その意味は、ニューラルネットワークと呼ばれる巨大な配列で巨大なデータセットを処理することに要約されます。異なるデータ値間の接続には、特定の重み(特定の接続の重要性を表す数値)が割り当てられます。
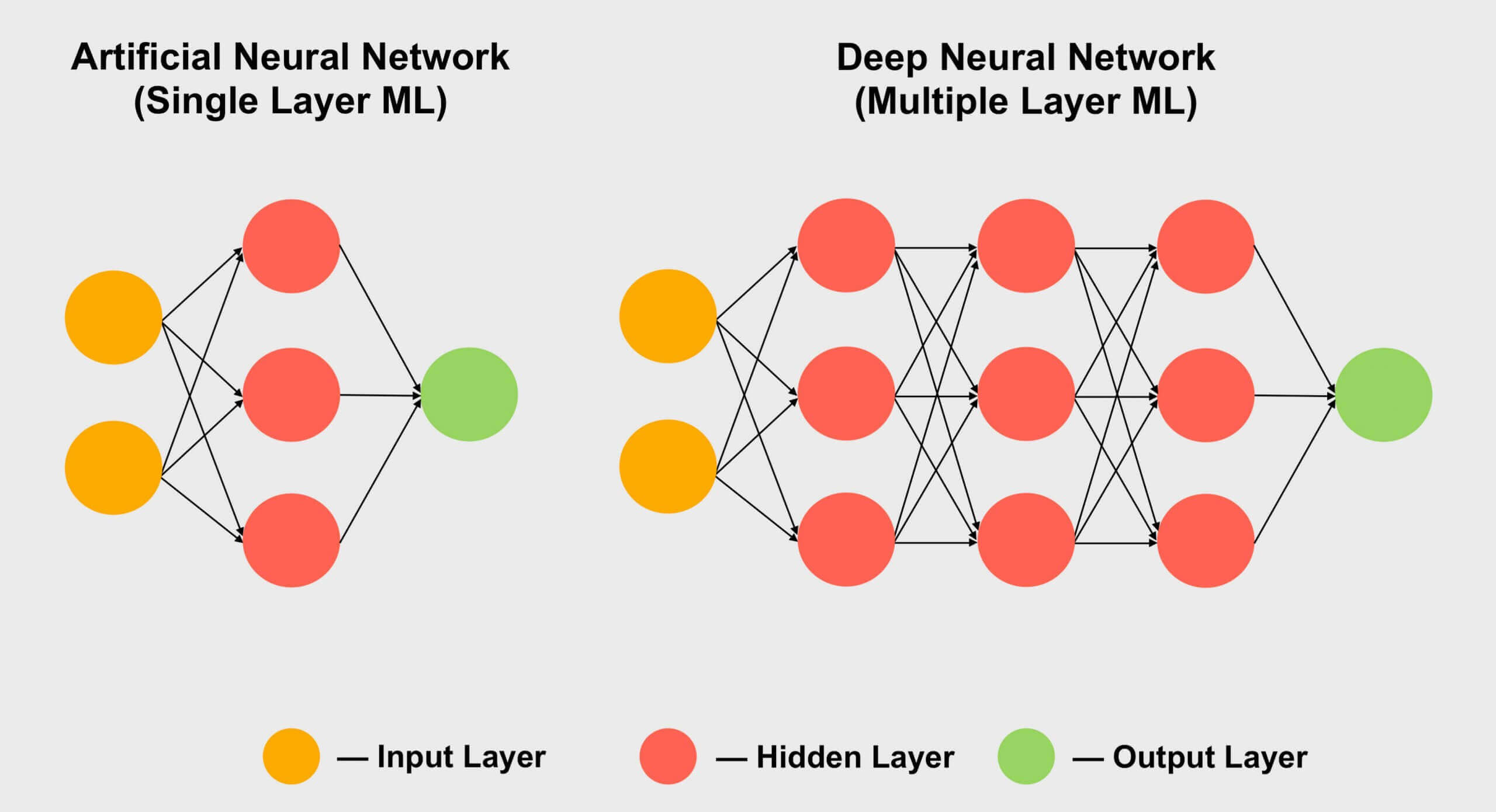
したがって、数千ではないにしても、これらの数百の接続がどのように相互作用するかを理解する必要がある場合、ネットワーク内のすべてのデータにすべての可能な接続の重みを掛ける必要があります。言い換えれば、古典的なテンソル数学である2つの行列を乗算します!

水冷式のGoogleTPU 3.0チップ
これが、すべての深層学習スーパーコンピューターがGPUを使用し、ほとんどの場合Nvidiaを使用する理由です。ただし、一部の企業は、テンソルコアから独自のプロセッサを開発しています。たとえば、Googleは2016年に最初のTPU(テンソル処理ユニット)の開発を発表しましたが、これらのチップは非常に特殊化されているため、マトリックスを使用した操作以外は何もできません。
コンシューマーGPUのテンソルコア(GeForce RTX)
しかし、リーマンの多様な問題を解決する天体物理学者や、畳み込み神経ネットワークの深さを実験する専門家でなくても、Nvidia GeForce RTXグラフィックカードを購入した場合はどうなりますか?テンソルカーネルを使用するにはどうすればよいですか?
多くの場合、これらは通常のビデオレンダリング、エンコード、またはデコードには適用されないため、役に立たない機能にお金を浪費しているように見える場合があります。ただし、Nvidiaは、DLSS(Deep Learning Super Sampling)を実装しながら、2018年に消費者向け製品にテンソルコアを組み込みました(Turing GeForce RTX)。

原理は単純です。フレームをかなり低い解像度でレンダリングし、完了後、最終結果の解像度を上げて、モニターの「ネイティブ」画面サイズに一致させます(たとえば、1080pでレンダリングしてから、1400pにサイズ変更します)。これにより、処理されるピクセルが少なくなり、画面が美しい画像を生成するため、パフォーマンスが向上します。
コンソールには何年もの間この機能があり、多くの最新のPCゲームもこの機能を提供しています。でアサシンクリード:オデッセイユービーアイソフトから、あなたは、モニタ解像度のわずか50%までレンダリング解像度を減らすことができます。残念ながら、結果はそれほどきれいに見えません。これは、最大のグラフィック設定を使用した4Kでのゲームの外観です。

より高い解像度では、テクスチャはより詳細を保持するため、よりきれいに見えます。ただし、これらのピクセルを画面に表示するには、多くの処理が必要です。次に、レンダリングが1080p(以前のピクセル数の25%)に設定されている場合に何が起こるかを見てみましょう。最後にあるシェーダーを使用して、画像を4Kに引き伸ばします。

jpegの圧縮により、すぐには違いが目立たない場合がありますが、キャラクターの鎧と遠くの岩がぼやけていることがわかります。画像の一部を拡大して詳しく見てみましょう。

左側の画像は4Kでレンダリングされています。右の画像は1080pを4Kに伸ばしたものです。すべての細部の柔らかさがすぐにぼやけた混乱に変わるので、違いは動きではるかに顕著です。グラフィックカードドライバのシャープネス効果により、シャープネスの一部を復元できますが、これを行う必要がまったくないことを願っています。
これがDLSSの出番です-最初のバージョンではこのテクノロジーNvidiaは、いくつかの選択されたゲームを分析しました。それらは、アンチエイリアシングの有無にかかわらず、高解像度、低解像度で実行されました。これらすべてのモードで、一連の画像が生成され、会社のスーパーコンピューターに読み込まれました。スーパーコンピューターは、ニューラルネットワークを使用して、1080p画像を理想的な高解像度画像に変換する最善の方法を決定しました。

DLSS 1.0は完璧ではなかったと言わざるを得ません。細部が失われることが多く、場所によっては奇妙なちらつきが見られました。さらに、グラフィックカードのテンソルコア自体を使用せず(Nvidiaネットワーク上で実行されました)、DLSS対応の各ゲームでは、アップスケーリングアルゴリズムを生成するために個別のNvidia調査が必要でした。

2020年の初めにバージョン2.0がリリースされたとき、大幅な改善が行われました。最も重要なことに、Nvidiaのスーパーコンピューターは現在、一般的なアップスケーリングアルゴリズムの作成にのみ使用されていました。新しいバージョンのDLSSは、レンダリングされたフレームのデータを使用して、ニューラルモデル(GPUテンソルコア)を使用してピクセルを処理します。

DLSS 2.0 の機能に感銘を受けましたが、これをサポートするゲームはこれまでのところほとんどありません。この記事の執筆時点では、12しかありませんでした。将来のゲームに実装したい開発者が増えています。
規模を拡大することで生産性を大幅に向上させることができるため、DLSSは進化し続けると確信できます。
DLSSの視覚的な結果は必ずしも完璧ではありませんが、レンダリングリソースを解放することで、開発者は視覚的な効果を追加したり、幅広いプラットフォームで1レベルのグラフィックスを提供したりできます。
たとえば、DLSSは、「RTX対応」ゲームでレイトレースとともにアドバタイズされることがよくあります。 GeForce RTXカードには、RTコアと呼ばれる追加の計算ブロックが含まれています。これは、光線と三角形の交差および境界ボリューム階層(BVH)のトラバースを加速するための特殊なロジックブロックです。これらの2つのプロセスは、光がシーン内の他のオブジェクトとどのように相互作用するかを決定する非常に時間のかかる手順です。
私たちが知ったように、レイトレースこれは非常に時間のかかるプロセスであるため、ゲームで許容可能なレベルのフレームレートを確保するには、開発者はシーンで実行される光線と反射の数を制限する必要があります。このプロセスでは粒子の粗い画像が作成される可能性があるため、ノイズ低減アルゴリズムを適用する必要があり、処理が複雑になります。テンソルカーネルは、AIを使用してノイズを除去することにより、このプロセスのパフォーマンスを向上させることが期待されますが、これはまだ実現されていません。ほとんどの最新のアプリケーションは、このタスクにCUDAカーネルを使用しています。一方、DLSS 2.0は非常に実用的なアップサイジング手法になりつつあるため、Tensorカーネルを効果的に使用して、シーン内のレイトレース後のフレームレートを上げることができます。
キャラクターアニメーションや組織シミュレーションの 改善など、GeForceRTXカードのテンソルコアを活用する他の計画があります。しかし、DLSS 1.0と同様に、GPUで特殊なマトリックスコンピューティングを使用するゲームが何百も存在するようになるまでには長い時間がかかります。
有望なスタート
したがって、状況は次のようになります。テンソルコア、優れたハードウェアユニットですが、一部のコンシューマーグレードのカードにのみ見られます。将来何か変わることはありますか? Nvidiaは、Ampereアーキテクチャの各Tensor Coreのパフォーマンスをすでに大幅に改善しているため、中低域モデルにもインストールされる可能性があります。
そのようなコアはまだAMDとIntelのGPUに含まれていませんが、おそらく将来的にはそれらが表示されるでしょう。 AMDには、パフォーマンスがわずかに低下する代わりに、完成したフレームの細部をシャープまたは強調するシステムがあります。そのため、特に開発者が統合する必要がないため、ドライバーで有効にするだけで十分です。
グラフィックチップのクリスタルのスペースは、追加のシェーダーコアに費やしたほうがよいという意見もあります。これは、NvidiaがTuringチップの予算バージョンを作成するときに行ったことです。GeForce GTX 1650などの製品では、同社はテンソルコアを完全に廃止し、追加のFP16シェーダーに置き換えました。
しかし今のところ、超高速のGEMM処理を提供してそれを最大限に活用したい場合は、2つのオプションがあります。巨大なマルチコアCPUを多数購入するか、テンソルコアを備えたGPUを1つだけ購入します。
参照: