
データサイエンスの実際の問題についてのメモのサイクルを続けて、今日は生きている問題に対処し、その過程でどのような問題が私たちを待っているかを見ていきます。
たとえば、データサイエンスに加えて、私は長い間陸上競技が好きで、もちろん、私のために走ることの目標の1つはマラソンです。そして、マラソンはどこにあり、問題は-どれだけ走るか?多くの場合、この質問への答えは目で与えられます-「まあ、平均して、彼らは走ります」または「これは良い時間です」!
そして今日、私たちは重要な問題を取り上げます-私たちは実際の生活にデータサイエンスを適用し、質問に答えます:
モスクワマラソンに関するデータは私たちに何を教えていますか?
より正確には、最初の表からすでに明らかなように、データを収集し、誰がどのように実行したかを把握します。同時に、それは私たちが干渉すべきかどうかを理解し、私たちの強みを賢明に評価できるようにするのに役立ちます!
TL; DR:2018/2019のモスクワマラソンレースに関するデータを収集し、参加者の時間とパフォーマンスを分析し、コードとデータを公開しました。
データ収集
クイックグーグルを通じて、過去数年間、2019年と2018年の結果を見つけました。
Webページを注意深く調べたところ、データを取得するのは非常に簡単であることが明らかになりました。たとえば、結果のクラス「results-table__col-result」など、どのクラスが何を担当しているかを把握する必要があります。
そこからすべてのデータを取得する方法を理解することは残っています。
そして、これは難しいことではありません。直接のページネーションがあり、実際には数値のセグメント全体を反復処理するからです。ビンゴ、私は2019年と2018年に収集したデータをここに投稿します。誰かがさらに分析に興味がある場合は、データ自体をここにダウンロードできます:こことここ。
私は何をいじくり回さなければなりませんでしたか?
- — - , , - (, ).
- - , — « ».
- Url- — - , url — , — .
- — — 2016, 2017… , 2019 — , — , — , , .
- NA: DNF, DQ, "-" — , , .
- データタイプ:ここでの時間はタイムデルタですが、再起動と無効な値のために、フィルターを操作して時間値をクリアする必要があります。これにより、純粋な時間の結果を操作して平均を計算します-ここでのすべての結果は、終了した人と有効な時間を持っている人。
そして、誰かが興味深い実行データを収集し続けることにした場合のスポイラーコードは次のとおりです。
パーサーコード
from bs4 import BeautifulSoup
import requests
from tqdm import tqdm
def main():
for year in [2018]:
print(f"processing year: {year}")
crawl_year(year)
def crawl_year(year):
outfilename = f"results_{year}.txt"
with open(outfilename, "a") as fout:
print("name,result,place,country,category", file=fout)
# parametorize year
for i in tqdm(range(1, 1100)):
url = f"https://results.runc.run/event/absolute_moscow_marathon_2018/finishers/distance/1/page/{i}/"
html = requests.get(url)
soup = BeautifulSoup(html.text)
names = list(
map(
lambda x: x.text.strip(),
soup.find_all("div", {"class": "results-table__values-item-name"}),
)
)
results = list(
map(
lambda x: x.text.strip(),
soup.find_all("div", {"class": "results-table__col-result"}),
)
)[1:]
categories = list(
map(
lambda x: x.text.strip().replace(" ",""),
soup.find_all("div", {"class": "results-table__values-item-country"}),
)
)
places = list(
map(
lambda x: x.text.strip(),
soup.find_all("div", {"class": "results-table__col-place"}),
)
)[1:]
for name, result, place, category in zip(names, results, places, categories):
with open(outfilename, "a") as fout:
print(name, result, place, category, sep=",", file=fout)
if __name__ == "__main__":
main()
```
時間と結果の分析
データと実際のレース結果の分析に移りましょう。
使用済みのパンダ、numpy、matplotlib、seaborn-すべてクラシックです。
すべてのアレイの平均値に加えて、次のグループを個別に検討します:
- 男性-私はこのグループに属しているので、これらの結果は私にとって興味深いものです。
- 女性は対称性のためです。
- 35 — «» , — .
- 2018 2019 — ?.
まず、下の表をざっと見てみましょう。スクロールしないように、ここでも参加者が増えています。平均して95%がフィニッシュラインに到達し、参加者のほとんどは男性です。さて、これは平均して私がメイングループに属していることを意味し、平均してデータは私にとって平均時間をよく表しているはずです。続けましょう。
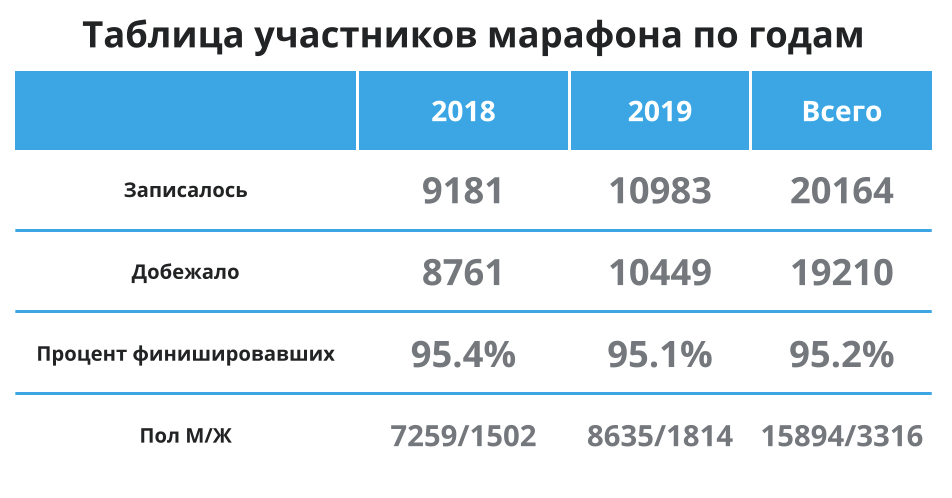

ご覧のとおり、2018年と2019年の平均は実質的に変化していません。2019年のランナーの方が約1.5分速かったです。私が興味を持っているグループ間の違いはごくわずかです。
全体としてのディストリビューションに移りましょう。そして、最初にレースの合計時間。
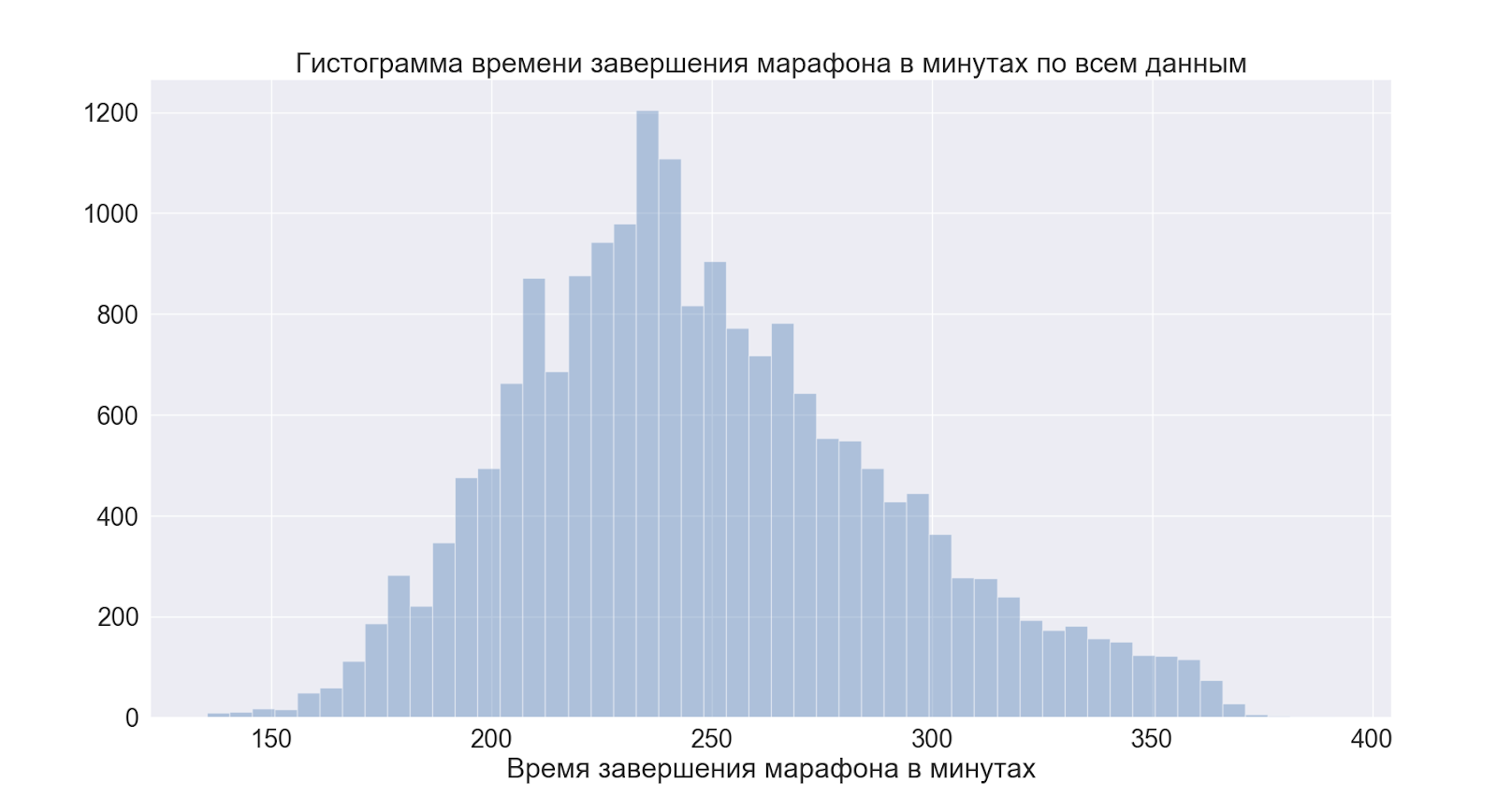
4時の直前にピークが見られるように、これはうまく走りたい人のための条件付きマークです= 4時を使い果たして、データは人気のある噂を裏付けています。
次に、1年間で平均して状況がどのように変化したかを見てみましょう。
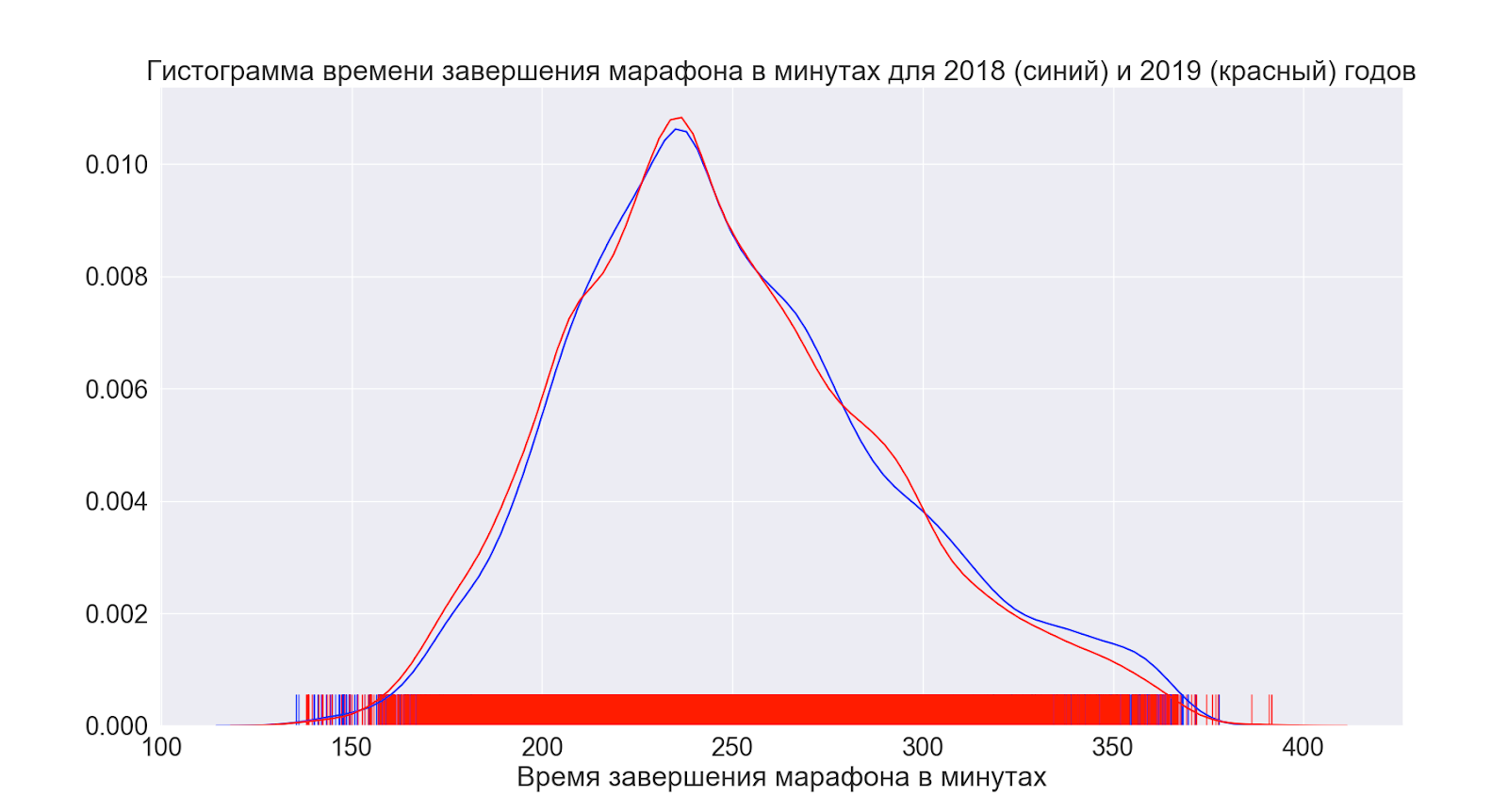
ご覧のとおり、実際には何も変更されていません。分布は実質的に同じように見えます。
次に、性別による分布を考えます

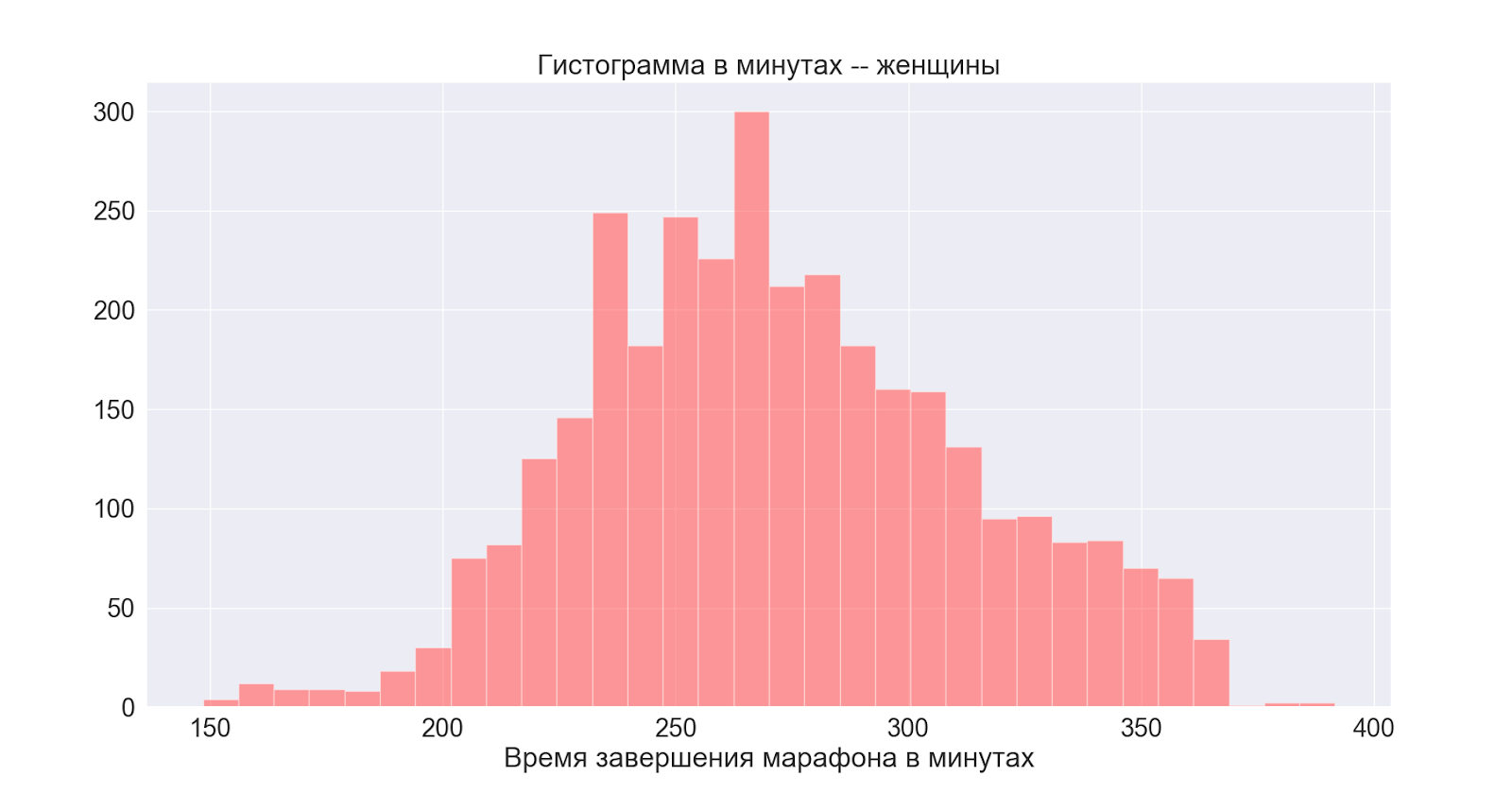
。一般に、両方の分布はわずかに異なる中心で正常です。男性のピークもメイン(一般)分布に現れていることがわかります。
それとは別に、私にとって最も興味深いグループに移りましょう。
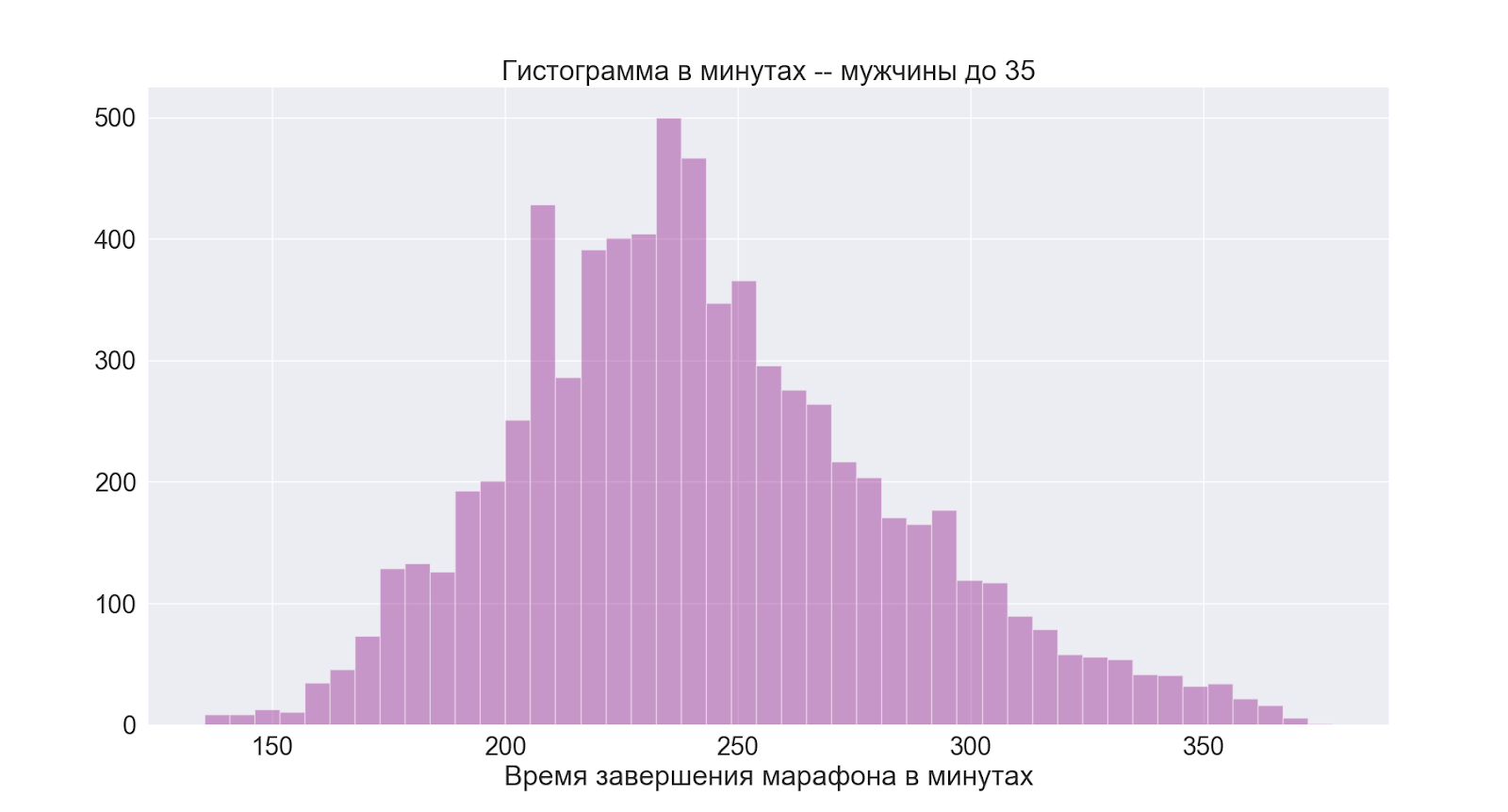
ご覧のとおり、写真は基本的に男性グループ全体と同じです。
このことから、4時間も私にとって良い平均時間であると結論付けます。
参加者の改善を研究する2018→2019
興味深いことに、何らかの理由で、今はすぐにデータを収集し、分析をさらに深く掘り下げて、そこで何時間もパターンを探すことができると思いました。逆に、データの収集は分析自体よりも難しいことが判明しました。古典によれば、ネットワークの操作、生データ、クリーニング、フォーマット、キャストなどは、分析と視覚化よりもはるかに時間がかかりました。ささいなことには少し時間がかかることを忘れないでください-しかし、それらのかなりの数[ささいなこと]があり、最終的にはあなたの夜全体を食い尽くします。
それとは別に、両方の時間に参加した人々がどのように結果を改善したかを知りたかったのですが、年ごとのデータを比較することで、次のことを確認できました。
- 14人が両方の年に参加し、決して終わっていません
- 89人が18mで走ったが、19で失敗した
- 124その逆
- 平均して両方の時間を実行できた人は、結果を4分改善しました
しかし、ここではすべてが非常に興味深いことが判明しました。
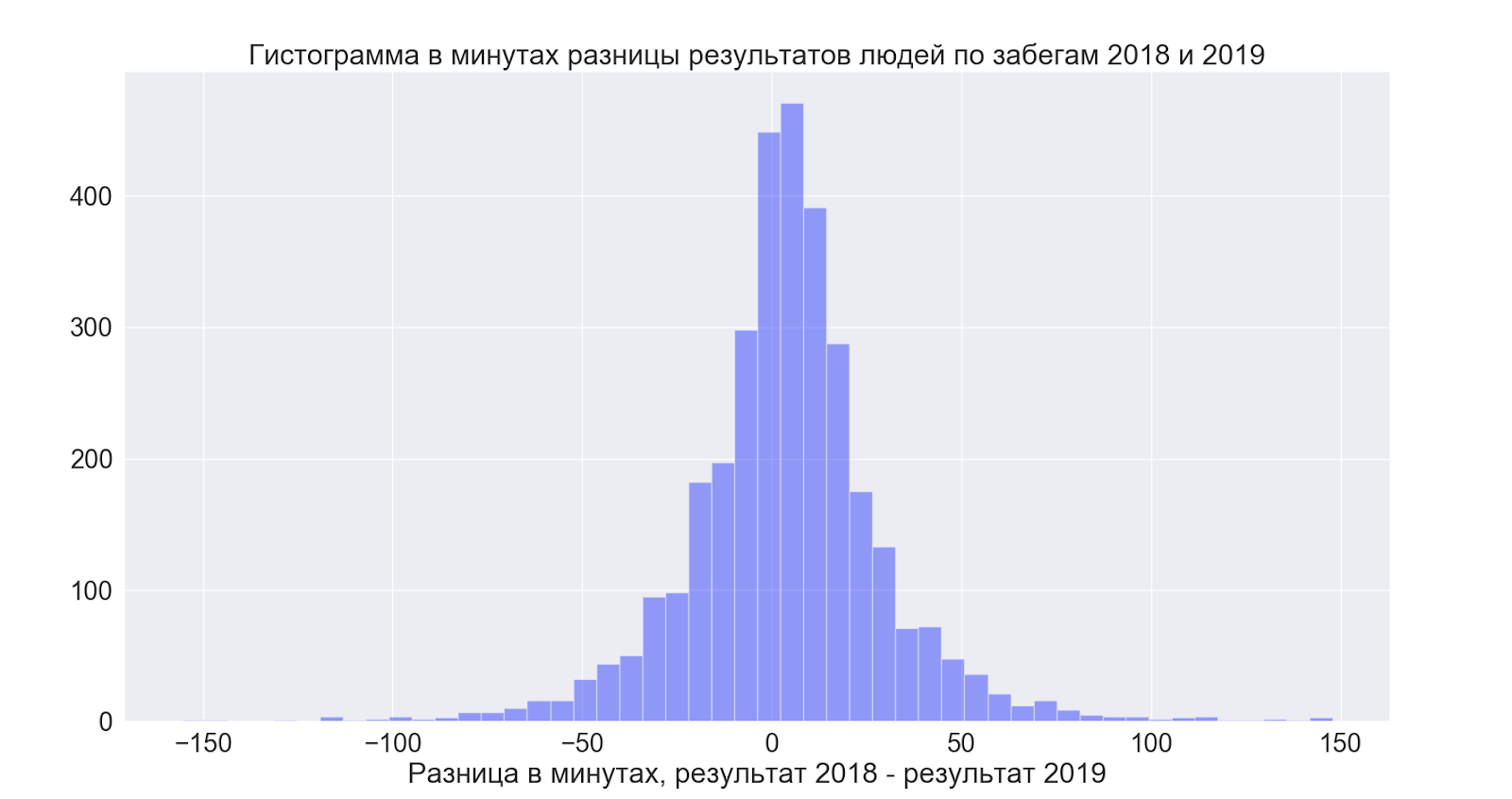
つまり、平均して、人々は結果をわずかに改善します-しかし、一般的に、広がりは信じられないほどであり、両方向で-つまり、それがより良くなることを期待するのは良いことです-しかし、データから判断すると、一般的にあなたが好きなようになります!
結論
分析したデータから、私は自分自身のために次の結論を出しました。
- 全体として、4時間は良い平均目標です。
- ランナーのメイングループはすでに非常に競争の激しい年齢になっています(そして私と同じグループにいます)。
- 平均して、人々は結果をわずかに改善しますが、一般的に、データから判断すると、どのようにしてそこに到達するかを示します。
- レース全体の平均結果は、両方の年でほぼ同じです。
- ソファからマラソンについて話すのはとても快適です。
