次に、受信したデータを操作するロジックを記述し、特定の状況でルールが機能するかどうかを判断する方法を学ぶ必要があります。この記事で取り上げるのは、ルールのこのセクションとその機能です。検出ロジックセクションの説明は、構文の最も重要な部分であり、既存のルールを理解して独自のルールを作成するには、その知識が必要です。
では次の出版物、私たちは、ルールのコレクション(このような記述または識別子として有益なまたは自然の中でインフラある属性、)メタ情報の記述に住むます。私たちの出版物に従ってください!
検出ロジックの説明(検出属性)
ルールのトリガー条件は、検出属性で設定されます。そのサブフィールドは、ルールの主要な技術的部分を説明します。ルールには、1つの記述部分と、複数のログソースおよび検出のみを含めることができることに注意することが重要です。検出セクションはソースセクションからのデータに基づいてトリガー基準を記述するため、これら2つのセクションは1から1になります。
一般に、検出フィールドのコンテンツは2つの論理部分で構成されます。
- イベントフィールド(検索ID)に関する仮定の説明、
- これらの記述間の論理関係(時間枠と条件フィールドの式)。

イベントフィールドの内容に関する仮定の説明は、検索識別子を指定することによって行われます。このような識別子は、(のようにいずれかになります。ここでは)または(としてそれらのいくつかがあることができ、ここで)。
2番目の部分には、次の3つのタイプがあります。
- 通常の状態、
- (上記の例のように)集計式を使用する条件、
- キーワードnearの条件。
各部分の要素の構文は、この記事の対応するセクションで説明されています。
検索ID
検索識別子はキーと値のペアです。ここで、キーは検索識別子の名前であり、値はリストまたは辞書(別名連想配列)です。プログラミング言語との類推によって-リストまたはマップ。リストと辞書を指定するための形式は、YAML標準によって定義されています。YAML標準はここにあります。シグマルール形式では検索識別子の名前が修正されないことは注目に値しますが、ほとんどの場合、単語の選択によってバリエーションを見つけることができます。
リストアイテムとボキャブラリーアイテムの両方に適用される一般的な要件があります。
- すべての値は大文字と小文字を区別しない文字列として扱われます。つまり、大文字と小文字の間に違いはありません。
- (wildcards) ‘*’ ‘?’. ‘*’ — ( ), ‘?’ — ( ).
- ‘\’, ‘\*’. , : ‘\\*’. .
- , .
- ‘ .
値の
リスト検索識別子値のリストには、イベントメッセージ全体で検索される文字列が含まれています。リストの要素は論理ORと組み合わされます。
detection:
keywords:
- EVILSERVICE
- svchost.exe -n evil
condition: keywords

値のリストとして検索識別子を含むルールの例:
- rules / web / web_apache_segfault.yml(リストには1つの要素を含めることができます)
- ルール/ウィンドウ/パワーシェル/powershell_clear_powershell_history.yml
- ルール/ linux / lnx_shell_susp_log_entries.yml
辞書検索識別子
辞書は、キーと値のペアのセットで構成されます。キーはイベントのフィールドの名前であり、値は文字列、整数、またはこれらのタイプのいずれかのリストです(文字列または数値のリストは論理ORと組み合わされます)。辞書のセットは論理ANDで結合されます。
一般的なスキーム:
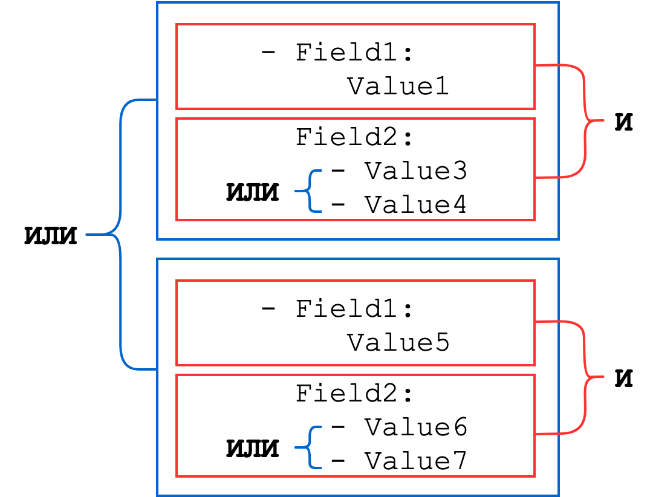
いくつかの例を考えてみましょう。
例1.イベントログクリーンアップ検出ルール
ルール/ウィンドウ/組み込み/win_susp_security_eventlog_cleared.yml
このルールは、イベントが次の条件を満たしている場合にトリガーされます
。EventID= 517 または EventID = 1102
ルールでは、次のようになります。
detection:
selection:
EventID:
- 517
- 1102
condition: selection ここで、selectionは唯一の検索識別子の名前であり、残りのサブフィールドはその値であり、この値は「dictionary」タイプです。この辞書では、EventIDがキーであり、番号517と1102がリストを形成します。これは、この辞書キーの値です。
例2.疑わしいチケットリクエスト。おそらくKerberoasting
ルール/ウィンドウ/ビルトイン/win_susp_rc4_kerberos.yml
イベントの条件を満たしている場合、このルールがトリガされます:
イベントID = 4679 AND TicketOptions = 0x40810000とTicketEncryption = 0x17のAND ServiceNameには、「$」記号で終わっていない
ルールには、それは次のようになります。
detection:
selection:
EventID: 4769
TicketOptions: '0x40810000'
TicketEncryption: '0x17'
reduction:
- ServiceName: '*$'
condition: selection and not reduction 特別なフィールド値
使用できる2つの特別なフィールド値があります:
- 2つの一重引用符で指定された空の値 ''
- nullキーワードで指定されたnull値
注:空でない値は、notnull構文を介して指定することはできません
これらの値の適用は、ターゲットSIEMシステムによって異なります。null以外の条件を説明するには、値が空の別の検索IDを作成し、そこから条件の否定を取得する必要があります(条件フィールド、記事の最後に説明されています)。空のフィールドの説明を使用するルールの例をさらに検討してください。
例3.リモートストリーム ルール/ windows / sysmon /sysmon_password_dumper_lsass.ymlの不審な起動
イベントが次の条件を満たしている場合、指定されたルールがトリガーされます
。EventID= 8 AND TargetImage = 'C:\ Windows \ System32 \ lsass.exe' AND StartModuleは空のフィールドです
ルールでは、次のようになります。
detection:
selection:
EventID: 8
TargetImage: 'C:\Windows\System32\lsass.exe'
StartModule: null
condition: selection 例4.実行可能ファイルを代替ファイルストリームに書き込むNTFS
ルール/ windows / sysmon / sysmon_ads_executable.yml
考慮されるルールは、空でない値の正しい指定の例です。このルールは、イベントが次の条件を満たす場合にトリガーされます
。EventID= 15 AND I
mphash != '00000000000000000000000000000000' Imphash
ルールでは、次のようになります。
detection:
selection:
EventID: 15
filter:
Imphash:
- '00000000000000000000000000000000'
- null
condition: selection and not filter 上記のように、ネゲーションは、検索識別子ではなく、条件(条件フィールド)に配置する必要があります。
値修飾子
ルール内のフィールド値の解釈は、修飾子を使用して変更できます。フィールド名の後に修飾子が追加され、各修飾子の前に垂直バー(パイプ)-「|」が付きます。それらをチェーン化して、修飾子のチェーン(パイプライン)を構築できます

。フィールド値は、チェーン内の修飾子の順序に従って変更されます。修飾子には、変換修飾子とタイプ修飾子の2つのタイプがあります。
変換修飾子は、元のフィールド値を他の値に変換するもの、または検索識別子の値のリストを処理するためのロジックを変換するものです。最初のタイプの例はBase64修飾子で、2番目のタイプはall修飾子です。すべての修飾子については、後で詳しく説明します。
それぞれの変換修飾子を見てみましょう。わかりやすくするために、これまたはその修飾子が初期値をどのように正確に変更するかを概略的に示します。
で始まる
startwith 修飾子は、文字列の先頭を目的の値と一致させるために使用されます。

使用例:
- ルール/ウィンドウ/組み込み/win_ad_replication_non_machine_account.yml
- ルール/ウィンドウ/ process_creation / win_apt_winnti_mal_hk_jan20.yml
- ルール/ウィンドウ/パワーシェル/powershell_downgrade_attack.yml
で終わる
extendswith 修飾子は、文字列の終わりを検索値と照合するために使用されます。

使用例:
- ルール/ウィンドウ/ process_creation / win_local_system_owner_account_discovery.yml
- ルール/ウィンドウ/ sysmon / sysmon_minidumwritedump_lsass.yml
- ルール/ウィンドウ/ process_creation / win_susp_odbcconf.yml
含まれています
contains 修飾子は、フィールド値でのサブストリングの出現をチェックします。実際、この修飾子はフィールド値を次のように変換します。

つまり、考慮された修飾子を適用した結果を検討する場合、次の式を記述できます
。startswith+ extendswith = contains
例:
- ルール/ウィンドウ/ process_creation / win_hack_bloodhound.yml
- ルール/ウィンドウ/ process_creation / win_mimikatz_command_line.yml
- ルール/ウィンドウ/ sysmon / sysmon_webshell_creation_detect.yml
すべて
通常、シート要素は論理ORと組み合わされます。all修飾子は、論理ORを論理ANDに変更します。つまり、リストのすべての要素が存在する必要があります。セクションの冒頭にあった一般的なスキームで条件がどのように変化するかを見てみましょう。ご覧の
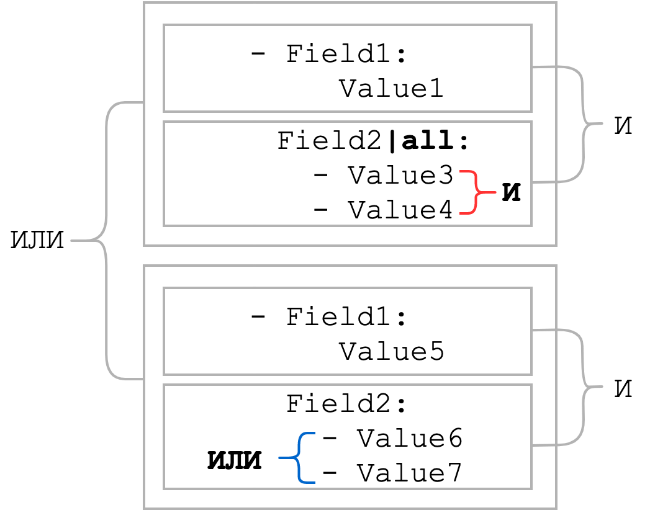
とおり、all修飾子が適用されると、リストアイテム間の論理接続はANDになりました。通常、all修飾子はcontains修飾子と組み合わせて使用されます。このような束は、静的パーツの順序が不明な場合に、ワイルドカードメタ文字を使用したパターンの代わりに使用できます。all
修飾子の使用例:
- ルール/ウィンドウ/組み込み/win_meterpreter_or_cobaltstrike_getsystem_service_installation.yml
- ルール/ウィンドウ/パワーシェル/powershell_suspicious_profile_create.yml
- ルール/ウィンドウ/パワーシェル/powershell_suspicious_download.yml
base64
この修飾子は、フィールド値がBase64でエンコードされている場合に適用されます。わかりやすくするために、結果のBase64文字列ではなく、エンコードされたテキストをルールに書き込みます。

この修飾子は、フィールドがエンコードされた文字列と完全に一致することを前提としています。通常、エンコードされた結果と完全に一致するものを探すよりも、元のデータで疑わしいアクティビティの兆候を特定する方が便利です。したがって、base64修飾子を使用する例はまだありません。
base64offset
Base64エンコーディングの性質上、base64からのパイプラインを使用することはできず、containsを使用してエンコードされたサブストリングを検索できます。base64offset修飾子は、まさにこの目的のために作成されました。これは、文字列がBase64でエンコードされていて、エンコードされた文字列のサブ文字列を検索する場合に使用されます。さらに、目的のサブストリングを囲む文字は事前に不明であり、ストリングの先頭に対するサブストリングのオフセットは不明です。ここで何が問題になっているのかがはっきりとわかります。
ほとんど常に、この修飾子を一緒に使用されている含まれてい修飾子:

使用例:
- ルール/ウィンドウ/ process_creation / win_encoded_frombase64string.yml
- ルール/ウィンドウ/ process_creation / win_encoded_iex.yml
重要!次の3つのエンコーディング変換修飾子は、Base64修飾子と組み合わせてのみ使用されます。
utf16leまたはワイド
utf16leおよびwide 修飾子は同義語です。フィールドの文字列値をUTF-16LEエンコーディング、つまりに変換します
“123” -> 0x31 0x00 0x32 0x00 0x33 0x00。

utf16be
utf16be 修飾子は、フィールドの文字列値をUTF-16BE、つまりに変換します
“123” -> 0x00 0x31 0x00 0x32 0x00 0x33。

utf16
修飾子utf16は、バイトオーダーマーク(BOM)を追加し、UTF-16で文字列をエンコードします
“123” -> 0xFF 0xFE 0x31 0x00 0x32 0x00 0x33 0x00。現在、

タイプ修飾子は1つだけです-re。
再
このタイプ修飾子は、フィールド値を通常の式パターンとして解釈します。これまでのところ、Elasticsearchクエリへのコンバーターによってのみサポートされているため、実際にはパブリックルールには表示されません。
使用例:
- ルール/ウィンドウ/ process_creation / win_invoke_obfuscation_obfuscated_iex_commandline.yml
- ルール/ウィンドウ/組み込み/win_invoke_obfuscation_obfuscated_iex_services.yml
- ルール/ウィンドウ/組み込み/win_mal_creddumper.yml
時間間隔(時間枠属性)
さらに、検索識別子が表示される時間間隔を指定することにより、検出ロジックを改良できます。標準の略語は、時間単位を示すために使用されます。
15s (15 )
30m (30 )
12h (12 )
7d (7 )
3M (3 ) 使用例:
- ルール/ linux / modsecurity / modsec_mulitple_blocks.yml
- ルール-サポートされていません/net_possible_dns_rebinding.yml
- ルール/ウィンドウ/組み込み/win_rare_service_installs.yml
ルールトリガー条件の説明(条件属性)
シグマの公式ドキュメントによると、ルールのトリガー条件の部分は最も複雑で、時間の経過とともに変化します。現在、以下の式が利用可能です。
論理演算AND、OR
それらは、それぞれキーワードandおよびorで示されます。これらの式は、検索識別子間の論理関係を構築するための主要な要素です。
detection:
keywords1:
- EVILSERVICE
- svchost.exe -n evil
keywords2:
- SERVICEEVIL
- svchost.exe -n live
condition: keywords1 or keywords2 使用例:
検索ID値の1つ/すべての検索ID値(1 /すべての検索識別子)
前の場合と同じですが、検索IDの場合
- 1-選択肢間の論理OR、
- すべて-選択肢の中で論理的かつかつ。
デフォルトで
condition: keywordsは、キーワード識別子にリストされている値は論理ORです。つまり、これは書き込みと同じcondition: 1 of keywordsです。値を論理ANDと組み合わせる場合は、を記述する必要がありますcondition: all of keywords。
使用例:
与えられたすべての検索IDの中 で、検索IDの1つ/すべての検索ID(1 /すべて)論理OR(1つ)または論理AND(すべて)。デフォルトでは、検索IDは、辞書の要素である場合は論理ANDでリンクされ、リストの要素である場合は論理ORでリンクされます。これらの関係を変更するために、この構造が作成されました。したがって、条件、条件:1は、少なくとも1つの検索識別子がイベントに表示される必要があることを意味します。
使用例:
- ルール/ウィンドウ/ process_creation / win_hack_bloodhound.yml
- ルール/ウィンドウ/パワーシェル/powershell_psattack.yml
- ルール/クラウド/aws_ec2_download_userdata.yml
名前パターンに一致する検索IDの1つ/名前パターンに一致するすべての検索ID(1 /すべてのsearch-identifier-pattern)
前の段落と同じですが、選択は名前がパターンに一致する検索識別子に制限されます。このようなパターンは、名前パターンの特定の位置にワイルドカード*(任意の数の文字)を使用して作成されます。
構文は次のとおりです。
condition: 1 of selection*
condition: all of selection* 使用例:
- ルール/ウィンドウ/組み込み/win_user_added_to_local_administrators.yml
- ルール/ウィンドウ/ process_creation / win_susp_eventlog_clear.yml
- ルール/クラウド/aws_iam_backdoor_users_keys.yml
論理的否定
論理ネガティブは、notキーワードを使用して作成されます。上記のように、「空ではない」という表現は、検索IDの説明ではなく、条件フィールドで指定する必要があります。次の例は、「フィールド値が空ではありません」という表現の説明の正しいバージョンを明確に示しています。

使用例:
- ルール/ウィンドウ/ sysmon / sysmon_malware_backconnect_ports.yml
- ルール/ウィンドウ/ process_creation / win_apt_gallium.yml
パイプ
垂直バー(またはパイプ)は、式の結果が集計関数に渡されることを示し、その結果はある値と比較される可能性があります。
一般的なスキーム:
_ | _
condition: selection | count(category) by dst_ip > 30 使用例:
- ルール/ウィンドウ/組み込み/win_susp_failed_logons_single_source.yml
- ルール/ウィンドウ/その他/win_rare_schtask_creation.yml
- ルール/ネットワーク/net_high_dns_requests_rate.yml
括弧
括弧は部分式を指定するために使用されます。これは、論理式が評価される順序を指定したり、複数の式を含む述語を否定したりする場合に役立ちます。それらは操作の最優先事項です。
condition: selection and (keywords1 or keywords2)
condition: selection and not (filter1 or filter2) 使用例:
集計関数式
集計式(または集計関数式)は、発生したイベントを定量化するために使用されます。
集計式スキーマ:カウント

を除くすべての集計関数には、パラメーターとしてフィールド名が必要です。count関数は、フィールド名が指定されていない場合、一致するすべてのイベントをカウントします。フィールド名が指定されている場合、関数はこのフィールドのさまざまな値をカウントします。たとえば、次の式は、1つのIPアドレスから接続が確立されたさまざまなポートの数をカウントし、この数が10を超えると、ルールがトリガーされます。
condition: selection | count(dst_port) by src_ip > 10 使用例:
- ルール/ linux / lnx_susp_failed_logons_single_source.yml
- ルール/ウィンドウ/その他/win_rare_schtask_creation.yml
- ルール/ネットワーク/net_susp_network_scan.yml
近くの集約式
near キーワードは、最初のIDを見つけた後、指定された時間間隔内に指定されたすべての検索IDの出現を認識するクエリを生成するために使用されます(この機能がターゲットシステムとバックエンドでサポートされている場合)。
一般的なスキーマ:
near search-id-1 [ [ and search-id-2 | and not search-id-3 ] ... ]
構文例:
timeframe: 30s
condition: selector | near dllload1 and dllload2 and not exclusion 縦棒の前の検索式と同じ規則が 、単語の近くの検索式にも適用されます。これについては、上記で詳しく説明しました。
使用例:
操作のデフォルトの優先順位は次のとおりです。
- (表現)
- 検索パターンのX
- ない
- そして
- または
- |
したがって、括弧の優先度が最も高く、パイプの優先度が最も低くなります。
注:複数の条件フィールドが指定されている場合、最終値は、すべての式の値に論理ORを適用することによって取得されます。
この記事では、検出ロジックについて説明しました。私たちの投稿に従ってください。次の記事では、ルールの残りのフィールドを見ていきます。それらのほとんどは、情報またはインフラストラクチャの性質のものです。メタ情報のあるフィールドに加えて、ルールコレクションと呼ばれるルールの構成のこのような機能について詳しく見ていきましょう。YAML言語の複雑さに精通していない人にとって、構文のこの側面を考慮することは、見知らぬ人を読んだり、独自のルールを書いたりするときに役立ちます。
著者:Anton Kutepov、専門家サービス部門およびポジティブテクノロジー開発のスペシャリスト(PTエキスパートセキュリティセンター)