まず、グラフをトラバースする方法を簡単に理解し、実際のパスファインディングを記述してから、パフォーマンスとメモリコストの最適化という最もおいしい方法に進みます。理想的には、使用時にガベージをまったく生成しない実装を開発する必要があります。
表面的な検索では、サードパーティのライブラリを使用せずにC#でA *アルゴリズムの優れた実装が1つも得られなかったので、驚きました(これは、何もないという意味ではありません)。さあ、指を伸ばしましょう!
パスファインディングアルゴリズムの作業を理解したい読者と、アルゴリズムの専門家がその最適化の実装と方法に精通するのを待っています。
始めましょう!
歴史への遠足
2次元メッシュは、各頂点に8つのエッジがあるグラフとして表すことができ
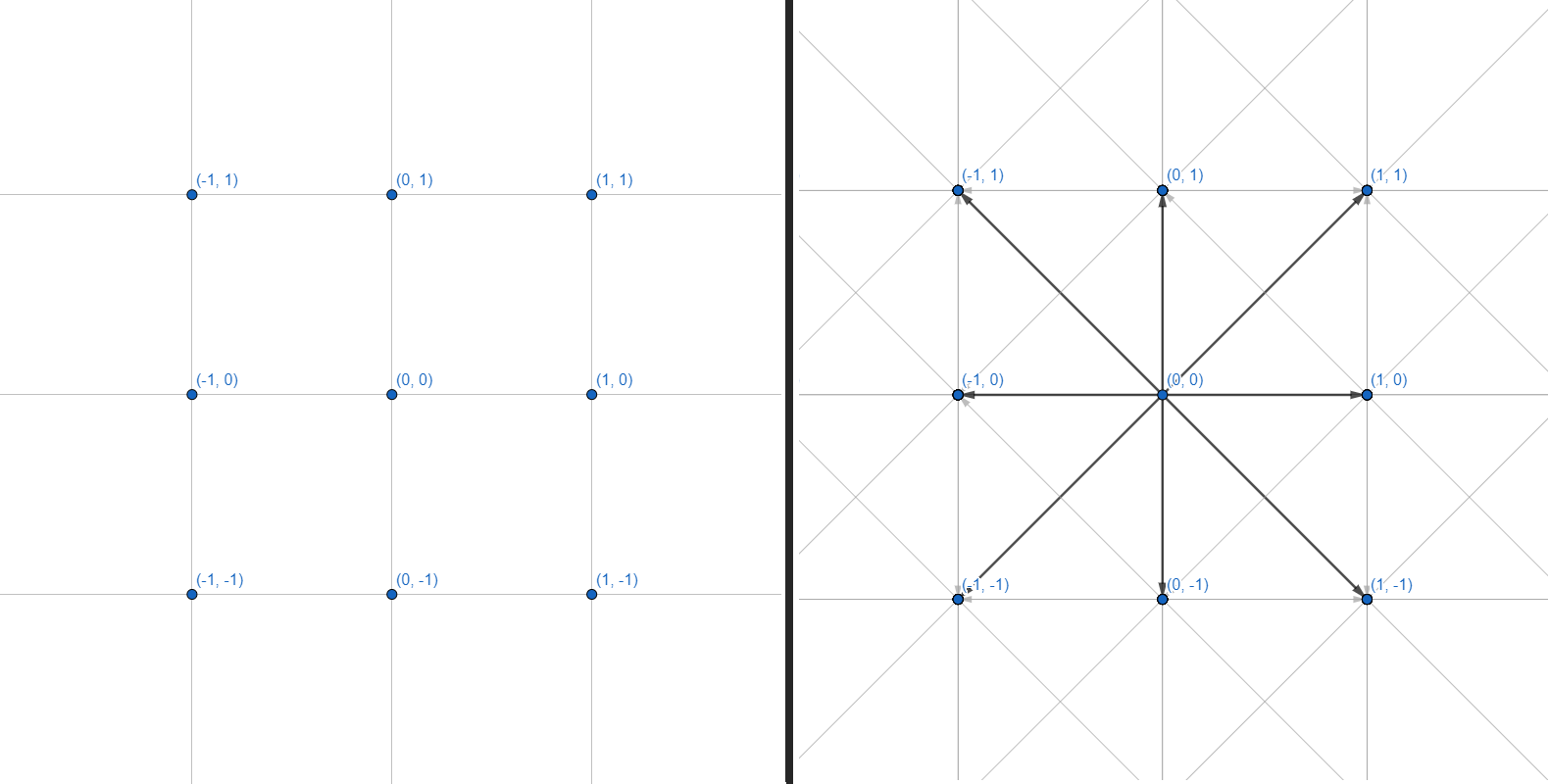
ます。グラフを使用します。各頂点は整数座標です。各エッジは、隣接する座標間の直線または斜めの遷移です。座標のグリッドと障害物のジオメトリの計算は行いません。入力として複数の座標を受け入れ、パスを構築するための一連のポイントを返すインターフェイスに制限します。
public interface IPath
{
IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles);
}まず、グラフをトラバースするための既存の方法を検討します。
深さ検索
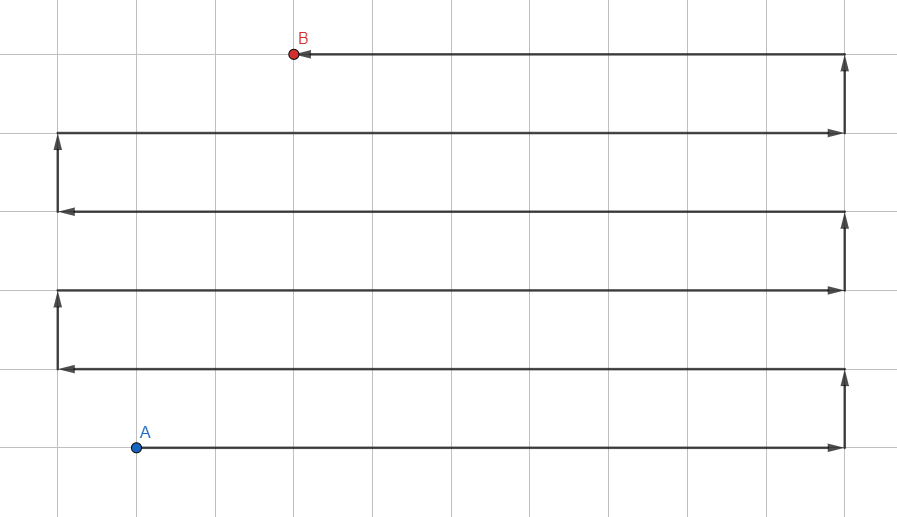
最も単純なアルゴリズム:
- 現在の頂点の近くにあるすべての未訪問の頂点をスタックに追加します。
- スタックから最初の頂点に移動します。
- 頂点が目的の頂点である場合は、サイクルを終了します。行き止まりになったら、戻ってください。
- ゴト1。
次のようになります。
, Node , .
private Node DFS(Node first, Node target)
{
List<Node> visited = new List<Node>();
Stack<Node> frontier = new Stack<Node>();
frontier.Push(first);
while (frontier.Count > 0)
{
var current = frontier.Pop();
visited.Add(current);
if (current == target)
return Node;
var neighbours = current.GenerateNeighbours();
foreach(var neighbour in neighbours)
if (!visited.Contains(neighbour))
frontier.Push(neighbour);
}
return default;
}, Node , .
LIFO(ラストイン-ファーストアウト)形式で構成され、新しく追加された頂点が最初に分析されます。遷移に沿って実際のパスを構築するには、頂点間の各遷移を監視する必要があります。
このアプローチは、グラフをランダムな方向に処理するため、(まあ、ほとんど)最短パスを返すことはありません。必要な頂点へのパスが少なくともある程度あるかどうか(たとえば、必要なリンクがテクノロジーツリーに存在するかどうか)を問題なく判断するには、小さなグラフに適しています。
ナビゲーショングリッドと無限のグラフの場合、この検索は無限に一方向に進み、コンピューティングリソースを浪費し、目的のポイントに到達することはありません。これは、アルゴリズムが動作する領域を制限することで解決されます。最初のポイントからNステップ以内にあるポイントのみを分析するようにします。したがって、アルゴリズムが領域の境界に達すると、展開され、指定された半径内の頂点の分析が続行されます。
面積を正確に決定できない場合もありますが、境界線をランダムに設定したくない場合があります。反復的な深さ優先の検索が助けになります:
- DFSの最小領域を設定します。
- 検索を開始。
- パスが見つからない場合は、検索領域を1つ増やします。
- GOTO2。
アルゴリズムは何度も何度も実行され、最終的に目的のポイントが見つかるまで、より広い領域をカバーします。
少し大きい半径でアルゴリズムを再実行するのはエネルギーの無駄のように思えるかもしれません(とにかく、ほとんどの領域は最後の反復ですでに分析されています!)、しかしいいえ:頂点間の遷移の数は半径が大きくなるたびに幾何学的に増加します。小さな半径に沿って数回歩くよりも、必要以上に大きな半径を取る方がはるかに費用がかかります。
このような検索では、タイマー制限を厳しくするのは簡単です。指定された時間が終了するまで、半径が拡大しているパスを正確に検索します。
幅の最初の検索
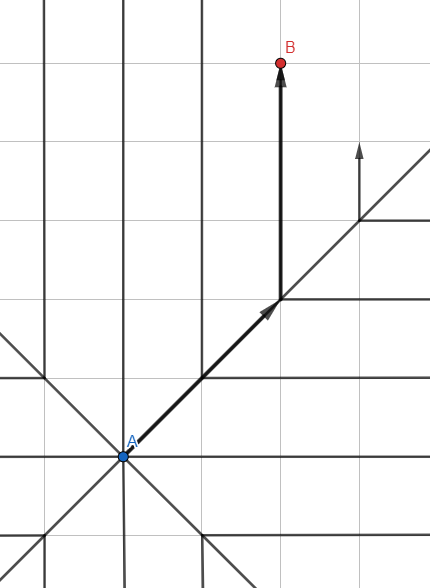
この図はジャンプ検索に似ている場合がありますが、これは通常のウェーブアルゴリズムであり、線は中間点が削除された検索伝播パスを表しています。
スタック(LIFO)を使用した深度優先検索とは対照的に、頂点を処理するためにキュー(FIFO)を取得しましょう。
- 訪問していないすべてのネイバーをキューに追加します。
- キューから最初の頂点に移動します。
- 頂点が目的の頂点である場合は、サイクルを終了します。それ以外の場合は、GOTO1です。
次のようになります。
, Node , .
private Node BFS(Node first, Node target)
{
List<Node> visited = new List<Node>();
Queue<Node> frontier = new Queue<Node>();
frontier.Enqueue(first);
while (frontier.Count > 0)
{
var current = frontier.Dequeue();
visited.Add(current);
if (current == target)
return Node;
var neighbours = current.GenerateNeighbours();
foreach(var neighbour in neighbours)
if (!visited.Contains(neighbour))
frontier.Enqueue(neighbour);
}
return default;
}, Node , .
このアプローチは最適なパスを提供しますが、落とし穴があります。アルゴリズムはすべての方向の頂点を処理するため、長距離および強い分岐のあるグラフでは非常にゆっくりと動作します。これはまさに私たちの場合です。
ここでは、アルゴリズムの動作領域を制限することはできません。いずれの場合も、半径を超えて目的のポイントに到達することはないためです。他の最適化方法が必要です。
A *
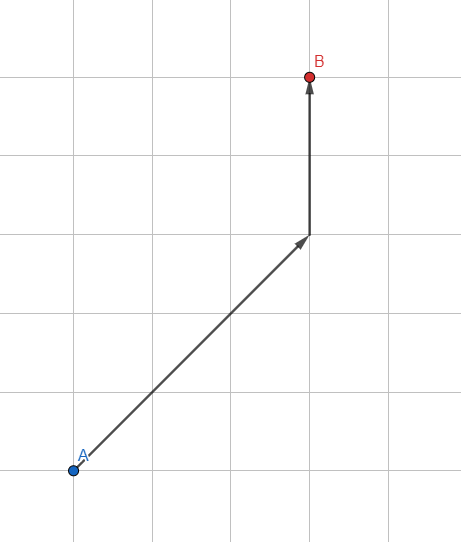
標準の幅優先検索を変更してみましょう。頂点を格納するための通常のキューではなく、ヒューリスティックに基づいてソートされたキュー(予想されるパスのおおよその見積もり)を使用します。
予想されるパスを見積もる方法は?最も単純なのは、処理された頂点から目的のポイントまでのベクトルの長さです。ベクトルが小さいほど、ポイントはより有望になり、キューの先頭に近くなります。アルゴリズムは、ゴールの方向にある頂点を優先します。
したがって、アルゴリズム内の各反復は、追加の計算のために少し時間がかかりますが、分析する頂点の数を減らすことによって(最も有望なものだけが処理されます)、アルゴリズムの速度が大幅に向上します。
しかし、処理された頂点はまだたくさんあります。ベクトルの長さを見つけることは、平方根を計算することを含む費用のかかる操作です。したがって、ヒューリスティックには簡略化された計算を使用します。
整数ベクトルを作成しましょう:
public readonly struct Vector2Int : IEquatable<Vector2Int>
{
private static readonly double Sqr = Math.Sqrt(2);
public Vector2Int(int x, int y)
{
X = x;
Y = y;
}
public int X { get; }
public int Y { get; }
/// <summary>
/// Estimated path distance without obstacles.
/// </summary>
public double DistanceEstimate()
{
int linearSteps = Math.Abs(Math.Abs(Y) - Math.Abs(X));
int diagonalSteps = Math.Max(Math.Abs(Y), Math.Abs(X)) - linearSteps;
return linearSteps + Sqr * diagonalSteps;
}
public static Vector2Int operator +(Vector2Int a, Vector2Int b)
=> new Vector2Int(a.X + b.X, a.Y + b.Y);
public static Vector2Int operator -(Vector2Int a, Vector2Int b)
=> new Vector2Int(a.X - b.X, a.Y - b.Y);
public static bool operator ==(Vector2Int a, Vector2Int b)
=> a.X == b.X && a.Y == b.Y;
public static bool operator !=(Vector2Int a, Vector2Int b)
=> !(a == b);
public bool Equals(Vector2Int other)
=> X == other.X && Y == other.Y;
public override bool Equals(object obj)
{
if (!(obj is Vector2Int))
return false;
var other = (Vector2Int) obj;
return X == other.X && Y == other.Y;
}
public override int GetHashCode()
=> HashCode.Combine(X, Y);
public override string ToString()
=> $"({X}, {Y})";
}座標のペアを格納するための標準構造。ここでは、1回だけ計算できるように、スクエアルートキャッシングが表示されています。IEquatableインターフェースを使用すると、Vector2Intをオブジェクトに変換したり、逆変換したりすることなく、ベクトルを相互に比較できます。これにより、アルゴリズムが大幅に高速化され、不要な割り当てがなくなります。
DistanceEstimate()は、直線および斜めの遷移の数を計算することにより、ターゲットまでのおおよその距離を推定するために使用されます。別の方法が一般的です:
return Math.Max(Math.Abs(X), Math.Abs(Y))このオプションはさらに高速に機能しますが、これは対角距離推定の精度が低いことで補われます。
座標を操作するためのツールができたので、グラフの上部を表すオブジェクトを作成しましょう。
internal class PathNode
{
public PathNode(Vector2Int position, double traverseDist, double heuristicDist, PathNode parent)
{
Position = position;
TraverseDistance = traverseDist;
Parent = parent;
EstimatedTotalCost = TraverseDistance + heuristicDist;
}
public Vector2Int Position { get; }
public double TraverseDistance { get; }
public double EstimatedTotalCost { get; }
public PathNode Parent { get; }
}親では、新しい頂点ごとに前の頂点を記録します。これは、ポイントごとに最終パスを構築するのに役立ちます。座標に加えて、移動距離とパスの推定コストも保存して、処理に最も有望な頂点を選択できるようにします。
このクラスは改善を求めていますが、後で戻ってきます。今のところ、頂点の近傍を生成するメソッドを開発しましょう。
internal static class NodeExtensions
{
private static readonly (Vector2Int position, double cost)[] NeighboursTemplate = {
(new Vector2Int(1, 0), 1),
(new Vector2Int(0, 1), 1),
(new Vector2Int(-1, 0), 1),
(new Vector2Int(0, -1), 1),
(new Vector2Int(1, 1), Math.Sqrt(2)),
(new Vector2Int(1, -1), Math.Sqrt(2)),
(new Vector2Int(-1, 1), Math.Sqrt(2)),
(new Vector2Int(-1, -1), Math.Sqrt(2))
};
public static IEnumerable<PathNode> GenerateNeighbours(this PathNode parent, Vector2Int target)
{
foreach ((Vector2Int position, double cost) in NeighboursTemplate)
{
Vector2Int nodePosition = position + parent.Position;
double traverseDistance = parent.TraverseDistance + cost;
double heuristicDistance = (position - target).DistanceEstimate();
yield return new PathNode(nodePosition, traverseDistance, heuristicDistance, parent);
}
}
}NeighborsTemplate-目的のポイントの線形および斜めのネイバーを作成するための事前定義されたテンプレート。また、対角遷移のコストの増加も考慮に入れています。
GenerateNeighbors-NeighborsTemplateをトラバースし、隣接する8つの辺すべてに新しい頂点を返すジェネレーター。
PathNode内の機能を押し出すことは可能ですが、SRPのわずかな違反のように感じます。また、アルゴリズム自体の中にサードパーティの機能を追加したくありません。クラスを可能な限りコンパクトに保ちます。
メインのパスファインディングクラスに取り組む時が来ました!
public class Path
{
private readonly List<PathNode> frontier = new List<PathNode>();
private readonly List<Vector2Int> ignoredPositions = new List<Vector2Int>();
public IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles) {...}
private bool GenerateNodes(Vector2Int start, Vector2Int target,
IEnumerable<Vector2Int> obstacles, out PathNode node)
{
frontier.Clear();
ignoredPositions.Clear();
ignoredPositions.AddRange(obstacles);
// Add starting point.
frontier.Add(new PathNode(start, 0, 0, null));
while (frontier.Any())
{
// Find node with lowest estimated cost.
var lowest = frontier.Min(a => a.EstimatedTotalCost);
PathNode current = frontier.First(a => a.EstimatedTotalCost == lowest);
ignoredPositions.Add(current.Position);
if (current.Position.Equals(target))
{
node = current;
return true;
}
GenerateFrontierNodes(current, target);
}
// All nodes analyzed - no path detected.
node = null;
return false;
}
private void GenerateFrontierNodes(PathNode parent, Vector2Int target)
{
foreach (PathNode newNode in parent.GenerateNeighbours(target))
{
// Position is already checked or occupied by an obstacle.
if (ignoredPositions.Contains(newNode.Position)) continue;
// Node is not present in queue.
var node = frontier.FirstOrDefault(a => a.Position == newNode.Position);
if (node == null)
frontier.Add(newNode);
// Node is present in queue and new optimal path is detected.
else if (newNode.TraverseDistance < node.TraverseDistance)
{
frontier.Remove(node);
frontier.Add(newNode);
}
}
}
}GenerateNodesは、分析用の頂点のキューを含むfrontierと、すでに処理された頂点が追加されるignoredPositionsの2つのコレクションで機能します。
ループを繰り返すたびに、最も有望な頂点が検出され、エンドポイントに到達したかどうかが確認され、この頂点の新しいネイバーが生成されます。
そして、このすべての美しさは50行に収まります。
インターフェイスを実装することは残っています:
public IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles)
{
if (!GenerateNodes(start, target, obstacles, out PathNode node))
return Array.Empty<Vector2Int>();
var output = new List<Vector2Int>();
while (node.Parent != null)
{
output.Add(node.Position);
node = node.Parent;
}
output.Add(start);
return output.AsReadOnly();
}GenerateNodesは最終頂点を返します。それぞれの親ネイバーを書き留めたので、最初の頂点まですべての親をウォークスルーするだけで十分であり、最短パスを取得します。すべて順調!
か否か?
アルゴリズムの最適化
1. PathNode
簡単に始めましょう。PathNodeを単純化しましょう:
internal readonly struct PathNode
{
public PathNode(Vector2Int position, Vector2Int target, double traverseDistance)
{
Position = position;
TraverseDistance = traverseDistance;
double heuristicDistance = (position - target).DistanceEstimate();
EstimatedTotalCost = traverseDistance + heuristicDistance;
}
public Vector2Int Position { get; }
public double TraverseDistance { get; }
public double EstimatedTotalCost { get; }
}これは一般的なデータラッパーであり、頻繁に作成されます。newを書き込むたびに、それをクラスにしてメモリをロードする理由はありません。したがって、structを使用します。
ただし、問題があります。構造には、独自のタイプへの循環参照を含めることはできません。したがって、PathNode内に親を格納する代わりに、頂点間のパスの構築を追跡する別の方法が必要です。簡単です。Pathクラスに新しいコレクションを追加しましょう。
private readonly Dictionary<Vector2Int, Vector2Int> links;そして、ネイバーの生成をわずかに変更します。
private void GenerateFrontierNodes(PathNode parent, Vector2Int target)
{
foreach (PathNode newNode in parent.GenerateNeighbours(target))
{
// Position is already checked or occupied by an obstacle.
if (ignoredPositions.Contains(newNode.Position)) continue;
// Node is not present in queue.
if (!frontier.TryGet(newNode.Position, out PathNode existingNode))
{
frontier.Enqueue(newNode);
links[newNode.Position] = parent.Position; // Add link to dictionary.
}
// Node is present in queue and new optimal path is detected.
else if (newNode.TraverseDistance < existingNode.TraverseDistance)
{
frontier.Modify(newNode);
links[newNode.Position] = parent.Position; // Add link to dictionary.
}
}
}親を頂点自体に書き込む代わりに、遷移を辞書に書き込みます。ボーナスとして、必要なのは座標だけで他には何もないため、辞書はPathNodeではなくVector2Intで直接機能します。
計算内での結果の生成も簡略化されています。
public IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles)
{
if (!GenerateNodes(start, target, obstacles))
return Array.Empty<Vector2Int>();
var output = new List<Vector2Int> {target};
while (links.TryGetValue(target, out target))
output.Add(target);
return output.AsReadOnly();
}2. NodeExtensions
次に、ネイバーの生成について説明します。IEnumerableは、そのすべての利点のために、多くの状況で悲しい量のゴミを生成します。それを取り除きましょう:
internal static class NodeExtensions
{
private static readonly (Vector2Int position, double cost)[] NeighboursTemplate = {
(new Vector2Int(1, 0), 1),
(new Vector2Int(0, 1), 1),
(new Vector2Int(-1, 0), 1),
(new Vector2Int(0, -1), 1),
(new Vector2Int(1, 1), Math.Sqrt(2)),
(new Vector2Int(1, -1), Math.Sqrt(2)),
(new Vector2Int(-1, 1), Math.Sqrt(2)),
(new Vector2Int(-1, -1), Math.Sqrt(2))
};
public static void Fill(this PathNode[] buffer, PathNode parent, Vector2Int target)
{
int i = 0;
foreach ((Vector2Int position, double cost) in NeighboursTemplate)
{
Vector2Int nodePosition = position + parent.Position;
double traverseDistance = parent.TraverseDistance + cost;
buffer[i++] = new PathNode(nodePosition, target, traverseDistance);
}
}
}現在、拡張メソッドはジェネレーターではありません。引数として渡されるバッファーを埋めるだけです。バッファは、パス内に別のコレクションとして保存されます。
private const int MaxNeighbours = 8;
private readonly PathNode[] neighbours = new PathNode[MaxNeighbours];そしてそれはこのように使用されます:
neighbours.Fill(parent, target);
foreach(var neighbour in neighbours)
{
// ...3. HashSet
Listを使用する代わりに、HashSetを使用しましょう。
private readonly HashSet<Vector2Int> ignoredPositions;大規模なコレクションを操作する場合は、はるかに効率的です。ignoredPositions.Contains()メソッドは、呼び出しの頻度が高いため、リソースを大量に消費します。コレクションタイプを変更するだけで、パフォーマンスが大幅に向上します。
4.BinaryHeap
私たちの実装には、アルゴリズムを10倍遅くする場所が1つあります。
// Find node with lowest estimated cost.
var lowest = frontier.Min(a => a.EstimatedTotalCost);
PathNode current = frontier.First(a => a.EstimatedTotalCost == lowest);リスト自体は悪い選択であり、Linqを使用すると事態はさらに悪化します。
理想的には、次のコレクションが必要です。
- 自動ソート。
- 漸近的な複雑さの低い成長。
- 高速挿入操作。
- 高速除去操作。
- 要素を簡単にナビゲートできます。
SortedSetは良いオプションのように思えるかもしれませんが、重複を含める方法がわかりません。EstimatedTotalCostで並べ替えを作成すると、価格が同じ(ただし座標が異なる)すべての頂点が削除されます。障害物の数が少ないオープンエリアでは、これはひどいことではなく、アルゴリズムを高速化しますが、狭い迷路では、結果は不正確なルートと偽陰性の結果になります。
したがって、コレクション(バイナリヒープ)を実装します。従来の実装は5つのうち4つの要件を満たし、小さな変更を加えるだけで、このコレクションは私たちの場合に理想的です。
コレクションは部分的にソートされたツリーであり、挿入および削除操作の複雑さはlog(n)に等しくなります。
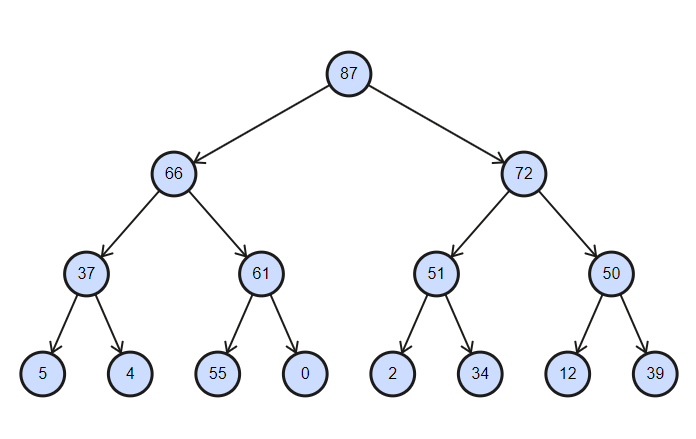
降順でソートされたバイナリヒープ
internal interface IBinaryHeap<in TKey, T>
{
void Enqueue(T item);
T Dequeue();
void Clear();
bool TryGet(TKey key, out T value);
void Modify(T value);
int Count { get; }
}簡単な部分を書いてみましょう:
internal class BinaryHeap : IBinaryHeap<Vector2Int, PathNode>
{
private readonly IDictionary<Vector2Int, int> map;
private readonly IList<PathNode> collection;
private readonly IComparer<PathNode> comparer;
public BinaryHeap(IComparer<PathNode> comparer)
{
this.comparer = comparer;
collection = new List<PathNode>();
map = new Dictionary<Vector2Int, int>();
}
public int Count => collection.Count;
public void Clear()
{
collection.Clear();
map.Clear();
}
// ...
}頂点のカスタムソートにはIComparerを使用します。IListは、実際に使用する頂点ストアです。頂点をすばやく削除するには、頂点のインデックスを追跡するためにIDictionaryが必要です(バイナリヒープの標準実装では、最上位の要素のみを簡単に操作できます)。
要素を追加しましょう:
public void Enqueue(PathNode item)
{
collection.Add(item);
int i = collection.Count - 1;
map[item.Position] = i;
// Sort nodes from bottom to top.
while(i > 0)
{
int j = (i - 1) / 2;
if (comparer.Compare(collection[i], collection[j]) <= 0)
break;
Swap(i, j);
i = j;
}
}
private void Swap(int i, int j)
{
PathNode temp = collection[i];
collection[i] = collection[j];
collection[j] = temp;
map[collection[i].Position] = i;
map[collection[j].Position] = j;
}新しい各要素はツリーの最後のセルに追加され、その後、最小の要素が可能な限り高くなるまで、新しい要素からルートへのノードによって、部分的に下から上に並べ替えられます。コレクション全体がソートされるのではなく、最上位と最後の中間ノードのみがソートされるため、操作には複雑度ログ(n)があります。
アイテムの入手:
public PathNode Dequeue()
{
if (collection.Count == 0) return default;
PathNode result = collection.First();
RemoveRoot();
map.Remove(result.Position);
return result;
}
private void RemoveRoot()
{
collection[0] = collection.Last();
map[collection[0].Position] = 0;
collection.RemoveAt(collection.Count - 1);
// Sort nodes from top to bottom.
var i = 0;
while(true)
{
int largest = LargestIndex(i);
if (largest == i)
return;
Swap(i, largest);
i = largest;
}
}
private int LargestIndex(int i)
{
int leftInd = 2 * i + 1;
int rightInd = 2 * i + 2;
int largest = i;
if (leftInd < collection.Count
&& comparer.Compare(collection[leftInd], collection[largest]) > 0)
largest = leftInd;
if (rightInd < collection.Count
&& comparer.Compare(collection[rightInd], collection[largest]) > 0)
largest = rightInd;
return largest;
}追加と同様に、ルート要素が削除され、最後の要素がその場所に配置されます。その後、部分的なトップダウンソートでアイテムが交換され、最小のものが一番上になります。
その後、要素の検索を実装して変更します。
public bool TryGet(Vector2Int key, out PathNode value)
{
if (!map.TryGetValue(key, out int index))
{
value = default;
return false;
}
value = collection[index];
return true;
}
public void Modify(PathNode value)
{
if (!map.TryGetValue(value.Position, out int index))
throw new KeyNotFoundException(nameof(value));
collection[index] = value;
}ここでは複雑なことは何もありません。辞書から要素のインデックスを検索し、その後直接アクセスします。
ヒープの汎用バージョン:
internal class BinaryHeap<TKey, T> : IBinaryHeap<TKey, T> where TKey : IEquatable<TKey>
{
private readonly IDictionary<TKey, int> map;
private readonly IList<T> collection;
private readonly IComparer<T> comparer;
private readonly Func<T, TKey> lookupFunc;
public BinaryHeap(IComparer<T> comparer, Func<T, TKey> lookupFunc, int capacity)
{
this.comparer = comparer;
this.lookupFunc = lookupFunc;
collection = new List<T>(capacity);
map = new Dictionary<TKey, int>(capacity);
}
public int Count => collection.Count;
public void Enqueue(T item)
{
collection.Add(item);
int i = collection.Count - 1;
map[lookupFunc(item)] = i;
while(i > 0)
{
int j = (i - 1) / 2;
if (comparer.Compare(collection[i], collection[j]) <= 0)
break;
Swap(i, j);
i = j;
}
}
public T Dequeue()
{
if (collection.Count == 0) return default;
T result = collection.First();
RemoveRoot();
map.Remove(lookupFunc(result));
return result;
}
public void Clear()
{
collection.Clear();
map.Clear();
}
public bool TryGet(TKey key, out T value)
{
if (!map.TryGetValue(key, out int index))
{
value = default;
return false;
}
value = collection[index];
return true;
}
public void Modify(T value)
{
if (!map.TryGetValue(lookupFunc(value), out int index))
throw new KeyNotFoundException(nameof(value));
collection[index] = value;
}
private void RemoveRoot()
{
collection[0] = collection.Last();
map[lookupFunc(collection[0])] = 0;
collection.RemoveAt(collection.Count - 1);
var i = 0;
while(true)
{
int largest = LargestIndex(i);
if (largest == i)
return;
Swap(i, largest);
i = largest;
}
}
private void Swap(int i, int j)
{
T temp = collection[i];
collection[i] = collection[j];
collection[j] = temp;
map[lookupFunc(collection[i])] = i;
map[lookupFunc(collection[j])] = j;
}
private int LargestIndex(int i)
{
int leftInd = 2 * i + 1;
int rightInd = 2 * i + 2;
int largest = i;
if (leftInd < collection.Count && comparer.Compare(collection[leftInd], collection[largest]) > 0) largest = leftInd;
if (rightInd < collection.Count && comparer.Compare(collection[rightInd], collection[largest]) > 0) largest = rightInd;
return largest;
}
}現在、私たちのパスファインディングはまともな速度であり、ゴミの生成はほとんど残っていません。仕上がりが近づいています!
5.再利用可能なコレクション
このアルゴリズムは、1秒間に数十回呼び出す機能を念頭に置いて開発されています。ガベージの生成は断固として受け入れられません。ロードされたガベージコレクターは、パフォーマンスの定期的な低下を引き起こす可能性があります(そしてそうなるでしょう!)。
出力を除くすべてのコレクションは、クラスの作成時にすでに1回宣言されており、最後のコレクションもそこに追加されます。
private const int MaxNeighbours = 8;
private readonly PathNode[] neighbours = new PathNode[MaxNeighbours];
private readonly IBinaryHeap<Vector2Int, PathNode> frontier;
private readonly HashSet<Vector2Int> ignoredPositions;
private readonly IList<Vector2Int> output;
private readonly IDictionary<Vector2Int, Vector2Int> links;
public Path()
{
var comparer = Comparer<PathNode>.Create((a, b) => b.EstimatedTotalCost.CompareTo(a.EstimatedTotalCost));
frontier = new BinaryHeap(comparer);
ignoredPositions = new HashSet<Vector2Int>();
output = new List<Vector2Int>();
links = new Dictionary<Vector2Int, Vector2Int>();
}publicメソッドは次の形式を取ります。
public IReadOnlyCollection<Vector2Int> Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles)
{
if (!GenerateNodes(start, target, obstacles))
return Array.Empty<Vector2Int>();
output.Clear();
output.Add(target);
while (links.TryGetValue(target, out target))
output.Add(target);
return output.AsReadOnly();
}そして、それはコレクションを作成することだけではありません!コレクションは、いっぱいになると容量を動的に変更します。パスが長い場合、サイズ変更は数十回発生します。これは非常にメモリを消費します。コレクションをクリアして、新しいコレクションを宣言せずに再利用すると、コレクションの容量は保持されます。最初のパスの構築では、コレクションを初期化して容量を変更するときに大量のガベージが作成されますが、後続の呼び出しは割り当てなしで正常に機能します(ただし、計算された各パスの長さが急激な歪みなしでプラスまたはマイナスで同じである場合)。したがって、次のポイント:
6.(ボーナス)コレクションのサイズの発表
すぐに多くの疑問が生じます。
- Pathクラスのコンストラクターに負荷をオフロードするか、パスファインダーへの最初の呼び出しでそれを残す方が良いですか?
- コレクションに供給する容量はどれくらいですか?
- より大きな容量をすぐに発表する方が安いですか、それともコレクションを独自に拡張する方が安いですか?
3つ目は、すぐに答えることができます。パスを見つけるためのセルが数百、数千ある場合、コレクションに特定のサイズをすぐに割り当てる方が間違いなく安価です。
他の2つの質問に答えるのはもっと難しいです。これらに対する答えは、ユースケースごとに経験的に決定する必要があります。それでもコンストラクターに負荷をかけることにした場合は、アルゴリズムにステップ数の制限を追加するときが来ました。
public Path(int maxSteps)
{
this.maxSteps = maxSteps;
var comparer = Comparer<PathNode>.Create((a, b) => b.EstimatedTotalCost.CompareTo(a.EstimatedTotalCost));
frontier = new BinaryHeap(comparer, maxSteps);
ignoredPositions = new HashSet<Vector2Int>(maxSteps);
output = new List<Vector2Int>(maxSteps);
links = new Dictionary<Vector2Int, Vector2Int>(maxSteps);
}GenerateNodes内で、ループを修正します。
var step = 0;
while (frontier.Count > 0 && step++ <= maxSteps)
{
// ...
}したがって、コレクションには、最大パスに等しい容量がすぐに割り当てられます。一部のコレクションには、トラバースされたノードだけでなく、その隣接ノードも含まれます。このようなコレクションの場合、指定されたものの4〜5倍の容量を使用できます。
少し多すぎるように思われるかもしれませんが、宣言された最大値に近いパスの場合、コレクションのサイズの割り当ては、動的拡張の半分から3分の1のメモリを消費します。一方、maxSteps値に非常に大きな値を割り当てて短いパスを生成する場合、そのような革新は害を及ぼすだけです。ああ、int.MaxValueを使おうとしないでください!
最適なソリューションは、2つのコンストラクターを作成することです。そのうちの1つは、コレクションの初期容量を設定します。そうすれば、クラスを変更せずに両方の場合に使用できます。
他に何ができますか?
- .
- XML-.
- GetHashCode Vector2Int. , , , .
- , . .
- IComparable PathNode EqualityComparer. .
- : , . , , .
- インターフェイスのメソッドシグネチャを変更して、その本質をより適切に反映します。
bool Calculate(Vector2Int start, Vector2Int target, IReadOnlyCollection<Vector2Int> obstacles, out IReadOnlyCollection<Vector2Int> path);
したがって、このメソッドはその操作のロジックを明確に示していますが、元のメソッドは次のように呼び出されているはずです:CalculateOrReturnEmpty。
Pathクラスの最終バージョン:
/// <summary>
/// Reusable A* path finder.
/// </summary>
public class Path : IPath
{
private const int MaxNeighbours = 8;
private readonly PathNode[] neighbours = new PathNode[MaxNeighbours];
private readonly int maxSteps;
private readonly IBinaryHeap<Vector2Int, PathNode> frontier;
private readonly HashSet<Vector2Int> ignoredPositions;
private readonly List<Vector2Int> output;
private readonly IDictionary<Vector2Int, Vector2Int> links;
/// <summary>
/// Creation of new path finder.
/// </summary>
/// <exception cref="ArgumentOutOfRangeException"></exception>
public Path(int maxSteps = int.MaxValue, int initialCapacity = 0)
{
if (maxSteps <= 0)
throw new ArgumentOutOfRangeException(nameof(maxSteps));
if (initialCapacity < 0)
throw new ArgumentOutOfRangeException(nameof(initialCapacity));
this.maxSteps = maxSteps;
var comparer = Comparer<PathNode>.Create((a, b) => b.EstimatedTotalCost.CompareTo(a.EstimatedTotalCost));
frontier = new BinaryHeap<Vector2Int, PathNode>(comparer, a => a.Position, initialCapacity);
ignoredPositions = new HashSet<Vector2Int>(initialCapacity);
output = new List<Vector2Int>(initialCapacity);
links = new Dictionary<Vector2Int, Vector2Int>(initialCapacity);
}
/// <summary>
/// Calculate a new path between two points.
/// </summary>
/// <exception cref="ArgumentNullException"></exception>
public bool Calculate(Vector2Int start, Vector2Int target,
IReadOnlyCollection<Vector2Int> obstacles,
out IReadOnlyCollection<Vector2Int> path)
{
if (obstacles == null)
throw new ArgumentNullException(nameof(obstacles));
if (!GenerateNodes(start, target, obstacles))
{
path = Array.Empty<Vector2Int>();
return false;
}
output.Clear();
output.Add(target);
while (links.TryGetValue(target, out target)) output.Add(target);
path = output;
return true;
}
private bool GenerateNodes(Vector2Int start, Vector2Int target, IReadOnlyCollection<Vector2Int> obstacles)
{
frontier.Clear();
ignoredPositions.Clear();
links.Clear();
frontier.Enqueue(new PathNode(start, target, 0));
ignoredPositions.UnionWith(obstacles);
var step = 0;
while (frontier.Count > 0 && step++ <= maxSteps)
{
PathNode current = frontier.Dequeue();
ignoredPositions.Add(current.Position);
if (current.Position.Equals(target)) return true;
GenerateFrontierNodes(current, target);
}
// All nodes analyzed - no path detected.
return false;
}
private void GenerateFrontierNodes(PathNode parent, Vector2Int target)
{
neighbours.Fill(parent, target);
foreach (PathNode newNode in neighbours)
{
// Position is already checked or occupied by an obstacle.
if (ignoredPositions.Contains(newNode.Position)) continue;
// Node is not present in queue.
if (!frontier.TryGet(newNode.Position, out PathNode existingNode))
{
frontier.Enqueue(newNode);
links[newNode.Position] = parent.Position;
}
// Node is present in queue and new optimal path is detected.
else if (newNode.TraverseDistance < existingNode.TraverseDistance)
{
frontier.Modify(newNode);
links[newNode.Position] = parent.Position;
}
}
}
}ソースコードへのリンク