
Webサイトからの写真。著者:Hitesh Choudhary
SQLクエリと同じ結果をPythonで取得する
多くの場合、同じプロジェクトで作業するときは、SQLとPythonを切り替える必要があります。そうは言っても、SQLクエリでのデータ操作には精通している人もいますが、Pythonには精通していないため、効率と生産性が低下します。実際、Pandasを使用すると、PythonでもSQLクエリと同じ結果を得ることができます。
仕事の始まり
Pandasパッケージがない場合は、インストールする必要があります。
conda install pandasKaggleの 有名なTitanicDatasetを使用します。
パッケージをインストールしてデータをダウンロードしたら、Python環境にインポートする必要があります。

DataFrameを使用してデータを保存します。さまざまなPandas関数は、このデータ構造の管理に役立ちます。
SELECT、DISTINCT、COUNT、LIMIT
よく使用する単純なSQLクエリから始めましょう。
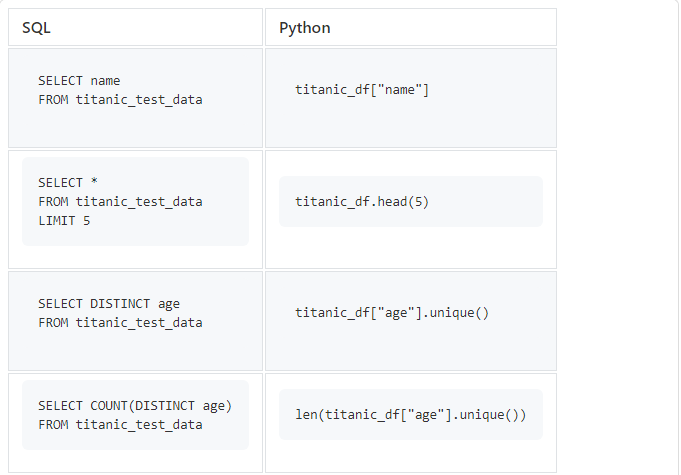
titanic_df["age"].unique()は一意の値の配列を返すため、を使用len()してそれらの数をカウントする必要があります。
SELECT、WHERE、OR、AND、IN(条件付きのSELECT)
最初のパートの後、簡単な方法でDataFrameを探索する方法を学びました。それでは、いくつかの条件でそれを試してみましょう(これは
WHERESQLのステートメントです)。

DataFrameから特定の列のみを選択する場合は、追加の角括弧のペアを使用して選択できます。
注:複数の列を選択する場合は、配列
["name","age"]を角括弧内に配置する必要があります。SQLクエリ
isin()とまったく同じように機能INします。を使用するにNOT INは、Pythonで否定を使用する必要があります(~)。
グループ化、注文者、カウント
GROUP BYまたORDER BY、データマイニングでよく使用されるSQLステートメントです。それでは、Pythonでそれらを使用してみましょう。

COUNT列を1つだけソートする場合は、ブール値をメソッドに渡すだけ
sort_valuesです。複数の列を並べ替える場合は、ブール値の配列をメソッドに渡す必要がありsort_valuesます。
このメソッド
sum()は、DataFrameの各列の合計を返します。これは、数値で集計できます。特定の列のみが必要な場合は、角括弧を使用して列名を指定する必要があります。
最小、最大、平均、中央
最後に、データを探索するときに重要ないくつかの標準的な統計関数を試してみましょう。
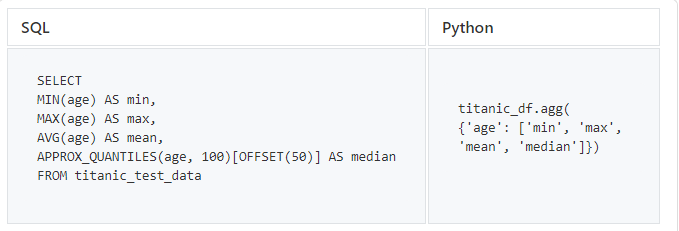
SQLには中央値を返す演算子が含まれていないため、BigQueryを使用して年齢列の中央値を取得します。Pandas
APPROX_QUANTILES
では、集計メソッド
.agg()は他の関数もサポートしていますsum。
これで、Pandasを使用してPythonでSQLクエリを書き直す方法を学習しました。この記事がお役に立てば幸いです。
すべてのコードは私のGithubリポジトリにあります。
清聴ありがとうございました!