パート2
パート3
この記事では、次のことを学びます。
- 転移学習とは何か、そしてそれはどのように機能するか
- セマンティック/インスタンスセグメンテーションとは何か、およびそれがどのように機能するか
- オブジェクト検出とは何か、およびその仕組みについて
前書き
オブジェクト検出タスクの場合、2つの方法が区別されます(ソースと詳細はこちらを参照)。
- 2段階の方法であり、「地域に基づく方法」(英語の地域ベースの方法)でもあります。これは、2つの段階に分けられたアプローチです。最初の段階では、関心領域(RoI)は、選択的検索またはニューラルネットワークの特別なレイヤー(オブジェクトを含む可能性が高い領域)を使用して選択されます。第2段階では、選択された領域は、元のクラスに属するかどうかを決定する分類子と、境界ボックスの場所を指定するリグレッサーによって考慮されます。
- シングルステージ方式(Englワンステージ方式)-個別のアルゴリズムを使用せずに領域を生成するアプローチ。代わりに、分類結果や信頼度などのさまざまな特性を持つ一定量の境界ボックスの座標を予測し、ロケーションフレームワークをさらに調整します。
この記事では、ワンステップの方法について説明します。
転移学習
転移学習は、ニューラルネットワークをトレーニングする方法であり、別の問題を解決するための追加のトレーニングのために、いくつかのデータですでにトレーニングされたモデルを取得します。たとえば、ImageNetデータセット(1000クラス)でトレーニングされたEfficientNet-B5モデルがあります。ここで、最も単純なケースでは、最後の分類子レイヤーを変更します(たとえば、10クラスのオブジェクトを分類するため)。
下の図を見てください。
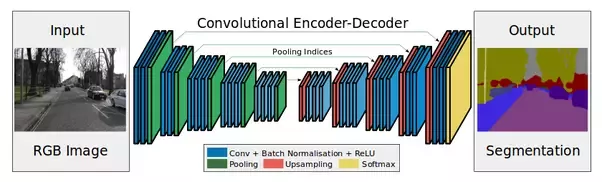
エンコーダーはレイヤー(畳み込みとプール)をサブサンプリングしています。
コードの最後のレイヤーを置き換えると、次のようになります(framework-pytorch、environment-google colab):
トレーニング済みのEfficientNet-b5モデルをロードし、その分類子レイヤーを確認します。

このレイヤーを別のレイヤーに変更し
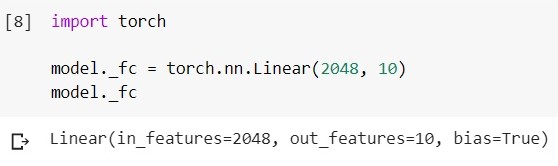
ます。特にセグメンテーションタスクではデコーダーが必要です(これについてさらに)。
転移学習戦略
デフォルトでは、さらにトレーニングしたいモデルのすべてのレイヤーがトレーニング可能であることを追加する必要があります。一部のレイヤーの重みを「フリーズ」できます。
すべてのレイヤーをフリーズするには:

トレーニングするレイヤーが少ないほど、モデルをトレーニングするために必要なコンピューティングリソースが少なくなります。このテクニックは常に正当化されますか?
ネットワークをトレーニングするデータの量、およびネットワークをトレーニングするデータに応じて、転送学習のイベントを開発するための4つのオプションがあります(「少し」と「たくさん」の下で、条件値10kを取ることができます)。
- あなたは少しのデータを持っている、そしてそれは同様のネットワークが前に訓練されたデータへ。あなたは最後の数層だけを訓練することを試みることができます。
- , , . . , , , .. .
- , , . , .
- , , . .
Semantic segmentation
セマンティックセグメンテーションとは、画像を入力としてフィードし、出力で次のようなものを取得することです。

より正式には、入力画像の各ピクセルを分類して、どのクラスに属しているかを理解します。
ここにはたくさんのアプローチとニュアンスがあります。 ResNeSt-269ネットワークのアーキテクチャのみは何ですか:)
直感-入力で画像(h、w、c)、出力でマスク(h、w)または(h、w、c)を取得します。ここで、cはクラスの数です(データとモデル)。エンコーダーの後にデコーダーを追加してトレーニングしましょう。
デコーダーは、特にアップサンプリングレイヤーで構成されます。フィーチャーマップの高さと幅をステップごとに「ストレッチ」するだけで、寸法を大きくすることができます。引っ張るときは、バイリニア補間(コードでは、メソッドパラメータの1つにすぎません)。
Deeplabv3 +ネットワークアーキテクチャ:
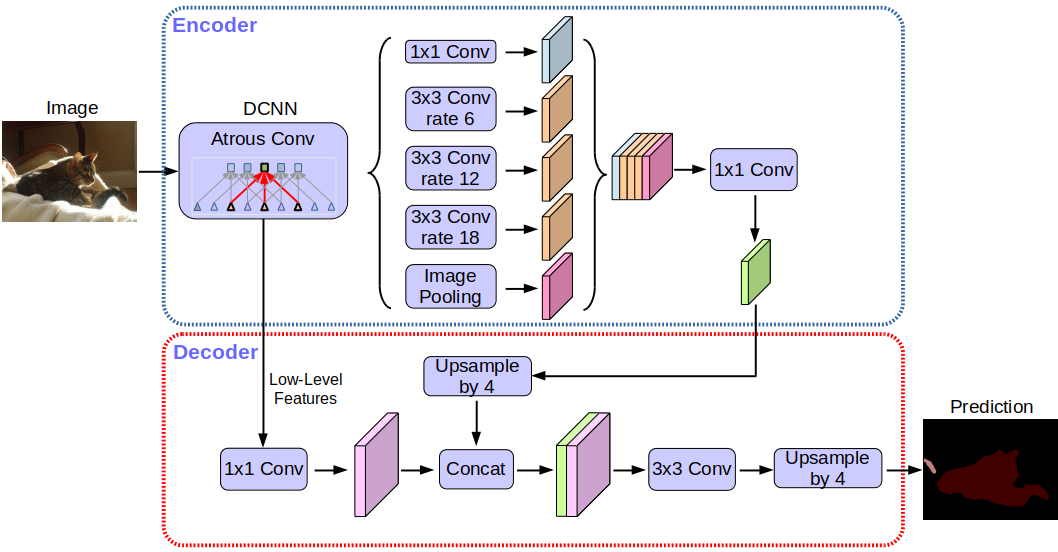
詳細に立ち入ることなく、ネットワークがエンコーダ-デコーダアーキテクチャを使用していることに気付くでしょう。
より古典的なバージョン、U-netネットワークのアーキテクチャ:
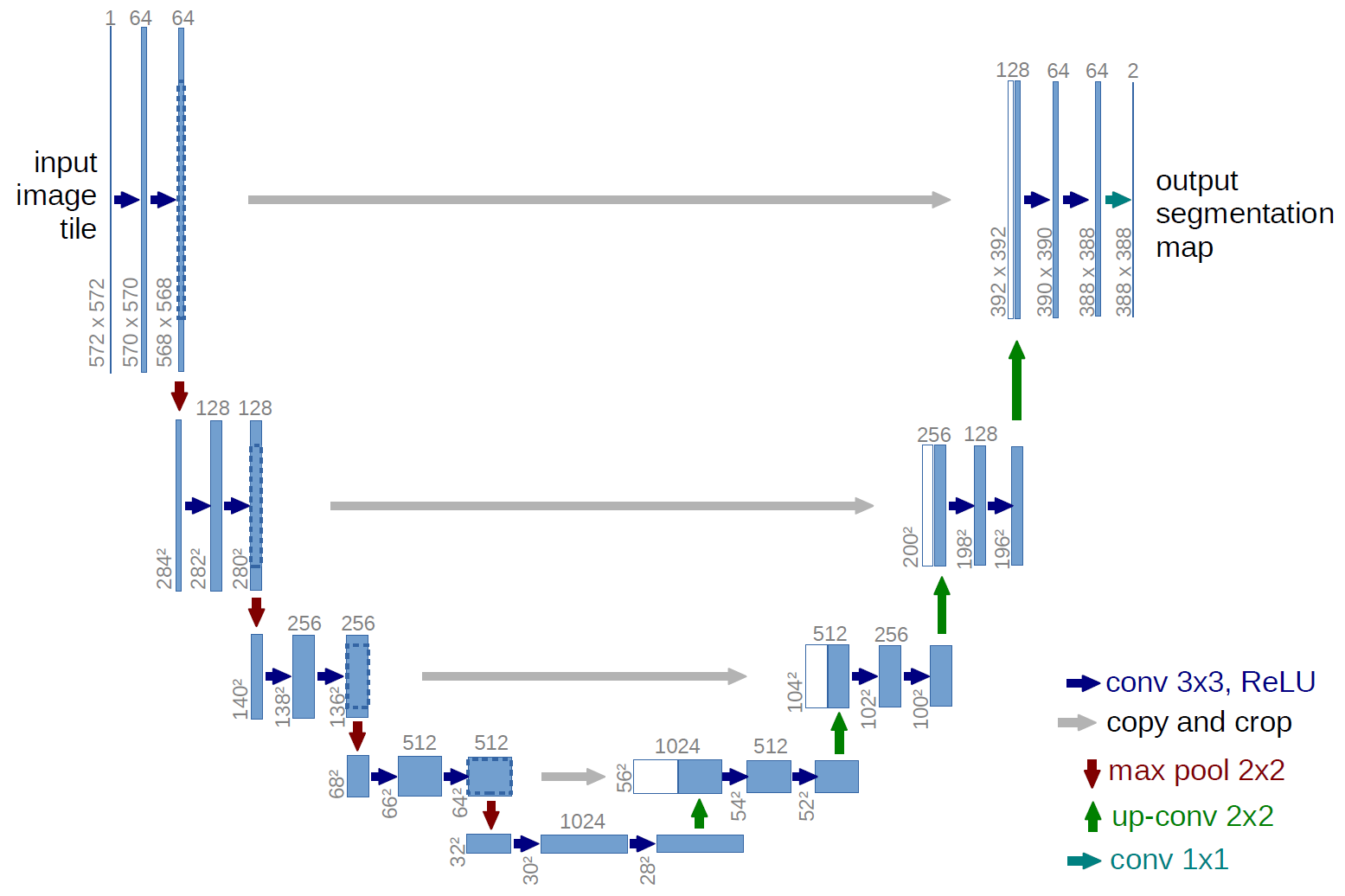
これらの灰色の矢印は何ですか?これらは、いわゆるスキップ接続です。重要なのは、エンコーダーが入力画像を「エンコード」するということです。このような損失を最小限に抑えるために、スキップ接続を使用します。
このタスクでは、転送学習を使用できます。たとえば、トレーニング済みのエンコーダーを備えたネットワークを取得し、デコーダーを追加してトレーニングすることができます。
現時点でこのタスクで最もよく機能するデータとモデルについては、こちらをご覧ください。..。
インスタンスのセグメンテーション
セグメンテーション問題のより複雑なバージョン。その本質は、入力画像の各ピクセルを分類するだけでなく、同じクラスの異なるオブジェクトを何らかの方法で選択
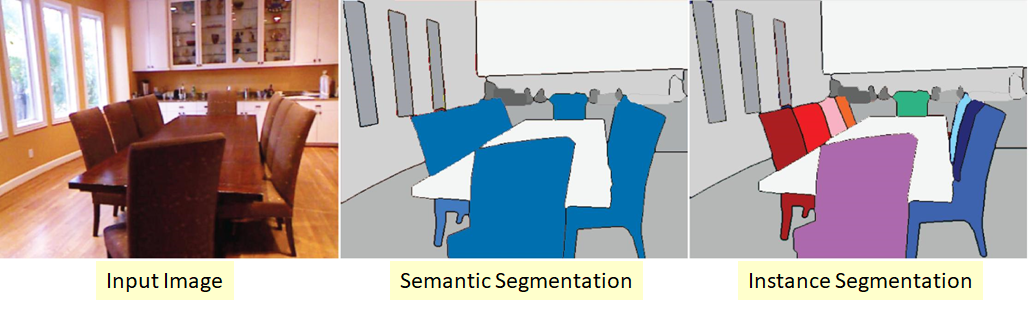
することです。クラスが「スティッキー」であるか、クラス間に目に見える境界線がない場合がありますが、同じクラスのオブジェクトを区切る必要があります。離れて。
ここにはいくつかのアプローチもあります。最も単純で直感的なのは、2つの異なるネットワークをトレーニングすることです。最初のクラスではいくつかのクラスのピクセルを分類し(セマンティックセグメンテーション)、2番目のクラスではクラスオブジェクト間でピクセルを分類します。2つのマスクを取得します。これで、最初から2番目を差し引いて、必要なものを取得できます:)
現時点で、このタスクで最もパフォーマンスの高いデータとモデルについては、こちらをご覧ください。..。
Object detection
入力に画像を送信し、出力で次のように表示します

。実行できる最も直感的な方法は、さまざまな長方形の画像を「実行」し、すでにトレーニング済みの分類子を使用して、この領域に対象のオブジェクトがあるかどうかを判断することです。そのようなスキームがありますが、それは明らかに最良のスキームではありません。フィーチャーマップの「後」(B)の「前」(A)のフィーチャーマップを何らかの形で解釈する畳み込みレイヤーがあります。この場合、畳み込みフィルターの寸法がわかります=> AからどのピクセルBに変換されたかがわかります。
YOLOv3を見てみましょう
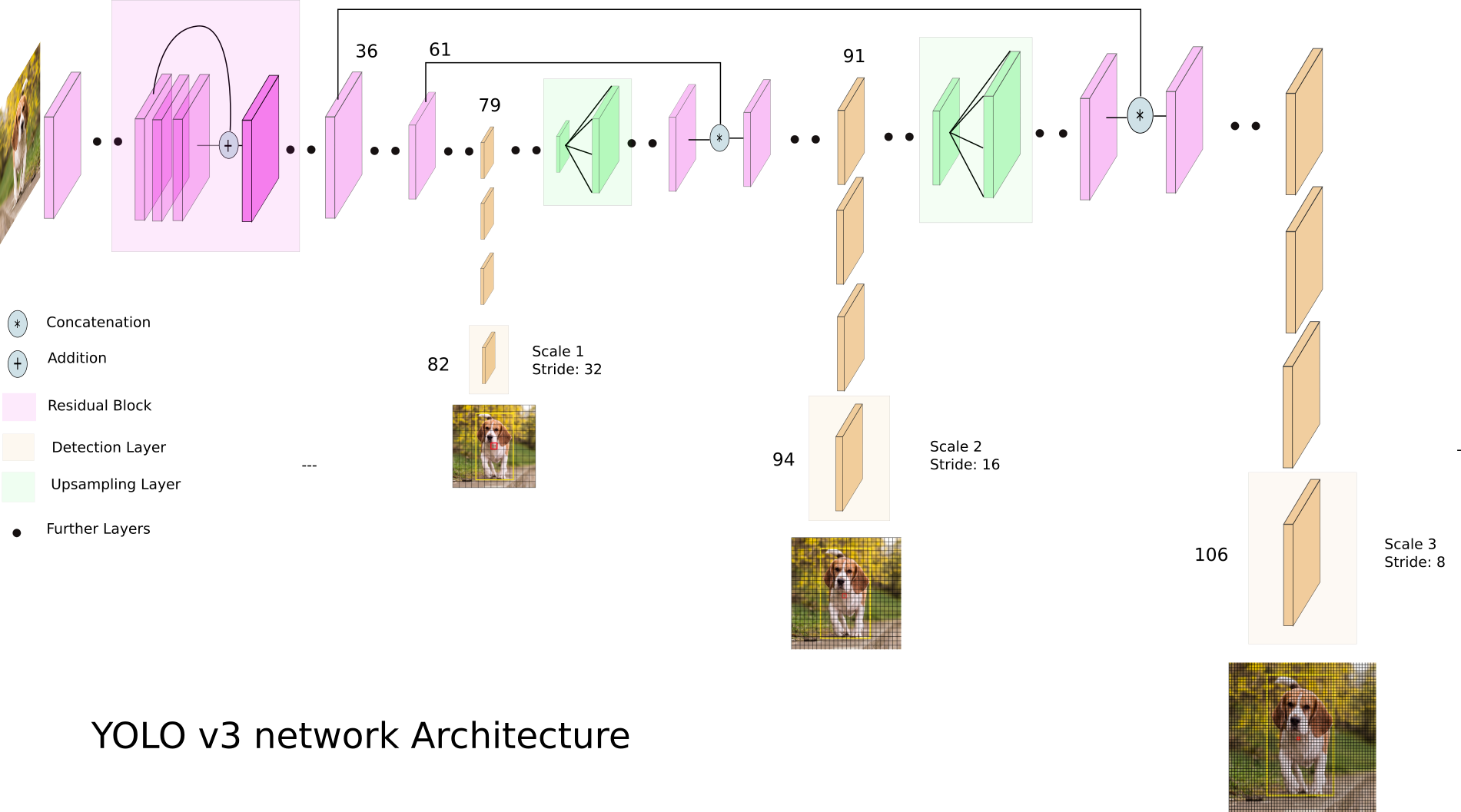
。YOLOv3はさまざまなディメンションのフィーチャマップを使用します。これは、特に、さまざまなサイズのオブジェクトを正しく検出するために行われます。
次に、3つのスケールすべてが連結されます。
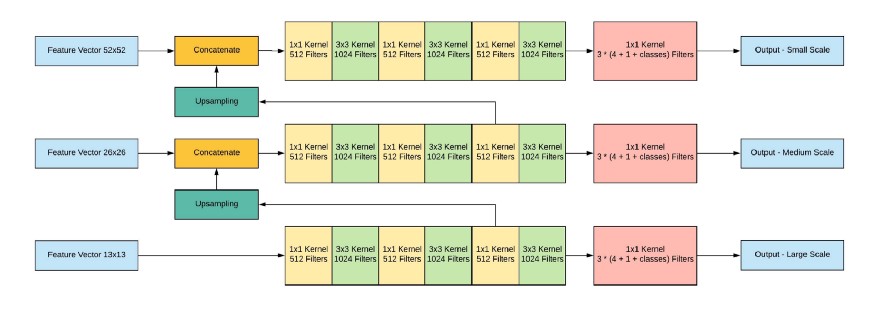
ネットワーク出力、入力イメージ416x416、13x13x(B *(5 + C))、ここでCはクラスの数、Bは各領域のボックスの数です(YOLO v3には3つのボックスがあります)。5-これらは次のようなパラメータです:Px、Py-オブジェクトの中心の座標、Ph、Pw-オブジェクトの高さと幅、Pobj-オブジェクトがこの領域にある確率。
写真を見てみましょう。もう少し明確になります

。YOLOは、最初にオブジェクト性スコアを何らかの値(通常は0.5〜0.6)で、次に非最大抑制で予測データを除外します。
現時点でこのタスクで最もパフォーマンスが高いデータとモデルについては、こちらをご覧ください。
結論
最近のオブジェクトのセグメンテーションとローカリゼーションのタスクには、さまざまなモデルとアプローチがあります。モデルとアプローチの動物園を分解するのがより簡単になることを理解して、特定のアイデアがあります。私はこの記事でこれらのアイデアを表現しようとしました。
次の記事では、スタイル転送とGANについて説明します。