
Open AIの開発に言及せずに、ダイジェストの1つが完成しているわけではないようです。7月に、新しいGPT-3アルゴリズムが機械学習の分野で最も議論されたトピックになりました。技術的には、これは1つのモデルではなく、家族全員であり、便宜上、単一の名前で一般化されています。最大のモデルは1,750億のパラメーターを使用し、570 Gbのデータセットがトレーニングに使用されました。これには、Common Crawlアーカイブからのフィルター処理されたデータと、WebText2、Books1、Books2、およびWikipediaからの高品質データが含まれます。
モデルは事前にトレーニングされており、特定のタスクを微調整する必要がないことに注意してください。より良い結果を得るには、入力で問題を解決する例を少なくとも1つ(ワンショット)または複数(数ショット)提供することをお勧めしますが、それなしでも実行できます。それら(ゼロショット)。モデルが問題の解決策を生成するには、問題を英語で説明するだけで十分です。これはテキストを生成するためのアルゴリズムであると一般に信じられていますが、その可能性がはるかに豊富であることはすでに明らかです。
モデルは5月に発表されましたが、Open AIは、GitHubリポジトリでトレーニングされたGPT-3がPythonコードを正常に生成できることを示し、1か月半後、最初の幸運な人がAPIにアクセスし、ベストプラクティスを示しました。結果は素晴らしいです。もちろん、私たちは開発者として、このアルゴリズムが私たちの生活をどれだけ簡素化し、おそらく競争を生み出すかに興味を持っています。
debuild.coサービスはすでに登場しており、関数のテキストによる説明に従って、機能するコードを作成し、適切なレイアウトを作成します。
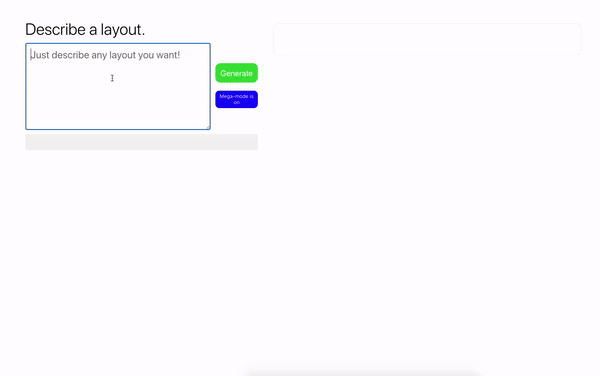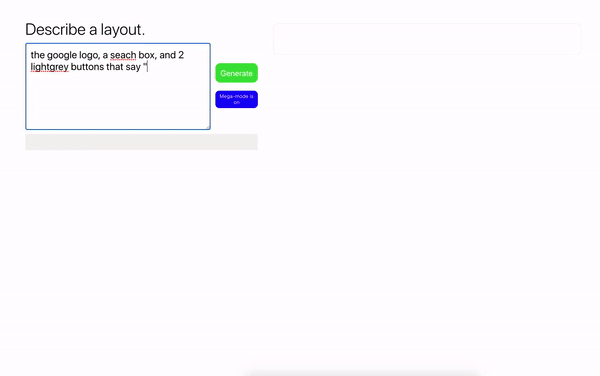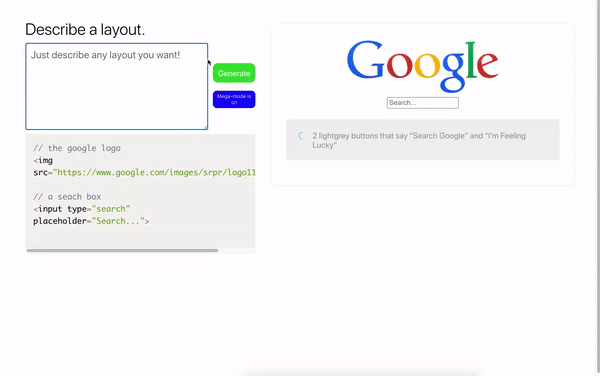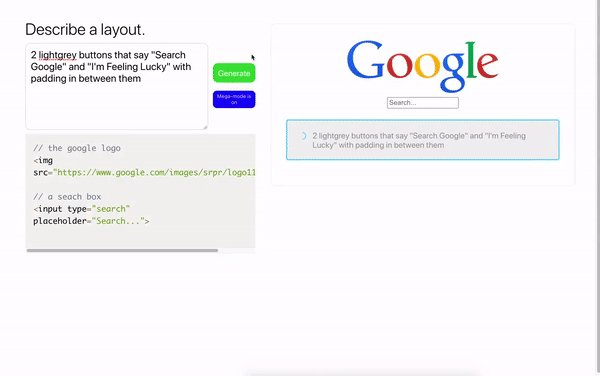
Webプログラミングだけでなく、設計でもベストプラクティスを使用できます。このモデルは、テキストの説明によってJSONデータを生成し、それをFigmaレイアウトに変換することができます。
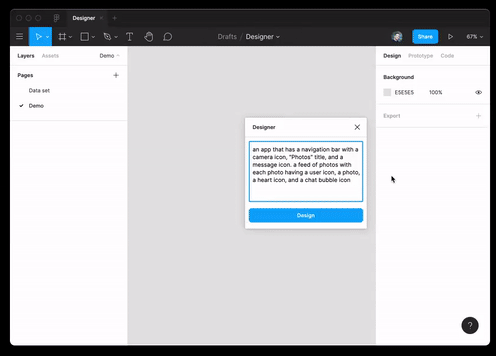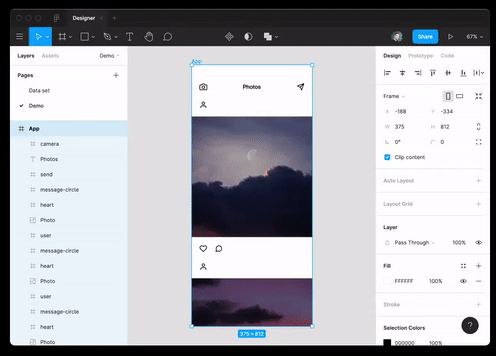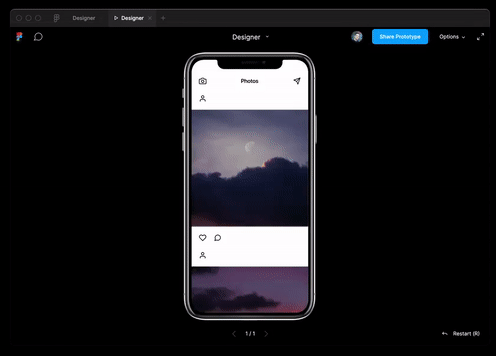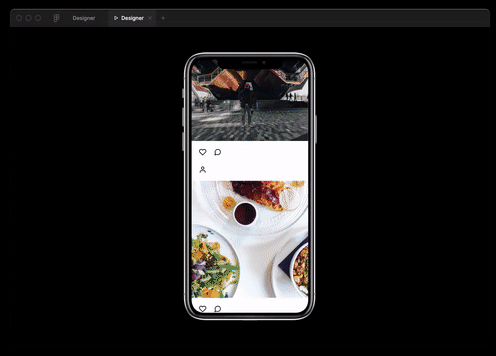
そしてまた彼女は実質的に成功したRuby開発者のポジションのインタビュー。
プログラミングでの機械学習の使用に関するニュースはそれだけではありません。
TransCoder
コードベースをCOBOLなどの古風なプログラミング言語からJavaやC ++などの最新の代替言語に移行することは、複雑でリソースを大量に消費するタスクであり、専門家は両方のテクノロジーに習熟している必要があります。同時に、古風な言語は今でも世界中のメインフレームで使用されているため、所有者はコードベースを手動で最新の言語に変換するか、レガシーコードを維持し続けるか、選択が難しいことがよくあります。
Facebookがオープンソースの自己学習モデルを発表、これはこのタスクを容易にするのに役立ちます。これは、並列トレーニングデータを必要とせずに、あるプログラミング言語から別のプログラミング言語にコードを変換できる最初のシステムです。
作成者は、モデルがJava関数の90%以上をC ++に、C ++関数の74.8%をJavaに、Java関数の68.7%をPythonに正しく変換すると推定しています。市販の類似物の指標よりも高い
ContraCode開発
ツールは、人間が書いたコードを理解して変更するために、ますます機械学習を使用しています。コードを使用してアルゴリズムを操作する際の主な問題は、ラベル付けされたデータセットがないことです。
Berkeleyの研究者は、ContraCodeメソッドを使用してこの問題を解決することを提案しています。著者は、同じ機能を持つプログラムは同じ表現を持つべきであり、逆もまた同様であると信じています。したがって、それらは対照学習用のコードバリアントを生成します。データを作成するために、変数の名前が変更され、コードが再フォーマットされて難読化されます。
将来的には、この方法を使用した自己学習モデルで、タイプの予測、エラーの検出、コードの要約などが可能になります。この分野でのこれらおよびその他の進歩を考えると、機械が人間と同じようにコードを書くことをすぐに学ぶ可能性があります。
DeepSIM

この研究の著者は、単一のターゲット画像上の生成的な敵対ネットワークが複雑な操作を処理できることを示しています。
モデルは、画像のプリミティブ表現(たとえば、写真内のオブジェクトのエッジのみ)を画像自体と一致させることを学習します。操作中に、ジェネレーターを使用すると、入力でのプリミティブ表現を変更し、ネットワークを介してマッピングすることにより、画像を変更できます。このアプローチは、膨大なトレーニングデータセットを必要とするDNN問題を解決します。結果は印象的です。
3D写真の修復

2DRGB-D画像を3Dに変換する別の方法。アルゴリズムは、元の画像のオブジェクトによって隠されている領域を再作成します。階層化された深度画像がベース表現として使用され、モデルはコンテキストを考慮して、非表示領域の新しい色と深度データを繰り返し合成します。出力は写真で、標準のグラフィックエンジンを使用してパララックス効果を追加できます。モデルを自分でテストできるコラボが利用可能です。
HiDT

ロシアの研究者チームは、写真の時刻を変更するオープンソースアルゴリズムを発表しました。高解像度の写真で照明の変化をモデル化することは困難です。提示されたアルゴリズムは、生成的な画像間モデルとアップサンプリングスキームを組み合わせており、高解像度画像での変換を可能にします。モデルは、タイムスタンプのないさまざまな風景の静止画像でトレーニングされていることに注意することが重要です。
自動エンコーダーの交換

HiDTが画像の照明を定性的に変更できる場合、さまざまなデータセットでトレーニングされたこのニューラルネットワークは、時刻だけでなく風景も変更できます。残念ながら、ソースコードを見る機会がないため、このモデルの機能を示すビデオしか賞賛できません。
SCAN
画像を意味的に意味のあるクラスターに独立してグループ化するオープンソースのニューラルネットワーク。著者のアプローチの目新しさは、トレーニングとクラスタリングの段階が分離されていることです。最初に機能を教えるタスクが開始され、次にモデルはクラスタリングの最初の段階で取得されたデータに基づいています。これにより、他の同様のモデルよりも優れた結果が得られます。
RetrieveGAN

ニューラルネットワークの生成は急速に発展しており、RetrieveGANはこれのもう1つの確認です。シーンのテキストによる説明に基づくアルゴリズムは、既存の画像のフラグメントを使用して、一意の新しい画像を作成します。結果として得られる画像には多くのアーティファクトがあり、あまり信頼できるようには見えませんが、将来的には、これによりフォトモンタージュの分野で新しい可能性が開かれる可能性があります。
エレベーター乗客追跡
コンピュータービジョンと機械学習の進歩のおかげで、人間の追跡はさらに効果的になっています。大規模な開発者から委託された上海の研究者グループは、エレベーターの行動をリアルタイムで社会的に管理するシステムを開発しました。このシステムは、エレベーター内の不審なアクティビティを検出することができます。したがって、作成者は、破壊行為、性的嫌がらせ、薬物取引を防ぐことを望んでいます。システムは、人々が特定の階に頻繁に立ち寄るかどうかも通知します。たとえば、アパートで違法に機能するケータリングを特定することはすでに可能です。このシステムはすでにインストールされており、数十万のエレベーターを監視しています。
これは7月がどれほど激しいことが判明したかです。来月どのようなニュースが私たちにもたらされるか見てみましょう。清聴ありがとうございました!