しばらくの間バックエンドアプリケーションまたはデータベースを設計している場合は、ページ化されたクエリを実行するためのコードを作成した可能性があります。たとえば-このように:
SELECT * FROM table_name LIMIT 10 OFFSET 40
どうですか?
しかし、これがあなたがページネーションをした方法であるならば、私はあなたが最も効率的な方法でそれをしなかったことに注意することを残念に思います。
私と議論したいですか?時間を無駄にする 必要は あり ません。スラック、Shopify、およびMixmaxされ、すでに私は今日の話をしたいのトリックを使用して。 使用したことのない開発者バックエンドを少なくとも1つ挙げて、ページネーションを使用してクエリを実行します。 MVP(Minimum Viable Product、minimum viable product)および少量のデータを使用するプロジェクトでは、このアプローチは非常に適用可能です。いわば、それはうまくいきます。
OFFSETLIMIT
ただし、信頼性が高く効率的なシステムを最初から作成する必要がある場合は、そのようなシステムで使用されるデータベースへのクエリの効率に事前に注意する必要があります。
今日は、ページ化されたクエリ実行エンジンの広く使用されている(申し訳ありませんが)実装に関連する問題と、そのようなクエリを実行するときに高いパフォーマンスを実現する方法について説明します。
OFFSETとLIMITの何が問題になっていますか?
それがされているように言った、
OFFSETとLIMIT完全に大量のデータで作業する必要はありませんプロジェクトに自身を示しています。
この問題は、データベースがサーバーのメモリに収まらなくなるほどのサイズに成長したときに発生します。ただし、このデータベースを操作するときは、ページ化されたクエリを使用する必要があります。
この問題が顕在化するためには、ページネーションを使用して各クエリを実行するときに、DBMSが非効率的なフルテーブルスキャン操作に頼る状況が発生する必要があります(同時に、データの挿入および削除操作が発生する可能性があります) 、古いデータは必要ありません!)。
「フルテーブルスキャン」(または「シーケンシャルテーブルスキャン」、シーケンシャルスキャン)とは何ですか?これは、DBMSがテーブルの各行、つまりテーブルに含まれるデータを順番に読み取り、特定の条件に対してそれらをチェックする操作です。このタイプのテーブルスキャンは最も遅いことが知られています。実際には、実行されると、サーバーのディスクサブシステムを使用する多くのI / O操作が実行されます。この状況は、ディスクに保存されたデータの処理に関連する遅延によって悪化し、ディスクからメモリへのデータの転送はリソースを大量に消費する操作であるという事実によって悪化します。
たとえば、1億人のユーザーのレコードがあり、次の構造でクエリを実行しているとします。
OFFSET 50000000..。これは、DBMSがこれらすべてのレコードをロードし(そしてそれらは必要ありません!)、それらをメモリに配置し、その後、たとえば、で報告された20の結果を取得する必要があることを意味しLIMITます。
「100,000から50,000から50020の行を選択」のように見えるとしましょう。つまり、システムは最初に50,000行をロードしてクエリを実行する必要があります。彼女がしなければならない不必要な仕事の量を見てください。
信じられない場合は、db-fiddle.comを使用して作成した例をご覧ください。

db-fiddle.comの例
左側のフィールド
Schema SQLには、データベースに100,000行を挿入するコードがあり、右側のフィールドにはQuery SQL、2つのクエリが示されています。最初の遅い、次のようになります。
SELECT *
FROM `docs`
LIMIT 10 OFFSET 85000;
そして2つ目は、同じ問題に対する効果的な解決策です。
SELECT *
FROM `docs`
WHERE id > 85000
LIMIT 10;
これらのリクエストを満たすに
Runは、ページ上部のボタンをクリックするだけです。これを行った後、クエリの実行時間に関する情報を比較してみましょう。非効率的なクエリの実行には、2番目のクエリの実行よりも少なくとも30倍長い時間がかかることがわかります(この時間は起動ごとに異なります。たとえば、システムは最初の要求が完了するまでに37ミリ秒かかったと報告する場合があり、 2番目の実行-1ミリ秒)。
さらにデータがある場合は、すべてがさらに悪化します(これを確認するために、1,000万行の私の例を見てください)。
ここで説明したことにより、データベースクエリが実際にどのように処理されるかについての洞察が得られるはずです。
値が大きいほど、
OFFSET -リクエストにかかる時間が長くなります。
OFFSETとLIMITの組み合わせの代わりに何を使用する必要がありますか?
代わりに組み合わせ
OFFSET、LIMITそれは以下のスキームに従って構築された構造を使用して価値があります:
SELECT * FROM table_name WHERE id > 10 LIMIT 20
これは、カーソルベースのページネーションクエリの実行です。
ローカルに保存された現在の
OFFSETを保存LIMITして各リクエストに送信する代わりに、最後に受信したプライマリキー(通常は-a ID)とを保存する必要がありLIMIT、その結果、上記のようにプロンプトが表示されます。
どうして?実際には、最後に読み取った行の識別子を明示的に指定することで、必要なデータの検索を開始する必要がある場所をDBMSに通知します。さらに、キーを使用することで検索が効率的に実行されるため、システムは指定された範囲外の行に気を取られる必要がありません。
さまざまなクエリの次のパフォーマンス比較を見てみましょう。これは効果のないクエリです。
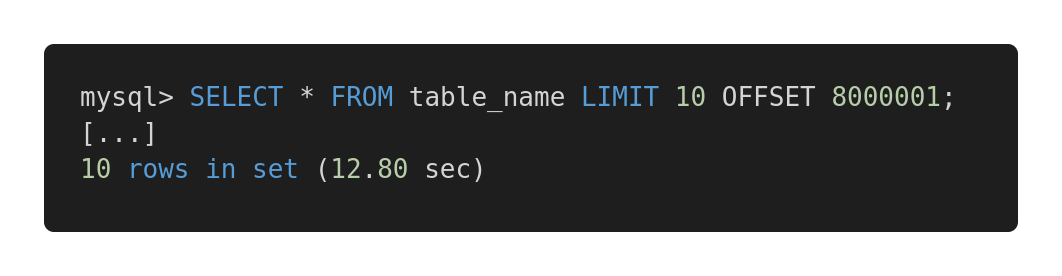
遅いクエリ
そして、これがこのクエリの最適化されたバージョンです。

クイッククエリ
両方のクエリは、まったく同じ量のデータを返します。ただし、最初の処理には12.80秒、2番目の処理には0.01秒かかります。違いを感じますか?
考えられる問題
提案されたクエリ実行方法が効率的に機能するためには、テーブルに、整数識別子などの一意の順次インデックスを含む1つまたは複数の列が必要です。場合によっては、これにより、データベースでの作業速度を上げるためにそのようなクエリを使用することの成功を判断できます。
当然のことながら、クエリを設計するときは、テーブルのアーキテクチャの特性を考慮し、既存のテーブルに最もよく表示されるメカニズムを選択する必要があります。たとえば、関連データが大量にあるクエリで作業する必要がある場合は、この記事がおもしろいと思うかもしれません。
主キーがないという問題に直面した場合、たとえば、多対多の関係を持つテーブルがある場合、従来の使用方法
OFFSETとLIMITが確実に機能します。ただし、そのアプリケーションは、潜在的に遅いクエリの実行につながる可能性があります。このような場合、ページ化されたクエリを整理するためだけに必要な場合でも、自動インクリメントのプライマリキーを使用することをお勧めします。
このトピックに興味がある場合-ここ、ここ、ここ-いくつかの有用な資料。
結果
私たちが引き出すことができる主な結論は、私たちが話しているデータベースのサイズに関係なく、クエリの実行速度を分析する必要があるということです。現在、ソリューションのスケーラビリティは非常に重要であり、特定のシステムでの作業の最初からすべてを正しく設計すれば、将来的には、開発者を多くの問題から救うことができます。
データベースクエリをどのように分析および最適化しますか?
