
この記事では、エンジニアが何百万ものユーザーから要求されている大規模なサービスを操作するのに役立ついくつかの一般的なパターンを収集します。
著者の経験では、これは完全なリストではありませんが、本当に効果的なヒントです。それでは、始めましょう。Mail.ru CloudSolutions
のサポートにより翻訳されました。
最初のレベル
以下にリストされている対策は、比較的簡単に実装できますが、高いリターンが得られます。これまでに試したことがない場合は、大幅な改善に驚かれることでしょう。
コードとしてのインフラストラクチャ
最初のアドバイスは、インフラストラクチャをコードとして実装することです。つまり、インフラストラクチャ全体をプログラムで展開する方法が必要です。複雑に聞こえますが、実際には次のコードについて話しています。
100台の仮想マシンを展開する
- Ubuntuで
- 各2GB RAM
- 次のコードがあります
- そのようなパラメータで
ソース制御を使用して、インフラストラクチャの変更をすばやく追跡して元に戻すことができます。
私のモダニストは、Kubernetes / Dockerを使用して上記のすべてを実行できると言っていますが、彼は正しいです。
Chef、Puppet、またはTerraformを使用して自動化を提供することもできます。
継続的な統合と配信
スケーラブルなサービスを作成するには、プルリクエストごとにビルドとテストのパイプラインを用意することが重要です。テストが最も単純な場合でも、少なくとも、デプロイするコードがコンパイルされることを確認します。
この段階で毎回、あなたは質問に答えています:私のアセンブリはコンパイルされてテストに合格しますか、それは有効ですか?これは低いバーのように聞こえるかもしれませんが、多くの問題を解決します。
これらのチェックボックスを表示することほど美しいものはありません。
このテクノロジーについては、Github、CircleCI、またはJenkinsをチェックしてください。
ロードバランサー
したがって、トラフィックをリダイレクトするためにロードバランサーを起動し、すべてのノードの負荷が等しいこと、または障害が発生した場合にサービスが機能することを確認します。
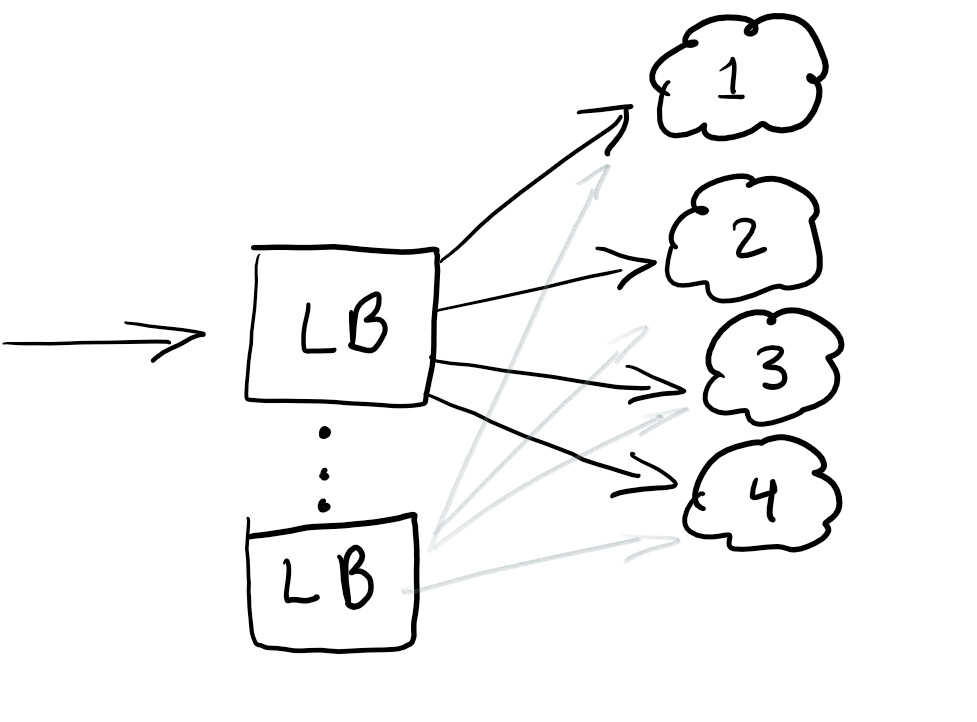
ロードバランサーは通常、トラフィックの分散を支援するのに適しています。ベストプラクティスは、単一の障害点が発生しないようにバランスを崩すことです。
通常、ロードバランサーは使用しているクラウドで構成されます。
リクエストのRayID、相関ID、またはUUID
アプリケーションで次のようなメッセージが表示されたときにエラーが発生したことがありますか。「問題が発生しました。このIDを保存して、サポートチームに送信してください」?
一意の識別子、相関ID、RayID、またはそれらのバリエーションのいずれかは、ライフサイクル全体でリクエストを追跡できるようにする一意の識別子です。これにより、ログでリクエストのパス全体を追跡できます。
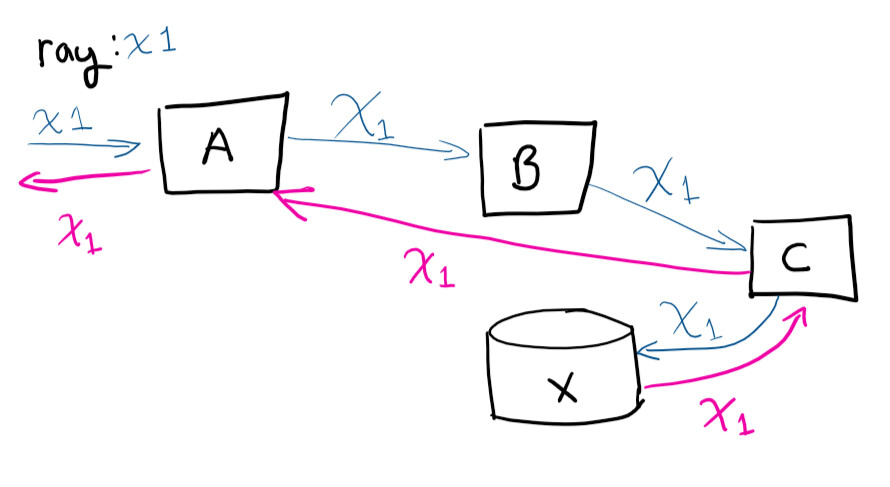
ユーザーがシステムAにリクエストを送信し、次にAがBに連絡し、Cに連絡してXに保存すると、リクエストはAに戻ります。
仮想マシンにリモート接続してリクエストパスをトレースしようとした場合(および発生しているコールを手動で関連付けようとした場合)、あなたは夢中になるでしょう。一意の識別子を使用すると、作業がはるかに簡単になります。これは、サービスの成長に合わせて時間を節約するための最も簡単な方法の1つです。
中間レベル
ここでのアドバイスは以前のアドバイスよりも複雑ですが、適切なツールを使用するとタスクが簡単になり、中小企業でも投資収益率が得られます。
一元化されたロギング
おめでとう!100台の仮想マシンを展開しました。翌日、CEOがやって来て、サービスのテスト中に受け取ったエラーについて不平を言います。上記で説明した対応するIDが報告されますが、クラッシュの原因となったIDを見つけるには、100台のマシンのログを調べる必要があります。そして、彼女は明日のプレゼンテーションの前に見つけられる必要があります。
これは楽しい冒険のように聞こえますが、すべての雑誌を1か所から検索できるようにすることをお勧めします。ELKスタックの組み込み機能でログを一元化する問題を解決しました。検索可能なログ収集をサポートします。これは、特定のログを見つける際の問題を解決するのに本当に役立ちます。ボーナスとして、あなたはそのような図や他の楽しいものを作成することができます。
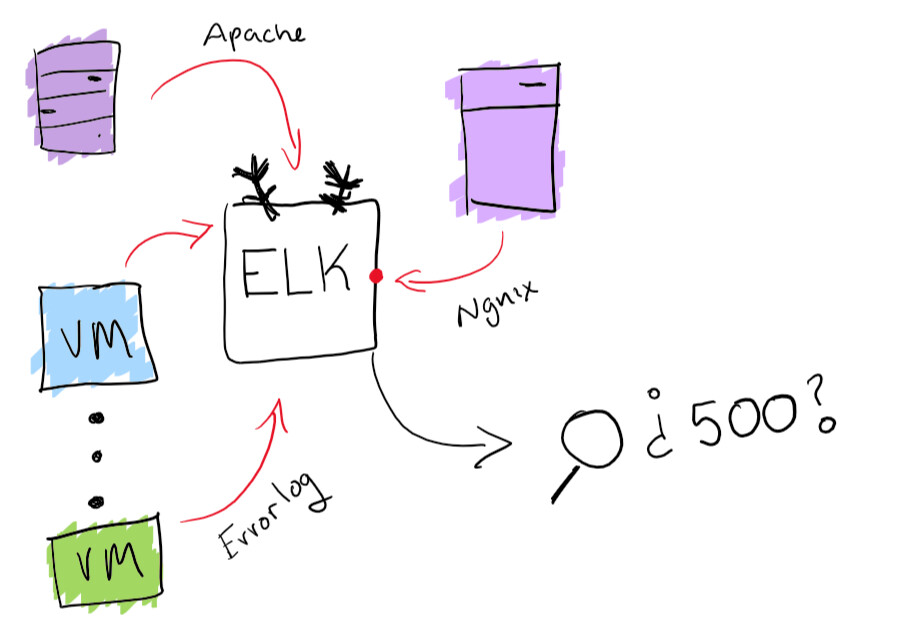
ELKスタック機能
監視エージェント
サービスが稼働しているので、スムーズに実行されることを確認する必要があります。これを行う最良の方法は、並行して実行される複数のエージェントを実行し、エージェントが実行され、基本的な操作が実行されていることを確認することです。
この時点で、実行中のアセンブリが正常に機能し、正常に機能していることを確認します。
中小規模のプロジェクトの場合、APIの監視と文書化にはPostmanをお勧めします。ただし、一般的には、障害がいつ発生したかを知り、タイムリーなアラートを受信する方法があることを確認する必要があります。
負荷に基づく自動スケーリング
とても簡単です。リクエストを処理する仮想マシンがあり、80%のメモリ使用量に近づいている場合は、そのリソースを増やすか、クラスターに仮想マシンを追加することができます。これらの操作の自動実行は、負荷がかかった状態での弾性力の変化に優れています。ただし、使用する金額に常に注意し、妥当な制限を設定する必要があります。
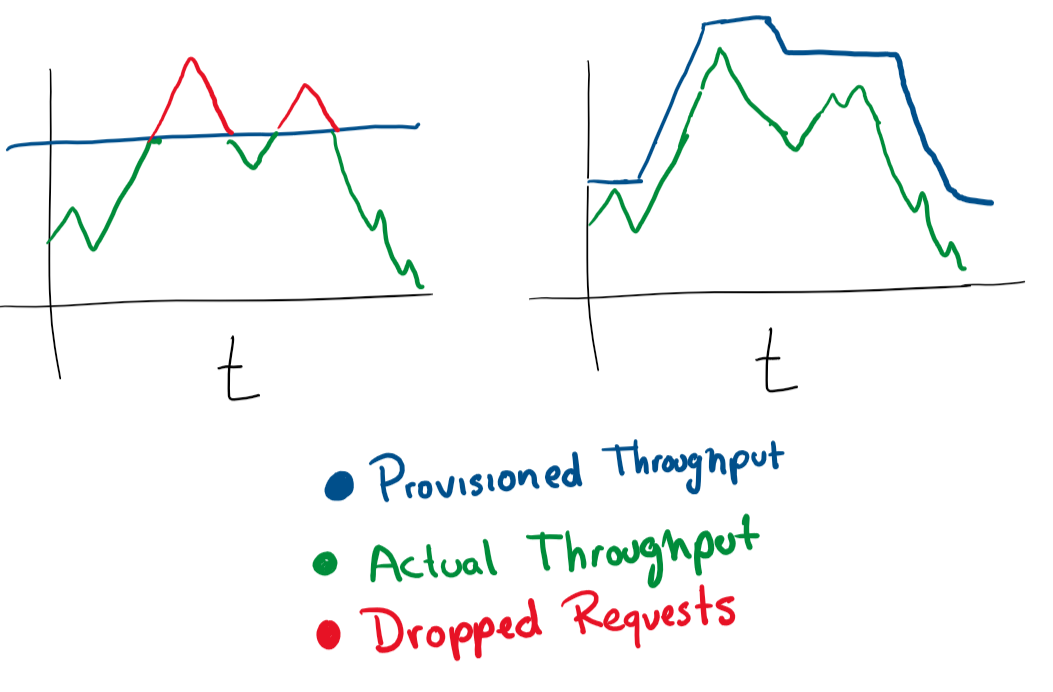
ほとんどのクラウドサービスでは、より多くのサーバーまたはより強力なサーバーを使用して自動スケーリングを構成できます。
実験システム
更新を安全に展開するための良い方法は、1時間以内に1%のユーザーに対して何かをテストできるようにすることです。あなたは確かにそのようなメカニズムが機能しているのを見てきました。たとえば、Facebookは視聴者の一部に異なる色を表示したり、フォントサイズを変更して、ユーザーが変更をどのように認識しているかを確認します。これはA / Bテストと呼ばれます。
新しい機能をリリースすることでさえ、実験として実行し、それをリリースする方法を理解することができます。また、サービスの低下の原因となる機能を考慮して、その場で構成を「記憶」または変更する機能も利用できます。
上級レベル
実装が非常に難しいヒントをいくつか紹介します。おそらくもう少しリソースが必要になるので、中小企業がこれを処理するのは難しいでしょう。
青緑色の展開
これは私が「Erlang」展開方法と呼んでいるものです。 Erlangは、電話会社が登場したときに広く使用されていました。ソフトスイッチは、電話のルーティングに使用されています。これらのスイッチでのソフトウェアの主な焦点は、システムのアップグレード中に通話を切断しないことでした。 Erlangには、前のモジュールをクラッシュさせることなく新しいモジュールをロードするための優れた方法があります。
このステップは、ロードバランサーの存在に依存します。ソフトウェアのバージョンNがあり、バージョンN +1をデプロイするとします。
あなたは可能性だけのサービスを停止し、ユーザーにとって便利である時には次のバージョンを導入し、いくつかのダウンタイムを取得します。しかし、あなたが持っているとしましょう本当に厳格なSLA用語。つまり、SLA 99,99%は、1年に52分しかオフラインにできないことを意味します。
これを本当に実現したい場合は、同時に2つの展開が必要です。
- 現在あるもの(N);
- 次のバージョン(N + 1)。
自分で積極的に回帰を追跡しながら、トラフィックの一部を新しいバージョン(N + 1)にリダイレクトするようにロードバランサーに指示します。
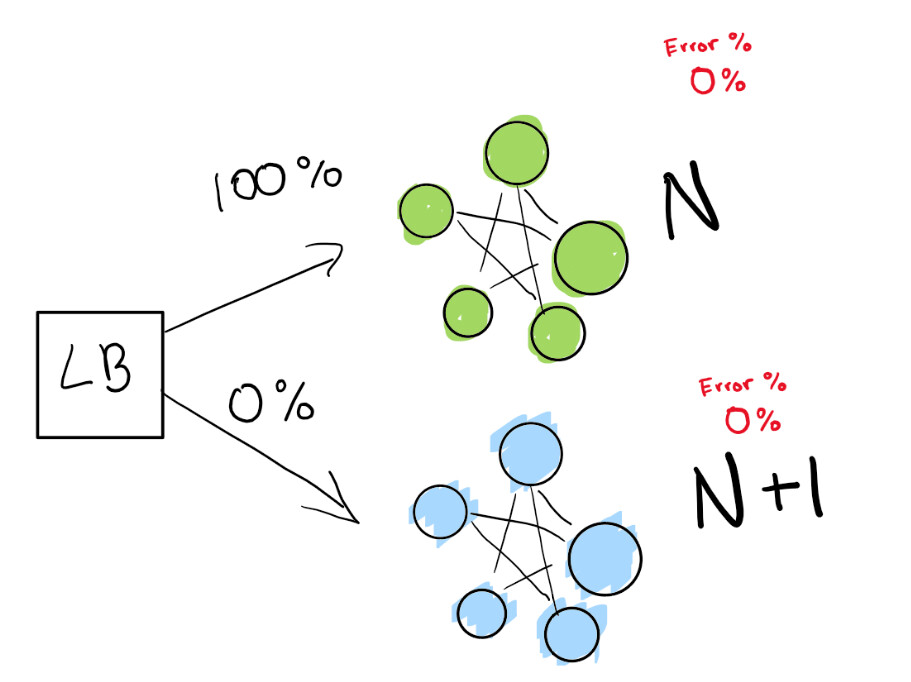
ここに、正常に機能するグリーンデプロイメントNがあります。この展開の次のバージョンに移行しようとしています。
最初に、N + 1展開が少ないトラフィックで機能するかどうかを確認するために、非常に小さなテストを送信します。
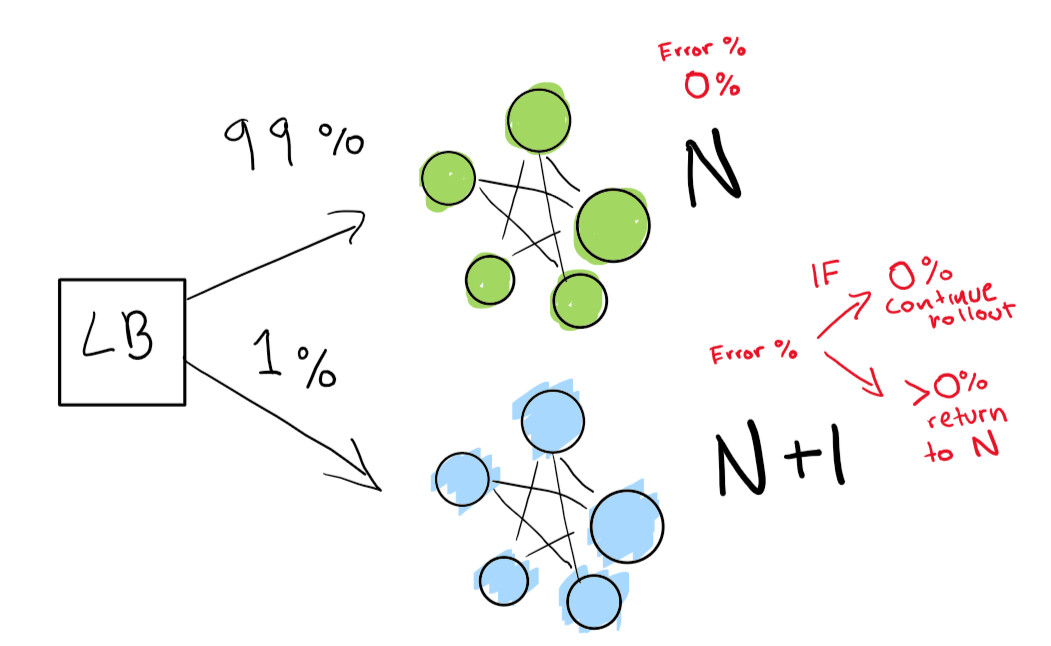
最後に、展開が完了するまで実行される一連の自動チェックがあります。あなたがいる場合には非常に、非常に慎重に、あなたも悪い回帰した場合の迅速なロールバックのために永遠にあなたのNの展開を保つことができます。
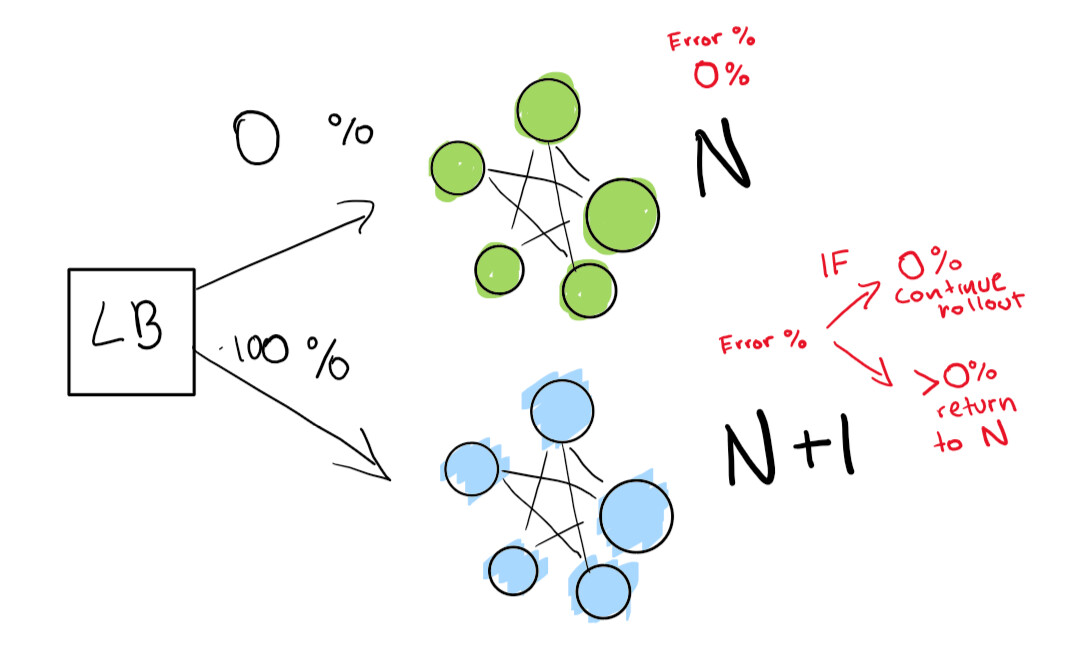
さらに高度なレベルに進みたい場合は、青緑色のデプロイのすべてを自動的に実行します。
異常の検出と自動軽減
一元化されたロギングと優れたログ収集があることを考えると、すでにより高い目標を設定できます。たとえば、障害を事前に予測します。モニターとログでは、機能が追跡され、さまざまな図が作成されます。何がうまくいかないかを事前に予測できます。
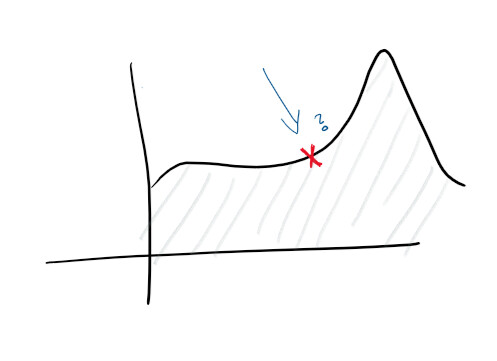
異常の発見で、あなたはサービスが発行する手がかりのいくつかを研究し始めます。たとえば、CPU使用率の急上昇は、ハードドライブに障害が発生していることを示している可能性がありますが、要求の急増は、スケーリングが必要であることを意味します。この種の統計により、サービスをプロアクティブにすることができます。
この洞察により、あらゆる次元でスケーリングし、マシン、データベース、接続、およびその他のリソースの特性をプロアクティブかつリアクティブに変更できます。
それで全部です!
この優先順位のリストは、クラウドサービスを立ち上げる場合に多くの問題を回避します。
元の記事の著者は、読者にコメントを残して変更を加えるように勧めています。記事はオープンソースとして配布され、作成者はGithubでプルリクエストを受け入れます。
このトピックについて他に読むべきこと: