
出典:Vecteezy
はい、線形回帰だけではありません
。5つの機械学習アルゴリズムに簡単に名前を付けてください。
多くの回帰アルゴリズムに名前を付けることはまずありません。結局のところ、広く使用されている回帰アルゴリズムは、主にその単純さのために線形回帰だけです。ただし、オプションが制限され、操作の自由度が制限されているため、線形回帰は実際のデータには適用できないことがよくあります。多くの場合、評価および新しい研究アプローチとの比較のためのベースラインモデルとしてのみ使用されます。Mail.ruクラウドソリューション
チーム記事を翻訳しました。その著者は5つの回帰アルゴリズムについて説明しています。これらは、SVM、意思決定ツリー、ニューラルネットワークなどの一般的な分類アルゴリズムとともにツールボックスに含める価値があります。
1.ニューラルネットワークの回帰
理論
ニューラルネットワークは非常に強力ですが、一般的に分類に使用されます。信号はニューロンの層を通過し、いくつかのクラスの1つに一般化されます。ただし、最後のアクティブ化関数を変更することで、回帰モデルに非常に迅速に適合させることができます。
各ニューロンは、一般化と非線形性の目的を果たすアクティベーション関数を介して、以前の接続からの値を送信します。通常、アクティベーション関数は、シグモイドまたはReLU(整流線形ユニット)関数のようなものです。
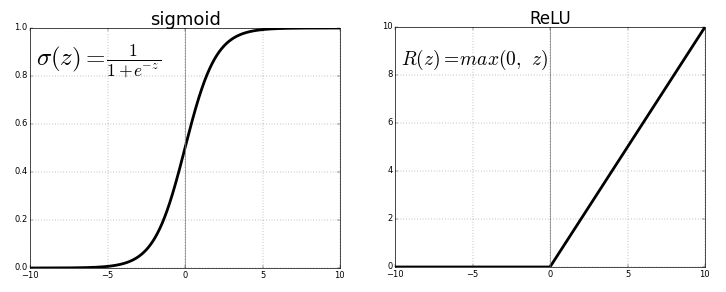
ソース。無料画像
しかし、最後の活性化関数(出力ニューロン)を線形のものに置き換えるアクティベーション機能では、出力信号を固定クラス以外の多くの値にマッピングできます。したがって、出力は、入力信号を任意の1つのクラスに割り当てる確率ではなく、ニューラルネットワークがその観測を固定する連続値になります。この意味で、ニューラルネットワークは線形回帰を補完していると言えます。
ニューラルネットワークの回帰には、(複雑さに加えて)非線形性という利点があります。これは、ニューラルネットワークの初期のシグモイドおよびその他の非線形アクティベーション関数で導入できます。ただし、アクティベーション関数としてReLUを使いすぎると、ReLUは負の値間の相対的な違いを無視するため、モデルは負の値の出力を回避する傾向がある可能性があります。
これは、ReLUの使用を制限し、対応するアクティベーション関数の負の値を追加するか、トレーニングの前にデータを厳密に正の範囲に正規化することで解決できます。
実装
Kerasを使用して、人工神経ネットワークの構造を構築しましょう。ただし、最後の層が線形活性化を伴う高密度層または線形活性化を伴う単なる層である場合、畳み込み神経ネットワークまたは別のネットワークでも同じことができます。(スペースを節約するために、Kerasのインポートはリストされていないことに注意してください)。
model = Sequential()
model.add(Dense(100, input_dim=3, activation='sigmoid'))
model.add(ReLU(alpha=1.0))
model.add(Dense(50, activation='sigmoid'))
model.add(ReLU(alpha=1.0))
model.add(Dense(25, activation='softmax'))
#IMPORTANT PART
model.add(Dense(1, activation='linear'))
ニューラルネットワークの問題は、常に分散が大きく、オーバーフィットする傾向があることです。上記のコード例には、SoftMaxやsigmoidなどの非線形性の原因が多数あります。
ニューラルネットワークが純粋に線形構造のトレーニングデータでうまく機能する場合は、線形で高度に分散したニューラルネットワークをエミュレートする切り捨てられた決定ツリー回帰を使用する方がよい場合がありますが、データサイエンティストは、深さ、幅、およびその他の属性をより適切に制御して、オーバーフィットを制御できます。
2.意思決定ツリーの回帰
理論
分類と回帰の決定ツリーは、yes / noノードでツリーを構築することによって機能するという点で非常に似ています。ただし、分類リーフノードの結果は単一のクラス値(たとえば、バイナリ分類問題の場合は1または0)になりますが、回帰ツリーは最終的に連続モードの値(たとえば、4593.49または10.98)になります。
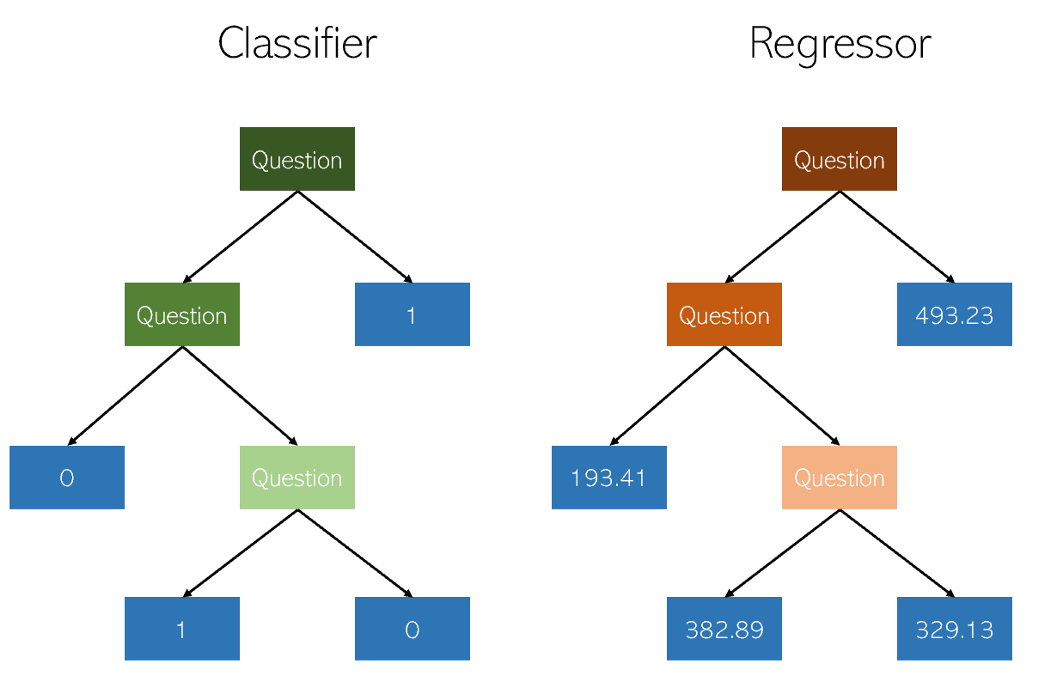
著者の説明
単なる機械学習の問題としての回帰の特定の高度に分散した性質のため、意思決定ツリーのリグレッサーは慎重に削除する必要があります。ただし、回帰アプローチは不規則です。連続的なスケールで値を計算する代わりに、特定のエンドノードに到達します。リグレッサのクリップが多すぎると、リーフノードが少なすぎて目的を適切に果たすことができません。
したがって、意思決定ツリーは、最も自由度が高くなるように(可能な回帰出力値はリーフノードの数です)、深すぎるほど十分ではないようにプルーニングする必要があります。トリミングしないと、回帰の性質上、すでに高度に分散しているアルゴリズムが非常に複雑になります。
実装
デシジョンツリー回帰は、次の場所で簡単に作成できます
sklearn。
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor()
model.fit(X_train, y_train)
非常に重要な決定木の回帰のパラメータので、検索エンジン最適化ツールのパラメータを使用することをお勧めします
GridCVからsklearn、このモデルのために右の勧告を見つけるために、。
パフォーマンスを正式に評価するとき
K-foldは、標準テストの代わりにテストtrain-test-splitを使用して、高分散モデルの機密性の高い結果に違反する可能性のある後者のランダム性を回避します。
ボーナス:決定ツリーの近親者であるランダムフォレストアルゴリズムも、リグレッサーとして実装できます。ランダムフォレストリグレッサは、ツリー構築アルゴリズムの性質における冗長性と欠陥の間の微妙なバランスのために、回帰の決定ツリーよりもパフォーマンスが優れている場合とそうでない場合があります(通常は分類のパフォーマンスが優れています)。
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor()
model.fit(X_train, y_train)
3.LASSO回帰
なげなわ回帰法(LASSO、最小絶対収縮および選択演算子)は、強い多重共線性(つまり、相互の特徴の強い相関)を示すデータに特別に適合された線形回帰のバリエーションです。
変数の選択やパラメーターの除外など、モデル選択の一部を自動化します。LASSOは収縮を使用します。これは、データ値が中心点(たとえば平均)に近づくプロセスです。

著者のイラスト。圧縮
プロセスの簡素化された視覚化圧縮プロセスは、回帰モデルにいくつかの利点を追加します。
- 真のパラメータのより正確で安定した推定。
- サンプリングエラーとアウトオブサンプリングを削減します。
- 空間変動の平滑化。
投げ縄は、モデルの複雑さを調整してデータの複雑さを補正するのではなく、高分散ニューラルネットワークや意思決定ツリーの回帰方法のように、データの複雑さを軽減しようとします。このプロセスでは、なげなわは、低分散法で相関性の高い冗長な機能を自動的に削除または歪めるのに役立ちます。
なげなわ回帰は、L1正規化を使用します。つまり、エラーを絶対値で重み付けします。たとえば、より重大なエラーをより強力に罰するために、エラーを2乗で重み付けするL2正規化の代わりに。
一部の係数がゼロになり、モデルから除外される可能性があるため、この正規化により、係数の少ないモデルがまばらになることがよくあります。これにより、解釈が可能になります。
実装
sklearn回帰は、投げ縄そうでない場合は、手動で実行しなければならないタスクを自動化し、異なる基本的なパラメータや学習パスを持つ多くの訓練を受けたモデルの最も効果的な選択クロスバリデーションモデルが付属しています。
from sklearn.linear_model import LassoCV
model = LassoCV()
model.fit(X_train, y_train)
4.リッジ回帰(リッジ回帰)
理論
リッジ回帰またはリッジ回帰は、圧縮を適用するという点でLASSO回帰と非常によく似ています。どちらのアルゴリズムも、互いに独立していない(共直線性)多数の機能を備えたデータセットに適しています。
ただし、これらの最大の違いは、リッジ回帰が正規化L2を使用することです。つまり、LASSO回帰のように、どの係数もゼロになりません。代わりに、係数はますますゼロに近づいていますが、L2正規化の性質により、それを達成するインセンティブはほとんどありません。
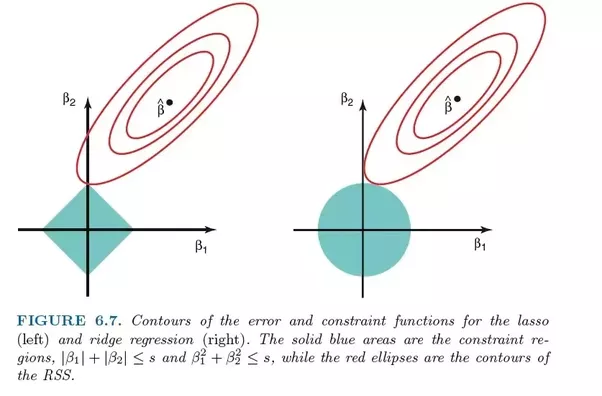
なげなわ回帰(左)と尾根回帰(右)のエラーの比較。 Ridge RegressionはL2正規化を使用するため、その領域は円に似ていますが、L1投げ縄正規化は直線を描画します。無料画像。ソース
なげなわでは、エラー5からエラー4への改善は、4から3への改善、3から2、2から1、1から0への改善と同じ方法で重み付けされます。したがって、より多くの係数がゼロに達し、より多くの機能が削除されます。
ただし、リッジ回帰では、エラー5からエラー4への改善は5²-4²= 9として計算されますが、4から3への改善は7としてのみ重み付けされます。改善に対する報酬は徐々に減少します。したがって、削除される機能は少なくなります。
リッジ回帰は、それぞれの影響が小さい多数の変数に優先順位を付けたい状況に最適です。モデルが複数の変数を考慮する必要があり、それぞれが中程度から大きな効果を持っている場合は、なげなわが最良の選択です。
実装
リッジ回帰
sklearnは、次のように実装できます(以下を参照)。なげなわ回帰と同様にsklearn、多くの訓練されたモデルの中から最良のものの選択を相互検証するための実装があります。
from sklearn.linear_model import RidgeCV
model = Ridge()
model.fit(X_train, y_train)
5.ElasticNet回帰
理論
ElasticNetは、L1とL2の正規化を組み合わせることにより、RidgeRegressionとLassoRegressionの最高の組み合わせを目指しています。
LassoとRidgeRegressionは、2つの異なる正規化方法です。どちらの場合も、λは罰金のサイズを制御する重要な要素です。
- λ = 0, , .
- λ = ∞, - . , , .
- 0 < λ < ∞, λ , .
λパラメータに、ElasticNet回帰は追加のパラメータαを追加します。これは、正規化L1とL2がどの程度「混合」されるべきかを測定します。ときαは0で、このモデルは純粋なリッジ回帰であり、αが1であるとき、それは純粋な投げ縄回帰です。
「混合係数」αは、損失関数でL1とL2の正規化をどの程度考慮する必要があるかを定義するだけです。3つの一般的な回帰モデル(Ridge、Lasso、ElasticNet)はすべて、係数のサイズを縮小することを目的としていますが、それぞれ動作が異なります。
実装
ElasticNetは、sklearnの相互検証モデルを使用して実装できます。
from sklearn.linear_model import ElasticNetCV
model = ElasticNetCV()
model.fit(X_train, y_train)
このトピックについて他に読むべきこと: