
今日は、tarantool /カートリッジのフェイルオーバーについての私の考えについて少しお話します。まず、カートリッジとは何かについて簡単に説明します。これは、tarantool内で機能し、タランチュラを1つの条件付き「クラスター」に結合するluaコードです。これは2つの理由によるものです。
- すべてのタランチュラは、他のすべてのタランチュラのネットワークアドレスを知っています。
- タランチュラは、UDPを介して定期的に相互に「ping」を実行し、誰が生きているのか、誰が生きていないのかを理解します。ここで私は意図的に少し単純化します。pingアルゴリズムは単なる要求-応答よりも複雑ですが、これは解析にとってそれほど重要ではありません。興味があれば-SWIMアルゴリズムをググってください。
クラスター内では、通常、すべてがステートフル(マスター/レプリカ)タランチュラとステートレス(ルーター)タランチュラに分割されます。ステートレスタランチュラはデータの保存を担当し、ステートレスタランチュラはリクエストのルーティングを担当します。
この図は次のようになります
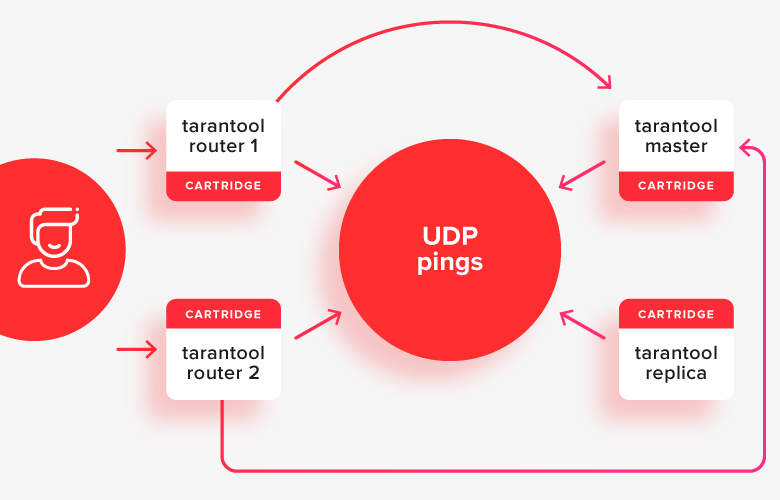
。クライアントはアクティブなルーターのいずれかにリクエストを送信し、現在アクティブなマスターであるストアの1つにリクエストをリダイレクトします。写真では、これらのパスが矢印で示されています。
今、私は物事を複雑にし、リーダーを選ぶことについての会話にシャーディングを導入したくありませんが、彼との状況は少し異なります。唯一の違いは、ルーターがストアから移動するレプリカセットを決定する必要があることです。
まず、ノードが互いのアドレスを学習する方法について説明しましょう。これを行うために、それらのそれぞれは、クラスタートポロジ、つまり、すべてのメンバーのネットワークアドレスに関する情報、およびそれらの誰が誰であるか(状態の有無にかかわらず)を含むyamlファイルをディスク上に持っています。さらに、潜在的に追加のカスタマイズがありますが、今のところ、それは脇に置いておきましょう。構成ファイルには、クラスター全体の設定が含まれており、各タランチュラで同じです。それらに変更が加えられると、すべてのタランチュラに対して同期的に行われます。
これで、クラスター内の任意のタランチュラのAPIを介して構成を変更できます。他のすべてのユーザーに接続し、新しいバージョンの構成を送信し、すべてのユーザーがそれを適用します。新しいバージョンが存在する場合は、どこでも同じです。
シナリオ-ノード障害、スイッチオーバー
ルーターに障害が発生した場合、すべてが多かれ少なかれ単純です。クライアントは他のアクティブなルーターに移動するだけで、目的のストアにリクエストを配信します。しかし、たとえば、Storajaの1人のマスターが倒れた場合はどうなりますか?
現在、UDP pingに依存する、このような場合の「ナイーブ」アルゴリズムを実装しています。レプリカは、pingに対するマスターからの応答を短時間「認識」しない場合、マスターがフォールダウンしたと見なし、マスター自体になり、読み取り専用から読み取り/書き込みモードに切り替わります。ルーターは同じように動作します。マスターからのping応答時間がない場合は、トラフィックをレプリカに切り替えます。
これは、ノードの半分が何らかのネットワークの問題によって別のノードから分離されているスプリットブレインの状況を除いて、単純なケースでは比較的うまく機能します。
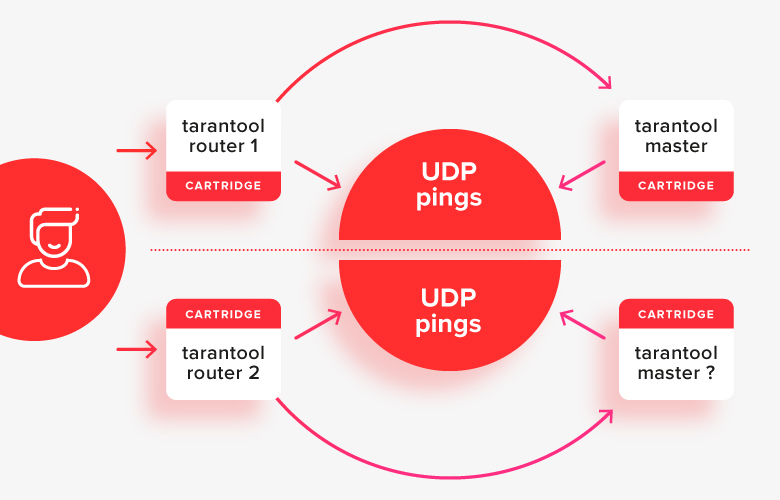
この状況では、ルーターはクラスターの「残りの半分」が使用できないことを認識し、それらの半分をメインと見なし、システムに同時に2つのマスターがあることがわかります。これは、解決すべき最初の重要なケースです。
シナリオ-失敗時に構成を編集する
もう1つの重要なシナリオは、クラスター内で障害が発生したタランチュラを新しいタランチュラに置き換えるか、レプリカまたはルーターの1つが使用できないときにクラスターにノードを追加することです。
通常の操作では、クラスター内のすべてが使用可能になると、APIを介して任意のノードに接続し、構成を編集するように依頼できます。前述したように、ノードは新しい構成をクラスター全体に「ロールアウト」します。
ただし、誰かが利用できない場合、新しい構成を適用することはできません。これらのノードが再び利用可能になると、クラスター内のどのノードが正しい構成で、どれが正しくないかが明確にならないためです。それでも、ノードが相互にアクセスできないということは、ノード間にスプリットブレインがあることを意味している可能性があります。また、構成を編集することは、さまざまな方法でさまざまな半分で誤って編集する可能性があるため、単に安全ではありません。
これらの理由により、誰かが不在の場合にAPIを介して構成を編集することを禁止するようになりました。これは、ディスク上でのみ、テキストファイルを介して(手動で)修正できます。ここでは、自分が何をしているのかをよく理解し、非常に注意する必要があります。自動化はまったく役に立ちません。
これは操作を不便にします、そしてこれは解決されるべき2番目のケースです。
シナリオ-安定したフェイルオーバー
ナイーブフェイルオーバーモデルのもう1つの問題は、マスターに障害が発生した場合のマスターからレプリカへの切り替えがどこにも記録されないことです。すべてのノードが独自に切り替えることを決定し、マスターが稼働すると、トラフィックは再びそれに切り替わります。
これは問題になる場合と問題にならない場合があります。マスターをオンにする前に、マスターはレプリカからのトランザクションログに「追いつく」ので、おそらく大きなデータの遅れはありません。この問題は、ネットワークに問題があり、パケットが失われた場合にのみ発生します。その場合、マスターの定期的な「フラッシュ」(フラッピング)が発生する可能性があります。
解決策は「強力な」コーディネーター(etcd / consul / tarantool)です
スプリットブレインの問題を回避し、クラスターが部分的に使用できない場合に構成を編集できるようにするには、ネットワークセグメンテーションに耐性のある強力なコーディネーターが必要です。コーディネーターは、3つのデータセンターに分散して、いずれかが失敗した場合でも運用を継続できるようにする必要があります。
現在、etcdとconsulを使用する2つの人気のあるRAFTベースのコーディネーターがいます。 tarantoolに同期レプリケーションが表示される場合は、これにも使用できます。
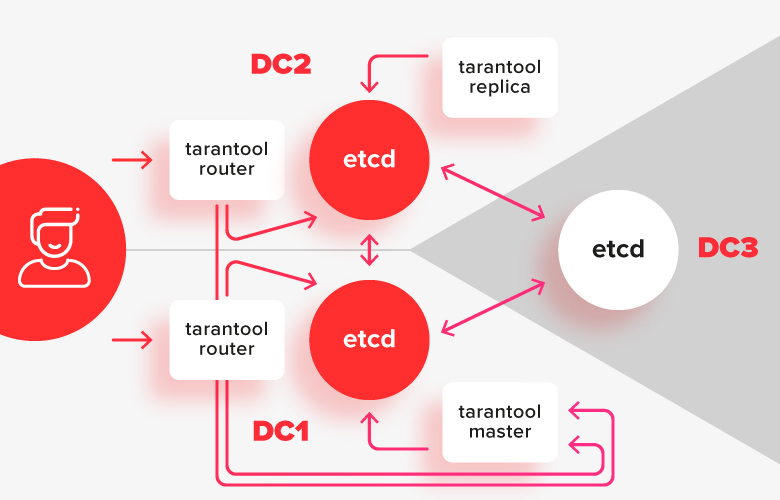
このスキームでは、タランチュラのインストールは2つのデータセンターに分割され、ローカルのetcdインストールに接続されます。 3番目のデータセンターのetcdのインスタンスはアービターとして機能するため、データセンターの1つに障害が発生した場合、それらのどれが大多数に残っているかを正確に言うことができます。
強力なコーディネーターによる構成管理
上で述べたように、コーディネーターがいなくて、タランチュラの1つに障害が発生した場合、どのノードのどの構成が正しいかを判断できないため、構成を一元的に編集できませんでした。
強力なコーディネーターの場合、すべてが簡単です。コーディネーターに構成を保存でき、タランチュラの各インスタンスには、ファイルシステムにこの構成のキャッシュが含まれます。コーディネーターに正常に接続されると、構成のコピーがコーディネーター内のものに更新されます。
構成の編集も簡単になります。任意のタランチュラのAPIを介して行うことができます。コーディネーターのロックを取得し、構成内の目的の値を置き換え、すべてのノードがそれを適用するまで待機し、ロックを解除します。または、最後の手段として、etcdの構成を手動で編集すると、クラスター全体に適用されます。
一部のタランチュラが利用できない場合でも、構成を編集することが可能になります。主なことは、ほとんどのコーディネーターノードが利用可能であるということです。
強力なコーディネーターとのフェイルオーバー
コーディネーターによるノードの信頼性の高い切り替えは、構成に加えて、レプリカ内の現在のマスターが誰であり、切り替えが行われた場所に関する情報をコーディネーターに格納するため、解決されます。
フェイルオーバーアルゴリズムは次のように変更されます。
- «» .
- UDP-, - , .
- , .
- .
- , read-only read-write.
- , , .
コーディネーターがあれば、羽ばたき保護も可能です。コーディネーターでは、切り替えの履歴全体を記録できます。最後のX分間にマスターがレプリカに切り替えた場合、逆切り替えは管理者によって明示的にのみ実行されます。
もう一つの重要なポイントは、いわゆる「フェンシング」です。他のデータセンターから切り離されている(または過半数を失ったコーディネーターに接続されている)タランチュラは、アクセスが失われたクラスターの残りの部分が過半数を持っている可能性が高いと想定する必要があります。つまり、特定の時間内に、過半数から切り離されたすべてのノードを読み取り専用にする必要があります。
コーディネーターが利用できない問題
コーディネーターと協力する方法について話し合っているときに、コーディネーターが倒れたが、すべてのタランチュラが無傷である場合は、クラスター全体を読み取り専用に変換しないようにするようにというリクエストを受け取りました。
最初はこれを行うのはあまり現実的ではないように見えましたが、クラスター自体がUDPpingを介して他のノードの可用性を監視していることを思い出しました。これは、UDP pingを通じてレプリカセット全体が有効であることが明らかな場合、それらをターゲットにでき、レプリカセット内のマスターの再選出をトリガーできないことを意味します。
このアプローチにより、特に更新のためにコーディネーターを再起動する必要がある場合に、コーディネーターの可用性について心配する必要がなくなります。
実施計画
現在、フィードバックを収集して実装を開始しています。何か言いたいことがあれば、コメントまたは個人的に書いてください。
計画は次のようなものです。
- tarantoolでetcdサポートを作成[完了]
- etcdをコーディネーターとして使用したフェイルオーバー、ステートフル[完了]
- タランチュラをコーディネーターとして使用し、ラッチするフェイルオーバー[完了]
- etcdへの構成の保存[進行中]
- クラスター修復用のCLIツールの作成[進行中]
- タランチュラに構成を保存する
- クラスターの一部が利用できない場合のクラスター管理
- フェンシング
- 羽ばたき保護
- 領事をコーディネーターとして使用したフェイルオーバー
- 領事館に構成を保存する
将来的には、強力なコーディネーターがいなくても、ほぼ確実にクラスターを完全に廃止する予定です。これは、タランチュラでの同期レプリケーションのRAFTベースの実装と一致する可能性があります。
謝辞
フィードバック、批判、テストを提供してくれたMail.ruの開発者と管理者に感謝します。