こんにちは、Habr!この記事では、現代のロシアのインターネット言語の周波数分析を行い、それを使用してテキストを解読する方法を紹介します。誰が気にする、カットの下で歓迎します!

ロシアのインターネット言語の頻度分析
現代のインターネット言語で多くのテキストを入手できる情報源として、ソーシャルネットワークVkontakteが採用されました。より正確には、これらはこのネットワークのさまざまなコミュニティの出版物に対するコメントです。私はコミュニティとして本物のサッカーを選びました。コメントの解析には、VkontakteAPIを使用しました。
def get_all_post_id():
sleep(1)
offset = 0
arr_posts_id = []
while True:
sleep(1)
r = requests.get('https://api.vk.com/method/wall.get',
params={'owner_id': group_id, 'count': 100,
'offset': offset, 'access_token': token,
'v': version})
for i in range(100):
post_id = r.json()['response']['items'][i]['id']
arr_posts_id.append(post_id)
if offset > 20000:
break
offset += 100
return arr_posts_id
def get_all_comments(arr_posts_id):
offset = 0
for post_id in arr_posts_id:
r = requests.get('https://api.vk.com/method/wall.getComments',
params={'owner_id': group_id, 'post_id': post_id,
'count': 100, 'offset': offset,
'access_token': token, 'v': version})
for i in range(100):
try:
write_txt('comments.txt', r.json()
['response']['items'][i]['text'])
except IndexError:
passその結果、約200MBのテキストが作成されました。ここで、どの文字が何回出現するかを数えます。
f = open('comments.txt')
counter = Counter(f.read().lower())
def count_letters():
count = 0
for i in range(len(arr_letters)):
count += counter[arr_letters[i]]
return count
def frequency(count):
arr_my_frequency = []
for i in range(len(arr_letters)):
frequency = counter[arr_letters[i]] / count * 100
arr_my_frequency.append(frequency)
return arr_my_frequency得られた結果は、ウィキペディアの結果と比較して、次のように表示できます。
1)比較表
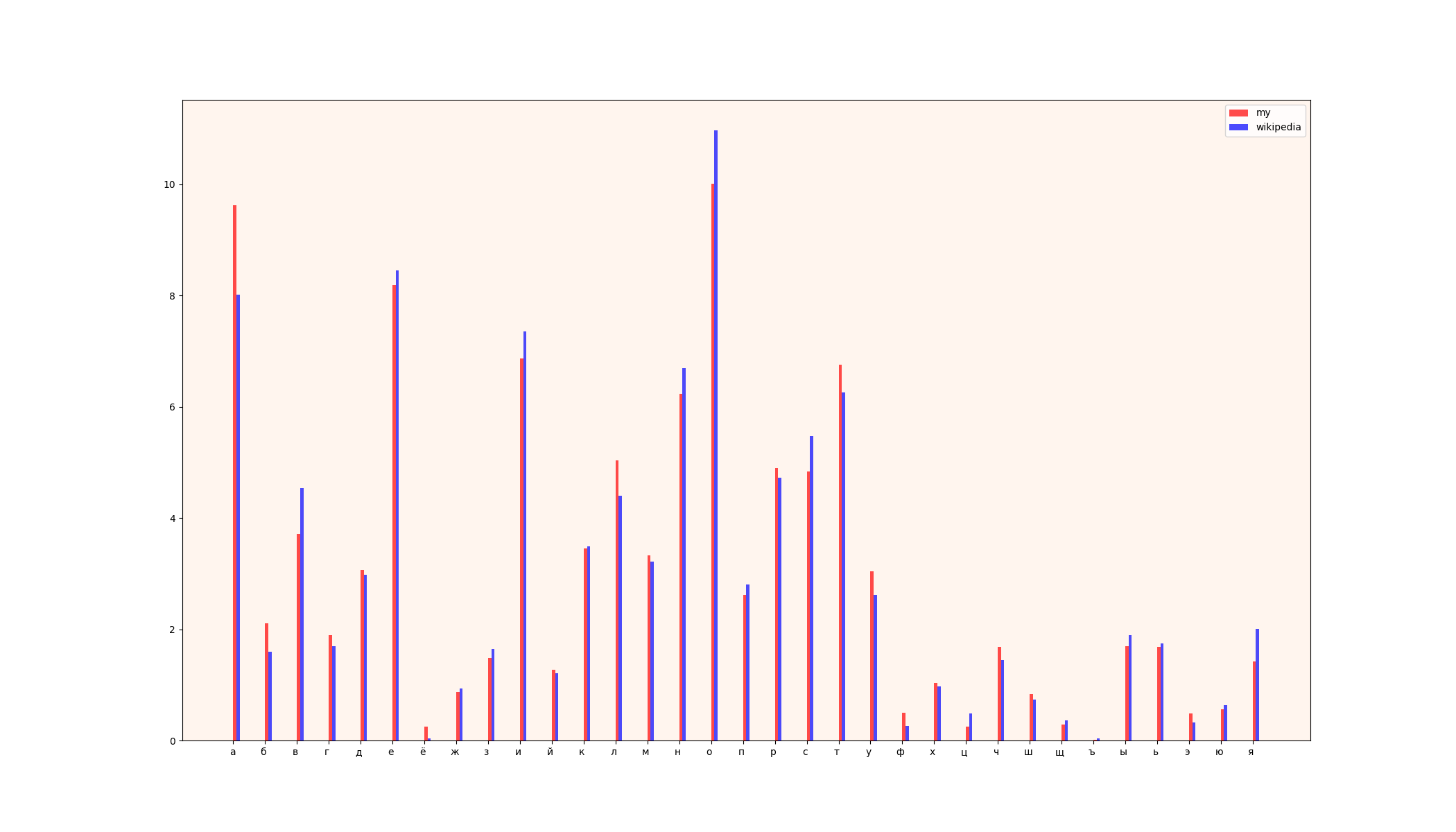
2)テーブル(左-ウィキペディアのデータ、右-私のデータ)
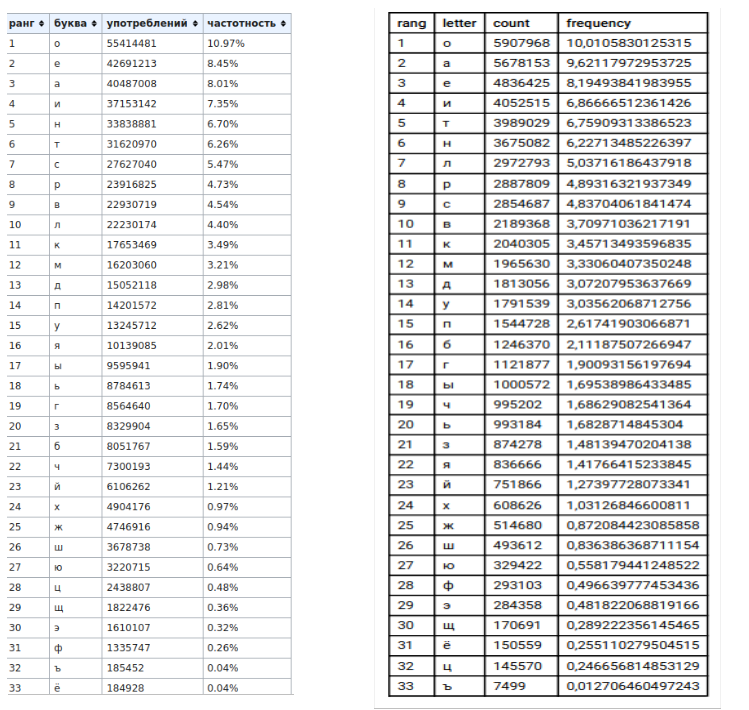
, , , «» «».
, , 2-4 :

, , , , , , , , ,
- . , — , , :
def caesar_cipher():
file = open("text.txt")
text_for_encrypt = file.read().lower().replace(',', '')
letters = ''
arr = []
step = 3
for i in text_for_encrypt:
if i == ' ':
arr.append(' ')
else:
arr.append(letters[(letters.find(i) + step) % 33])
text_for_decrypt = ''.join(arr)
return text_for_decrypt
:
def decrypt_text(text_for_decrypt, arr_decrypt_letters):
arr_encrypt_text = []
arr_encrypt_letters = [' ', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '',
'', '', '', '', '', '', '', '',
'', '', '', '', '', '', '',
'', '', '']
dictionary = dict(zip(arr_decrypt_letters, arr_encrypt_letters))
for i in text_for_decrypt:
arr_encrypt_text.append(dictionary.get(i))
text_for_decrypt = ''.join(arr_encrypt_text)
print(text_for_decrypt)
復号化されたテキストを見ると、アルゴリズムがどこで間違っていたかを推測できます。戦い→行う、vadio→ラジオ、東方→追加、リード→人。したがって、少なくともテキストの意味を把握するために、テキスト全体を解読することが可能です。また、この方法は、対称暗号化方法で暗号化された長いテキストのみを復号化するのに効果的であることに注意したいと思います。完全なコードはGithubで入手できます。