したがって、それぞれの個別のプロセス内で、並列コードの実行、ロック、競合条件などに関する従来の「奇妙な」問題はありません。また、DBMS自体の開発は快適でシンプルです。
しかし、同じ単純さは重大な制限を課します。プロセス内にはワーカースレッドが1つしかないため、要求を実行するために使用できるCPUコアは1つだけです。つまり、サーバーの速度は、別のコアの頻度とアーキテクチャに直接依存します。
終焉を迎えた「メガヘルツの競争」と勝利を収めたマルチコアおよびマルチプロセッサーシステムの時代において、そのような行動は許されない贅沢と無駄です。したがって、PostgreSQL 9.6以降、クエリを処理するときに、一部の操作を複数のプロセスで同時に実行できるようになりました。
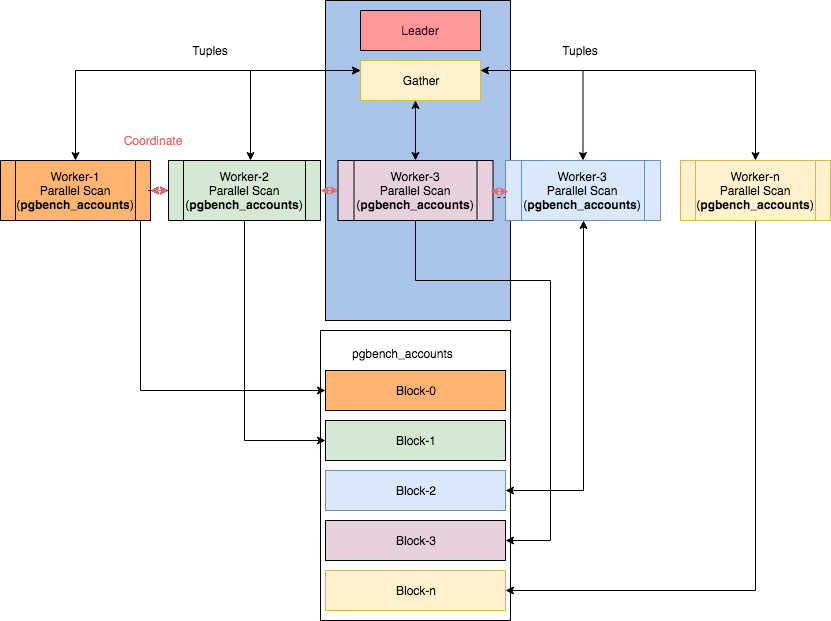
いくつかの並列ノードは、この画像の取得元であるIbrarAhmedによる記事「PostgreSQLの並列処理」にあります。ただし、この場合、計画を読むことは…重要になります。
簡単に言うと、計画操作の並列実行の実装の時系列は次のようになります。
- 9.6-基本機能:Seq Scan、Join、Aggregate
- 10-インデックススキャン(btreeの場合)、ビットマップヒープスキャン、ハッシュ結合、マージ結合、サブクエリスキャン
- 11 -グループの操作:ハッシュは、共有ハッシュテーブルとの結合追加(UNION)
- 12-プランノードの基本的なワーカーごとの統計
- 13-労働者ごとの詳細な統計
したがって、最新のPostgreSQLバージョンのいずれかを使用している場合、プランにそれが表示される可能性は
Parallel ...非常に高くなります。そして彼と一緒に彼らは来て...
時間の経過に伴う奇異
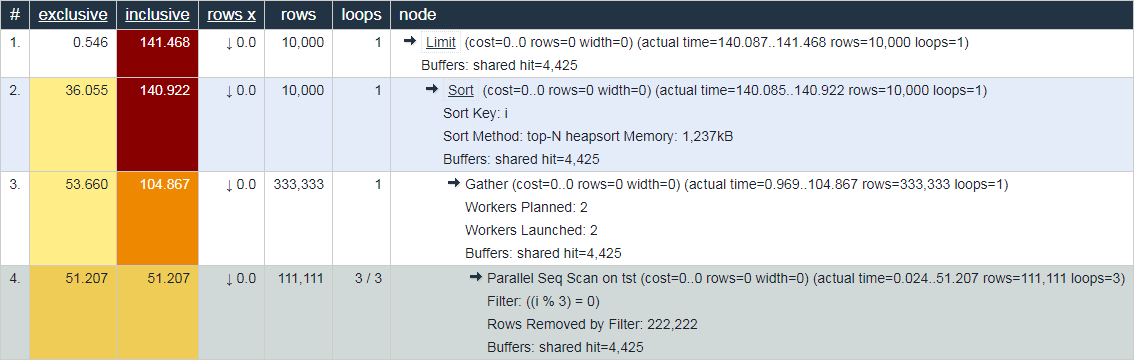
PostgreSQL 9.6から計画を立てましょう:
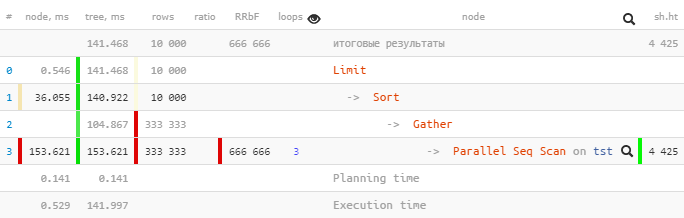
[explain.tensor.ruを見てください]サブツリー内で
1つだけが153.621ミリ秒
Parallel Seq Scan実行され、すべてのサブノードと一緒に実行されましたGather-わずか104.867ミリ秒。
どうして?「2階」の合計時間は短くなりましたか?..- node
をさらに
Gather詳しく見てみましょう。
Gather (actual time=0.969..104.867 rows=333333 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=4425Workers Launched: 2ツリーの下のメインプロセスに加えて、さらに2Gatherつのプロセス(合計3つ)が含まれていることを示しています。したがって、サブツリー内で発生したすべては、3つのプロセスすべての合計の創造性です。
そこに何があるか見てみましょう
Parallel Seq Scan:
Parallel Seq Scan on tst (actual time=0.024..51.207 rows=111111 loops=3)
Filter: ((i % 3) = 0)
Rows Removed by Filter: 222222
Buffers: shared hit=4425あはは!
loops=33つのプロセスすべての要約です。そして、平均して、そのような各サイクルは51.207msかかりました。つまり、このノードを完了するのにサーバー51.207 x 3 = 153.621のプロセッサ時間はミリ秒かかりました。つまり、「サーバーが何をしていたか」を理解したい場合、この数値は理解に役立ちます。
「実際の」実行時間を理解するには、合計時間をワーカーの数で割る必要があることに注意してください[actual time] x [loops] / [Workers Launched]。つまり、です。
この例では、各ワーカーはノードを1サイクルだけ実行したため、
153.621 / 3 = 51.207。そして、はい、今ではGather、ヘッドプロセスの唯一のものが「いわば、より短い時間で」完了したことは奇妙なことではありません。
合計:explain.tensor.ruを 見て、(すべてのプロセスの)ノードの合計時間を調べて、サーバーがビジー状態の負荷の種類を理解し、クエリのどの部分に時間を費やす価値があるかを最適化します。
この意味で、同じexplain.depesz.comの動作は、「実際の平均」時間を一度に表示しますが、デバッグの目的にはあまり役立ち
ません。同意しませんか?コメントへようこそ!
GatherMergeはすべてを失います
今度は、PostgreSQLのために同じクエリを実行してみましょう10のバージョン:
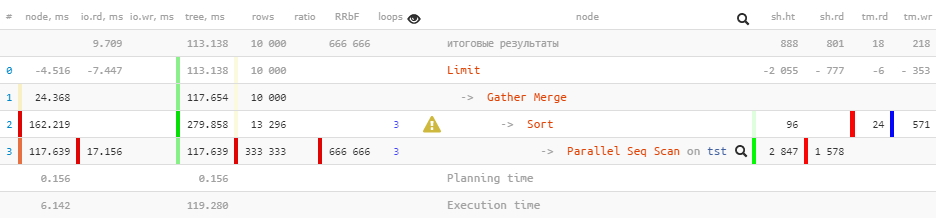
[explain.tensor.ru見]
私たちがいることを注意
Gather今、代わりに計画中のノードのノードを持っていますGather Merge。これはマニュアルがこれについて言っていることです:
ノードがプランの並列部分の上にある場合Gather Merge、ではなくGather、並列プランの部分を実行するすべてのプロセスがソートされた順序でタプルを出力し、先頭のプロセスが順序を保持するマージを実行していることを意味します。Gather一方、ノードは、従属プロセスから都合のよい任意の順序でタプルを受け取り、存在する可能性のあるソート順序に違反します。
しかし、デンマーク王国ではすべてがうまくいくわけではありません。
Limit (actual time=110.740..113.138 rows=10000 loops=1)
Buffers: shared hit=888 read=801, temp read=18 written=218
I/O Timings: read=9.709
-> Gather Merge (actual time=110.739..117.654 rows=10000 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=2943 read=1578, temp read=24 written=571
I/O Timings: read=17.156属性
Buffersを渡しI/O Timingsてツリーを上っていくと、一部のデータがタイムリーに失われました。この損失の大きさは、補助プロセスによって形成される約2/3と見積もることができます。
残念ながら、計画自体では、この情報を取得する場所がありません。したがって、上にあるノードの「マイナス」です。そして、PostgreSQL 12でこの計画のさらなる進化を見ると、-
Sortノード上の各ワーカーにいくつかの統計が追加されていることを除いて、基本的には変わりません。
Limit (actual time=77.063..80.480 rows=10000 loops=1)
Buffers: shared hit=1764, temp read=223 written=355
-> Gather Merge (actual time=77.060..81.892 rows=10000 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=4519, temp read=575 written=856
-> Sort (actual time=72.630..73.252 rows=4278 loops=3)
Sort Key: i
Sort Method: external merge Disk: 1832kB
Worker 0: Sort Method: external merge Disk: 1512kB
Worker 1: Sort Method: external merge Disk: 1248kB
Buffers: shared hit=4519, temp read=575 written=856
-> Parallel Seq Scan on tst (actual time=0.014..44.970 rows=111111 loops=3)
Filter: ((i % 3) = 0)
Rows Removed by Filter: 222222
Buffers: shared hit=4425
Planning Time: 0.142 ms
Execution Time: 83.884 ms合計:上記のノードデータを信頼しないでください
Gather Merge。