
これらの湖(データ湖)は、実際には、利用可能なすべての情報を使用しようとしている企業や企業の標準になります。大規模なデータレイクを開発する場合、オープンソースコンポーネントは多くの場合魅力的なオプションです。クラウドまたはハイブリッドソリューションのデータレイクを作成するために必要な一般的なアーキテクチャパターンを確認し、主要なコンポーネントを実装する際に注意すべきいくつかの重要な詳細についても説明します。
データフローの設計
一般的な論理データレイクフローには、次の機能ブロックが含まれます。
- データソース;
- データ受信中;
- ストレージノード;
- データ処理と強化;
- データ解析。
このコンテキストでは、データソースは通常、生のイベントデータ(ログ、クリック、IoTテレメトリ、トランザクションなど)のストリームまたはコレクションです。
このようなソースの主な機能は、生データが元の形式で保存されることです。このデータのノイズは通常、冗長または誤ったフィールドを持つ重複または不完全なレコードで構成されます。
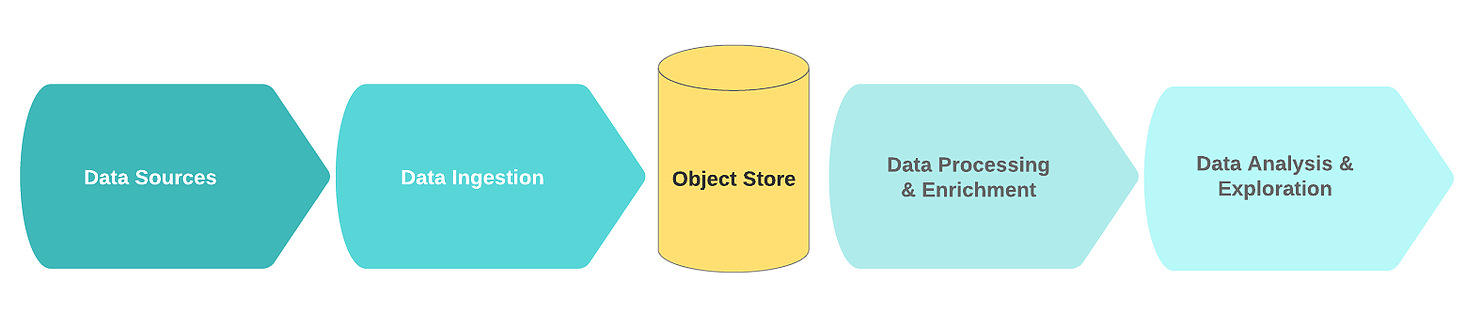
取り込み段階では、生データは1つ以上のデータソースから取得されます。受信メカニズムは、ほとんどの場合、データのプライマリクリーニングと保存を目的とした単純なコンポーネントを備えた1つ以上のメッセージキューの形式で実装されます。効率的でスケーラブルで一貫性のあるデータレイクを構築するには、単純なデータクレンジングタスクとより複雑なデータエンリッチメントタスクを区別することをお勧めします。目安として、クリーンアップタスクではスライディングウィンドウ内の単一のソースからのデータが必要です。
隠しテキスト
( - , ..). , .
, , , 60 , . , (, 24 ), .
, , , 60 , . , (, 24 ), .
データが受信されてクリーンアップされた後、分散ファイルシステムに保存されます(障害耐性を高めるため)。多くの場合、データは表形式で書き込まれます。新しい情報がストレージノードに書き込まれると、スキーマとメタデータを含むデータカタログをオフラインクローラーを使用して更新できます。クローラーの起動は通常、イベントによってトリガーされます。たとえば、新しいオブジェクトがストレージに到着したときなどです。リポジトリは通常、カタログと統合されています。データにアクセスできるように、基になるスキーマをアンロードします。
次に、データは「ゴールドデータ」専用の特別な領域に送られます。この時点から、データは他のプロセスによる強化の準備が整います。
隠しテキスト
, , .
エンリッチメントプロセス中に、ビジネスロジックに従ってデータが追加で変更され、クリーンアップされます。その結果、情報、分析、またはトレーニングモデルをすばやく取得するために使用されるデータウェアハウスまたはデータベースに、構造化された形式で保存されます。
最後に、データの使用は分析と研究です。ここで、抽出された情報が視覚化、ダッシュボード、およびレポートを通じてビジネスアイデアに変換されます。また、このデータは機械学習を使用した予測のソースであり、その結果はより良い決定を下すのに役立ちます。
プラットフォームコンポーネント
データレイククラウドインフラストラクチャには、堅牢で、ハイブリッドクラウドシステムの場合、APIプロバイダーの制約なしに計算タスクの展開、調整、および実行を支援できる統合抽象化レイヤーが必要です。
Kubernetesはこの仕事に最適なツールです。これにより、信頼性が高く費用効果の高い方法で、データレイクのさまざまなサービスと計算タスクを効率的に展開、整理、および実行できます。オンプレミスとパブリックまたはプライベートクラウドの両方で機能する統合APIを提供します。
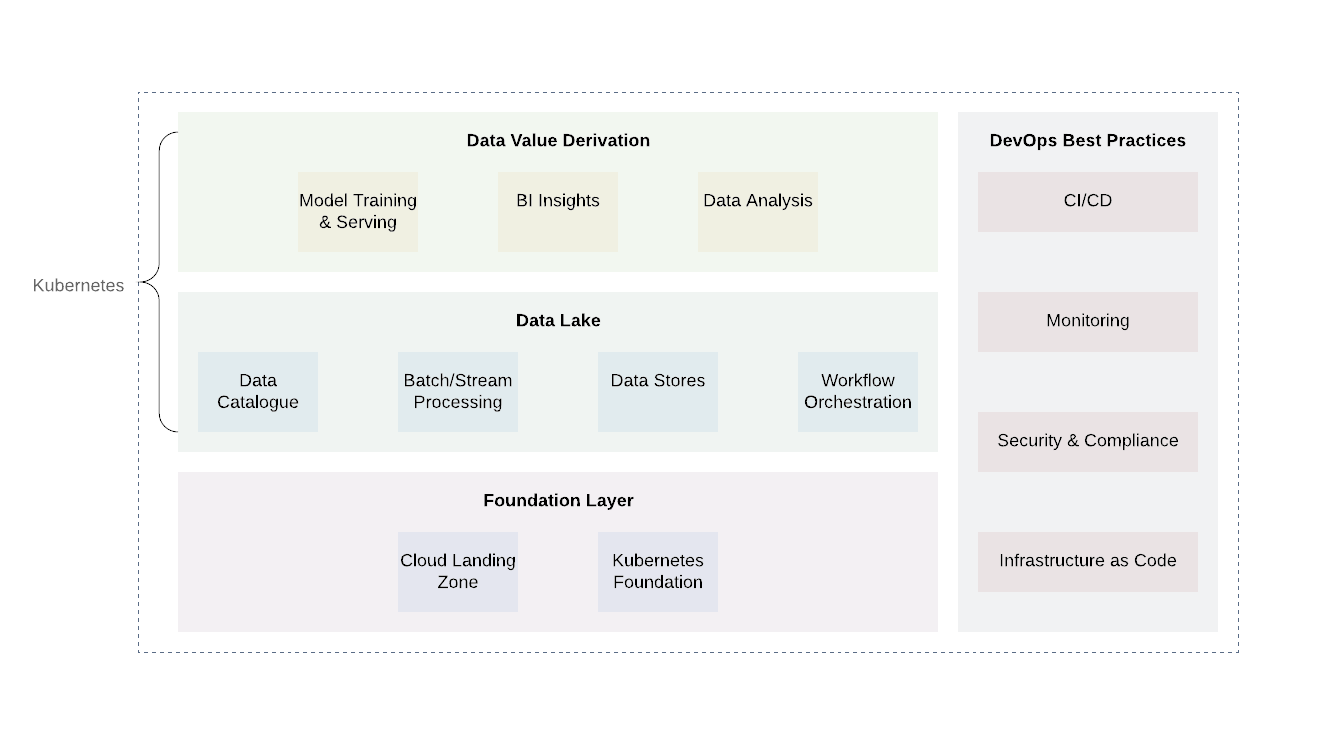
プラットフォームは大きくいくつかの層に分けることができます。ベースレイヤーは、Kubernetesまたはそれに相当するものを展開する場所です。ベースレイヤーは、データレイクのドメイン外の計算タスクを処理するためにも使用できます。クラウドプロバイダーを使用する場合、クラウドプロバイダーのすでに確立されたプラクティス(ロギングと監査、最小アクセスの設計、脆弱性のスキャンとレポート、ネットワークアーキテクチャ、IAMアーキテクチャなど)を使用することは有望です。これにより、必要なレベルのセキュリティと他の要件への準拠が実現します。 ..。
基本レベルの上に、データレイク自体と値の出力レベルの2つの追加レベルがあります。これらの2つのレイヤーは、ビジネスロジックのコアとデータ処理を担当します。これらの2つの層には多くのテクノロジーがありますが、Kubernetesは、さまざまなコンピューティングタスクをサポートする柔軟性があるため、再び優れたオプションであることが証明されます。
データレイクレイヤーには、受信(Kafka、Kafka Connect)、フィルタリング、エンリッチメント、処理(FlinkとSpark)、ワークフロー管理(Airflow)に必要なすべてのサービスが含まれています。さらに、データストレージと分散ファイルシステム(HDFS)が含まれます)およびRDBMSおよびNoSQLデータベース。
最上位レベルはデータ値の取得です。基本的に、これは消費のレベルです。これには、ビジネスインテリジェンスを理解するための視覚化ツール、データマイニングツール(Jupyter Notebooks)などのコンポーネントが含まれています。このレベルで行われるもう1つの重要なプロセスは、データレイクからのトレーニングサンプルを使用した機械学習です。
すべてのデータレイクの不可欠な部分は、コードとしてのインフラストラクチャ、可観測性、監査、およびセキュリティという一般的なDevOpsプラクティスの実装であることに注意することが重要です。これらは日常の問題を解決する上で重要な役割を果たし、標準化、セキュリティ、および使いやすさを確保するために、すべての個々のレベルで適用する必要があります。
, — , opensource-.
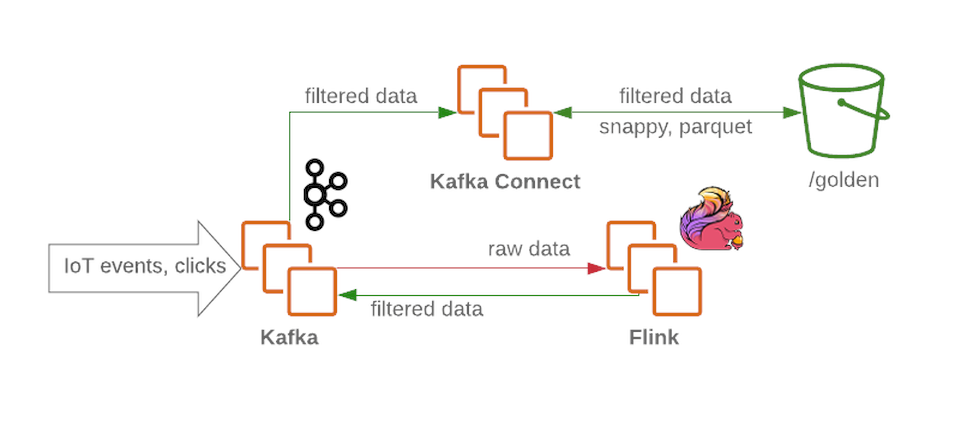
Kafka クラスターは、フィルタリングされていない未処理のメッセージを受信し、データレイクの受信ノードとして機能します。Kafkaは、信頼性の高い方法で高いメッセージスループットを提供します。クラスターには通常、生データ、処理済み(ストリーミング用)、および未配信または不正な形式のデータ用のいくつかのセクションが含まれています。
Flinkは、Kafkaの生データノードからのメッセージを受け入れ、データをフィルタリングし、必要に応じてデータを事前に強化します。その後、データはKafkaに戻されます(フィルタリングされたリッチデータ用の別のセクションにあります)。障害が発生した場合、またはビジネスロジックが変更された場合、これらのメッセージを再度呼び出すことができます。それらが保存されていることカフカ。これは、ストリーミングプロセスの一般的なソリューションです。一方、Flinkは、さらに分析するために、すべての不正な形式のメッセージを別のセクションに書き込みます。Kafka Connect
を使用すると、必要なデータストレージバックエンド(HDFSのゴールドゾーンなど)にデータを保存することができます。Kafka Connectは簡単に拡張でき、重いワークロードでスループットを向上させることにより、同時プロセスの数をすばやく増やすのに役立ちます。
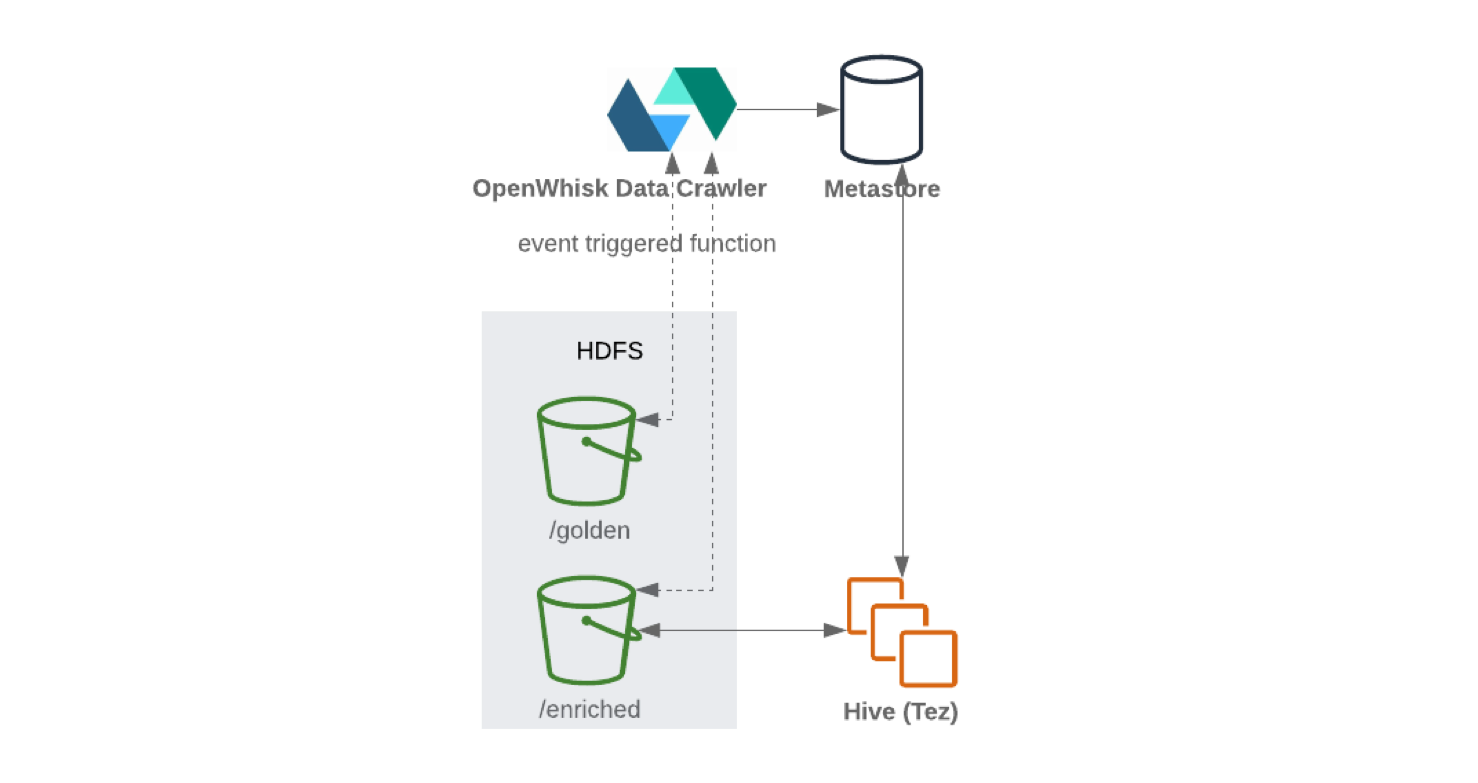
Kafka ConnectからHDFSに 書き込む場合は、効率的なデータ処理のためにコンテンツ分割を実行することをお勧めします(スキャンするデータが少ないほど、要求と応答が少なくなります)。データがHDFSに書き込まれた後、サーバーレス機能(OpenWhiskやKnativeなど)は、メタデータとスキーマパラメーターストアを定期的に更新します。その結果、更新されたスキーマには、SQLのようなインターフェイス(HiveやPrestoなど)を介してアクセスできます。
Apache Airflowは 、後続のデータフローおよびETLプロセス制御に使用できます。これにより、ユーザーはPythonおよびDirected Acyclic Graph(DAG)オブジェクトを使用してマルチステップパイプラインを実行できます。ユーザーは、グラフィカルインターフェイスを介して、依存関係を定義し、複雑なプロセスをプログラムし、タスクを追跡できます。Apache Airflowは、すべての外部データも処理できます。たとえば、外部APIを介してデータを受信し、それを永続ストレージに保存します。パワードスパークによってApacheのエアフロー
特別なプラグインを介して、ビジネス目標に応じてフィルタリングされた生データを定期的に強化し、データサイエンティストやビジネスアナリストによる調査用のデータを準備できます。データサイエンティストは、JupyterHubを使用して複数のJupyterNotebookを管理できます。したがって、Sparkを使用して、データを操作、収集、分析するためのマルチユーザーインターフェイスを構成することをお勧めします。

機械学習には、Kubernetesのスケーラビリティを利用してKubeflowなどのフレームワークを使用できます。結果のトレーニングモデルは、システムに返すことができます。 パズルを組み合わせると、次のようになります。

オペレーショナルエクセレンス
DevOpsとDevSecOpsの 原則は、データレイクの重要なコンポーネントであり、見逃してはならないことを説明しました。特に、ビジネスに関するすべての構造化データと非構造化データが1つの場所にある場合は、多くの力が必要になります。
基本的な原則は次のとおりです。
- ユーザーアクセスを制限します。
- モニタリング;
- データ暗号化;
- サーバーレスソリューション。
- CI / CDプロセスの使用。
DevOpsとDevSecOps の原則は、データレイクの重要なコンポーネントであり、見逃してはなりません。特に、ビジネスに関するすべての構造化データと非構造化データが1つの場所にある場合は、多くの力が必要になります。
推奨される方法の1つは、適切な権限を割り当てて特定のサービスへのアクセスのみを許可し、ユーザーがデータを変更できないようにユーザーの直接アクセスを拒否することです(これはコマンドにも適用されます)。データを保護するには、アクションをログに記録して完全に監視することも重要です。
データ暗号化は、データを保護するためのもう1つのメカニズムです。保存されたデータは、キー管理システム(KMS)を使用して暗号化できます。)。これにより、ストレージシステムと現在の状態が暗号化されます。次に、KafkaやElasticSearchなどのサービスのすべてのインターフェイスとエンドポイントの証明書を使用して送信暗号化を実行できます。
また、セキュリティポリシーに準拠していない可能性のある検索エンジンの場合は、サーバーレスソリューションを優先することをお勧めします。また、手動展開、データレイクのコンポーネントの状況変更を放棄する必要があります。各変更は、ソースコントロールから取得され、一連のCIテストを経てから、製品データレイクに展開される必要があります(煙テスト、回帰など)。
エピローグ
オープンソースのデータレイクアーキテクチャの基本的な設計原則について説明しました。よくあることですが、アプローチの選択は必ずしも明白ではなく、さまざまなビジネス、予算、および時間の要件によって決定される場合があります。しかし、クラウドテクノロジーを活用してデータレイクを作成することは、ハイブリッドソリューションであろうとオールクラウドソリューションであろうと、業界の新たなトレンドです。これは、このアプローチが提供する非常に多くの利点によるものです。柔軟性が高く、開発を制限しません。柔軟な作業モデルは大きな経済的利益をもたらし、適用されるプロセスを組み合わせ、拡張し、改善できることを理解することが重要です。