
私は常にシステム障害とその動作の奇妙さに興味を持っていました。特に、通常の状態で動作している場合はそうです。最近、Ian Goodfellowのプレゼンテーションでスライドの1つを見ましたが、それはとても面白いと思いました。訓練されたニューラルネットワークにランダムな視覚的ノイズが供給され、彼女はそれを自分が知っているオブジェクトの1つとして認識しました。ここではすぐに多くの疑問が生じます。訓練された異なるニューラルネットワークは同じオブジェクトを見ますか?このランダムノイズが実際に認識されたオブジェクトであるというニューラルネットワークの最大信頼度はどれくらいですか?そして、ニューラルネットワークは実際にそこで何を「見る」のでしょうか?
これに対する私の好奇心から、このエントリが生まれました。幸い、このような実験はPyTorchを使用して非常に簡単に行うことができます。..。ニューラルネットワークがオブジェクトを特定の方法で分類する理由を視覚化するために、Captumモデルの解釈可能性フレームワークを使用します。コードはGithubからダウンロードできます。
質問の重要性
これらの質問が重要である理由を尋ねることができます。多くの場合、開発者はモデルを最初から作成しません。彼らは出発点としてモデル動物園からプラットフォームと事前に訓練されたネットワークを選択します。これにより時間を節約できます。データを収集してニューラルネットワークの初期トレーニングを行う必要はありません。ただし、予期しない場所で予期しない問題が発生する可能性があることも意味します。このモデルの使用方法によっては、プロセスでセキュリティの問題が発生する可能性があります。
事前トレーニング済みモデル
事前トレーニング済みのモデルは簡単に使い始めることができ、分類のためにデータをすばやく送信できます。この場合、モデルを定義してトレーニングする必要はありません。これはすべて事前に行われており、展開後すぐに使用できるようになります。 Torchvisionライブラリの事前トレーニング済みモデルは、Imagenetデータベースの一連の画像でトレーニングされ、1000のカテゴリに分類されます。..。このトレーニングでは、さまざまなオブジェクトを含む複雑な画像を解析するのではなく、画像内の1つのオブジェクトを識別する必要があることを覚えておくことが重要です。 2番目のケースでも興味深い結果を得ることができますが、これはまったく別のトピックです。 Torchvisionライブラリから事前にトレーニングされたモデルをダウンロードするのは非常に簡単です。事前トレーニング済みパラメーターをTrueに設定して、選択したモデルをインポートする必要があります。テスト中に学習曲線がないため、モデルに評価モードも含めました。
まず、GPUが使用可能かどうかに応じて、cudaまたはcpuの使用を選択するコード行があります。これらの簡単なテストでは、GPUは必要ありませんが、GPUを持っているので、それを使用します。
device = "cuda" if torch.cuda.is_available() else "cpu"
import torchvision.models as models
vgg16 = models.vgg16(pretrained=True)
vgg16.eval()
vgg16.to(device)
Torchvisionの事前トレーニング済みモデルのリストは、ここにあります。事前にトレーニングされたすべてのニューラルネットワークを使用したくありませんでした。これはすでに多すぎます。私は次の5つを選びました:
- vgg16
- resnet18
- alexnet
- デンスネット
- 始まり
ニューラルネットワークを選択するために特別な方法を使用しませんでした。たとえば、Vgg16とInceptionは異なる例でよく使用され、それらはすべて異なります。
ノイズのある画像を作成する方法
ニューラルネットワークに送ることができるノイズを含む画像を自動的に生成する方法が必要になります。これを行うために、NumpyライブラリとPILライブラリを組み合わせて使用し、ランダムノイズで満たされた画像を返す小さな関数を作成しました。
import numpy as np
from PIL import Image
def gen_image():
image = (np.random.standard_normal([256, 256, 3]) * 255).astype(np.uint8)
im = Image.fromarray(image)
return im
最終的には次のようになります。

画像の変換
その後、画像をテンソルに変換して正規化する必要があります。次のコードは、ランダムノイズだけでなく、事前にトレーニングされたニューラルネットワークにフィードする任意の画像にも使用できます(そのため、コードはResize値とCenterCrop値を使用します)。
def xform_image(image):
transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
new_image = transform(image).to(device)
new_image = new_image.unsqueeze_(0)
return new_image予測を得る
変換された画像を準備すると、展開されたモデルから予測を簡単に取得できます。この場合、xform_image関数はimage_xformを返すと想定されます。テストに使用したコードでは、作業をこれら2つの関数に分割しましたが、ここでは参照しやすいようにまとめました。基本的に、変換された画像をネットワークにフィードし、softmax関数を実行し、topk関数を使用してスコアを取得し、最良の結果を得るには予測ラベルIDを取得する必要があります。
with torch.no_grad():
vgg16_res = vgg16(image_xform)
vgg16_output = F.softmax(vgg16_res, dim=1)
vgg16score, pred_label_idx = torch.topk(vgg16_output, 1)
結果
さて、ノイズの多い画像を生成し、事前にトレーニングされたネットワークにフィードする方法を見てみましょう。では、結果はどうなりますか?このテストでは、1000個のノイズの多い画像を生成し、事前にトレーニングされた5つの選択されたネットワークで実行し、すばやく分析できるようにPandasデータフレームに詰め込むことにしました。結果は面白く、やや予想外でした。
| vgg16 | resnet18 | alexnet | デンスネット | 始まり | |
|---|---|---|---|---|---|
| カウント | 1000.000000 | 1000.000000 | 1000.000000 | 1000.000000 | 1000.000000 |
| 平均 | 0.226978 | 0.328249 | 0.147289 | 0.409413 | 0.020204 |
| std | 0.067972 | 0.071808 | 0.038628 | 0.148315 | 0.016490 |
| 分 | 0.074922 | 0.127953 | 0.061019 | 0.139161 | 0.005963 |
| 25% | 0.178240 | 0.278830 | 0.120568 | 0.291042 | 0.011641 |
| 50% | 0.223623 | 0.324111 | 0.143090 | 0.387705 | 0.015880 |
| 75% | 0.270547 | 0.373325 | 0.171139 | 0.511357 | 0.022519 |
| 最大 | 0.438011 | 0.580559 | 0.328568 | 0.868025 | 0.198698 |
ご覧のとおり、一部のニューラルネットワークは、このノイズが実際にはかなり高いレベルの信頼性で何かを表していると判断しています。 Resnet18とdensenetは両方とも50%でピークに達しました。これはすべて良いことですが、これらのネットワークはノイズの中で正確に何を「見る」のでしょうか。興味深いことに、さまざまなネットワークがさまざまなオブジェクトを「見つけました」。 それぞれのネットワークは何か違うものを見ました。 Resnet18は、それがクラゲであると100%確信していましたが、Inceptionは、他のどのネットワークよりもはるかに多くのオブジェクトを見ましたが、それどころか、予測にはほとんど自信がありませんでした。
Vgg16:
978
14
7
1
Resnet18:
1000
Alexnet:
942
58
Densenet:
893
37
33
20
16
1
Inception:
155
123
102
85
83
81
69
32
26
25
24
18
16
16
12
12
11
9
9
8
7
5
5
5
- 5
4
4
4
4
3
3
3
3
3
2
2
2
2
2
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
楽しみのために、このエントリの冒頭に近づけたノイズイメージの下にMicrosoftがどのような署名を付けるかを確認することにしました。テストでは、最も簡単な方法でOffice 365のPowerPointを使用することにしました。単一のオブジェクトを認識しようとするimagenetモデルとは異なり、PowerPointは画像の正確な説明を作成するために複数のオブジェクトを認識しようとするため、結果は興味深いものです。
画像は象、人、大きなボールを示しています。
結果は私を失望させませんでした。私の見方では、ノイズのイメージはサーカスとして認識されていました。
展望
これは別の質問につながります-ノイズがオブジェクトであると思わせるニューラルネットワークは何を見ていますか?答えを探す際に、ネットワークが「見ている」ものを大まかに理解できるモデル解釈ツールを使用できます。 Captumは、PyTorchのモデル解釈フレームワークです。ここでは特別なことは何もしませんでした。彼らのWebサイトのチュートリアルのコードを使用しただけです。 internal_batch_sizeパラメーターを値50で追加しました。これがないと、GPUのメモリがすぐに不足したためです。
レンダリングには、2つのグラデーションベースのアトリビューションとオクルージョンベースのアトリビューションを使用しました。これらの視覚化を使用して、分類子にとって何が重要であるかを理解し、ネットワークが何を認識しているかを「確認」しようとします。事前にトレーニングされたresnetモデルも使用しましたが、コードを変更して、他の事前にトレーニングされたモデルを使用できます。
ノイズに移る前に、その兆候が認識しやすいので、レンダリングプロセスのデモンストレーションとしてカモミールの画像を撮りました。
result = resnet18(image_xform)
result = F.softmax(result, dim=1)
score, pred_label_idx = torch.topk(result, 1)
integrated_gradients = IntegratedGradients(resnet18)
attributions_ig = integrated_gradients.attribute(image_xform, target=pred_label_idx,
internal_batch_size=50, n_steps=200)
default_cmap = LinearSegmentedColormap.from_list('custom blue',
[(0, '#ffffff'),
(0.25, '#000000'),
(1, '#000000')], N=256)
_ = viz.visualize_image_attr(np.transpose(attributions_ig.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
method='heat_map',
cmap=default_cmap,
show_colorbar=True,
sign='positive',
outlier_perc=1)
noise_tunnel = NoiseTunnel(integrated_gradients)
attributions_ig_nt = noise_tunnel.attribute(image_xform, n_samples=10, nt_type='smoothgrad_sq', target=pred_label_idx, internal_batch_size=50)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_ig_nt.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
cmap=default_cmap,
show_colorbar=True)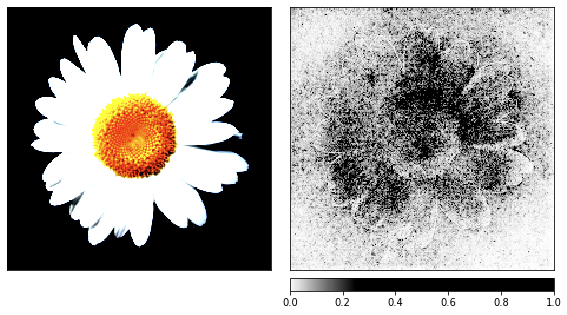
occlusion = Occlusion(resnet18)
attributions_occ = occlusion.attribute(image_xform,
strides = (3, 8, 8),
target=pred_label_idx,
sliding_window_shapes=(3,15, 15),
baselines=0)
_ = viz.visualize_image_attr_multiple(np.transpose(attributions_occ.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(image_xform.squeeze().cpu().detach().numpy(), (1,2,0)),
["original_image", "heat_map"],
["all", "positive"],
show_colorbar=True,
outlier_perc=2,
)

ノイズの視覚化
カモミールに基づいて以前の画像を生成しました。次に、ランダムノイズでどのように機能するかを確認します。
私は事前にトレーニングされたresnet18ネットワークを使用していますが、この画像を使用すると、クラゲが見えると40%確信しています。コードを繰り返すことはしません。レンダリングのコードは上記のものと同じです。


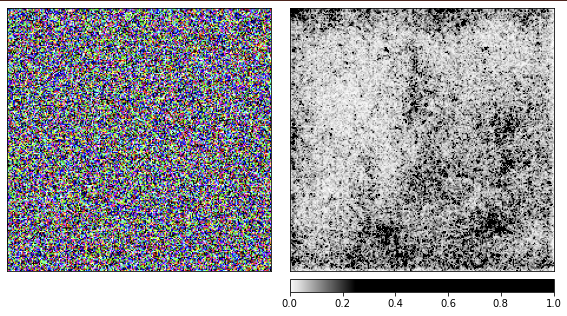

視覚化から、ネットワークがクラゲをここで見る理由を私たち人間が理解できないことは明らかです。画像の一部の領域はより重要であるとマークされていますが、カモミールの例で見たように、それらはまったく定義されていません。カモミールとは異なり、クラゲはアモルファスであり、透明度のレベルが異なります。
クラゲの実際の画像を処理するレンダリングがどのようになるのか疑問に思われるかもしれません。私のコードはGithubに投稿されており、その助けを借りてこの質問に対する答えを簡単に得ることができます。
結論
この記録に基づいて、予期しない入力を供給することによってニューラルネットワークをだますことがいかに簡単であるかを簡単に理解できます。彼らの名誉のために、私たちは彼らが彼らの仕事をし、彼らができる限り最高の結果を出したと言うでしょう。また、作業の結果から、このような場合、信頼性の高いオプションもあるため、信頼性の低いオプションを除外するだけでは不十分であることがわかります。実世界のシステムが非常に簡単に失敗する状況に注意を払う必要があります。システムに予期しないデータが入力されたことに驚かないでください。これは、セキュリティの専門家がかなり前から行っていることです。