360パフォーマンスレビュー方法は、X5 RetailGroupでも使用されています。今日は、詳細なHR分析のためのBigDataX5のベストプラクティスについて説明します。

明らかに、そのような方法の精度は、さまざまな意見を平均することによって向上しますが、それでも、人々が質問に記入するオープンさと熱意、規模の理解、チームの強さ、チームの雰囲気などに依存します。
このようなシステムの運用の重要な側面は、質問票への記入との相互作用です。人が無意識のうちに全員に5を与える場合、彼らは彼と協力し、プロセスの重要性を説明する必要があります。ロシアでは、C学生はまあまあの性格であり、良い人は普通ですが、優秀な学生はうまく働く人であるという5段階の尺度に基づいた成績に対する一定の態度があります。それは賞賛です。敗者は2年目も残っており、実際、「敗者はそれほど多くなく、私たちの会社では見たことがありません」。これは、マネージャーが通常チームについて答える方法です。 「どこか」ですが、ここではありません。だから、あなたが従業員が良いと思うなら、あなたは彼に4を与えます、なぜならC ...まあ、Cがあります、そしてあなたが友達ならあなたは5を置くことができます-躊躇しないでください。これにより、評価が歪められ、調査では5の割合が高くなります。これはほぼ2ポイントに縮退します:4と5で。
評価者を教えることは、説明を含む遅くて悲しい(まあ、必ずしも悲しいとは限らない)プロセスです。 1回のやり取りの結果を賞賛したり、1つの失礼な手紙の結果を否定したりせずに、人を正しく評価する方法。学校で使用されているものとは異なる、グレーディングスケールがどのように見えるか。レビューアの典型的な間違いの概要など。人々をリラックスさせ、さらに別の退屈なツールとしてのプロセスの認識から離れ、評価が同僚の財務結果に影響を与えるという恐れを取り除くことが非常に重要です。ここでは、急いで人事を決定したり、コマンドスタッフを新しい軌道に乗せたりしないことが基本的に重要です。
HR従業員の観点からの分析プロセスのステートメントは、テキストに適切に配置されています。Avitoから、私は読むことを強くお勧めします。彼らは良い方向への強い偏見を観察しました、4の数(「期待以上」)はトリプルの数(「期待を満たす」)と同様でした。独自のデザインのスケールを使用しましたが、「善と悪」についての議論にも遭遇しました。
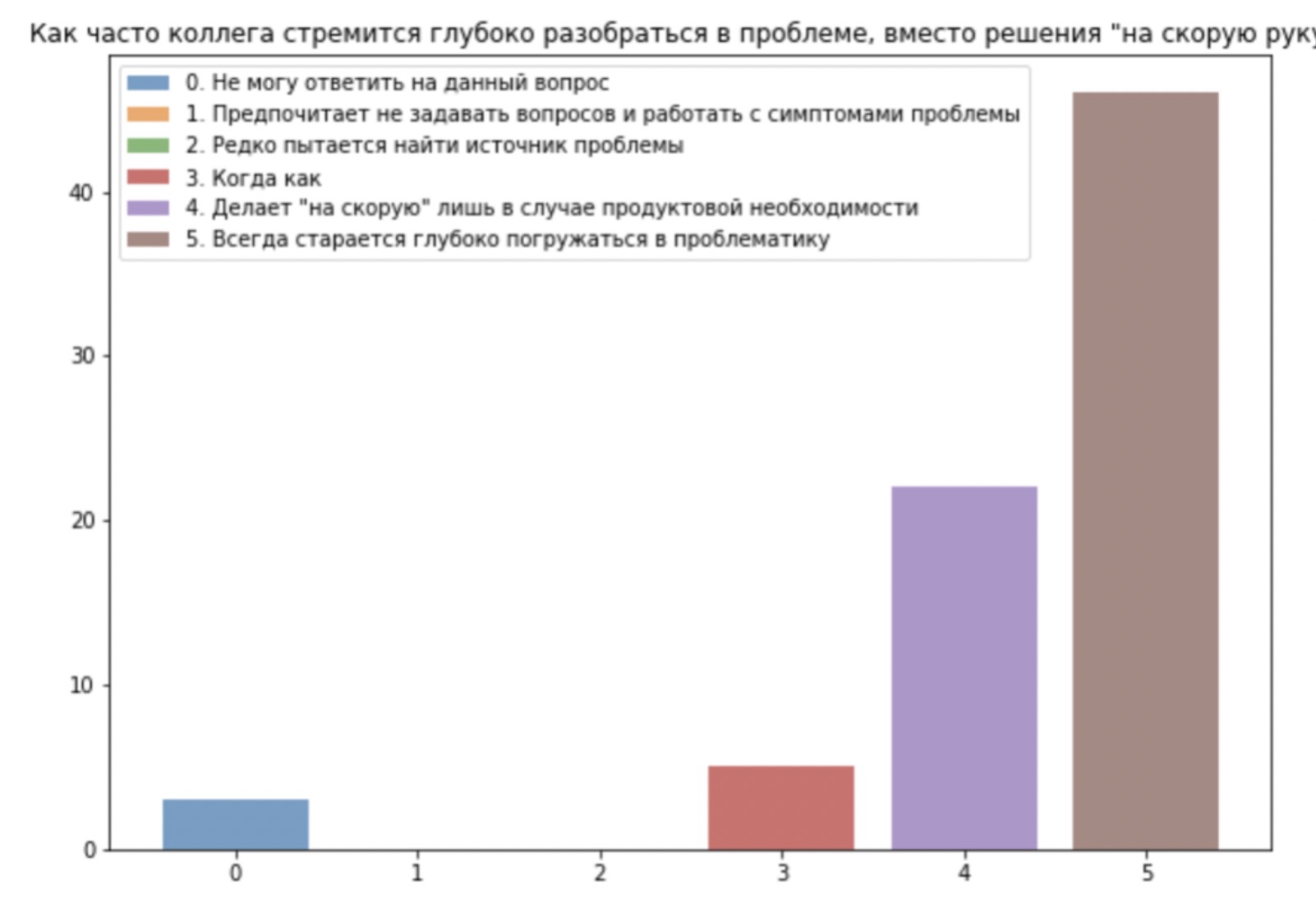
さらに、声が分かれました。強力で友好的なチームか、2つのうちの1つです。そのため、別のチームで2回目のレビューをすぐに開始
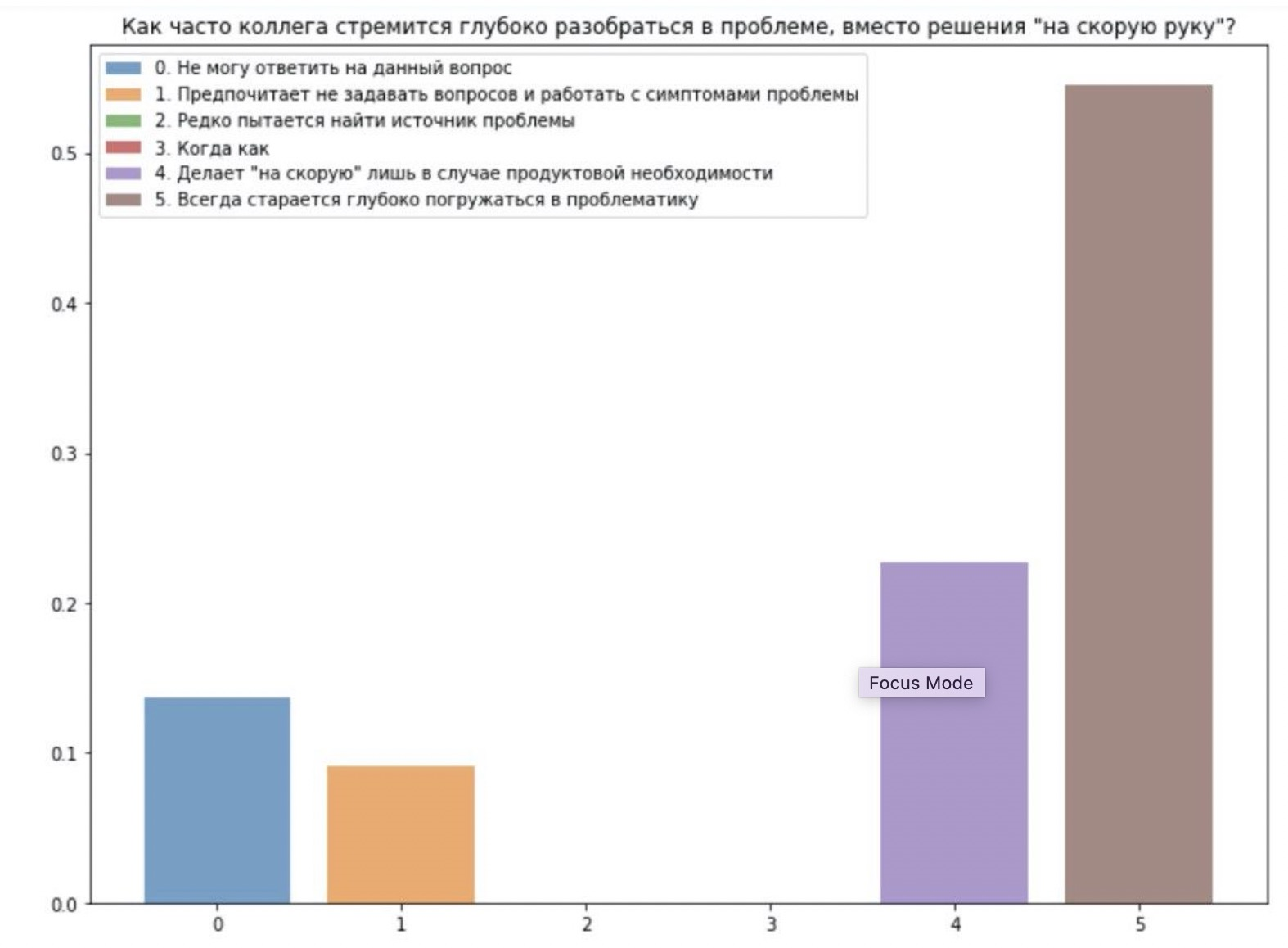
し、スケールの明確化と見積もりの調整に追加の作業を行わなくても、変動の大きいデータを取得できる場合があることを確認しました。つまり、人々と協力し、「客観的」評価の有機的な傾向を考慮する必要があります。あるいは、これはチーム内の不一致である可能性があり、一般的に言えば、これも知っておくと便利です。
360スコアは通常、従業員の育成とパフォーマンス分析の2つの目的で使用されます。フィードバックを提供する人の準備とオープンさのレベルによって、出力が異なる場合があることを理解することが重要です。従業員の育成を支援するツールを作成するときは、さまざまなソースから匿名のフィードバックを提供して、彼の長所と短所、ポンプスキル、不足している資質の開発を理解できるようにすることが重要です。調査は、職務の遂行に密接に関連する能力または行動、および組織の価値に焦点を当てています。このようなツールを起動するときは、参加者に自分がそうではないことを明確にする必要がありますその結果を人事決定に使用します。私たちのストーリーは、360レビュー方式を使用して従業員を育成することについてです。
従業員の育成データは、ボーナスや才能の変化について決定を下すのではなく、育成の強みと分野を評価するために必要です。人の価値観が会社の価値観とどのように相関しているかを会社が理解することも重要です。 360の結果は、常に従業員とそのマネージャーと共有されます。
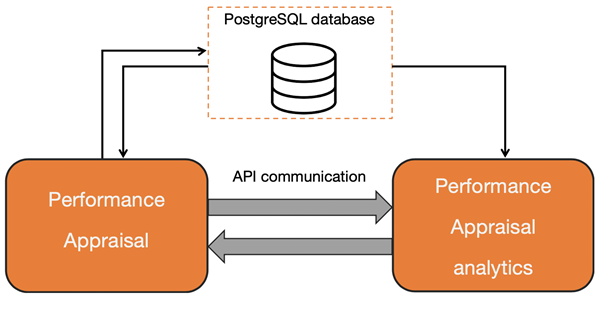
360の調査スコアと結果は、洞察と分析を提供するために使用できるデータの宝庫です。このデータは、より信頼性の高い結果を得るのに役立つ「修正」係数を計算するため、および能力、スキル、個々のチームの「プロファイル」の編集などによって従業員をクラスター化するために必要です。これらの計算にはすべて、追加の電力とフレームワークが必要であり、別のマイクロサービスに移行することにしました。したがって、ユーザーが(HR部門から)見る部分を、すべての追加の分析計算が実行される「分析」部分から論理的に分離しました。このアプローチにより、これらのサービスを独立して開発でき、計算をさらに分離できます。分析サービスには独自のデータベースがありません。すべての計算はメインサービスのデータベースにあるデータに基づいて行われ、REST-APIを使用して相互作用します。
分析サービスはFlaskで記述された別個のサーバーであり、メインサービスはPostgreSQLデータベースを使用してNodeJSに実装されます。この間違いなく難しい相互作用スキームを以下に示します。
他のチームでの調査を評価する例を考えてみましょう。チームAとチームBと呼びましょう。チームAで従業員が友好的で、お互いをよく扱い、したがって平均スコアが得られる状況を想像してみてください。かなり高くなる可能性があります。チームAとは対照的に、チームBは、実際に業績の良い従業員にのみ正直に高得点を与える、より重要な人々で構成されているとします。
チームAとチームBの2人の従業員をどのように比較しますか?異なるチームの従業員を比較するために、特別な「チーム」キャリブレーションを使用して、チームの平均スコアに対する従業員のスコアを取得します。ここで式なしで行うことはできません。
チームAのスコアが0.9で平均スコアが0.85の従業員xがいて、チームBのスコアが0.65で平均スコアが0.5の従業員yがいるとします。チームの平均スコアを差し引いた後、従業員の「調整済み」スコアを取得します。
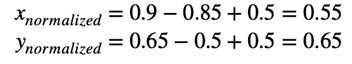
したがって、従業員yの調整済みスコアが従業員xの調整済みスコアよりも高いことがわかります。
同じ例がチーム内の正規化にも当てはまります。すべての従業員は異なり、同僚の評価も異なる傾向があります。たとえば、すべての同僚を非常によく扱い、全員に平均スコア0.8を与える従業員xがいます。また、他の従業員をより批判的に見て、他の従業員に平均0.5を与える従業員yがいます。従業員xとyが従業員zを評価する場合、彼らは彼を同等に良い(または同等に悪い)と評価できますが、独自の価値体系であるため、チーム内の平均スコアを平均するとき、履歴データから計算された各従業員の平均を差し引きます。従業員xが従業員zを0.9、従業員yが0.7と評価した場合、平均スコアは等しくなります。
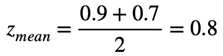
ただし、過去の平均的な著者の評価を差し引くと、次のようになります。
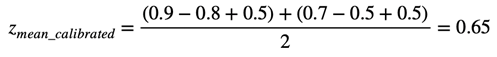
このキャリブレーションの後、各従業員の「価値体系」を考慮に入れた、したがって、より「正直」なメトリックを取得します。
重要なことは、個人のプロファイルを定義するときに、さまざまな係数を使用してレビューアからの評価を比較検討できることです。マネージャーが人々を評価する際により正確で公平である傾向があるという多くの証拠があります(実際、これは彼らが彼らがいた場所にたどり着いた理由でもあります)、おそらくより多くの経験のためです。
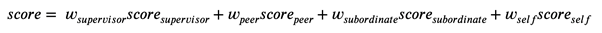
重みのデフォルト値は0.25です。つまり、現在のバージョンでは、回答者のカテゴリのいずれも優先しませんが、ある古い逸話で述べられているように、「ツールはそこにあります」。
言い換えれば、著者によって調整された推定値を収集した後、データから正しい洞察を抽出できるようにするために、それらをグローバルな「調整システム」に駆動しようとします。そうでなければ、偏った評価のために、実際には存在しない驚くべき規則性を発見することができます。そして、何が良いのか、私たちは彼のプロファイルとは反対の方向に従業員を育成し始めます。
成功し、従業員の能力プロファイルを表すベクトルをまとめました。さらに、同僚、マネージャー、部下、自尊心から受け取ったベクトルがあります。これらすべてをキューブに収集します(正確には、並列パイプですが、さらに、OLAPキューブと同様にキューブという用語を使用します)。
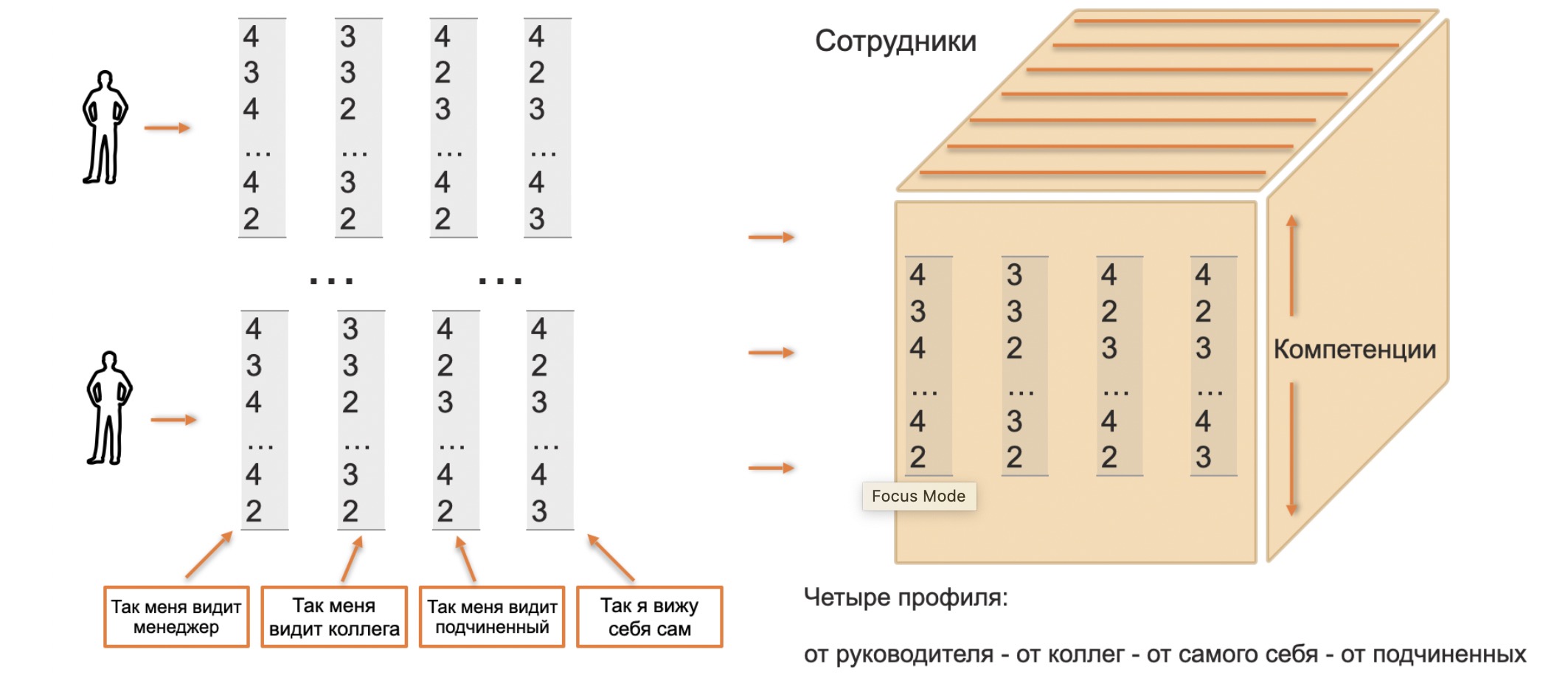
しかし今では、キューブをさまざまな軸に沿って分析することで、さまざまな分析依存関係を取得できます。たとえば、コンピテンシーを修正して、組織全体または組織内のチーム間の分布を確認しましょう。または、マネージャーの評価の右端の列を取得し、評価の差異を内部的に調べて、驚くべき結果がないかどうかを確認します。
このロジックを開発することで、チーム内と異なる部門に属する従業員の比較図、いわゆるクモの巣を取得することができます。しかし、同じ図で、チーム内の能力の平均値を示し、特定の人がチームに対してどこでどの方向にノックアウトされているかを理解することは可能です。従業員がいるチームの代わりに別のチームを選び、その平均能力を人の能力と比較することができます。なぜ、スイングすると、チームを他のチームと比較できるので、楽しいゲームが生まれます。
組織内の特定のタイプのクラスターを分析して、問題解決への深いアプローチで知られている効果的なコミュニケーターまたは専門家である可能性のある人々を見つけることもできます。
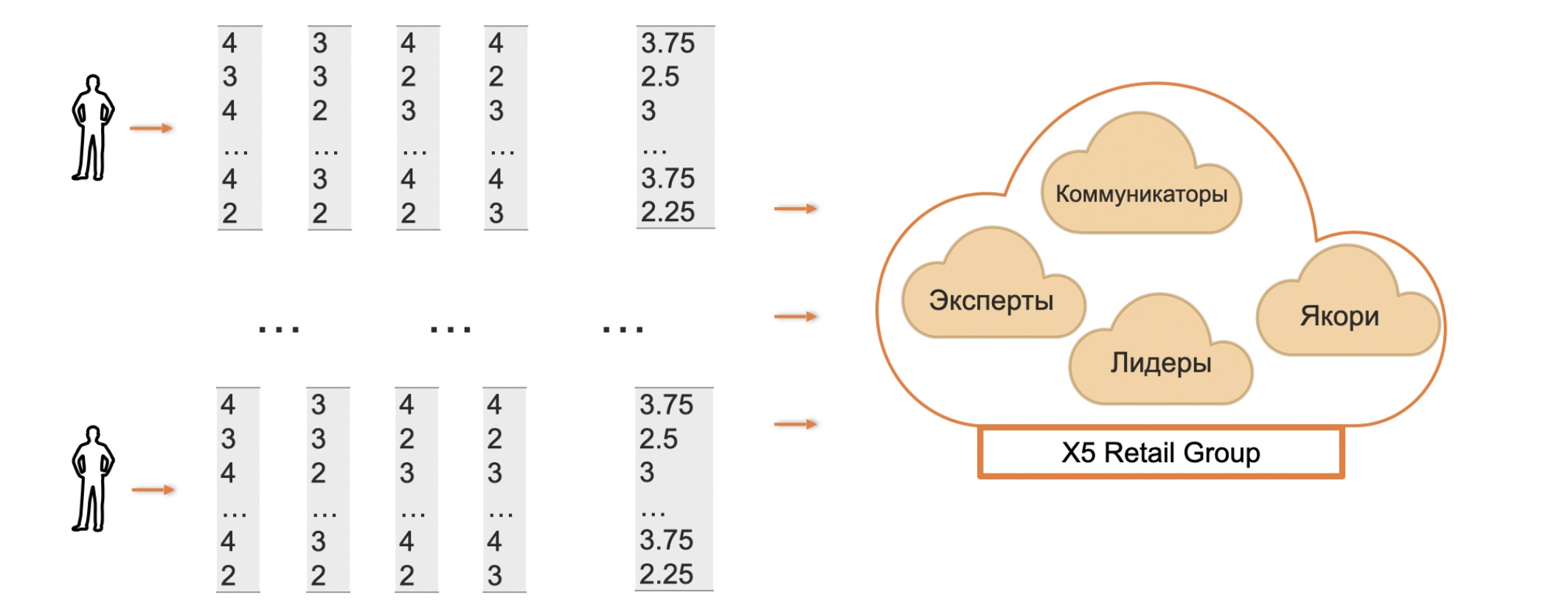
分析的に単純な検索も可能ですが、それほど興味深いものではありません。特に、同僚間でポーリングされたときの従業員の1人の評価の大きなばらつきは、彼の同僚の二極化した認識を示している可能性があります。
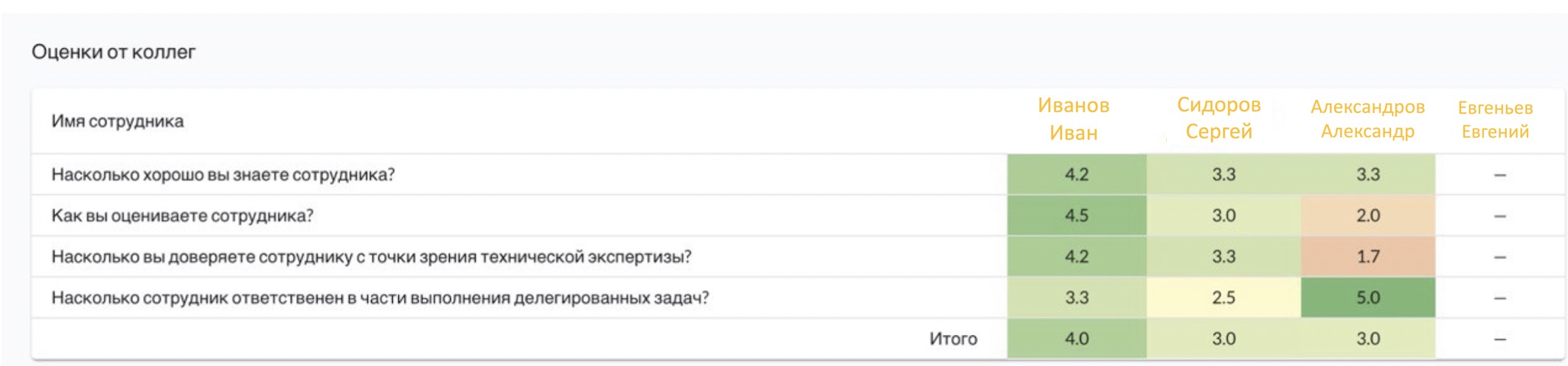
同僚とマネージャーの評価を比較するときに差異が大きい場合はどうなりますか?同僚とマネージャーは従業員を非常に異なって評価しますか?おそらくここで、彼がどのようなリーダーであるか、そして彼が彼のチームのメンバーに対して厳しすぎるかどうか(まあ、またはその逆、重要ではない)疑問に思うかもしれません。または、他のチームでも同様のパターンが繰り返される場合は、組織内のマネージャーの基本的な超客観性について結論を出します。
いずれかの従業員の評価が欠落している場合は、その人が同僚とほとんどやり取りしていないことを示している可能性があります。同時に、X5の一部のチームにとって、これはかなりの方法であり、ここで驚くべきことは何もありませんが、一部のチームにとって、これが作業プロセスの変更の必要性の指標として機能することは明らかです。
将来的には、この段階で見積もりの偏りをなくし、サービスユーザーとの手作業や、正しい見積もりの選択方法とその意味についての無限の説明を避けて、調査フォームでより微妙な質問を作成したいと考えています。私たちはいくつかのアイデアを持っています、それらは検証の過程にあります、そして私たちは間違いなくあなたと結果を共有します。また、軸に沿ったカットとクラスタリングに加えて、より狡猾な手法をデータキューブに適用したいと考えています。ここでは、線形と非線形のさまざまな自動エンコーダーを試し、さまざまな座標軸に沿ったビュー間の相互接続を探します。一般的に、多くの作業があり、データは不従順であり、システムのセットアップは簡単ではありません:)
著者:
Evgeny Makarov
Valery Babushkin
Svyatoslav Oreshin
Daniil Pavlyuchenko
Evgeny Molodkin