- 組み込みデバイスとIoT。
- データ解析。
- あるシステムから別のシステムへのデータの転送。
- データのアーカイブおよび(または)データのコンテナへのパッキング。
- 外部データベースまたは一時データベースのデータストレージ。
- デモンストレーションまたはテストの目的で使用される企業データベースの代替。
- データベースを操作する実践的なテクニックの初心者によるトレーニング、習得。
- SQL言語の実験的拡張のプロトタイピングと調査。
このデータベースを使用する他の理由 は、SQLiteのドキュメントに記載されています。 この記事は、Python開発でのSQLiteの使用についてです。したがって、モジュールで表されるこのDBMSが、言語の標準ライブラリに含まれていることが特に重要です。つまり、PythonコードからSQLiteを操作するために、クライアントサーバーソフトウェアをインストールする必要はなく、DBMSの操作を担当するサービスの操作をサポートする必要もありません。モジュールをインポートしてプログラムで使用を開始するだけで、リレーショナルデータベース管理システムを自由に使用できます。
sqlite3sqlite3
モジュールのインポート
上記で、SQLiteはPythonに組み込まれたDBMSであると述べました。つまり、作業を開始するには、のようなコマンドを使用して最初にインストールせずに、対応するモジュールをインポートするだけで十分
pip installです。SQLiteimportコマンドは次のようになります。
import sqlite3 as sl
データベースへの接続の作成
SQLiteデータベースへの接続を確立するために、ドライバーのインストール、接続文字列の準備などについて心配する必要はありません。データベースを作成し、それに接続するオブジェクトを自由に使用できるようにするのは、非常に簡単で迅速です。
con = sl.connect('my-test.db')
このコード行を実行することにより、データベースを作成して接続します。ここでのポイントは、接続先のデータベースがまだ存在しないため、システムが自動的に新しい空のデータベースを作成することです。データベースがすでに作成されている場合(これは
my-test.db前の例のものであるとしましょう)、データベースに接続するには、まったく同じコードを使用する必要があります。

新しく作成されたデータベースファイル
テーブルの作成
次に、新しいデータベースにテーブルを作成しましょう。
with con:
con.execute("""
CREATE TABLE USER (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
name TEXT,
age INTEGER
);
""")
これは
USER、3つの列を持つテーブルをデータベースに追加する方法を説明しています。ご覧のとおり、SQLiteは確かに非常に単純なデータベース管理システムですが、従来のリレーショナルデータベース管理システムに期待されるすべての基本機能を備えています。値を許可するタイプnull、主キーのサポート、自動インクリメントなど、データタイプのサポートについて説明しています。
このコードが期待どおりに機能する場合(ただし、上記のコマンドは何も返しません)、テーブルを自由に使用できるようになり、さらに作業できるようになります。
テーブルへのレコードの挿入
USER作成
したテーブルにいくつかのレコードを挿入しましょう。これは、とりわけ、テーブルが実際に上記のコマンドによって作成されたことの証拠を提供します。
1つのコマンドでテーブルに複数のレコードを追加する必要があると想像してみましょう。SQLiteでこれを行うのは非常に簡単です。
sql = 'INSERT INTO USER (id, name, age) values(?, ?, ?)'
data = [
(1, 'Alice', 21),
(2, 'Bob', 22),
(3, 'Chris', 23)
]
ここでは
?、プレースホルダーとして疑問符()を使用してSQL式を定義する必要があります。データベース接続オブジェクトを自由に使用できるので、式とデータを準備したら、テーブルにレコードを挿入できます。
with con:
con.executemany(sql, data)
このコードを実行した後、エラーメッセージは受信されません。これは、データがテーブルに正常に追加されたことを意味します。
データベースクエリの実行
次に、実行したコマンドが正しく機能したかどうかを確認します。データベースへのクエリを実行して、テーブルから
USERデータを取得してみましょう。たとえば、22歳を超えないユーザーに関連するレコードを取得します。
with con:
data = con.execute("SELECT * FROM USER WHERE age <= 22")
for row in data:
print(row)
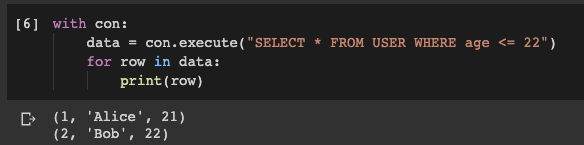
データベースへのクエリを実行した結果
ご覧のとおり、必要なものを取得することができました。そして、それを行うのはとても簡単でした。
さらに、SQLiteは単純なDBMSですが、非常に幅広いサポートがあります。したがって、ほとんどのSQLクライアントを使用して操作できます。
私はDBeaverを使用しています。それがどのように見えるかを見てみましょう。
SQLクライアント(DBeaver)からSQLiteデータベースに接続する
Google Colabクラウドサービスを使用
my-test.dbしていて、ファイルを自分のコンピューターにダウンロードしたいと思っています。コンピューターでSQLiteを試している場合は、どこかからデータベースファイルをダウンロードしなくても、SQLクライアントを使用してSQLiteに接続できることを意味します。
DBeaverの場合、SQLiteデータベースに接続するには、新しい接続を作成し、データベースタイプとしてSQLiteを選択する必要があります。
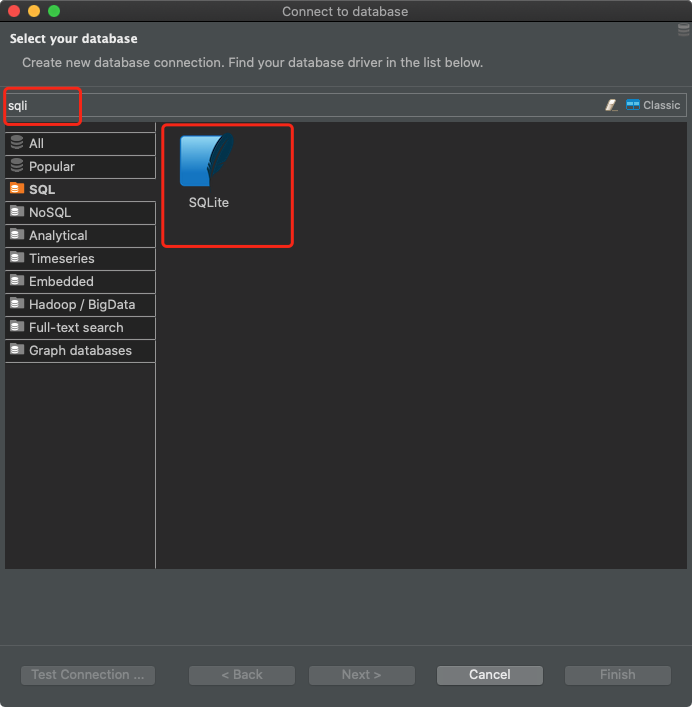
DBeaverでの接続の準備
次に、データベースファイルを見つける必要があります。
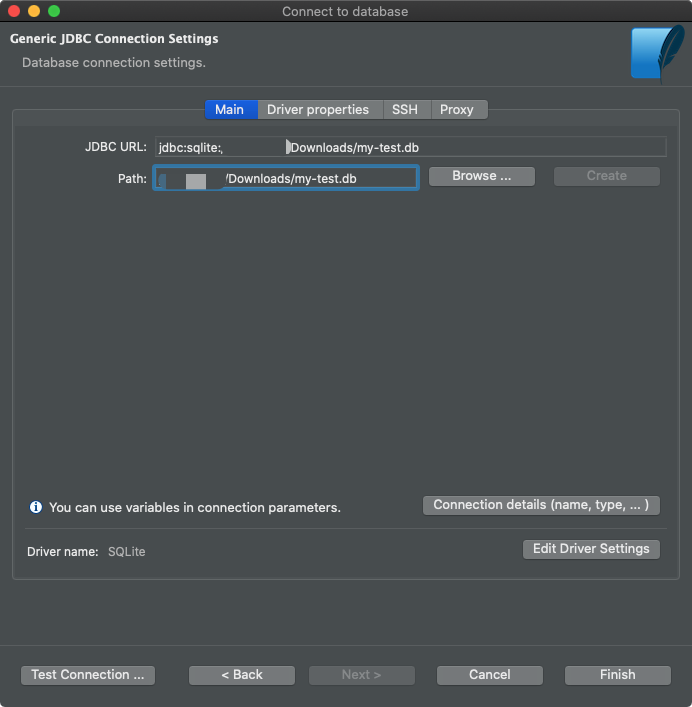
データベースファイルの接続
その後、データベースに対してSQLクエリを実行できます。ここでは、通常のリレーショナルデータベースでの作業と異なる特別なことは何もありません。
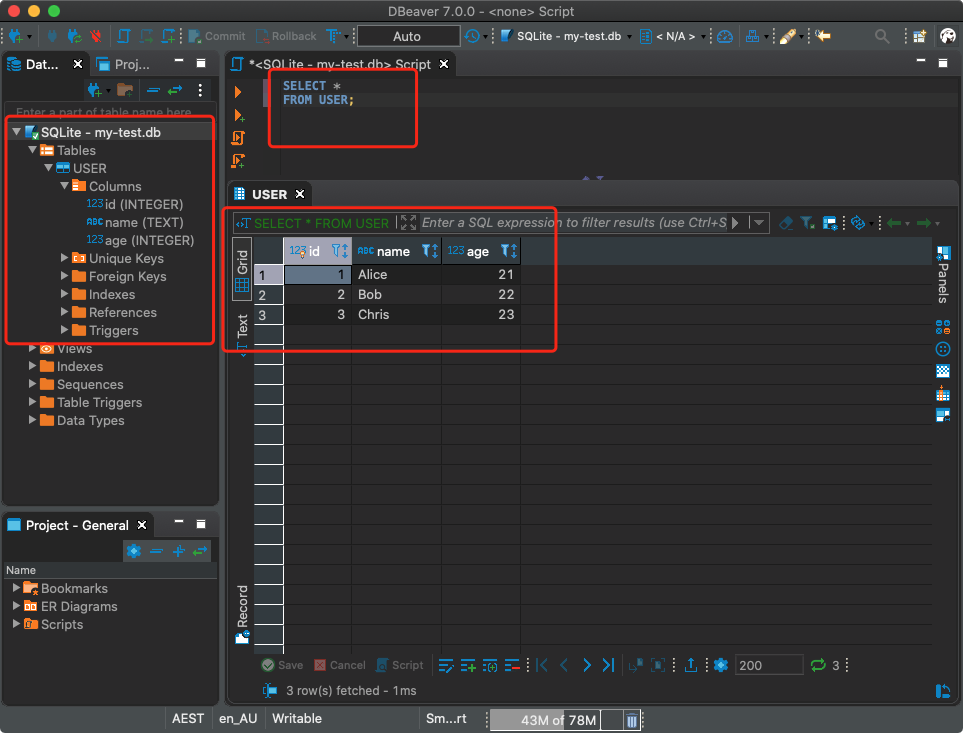
データベースクエリの実行
パンダとの統合
これで、PythonでのSQLiteサポートについての会話を締めくくると思いますか?いいえ、まだ話し合うことがたくさんあります。つまり、SQLiteは標準のPythonモジュールであるため、pandasデータフレームと簡単に統合できます。
データフレームを宣言しましょう:
df_skill = pd.DataFrame({
'user_id': [1,1,2,2,3,3,3],
'skill': ['Network Security', 'Algorithm Development', 'Network Security', 'Java', 'Python', 'Data Science', 'Machine Learning']
})
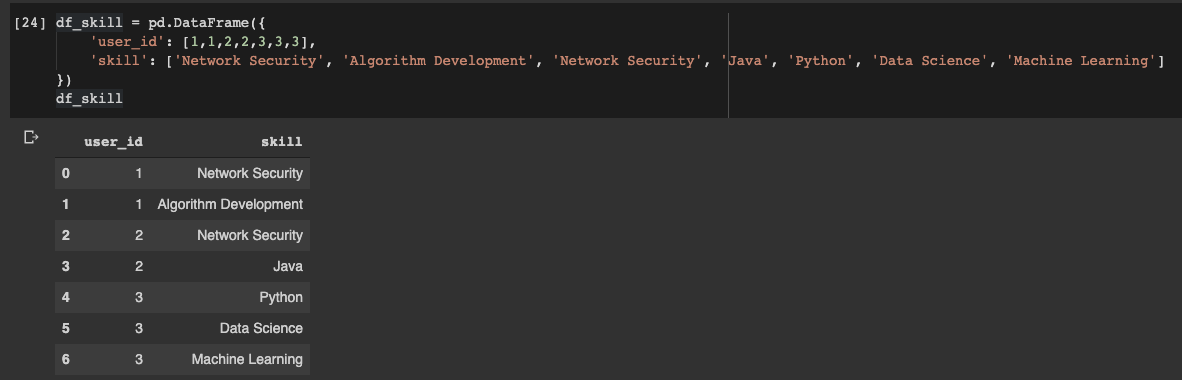
Pandasデータフレームデータフレーム
をデータベースに保存するには、次の方法を使用するだけです
to_sql()。
df_skill.to_sql('SKILL', con)
それで全部です!事前にテーブルを作成する必要もありません。フィールドのデータタイプと特性は、データフレームの特性に基づいて自動的に構成されます。もちろん、必要に応じてすべてを自分でカスタマイズできます。
ここで、テーブル
USERとの和集合を取得し、SKILLdatafreympandasにデータを書き込む必要があるとします。それも非常に簡単です:
df = pd.read_sql('''
SELECT s.user_id, u.name, u.age, s.skill
FROM USER u LEFT JOIN SKILL s ON u.id = s.user_id
''', con)
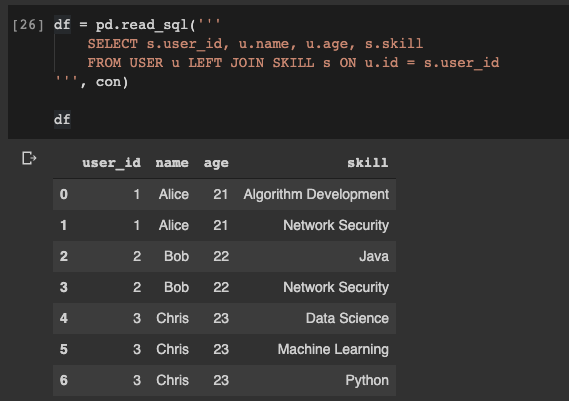
データベースからパンダデータフレームにデータを読み取る
素晴らしい!それでは、次のような新しいテーブルに取得したものを記述しましょう
USER_SKILL。
df.to_sql('USER_SKILL', con)
もちろん、SQLクライアントを使用してこのテーブルを操作できます。
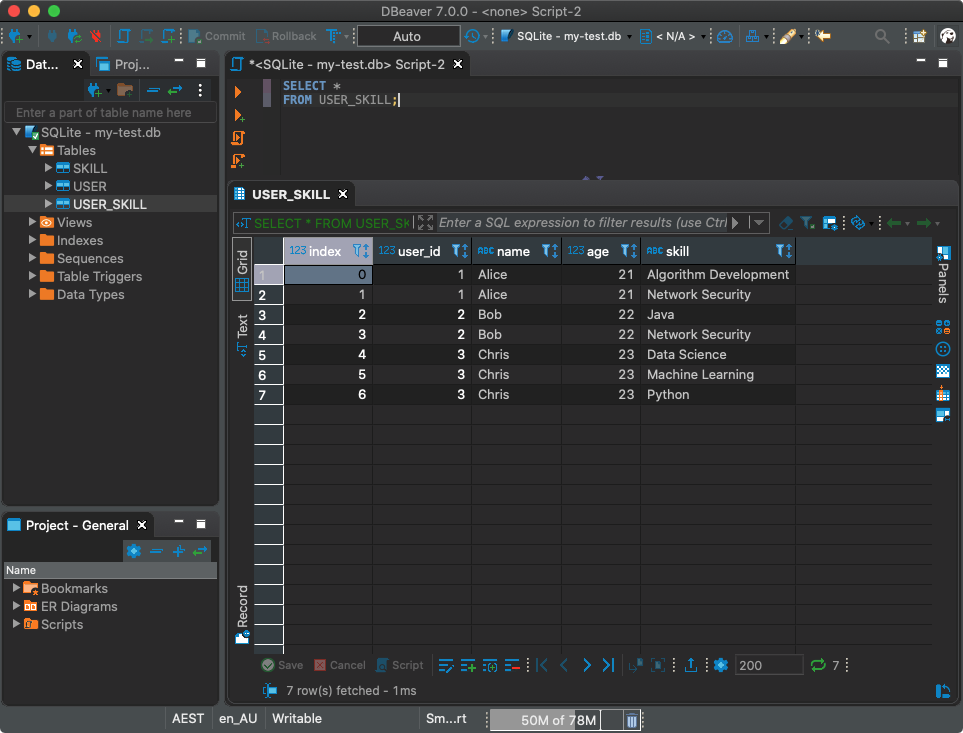
SQLクライアントを使用してデータベースを操作する
結果
Pythonには確かに多くの楽しい驚きがあり、特にそれらを探さない限り、気付かないかもしれません。そのような機能を特別に隠した人は誰もいませんが、Pythonには多くのものが組み込まれているため、これらの機能のいくつかに注意を払うことができないか、どこかからそれらについて学んだので、単に忘れてしまいます。
ここでは、組み込みのPythonライブラリ
sqlite3を使用してデータベースを作成および操作する方法について説明しました。もちろん、このようなデータベースは、データの追加操作だけでなく、情報の変更や削除の操作もサポートしています。学んだことでsqlite3、すべて自分で体験できると思います。
非常に重要なことは、SQLiteがパンダで素晴らしい仕事をするということです。データフレームに配置することで、データベースからデータを読み取るのは非常に簡単です。データフレームの内容をデータベースに保存する操作は、それほど簡単ではありません。これにより、SQLiteがさらに使いやすくなります。
これまで読んだすべての人に、興味深いPython機能を探して独自の調査を行うことをお勧めします。
この記事で示したコードは、ここにあります。
PythonプロジェクトでSQLiteを使用していますか?
