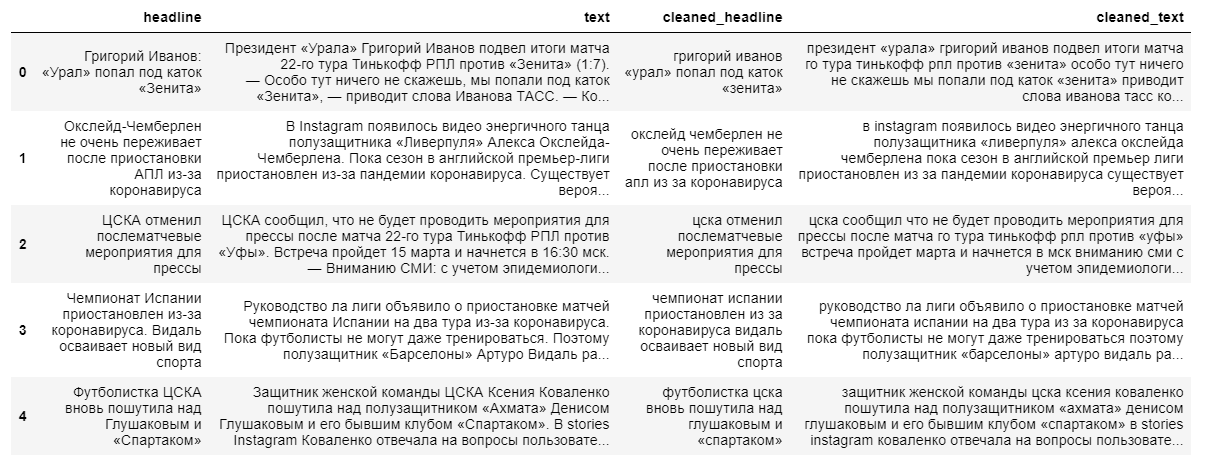
当社では、ドキュメントの自動抽出に積極的に取り組んでいます。この記事にはすべての詳細とコードは含まれていませんが、中立的なデータセットの例を使用して主なアプローチと結果について説明しました。Sport-Express情報ポータルから収集された30,000のサッカースポーツニュース記事です。
したがって、要約は、元のテキストの要約(タイトル、要約、注釈)の自動作成として定義できます。この問題には、抽出と抽象の2つの大きく異なるアプローチがあります。
抽出的要約
抽出アプローチは、ソーステキストから最も「重要な」情報ブロックを抽出することで構成されます。ブロックは、単一の段落、文、またはキーワードにすることができます。

このアプローチの方法は、情報ブロックの重要性の評価関数の存在によって特徴付けられます。これらのブロックを重要度の順にランク付けし、以前に指定した数を選択することにより、テキストの最終的な要約を作成します。
いくつかの抽出アプローチの説明に移りましょう。
一般的な単語の出現に基づく抽出的な合計
このアルゴリズムは非常に簡単に理解でき、さらに実装できます。ここでは、ソースコードのみを使用しており、概して、抽出モデルをトレーニングする必要はありません。私の場合、取得された情報ブロックは特定のテキスト文を表します。
したがって、最初のステップでは、入力テキストを文に分割し、各文をトークン(個別の単語)に分割し、それらのレンマ化を実行します(単語を「正規」形式にします)。このステップは、アルゴリズムが意味は同じであるが単語の形式が異なる単語を組み合わせるために必要です。
次に、文の各ペアに類似度関数を設定します。これは、両方の文で見つかった一般的な単語の数とそれらの全長の比率として計算されます。..。その結果、文の各ペアの類似度係数を取得します。
以前に他の人と共通の単語がない文を削除したので、頂点が文自体であり、その間のエッジがそれらの中に共通の単語の存在を示すグラフを作成します。
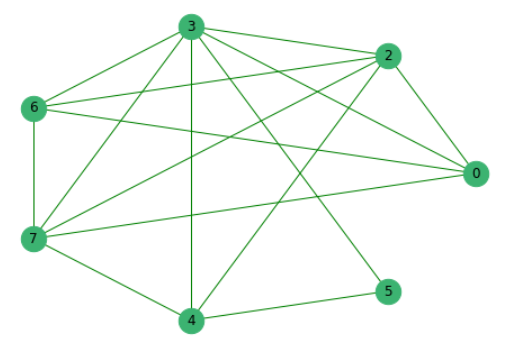
次に、すべての提案を重要度に従ってランク付けします。

係数が最も高い文をいくつか選択し、テキスト内の出現回数で並べ替えると、最終的な要約が得られます。
訓練されたベクトル表現に基づく抽出的合計
以前に収集されたフルテキストニュースデータは、次のアルゴリズムを構築するために使用されました。
すべてのテキストの単語をトークンに分割し、それらを組み合わせてリストにします。合計で、テキストには2,270,778語が含まれ、そのうち114,247語が一意でした。
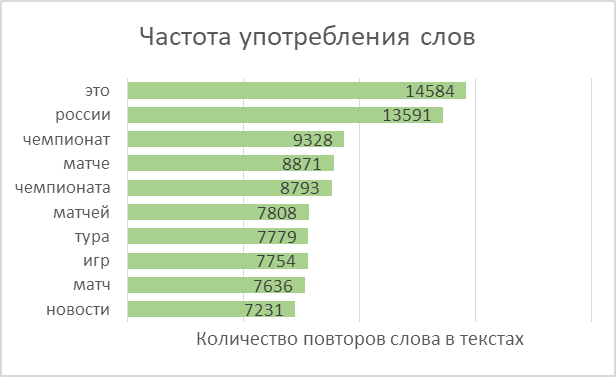
人気のあるWord2Vecモデルを使用して、一意の単語ごとにそのベクトル表現を見つけます。モデルはランダムなベクトルを各単語に割り当て、学習の各ステップで「コンテキストの調査」によってそれらの値を修正します。単語の特徴を「記憶」できるベクトルの次元は、任意に設定できます。利用可能なデータセットのボリュームに基づいて、100個の数値で構成されるベクトルを取得します。また、Word2Vecは再トレーニング可能なモデルであり、新しいデータを入力に送信し、それに基づいて、単語の既存のベクトル表現を修正できることにも注意してください。
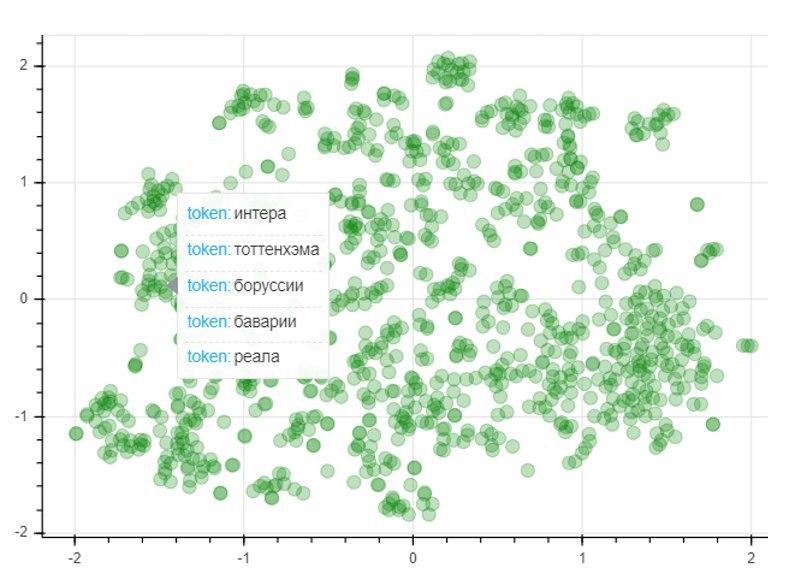
モデルの品質を評価するために、T-SNE次元削減法を適用します。この方法では、最もよく使用される1000個の単語のベクトルマッピングを2次元空間に繰り返し構築します。結果のグラフは、ポイントの位置を表します。各ポイントは、意味が似ている単語が互いに近くに配置され、反対に異なる単語が配置されるように、特定の単語に対応します。したがって、グラフの左側にはサッカークラブの名前があり、左下隅のドットはサッカー選手とコーチの名前と姓を表しています。
単語の訓練されたベクトル表現を取得した後、アルゴリズム自体に進むことができます。前の場合と同様に、入力には、文に分割するテキストがあります。各文をトークン化することにより、それらのベクトル表現を作成します。これを行うには、文内の各単語のベクトルの合計と文自体の長さの比率を取ります。以前に訓練された単語ベクトルはここで私たちを助けます。辞書に単語がない場合、ゼロベクトルが現在の文ベクトルに追加されます。したがって、辞書にない新しい単語の出現が文の一般的なベクトルに与える影響を中和します。
次に、文の各ペアの余弦類似性式を使用する文類似性マトリックスを作成します。
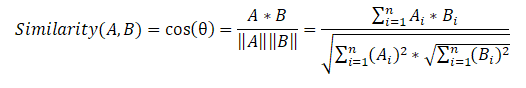
最後の段階では、類似性マトリックスに基づいて、グラフを作成し、重要度による文のランク付けも実行します。前のアルゴリズムと同様に、テキスト内の重要度に従ってソートされた文のリストを取得します。

最後に、アルゴリズム実装の主な段階を概略的に示し、もう一度説明します(最初の抽出アルゴリズムの場合、アクションのシーケンスは、単語のベクトル表現を見つける必要がないことを除いて、まったく同じです。各ペアの文の類似度関数は、共通の発生に基づいて計算されます。言葉):

- 入力テキストを別々の文に分割して処理します。
- 各文のベクトル表現を検索します。
- 文ベクトル間の類似性を計算してマトリックスに保存します。
- 結果のマトリックスを、頂点の形式の文とエッジの形式の類似性推定値を含むグラフに変換して、文のランクを計算します。
- 最終再開のスコアが最も高い提案の選択。
抽出アルゴリズムの比較
Flaskマイクロフレームワーク(最小限のWebアプリケーションを作成するためのツール)を使用して、さまざまなソースニューステキストの例を使用して抽出モデルの出力を視覚的に比較するためのテストWebサービスが開発されました。100の異なるスポーツニュース記事について、両方のモデル(最も重要な2つの文を抽出)によって生成された概要を分析しました。

両方のモデルで最も関連性の高いオファーを決定した結果を比較した結果に基づいて、アルゴリズムを使用するための次の推奨事項を提供できます。
- . , . , .
- . , , , . , , , .
抽象的要約
抽象的アプローチは、その前身とは大きく異なり、新しいテキストを生成して要約を生成し、主要なドキュメントを有意義に要約することにあります。
このアプローチの主なアイデアは、モデルが完全に一意の要約を生成できることです。これには、元のテキストにない単語が含まれている可能性があります。モデル推論は、テキストの再記述であり、人々によるテキストの要約の手動編集に近いものです。
学習フェーズ
アルゴリズムの数学的正当性については詳しく説明しません。私が知っているすべてのモデルは、「エンコーダー-デコーダー」アーキテクチャーに基づいています。このアーキテクチャーは、繰り返しLSTMレイヤーを使用して構築されています(これらの作業の原理については、こちらを参照してください)。テストシーケンスをデコードする手順について簡単に説明します。
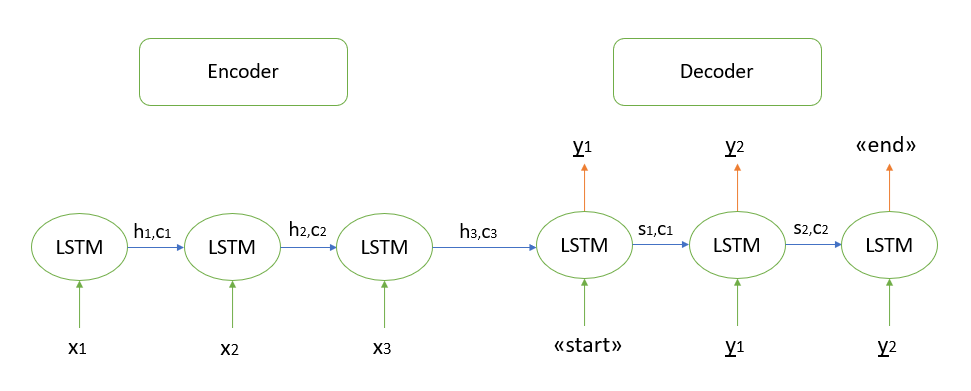
- 入力シーケンス全体をエンコードし、エンコーダの内部状態でデコーダを初期化します
- 「開始」トークンをデコーダーへの入力として渡します
- デコーダーをエンコーダーの内部状態で1つのタイムステップで開始します。その結果、次の単語(最大確率の単語)の確率を取得します。
- 選択したワードを次のタイムステップでデコーダーへの入力として渡し、内部状態を更新します
- 「終了」トークンを生成するまで、手順3と4を繰り返します。
「エンコーダ-デコーダ」アーキテクチャの詳細については、こちらをご覧ください。
抽象的要約の実装
要約コンテンツを抽出するためのより複雑な抽象モデルを構築するには、完全なニューステキストとその見出しの両方が必要です。モデルは長いテキストシーケンスを「よく覚えていない」ため、ニュースの見出しは要約として機能します。
データをクリーンアップするときは、小文字の翻訳を使用し、ロシア語以外の文字を破棄します。文中の単語間の関係が失われるため、単語のレマタイゼーション、前置詞、粒子、およびその他の有益でない音声部分の削除は、モデルの最終出力に悪影響を及ぼします。
次に、テキストとそのタイトルを9対1の比率でトレーニングサンプルとテストサンプルに分割し、その後、それらをベクトルに(ランダムに)変換します。
次のステップでは、モデル自体を作成します。モデル自体は、送信された単語のベクトルを読み取り、LSTMエンコーダーの3つの反復レイヤーとデコーダーの1つのレイヤーを使用して処理を実行します。
モデルを初期化した後、実際のターゲットタイトルとモデルによって予測されたタイトルとの間の不一致を示すクロスエントロピー損失関数を使用してモデルをトレーニングします。

最後に、トレーニングセットのモデル結果を出力します。例でわかるように、モデルを構築する前にまれな単語を破棄するため、ソーステキストと要約には不正確さが含まれています(「学習を簡素化する」ために破棄します)。

この段階でのモデル出力には、まだ多くの要望があります。モデルはクラブの名前とサッカー選手の名前のいくつかを「うまく覚えている」が、実際には文脈自体を捉えていなかった。
抽出を再開するためのより現代的なアプローチにもかかわらず、このアルゴリズムは以前に作成された抽出モデルよりも非常に劣っています。それでも、モデルの品質を向上させるには、より大きなデータセットでモデルをトレーニングできますが、私の意見では、本当に良いモデル出力を得るには、使用するニューラルネットワークのアーキテクチャそのものを変更するか、場合によっては完全に変更する必要があります。
では、どちらのアプローチが優れているのでしょうか?
この記事を要約すると、要約を抽出するためのレビューされたアプローチの主な長所と短所をリストし
ます。1。抽出アプローチ:
利点:
- アルゴリズムの本質は直感的です
- 実装が比較的簡単
短所:
- 多くの場合、コンテンツの品質は人間の手書きのコンテンツよりも悪い可能性があります
2.抽象的なアプローチ:
利点:
- 適切に実装されたアルゴリズムは、手動の再開書き込みに最も近い結果を生成できます。
短所:
- アルゴリズムの主な理論的アイデアを理解することの難しさ
- アルゴリズムの実装における大きな人件費
どのアプローチが最終的な再開を最もよく形成するかという質問に対する明確な答えはありません。それはすべて、ユーザーの特定のタスクと目標によって異なります。たとえば、抽出アルゴリズムは、関連する文の抽出が実際に大きなテキストのアイデアを正しく伝えることができる、複数ページのドキュメントのコンテンツを生成するのに適している可能性が最も高いです。
私の意見では、未来は抽象的なアルゴリズムに属しています。現時点では開発が不十分で、一定レベルの出力品質では小さな要約(1〜2文)の生成にしか使用できないという事実にもかかわらず、ニューラルネットワーク方式からのブレークスルーを期待する価値があります。将来的には、絶対にあらゆるサイズのテキストのコンテンツを作成できるようになります。最も重要なことは、コンテンツ自体が、特定の分野の専門家による履歴書の手動作成に可能な限り近いものになることです。
Veklenko Vlad、システムアナリスト、
コーデックスコンソーシアム