Bツリーインデックスがどのようになったかを理解するために、Bツリーインデックスのない世界を想像して、典型的な問題を解決してみましょう。その過程で、私たちが直面する問題とその解決方法について話し合います。

前書き
データベースの世界では、情報を保存する最も一般的な方法が2つあります。
- ログベースの構造に基づいています。
- ページに基づいています。
最初の方法の利点は、データを簡単かつ迅速に読み取って保存できることです。新しい情報はファイルの最後にのみ書き込むことができ(順次記録)、これにより高い記録速度が保証されます。このメソッドは、Leveldb、Rocksdb、Cassandraなどのベースで使用されます。
2番目の方法(ページベース)は、データを固定サイズのチャンクに分割し、ディスクに保存します。これらの部分は「ページ」または「ブロック」と呼ばれます。それらには、テーブルからのレコード(行、タプル)が含まれています。
このデータストレージの方法は、MySQL、PostgreSQL、Oracleなどで使用されています。また、MySQLのインデックスについて話しているので、これが検討するアプローチです。
MySQLでのデータストレージ
したがって、MySQLのすべてのデータはページとしてディスクに保存されます。ページサイズはデータベース設定によって規制されており、デフォルトでは16KBです。
各ページには、38バイトのヘッダーと8バイトの末尾が含まれています(図を参照)。また、MySQLは将来の変更のために各ページに空のスペースを残すため、データストレージに割り当てられたスペースは完全には埋められません。
さらに計算では、ページの16 KBすべてがデータで満たされていると仮定して、サービス情報を無視します。 InnoDBページの構成については詳しく説明しません。これは、別の記事のトピックです。これについて詳しくは、こちらをご覧ください。

たとえば、インデックスがまだ存在しないことに上記で同意したので、インデックスのない単純なテーブルを作成します(実際、MySQLは引き続きインデックスを作成しますが、計算では考慮しません)。
CREATE TABLE `product` (
`id` INT NOT NULL AUTO_INCREMENT,
`name` CHAR(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`category_id` INT NOT NULL,
`price` INT NOT NULL,
) ENGINE=InnoDB;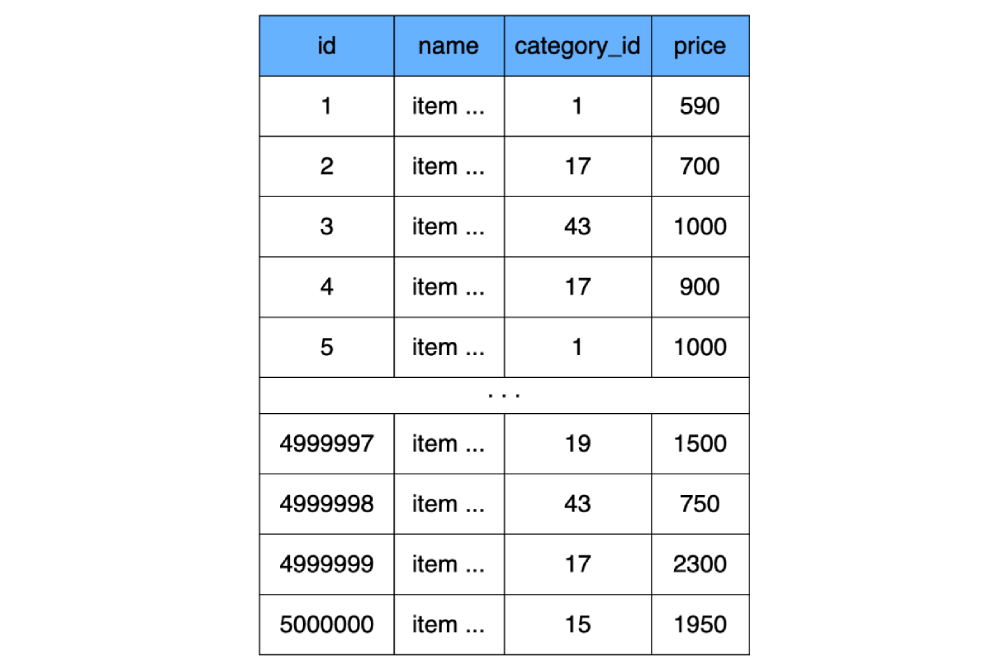
次のリクエストを実行します。
SELECT * FROM product WHERE price = 1950;MySQLは、テーブルのデータが保存されているファイルを開き、
product必要なレコードを検索するためにすべてのレコード(行)の反復を開始し、price見つかった各行のフィールドをクエリの値と比較します。わかりやすくするために、ファイルをフルスキャンするオプションを特に検討しているため、MySQLがキャッシュからデータを受信する場合は適切ではありません。
これでどのような問題に直面できますか?
HDD
すべてがハードドライブに保存されているので、そのデバイスを見てみましょう。ハードディスクは、セクター(ブロック)でデータを読み書きします。このようなセクターのサイズは、512バイトから8 KBまでです(ディスクによって異なります)。複数の連続するセクターを組み合わせてクラスターにすることができます。
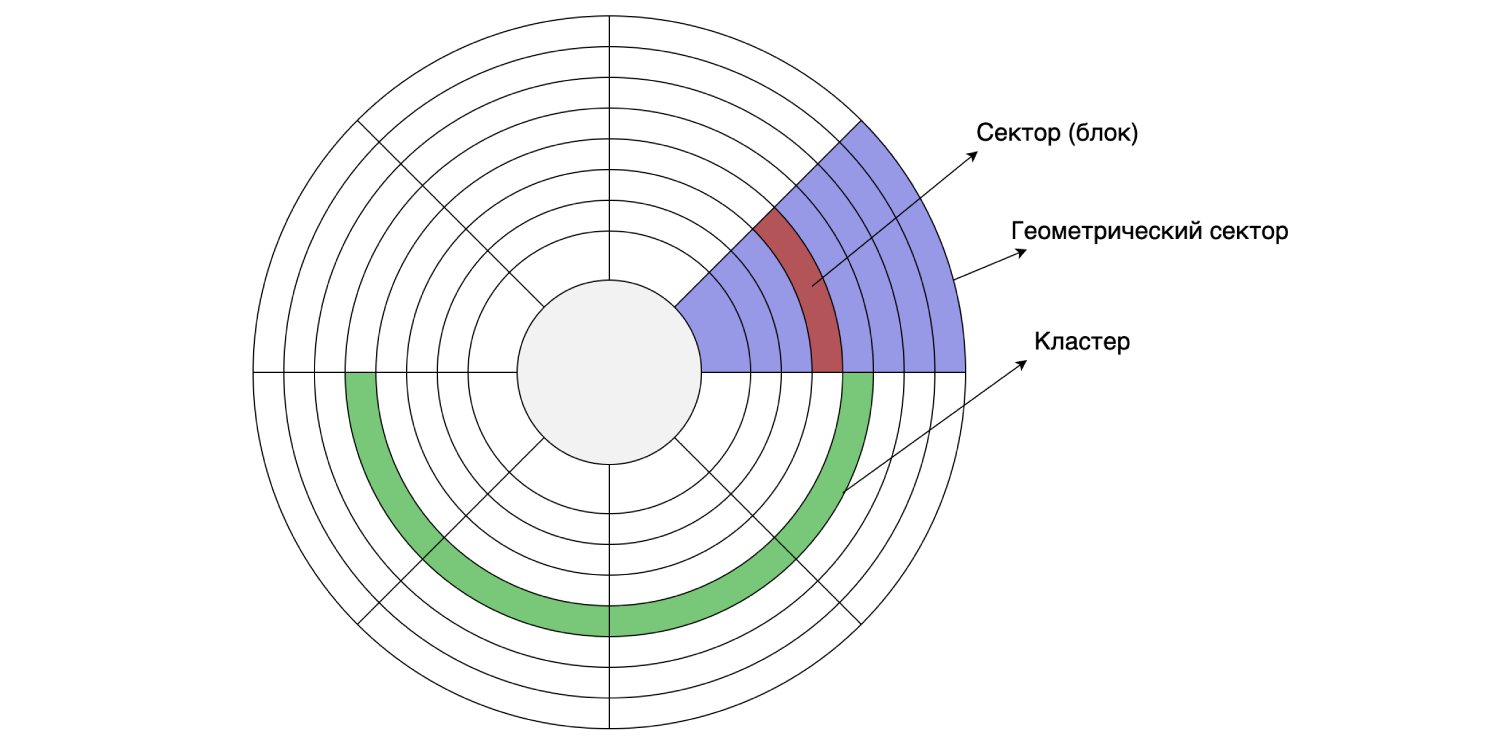
クラスターサイズは、ディスクのフォーマット/パーティション分割時に設定できます。つまり、プログラムで実行されます。ディスク上のセクターサイズが4KBで、ファイルシステムが16KBのクラスターサイズでパーティション化されているとします。1つのクラスターは4つのセクターで構成されます。私たちが覚えているように、MySQLはデフォルトでデータを16 KBページでディスクに保存するため、1ページが1つのディスククラスターに収まります。
500,000アイテムを保持すると仮定して、製品プレートにかかるスペースを計算してみましょう。私たちは、3〜4バイトのフィールドを持っている
id、priceとcategory_id。すべてのレコードの名前フィールドが最後まで入力され(すべて100文字)、各文字が3バイトかかることに同意しましょう。 (3 * 4)+(100 * 3)= 312バイト-これは、テーブルの1行の重みであり、これに500,000行を掛けると、product156メガバイトのテーブル重みが得られます。
したがって、このラベルを保存するには、ハードディスクに9750クラスターが必要です(16 KBの9750ページ)。
ディスクに保存すると、空きクラスターが取得されます。これにより、ディスク全体で1つのプレート(ファイル)のクラスターが「スミアリング」されます(これはフラグメンテーションと呼ばれます)。ディスク上にランダムに配置されたこのようなメモリブロックの読み取りは、ランダム読み取りと呼ばれます。ハードディスクヘッドを何度も移動する必要があるため、この読み取りは遅くなります。ファイル全体を読み取るには、ディスク全体をジャンプして必要なクラスターを取得する必要があります。
SQLクエリに戻りましょう。すべての行を見つけるために、サーバーはディスク全体に散在するすべての9750クラスターを読み取る必要があり、ディスク読み取りヘッドを移動するのに多くの時間がかかります。データを使用するクラスターが多いほど、検索が遅くなります。その上、私たちの操作はオペレーティングシステムのI / Oシステムを詰まらせます。
結局、読み取り速度が遅くなります。OSを「一時停止」し、I / Oシステムを詰まらせます。そして、各行のクエリ条件をチェックしながら、多くの比較を行います。
自分の自転車
どうすればこの問題を自分で解決できますか?
テーブルルックアップを改善する方法を理解する必要があります
product。フィールドpriceとレコード(ディスク上の領域)へのリンクのみをテーブルに格納する別のテーブルを作成しましょうproduct。新しいテーブルにデータを追加するときは、ソートされた形式で価格を保存するという原則をすぐに考えてみましょう。
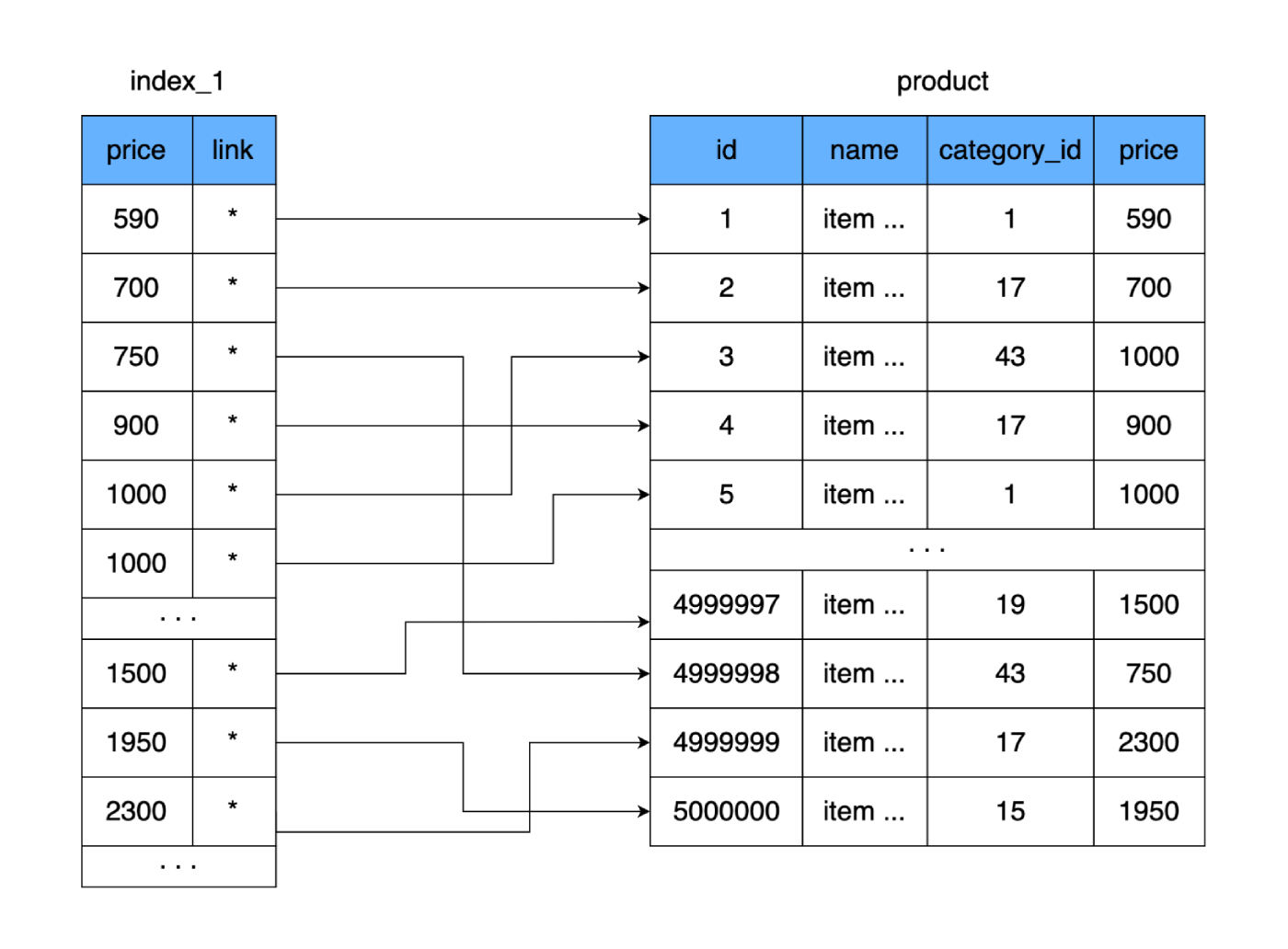
それは私たちに何を与えますか?新しいテーブルは、メインのテーブルと同様に、ページごとに(ブロック単位で)ディスクに保存されます。価格とメインテーブルへのリンクが含まれています。このようなテーブルに必要なスペースを計算してみましょう。価格は4バイトで、メインテーブル(アドレス)への参照も4バイトとします。 500,000行の場合、新しいテーブルの重量はわずか4MBになります。そうすれば、新しいテーブルのより多くの行が1つのデータページに収まり、すべての価格を保存するために必要なページが少なくなります。
完全なテーブルに9,750個のハードディスククラスターが必要な場合(最悪のシナリオ、9,750個のハードディスクホップ)、新しいテーブルは250個のクラスターにのみ適合します。これにより、ディスク上で使用されるクラスターの数が大幅に削減され、ランダムな読み取りに費やされる時間が短縮されます。新しいテーブル全体を読み、値を比較して適切な価格を見つけたとしても、最悪の場合、新しいテーブルのクラスター全体で250回のジャンプが必要になります。そして、必要なアドレスを見つけた後、完全なデータが配置されている別のクラスターを読み取ります。結果:元の9750に対して251の読み取り値。違いは重要です。
さらに、そのようなテーブルを検索するには、たとえば、バイナリ検索アルゴリズムを使用できます(リストがソートされているため)。これにより、読み取りと比較操作の数をさらに節約できます。
2番目のテーブルをインデックスと呼びましょう。
やったー!独自の
しかし、やめてください。テーブルが大きくなるにつれて、インデックスもどんどん大きくなり、最終的には元の問題に戻ります。検索には再び長い時間がかかります。
別のインデックス
また、既存のインデックスの上に別のインデックスを作成した場合はどうなりますか?
今回だけ、フィールドのすべての値を書き留めるわけではありませんが、
price1つの値をインデックスのページ全体(ブロック)に関連付けます。つまり、追加のレベルのインデックスが表示され、前のインデックス(最初のインデックスのデータが格納されているディスク上のページ)のデータセットを指します。
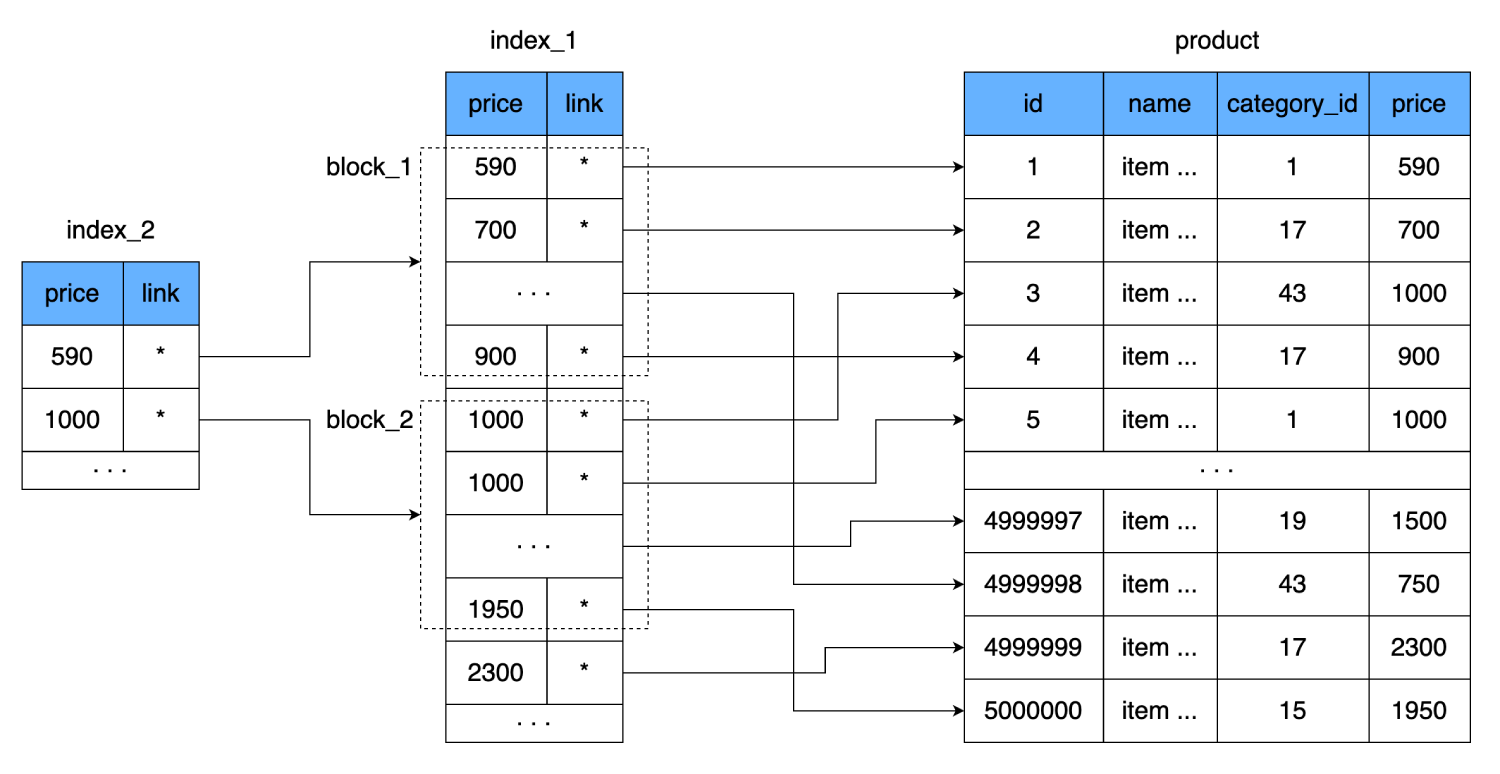
これにより、読み取りの数がさらに減少します。インデックスの1行は8バイトを使用します。つまり、1つの16キロバイトのページに2000行を収めることができます。新しいインデックスには、最初のインデックスの2000行のブロックへのリンクと、このブロックが開始される価格が含まれます。そのような1行も8バイトかかりますが、その数は大幅に減少します。500,000ではなく250だけです。1つのハードディスククラスターにさえ収まります。したがって、希望の価格を見つけるために、2000行のどのブロックにあるかを正確に判断できます。そして最悪の場合、同じレコードを見つけるために、私たちは:
- 新しいインデックスから1回読み取ります。
- 250行を実行した後、2番目のインデックスからデータブロックへのリンクを見つけます。
- 価格とメインテーブルへのリンクを含む2000行を含む1つのクラスターを検討します。
- これらの2000行を確認すると、最後のデータブロックを読み取るために必要な1回と1回のジャンプがディスクを横切っていることがわかります。
合計3つのクラスタージャンプが発生します。
しかし遅かれ早かれ、このレベルも多くのデータで満たされるでしょう。したがって、新しいレベルを何度も追加して、これまでに行ったすべてのことを繰り返す必要があります。つまり、インデックスを格納するためのこのようなデータ構造が必要です。これにより、インデックスのサイズが大きくなるにつれて新しいレベルが追加され、それらの間でデータのバランスが独立して得られます。
最後のインデックスが上になり、メインテーブルが下のデータになるようにテーブルを裏返すと、ツリーに非常によく似た構造になります。
Bツリーデータ構造は同様の原理で機能するため、これらの目的のために選択されました。
Bツリーの概要
MySQLで使用される最も一般的なインデックスは、Bツリー(バランス検索ツリー)の順序付きインデックスです。
Bツリーの一般的な考え方は、インデックステーブルに似ています。値は順番に保存され、ツリーのすべての葉はルートから同じ距離にあります。
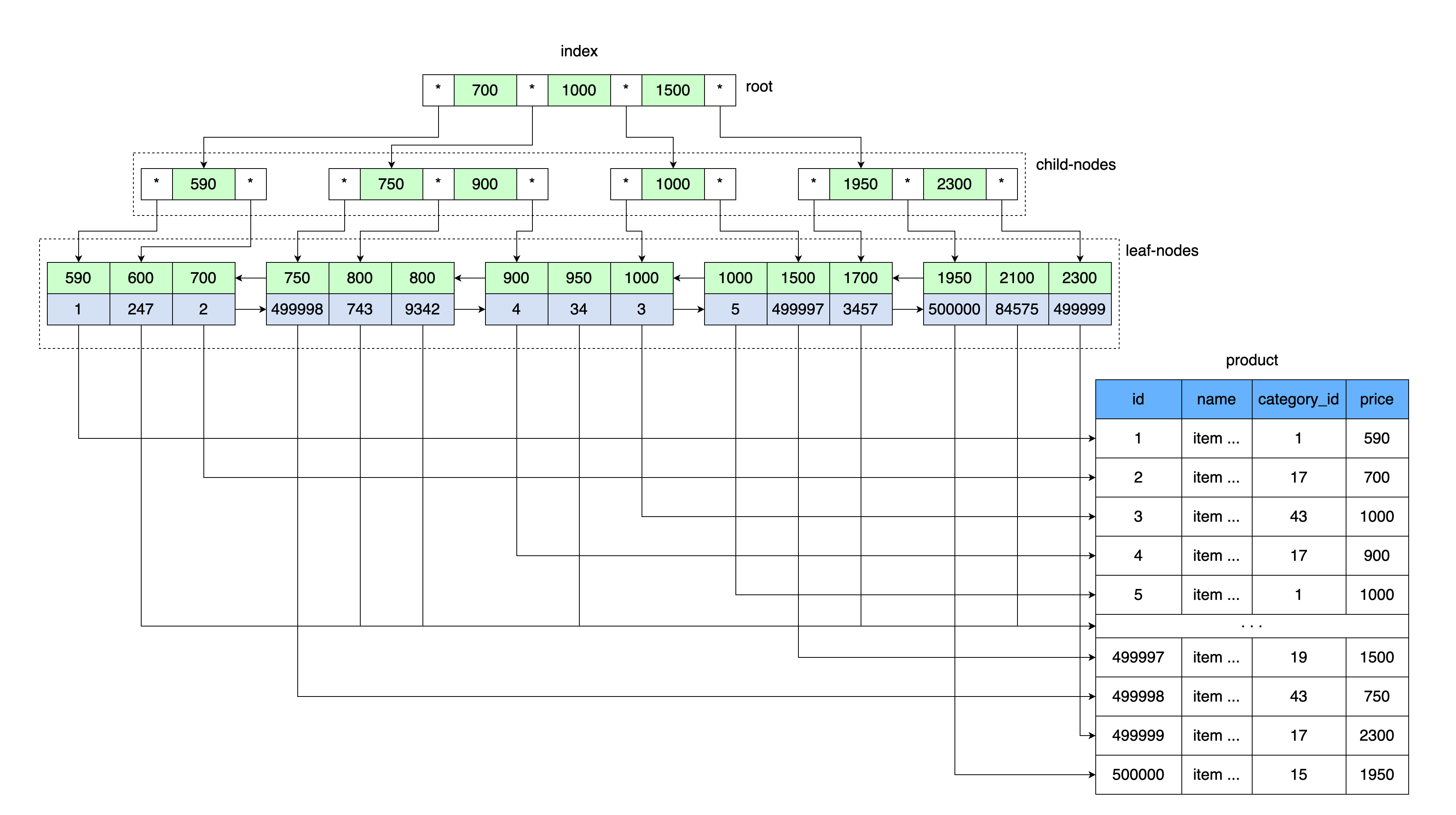
インデックス付きのテーブルに価格値と、この価格の値の範囲を含むデータブロックへのリンクが格納されているのと同じように、Bツリールートには価格値とディスク上のメモリ領域へのリンクが格納されます。
最初に、Bツリーのルートを含むページが読み取られます。さらに、キーの範囲を入力した後、目的の子ノードへのポインターがあります。子ノードのページが読み取られ、そこからデータシートへのリンクがキー値から取得され、データのあるページがこのリンクから読み取られます。
InnoDBのBツリー
より具体的には、InnoDBはB +ツリーデータ構造を使用します。
MySQLはプライマリキーとセカンダリキーのそのようなインデックスを保存するため、テーブルを作成するたびに、自動的にB +ツリーが作成されます。
二次キーはさらに、データ行への参照として一次(クラスター)キーの値を格納します。その結果、セカンダリキーはプライマリキーの値のサイズだけ大きくなります。
さらに、B +ツリーは子ノード間に追加のリンクを使用するため、値の範囲を検索する速度が向上します。InnoDBのb +ツリーインデックスの構造について詳しくは、こちらをご覧ください。
まとめ
b-treeインデックスは、ディスクから読み取られる情報の量を劇的に減らすことにより、値の範囲にわたってデータを検索するときに大きな利点を提供します。条件による検索だけでなく、並べ替え、結合、グループ化にも参加します。 MySQLがインデックスをどのように使用するかをここで読んでください。
データベースへのクエリのほとんどは、値または値の範囲によって情報を検索するための単なるクエリです。したがって、MySQLでは、最も一般的に使用されるインデックスはbツリーインデックスです。
また、b-treeインデックスは、データを取得するときに役立ちます。プライマリキー(クラスタ化されたインデックス)と非クラスタ化インデックスが構築されている列の値(セカンダリキー)がインデックスリーフに格納されているため、このデータのメインテーブルにアクセスしてインデックスから取得することはできなくなります。これをカバーリングインデックスと呼びます。クラスター化インデックスと非クラスター化インデックスの詳細については、この記事を参照してください。
テーブルと同様に、インデックスもディスクに保存され、スペースを占有します。情報がテーブルに追加されるたびに、ノード間のすべてのリンクの正確さを監視するために、インデックスを最新の状態に保つ必要があります。これにより、情報の書き込みにオーバーヘッドが発生します。これは、bツリーインデックスの主な欠点です。書き込み速度を犠牲にして読み取り速度を上げます。
- MySQL . 3-
: ,
: 2018 - blog.jcole.us/innodb
- dev.mysql.com/doc/refman/8.0/en/innodb-storage-engine.html