技術の世界は新しい誇大宣伝-GPT-3を受け入れました。
巨大な言語モデル(GPT-3など)は、その機能でますます私たちを驚かせます。そして、それらに対するビジネスの信頼は、それらを顧客に提示するのに十分ではありませんが、これらのモデルは、自動化の開発と「スマート」コンピューティングシステムの機能を加速するインテリジェンスの始まりを示しています。GPT-3から謎のオーラを取り除き、それがどのように学習し、どのように機能するかを調べてみましょう。
訓練された言語モデルはテキストを生成します。モデルの入力にテキストを送信して、出力がどのように変化するかを確認することもできます。後者は、大量のテキストを分析することにより、トレーニング期間中にモデルが「学習」したものから生成されます。
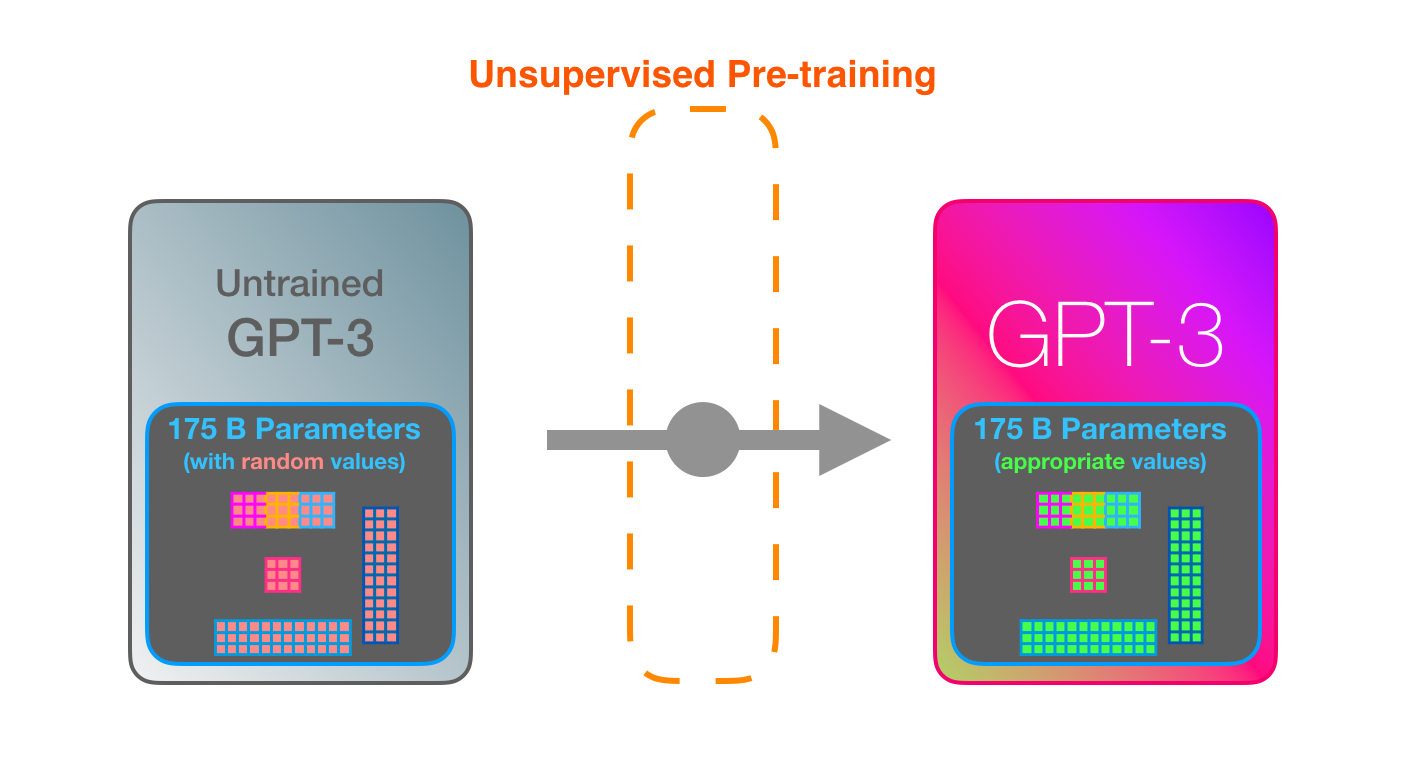
学習は、大量のテキストをモデルに転送するプロセスです。GPT-3の場合、このプロセスは完了しており、表示されるすべての実験は、すでにトレーニングされたモデルで実行されています。トレーニングには355GPU年(1枚のグラフィックカードで355年のトレーニング)かかり、460万ドルかかると見積もられました。
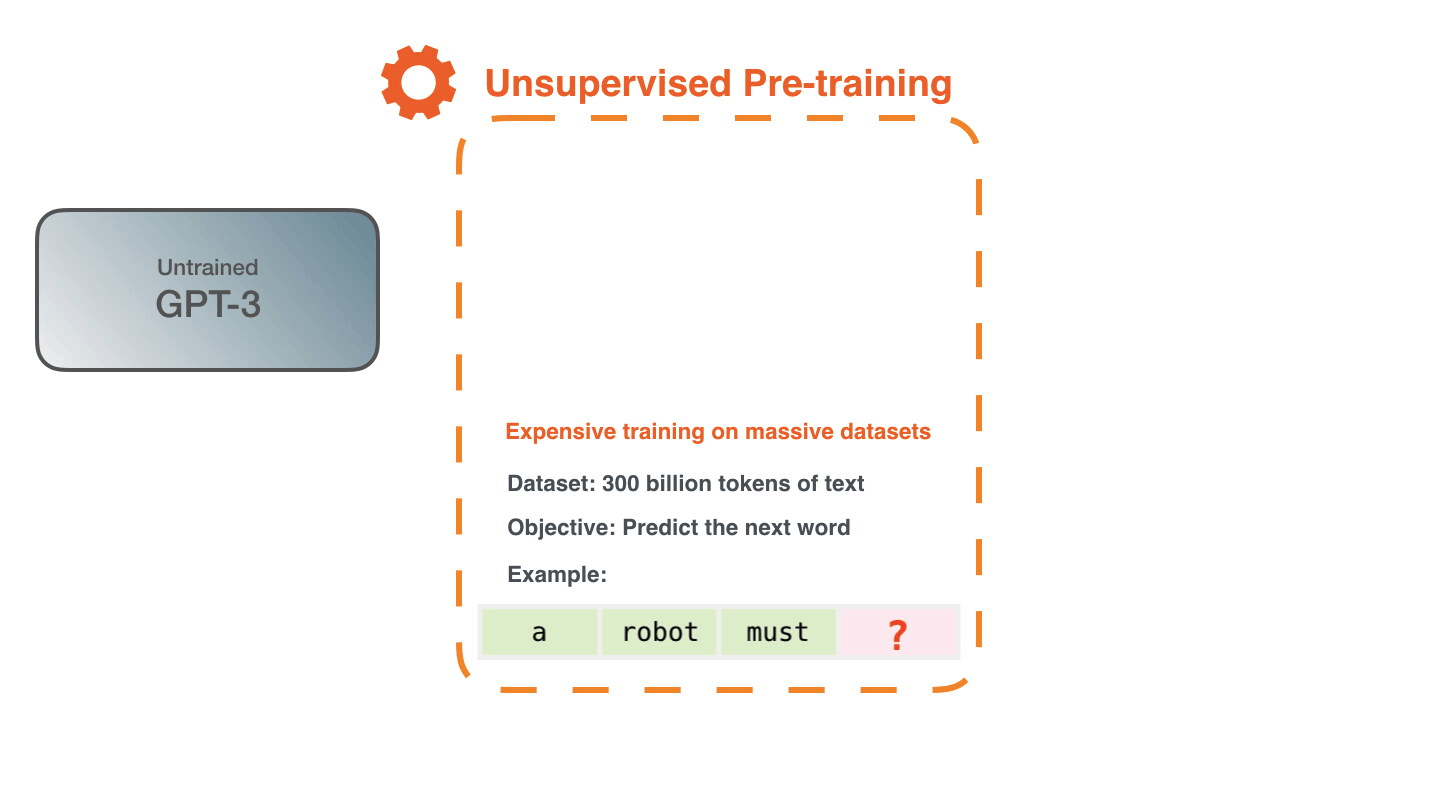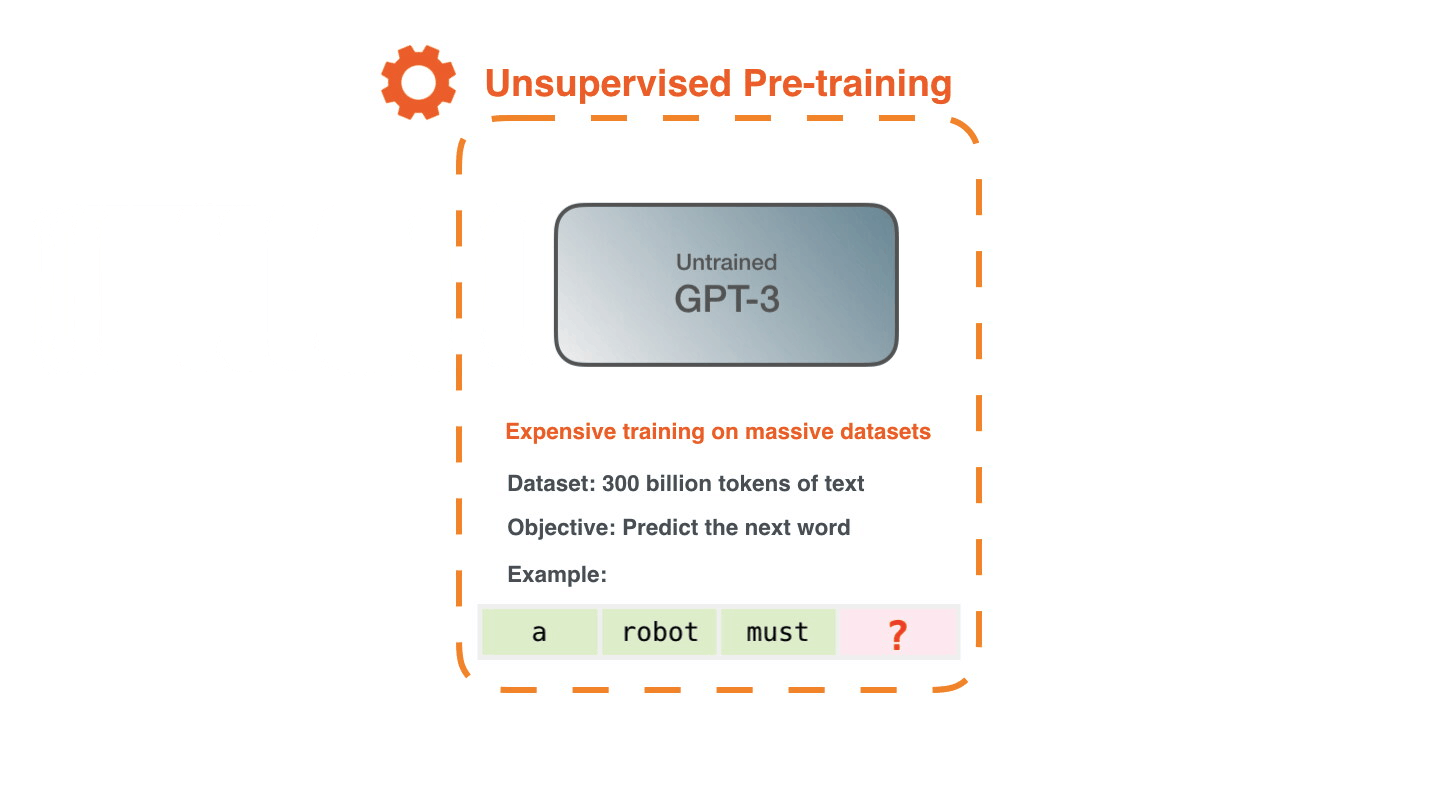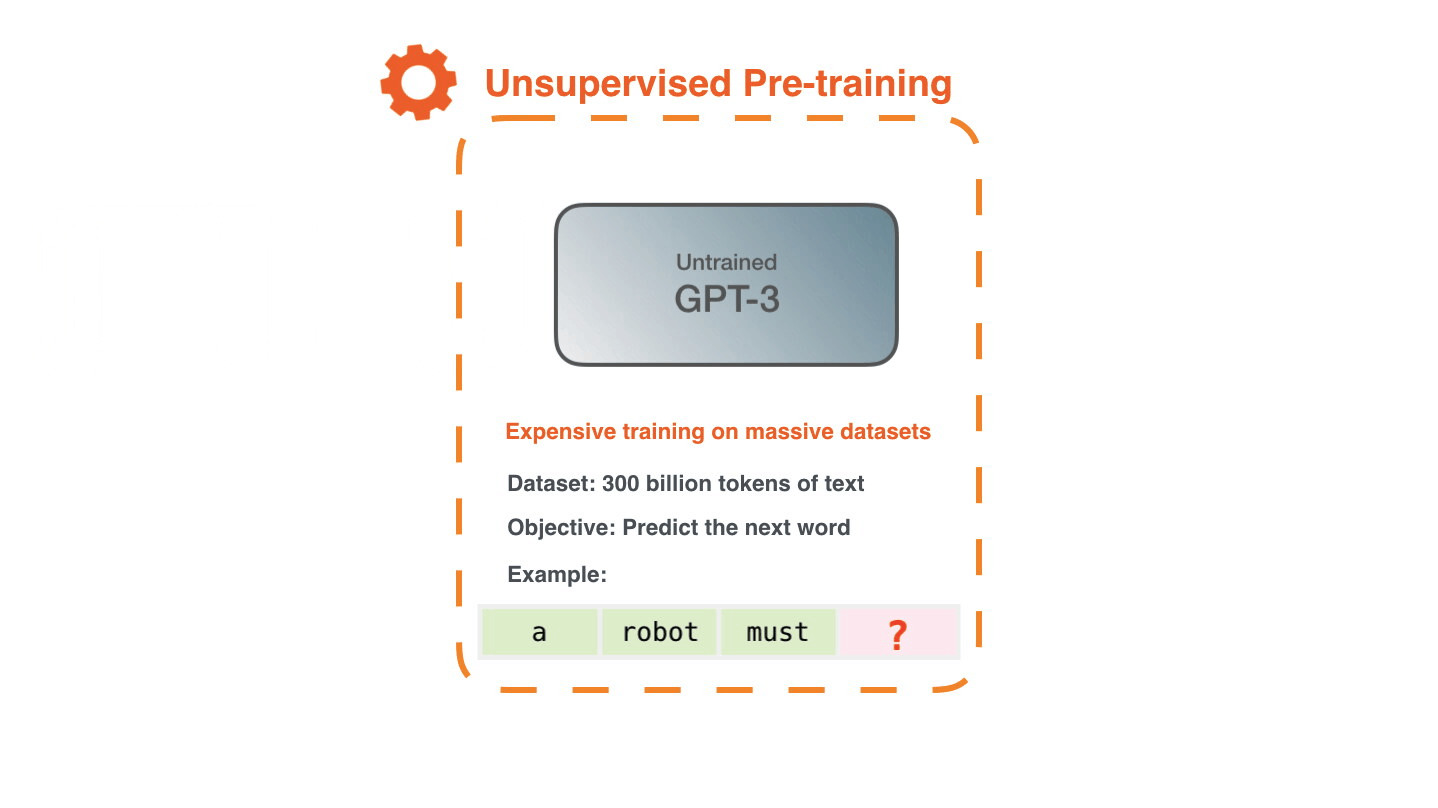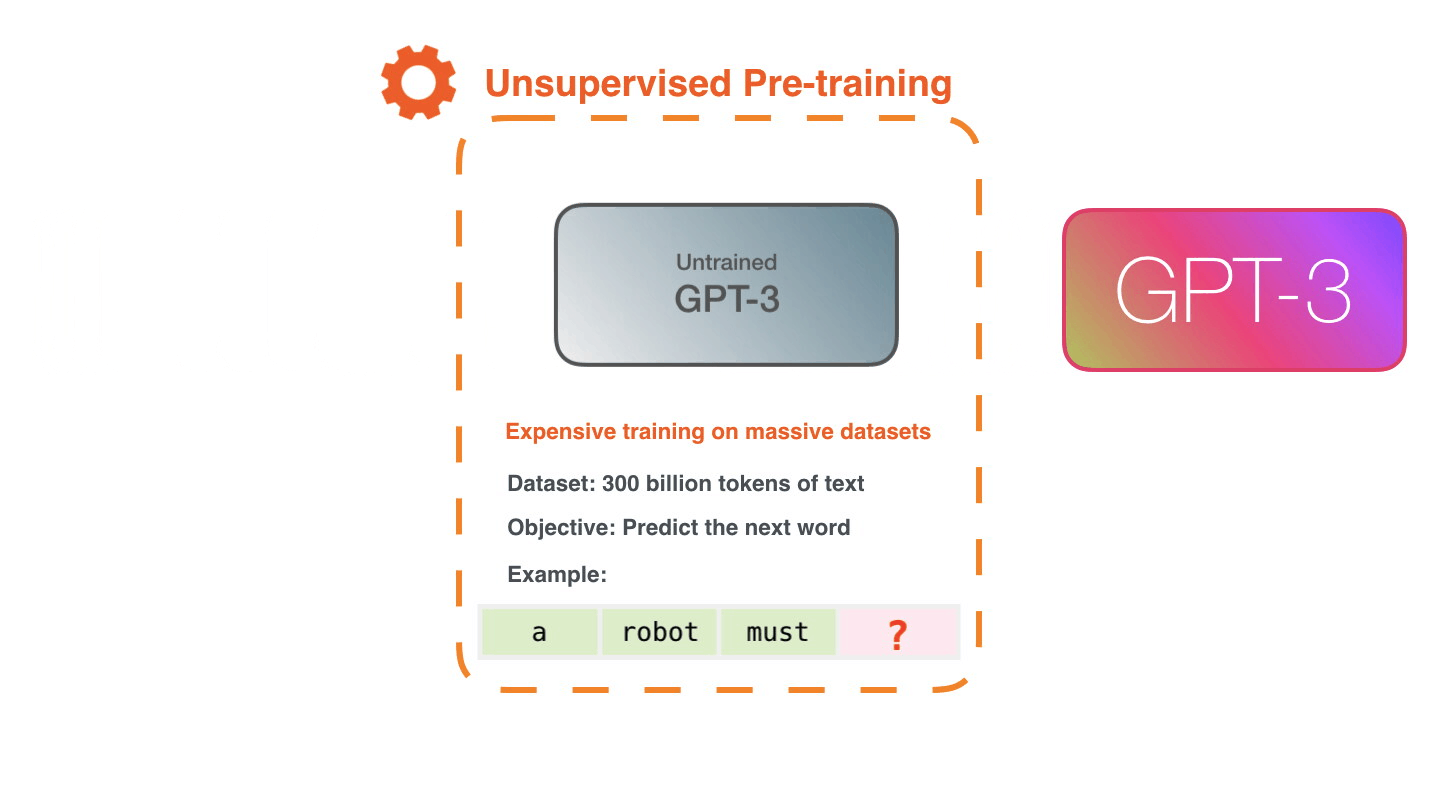
3,000億のテキストトークンのデータセットを使用して、モデルをトレーニングするための例を生成しました。たとえば、これは上記の1つの文から派生した3つのトレーニング例のように見えます。
, , .
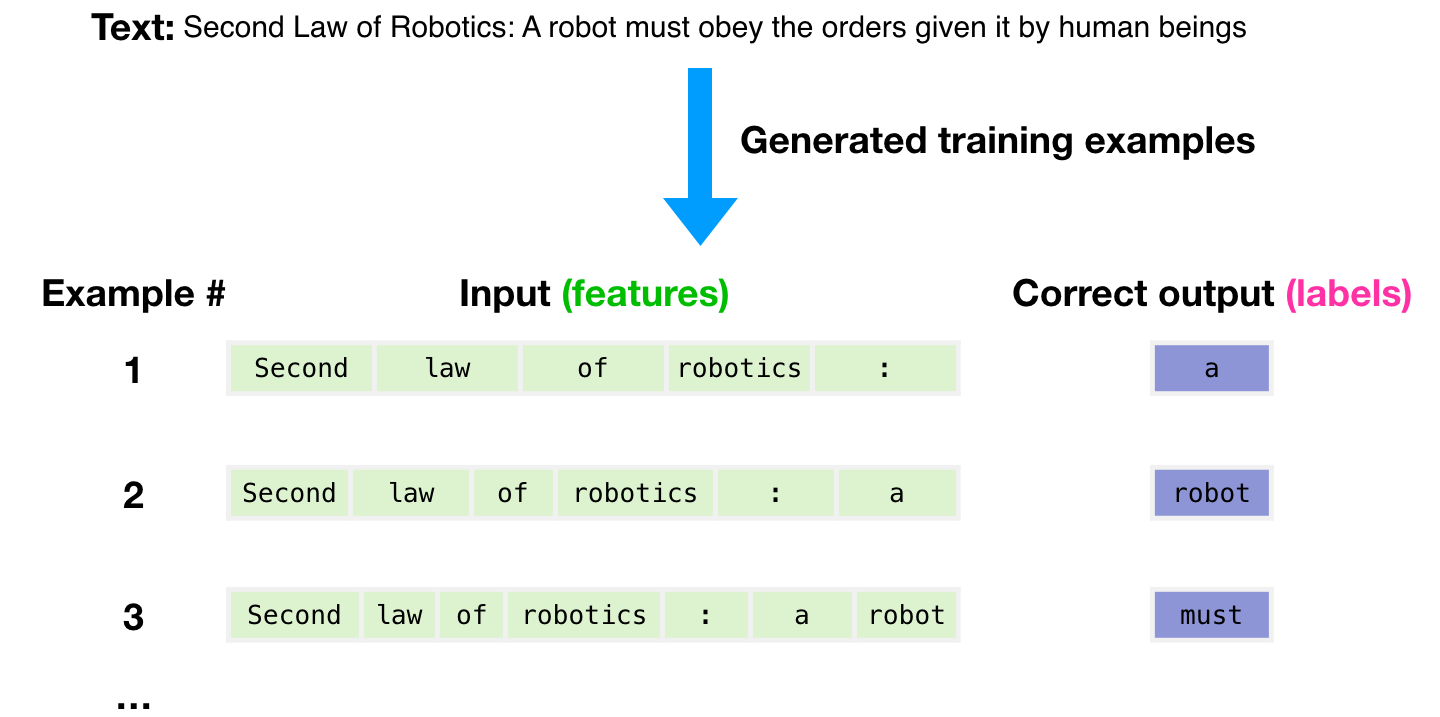
( ) .
. , .
.

.
GPT-3 ( , – ).

GPT-3 . , , 175 ( ). .
, , .
– , – , .
« Youtube» – 175- .
, , .
GPT-3 2048 – « », 2048 , .
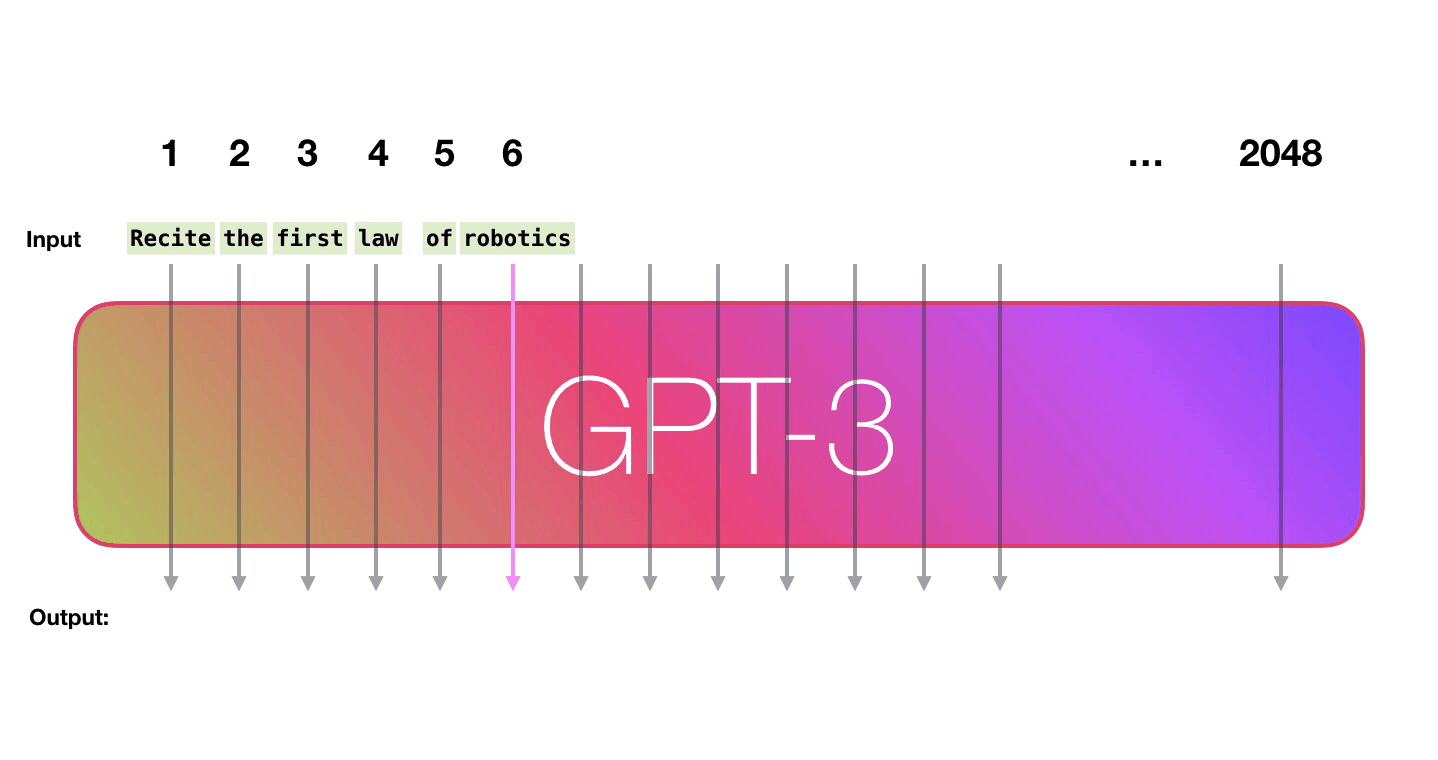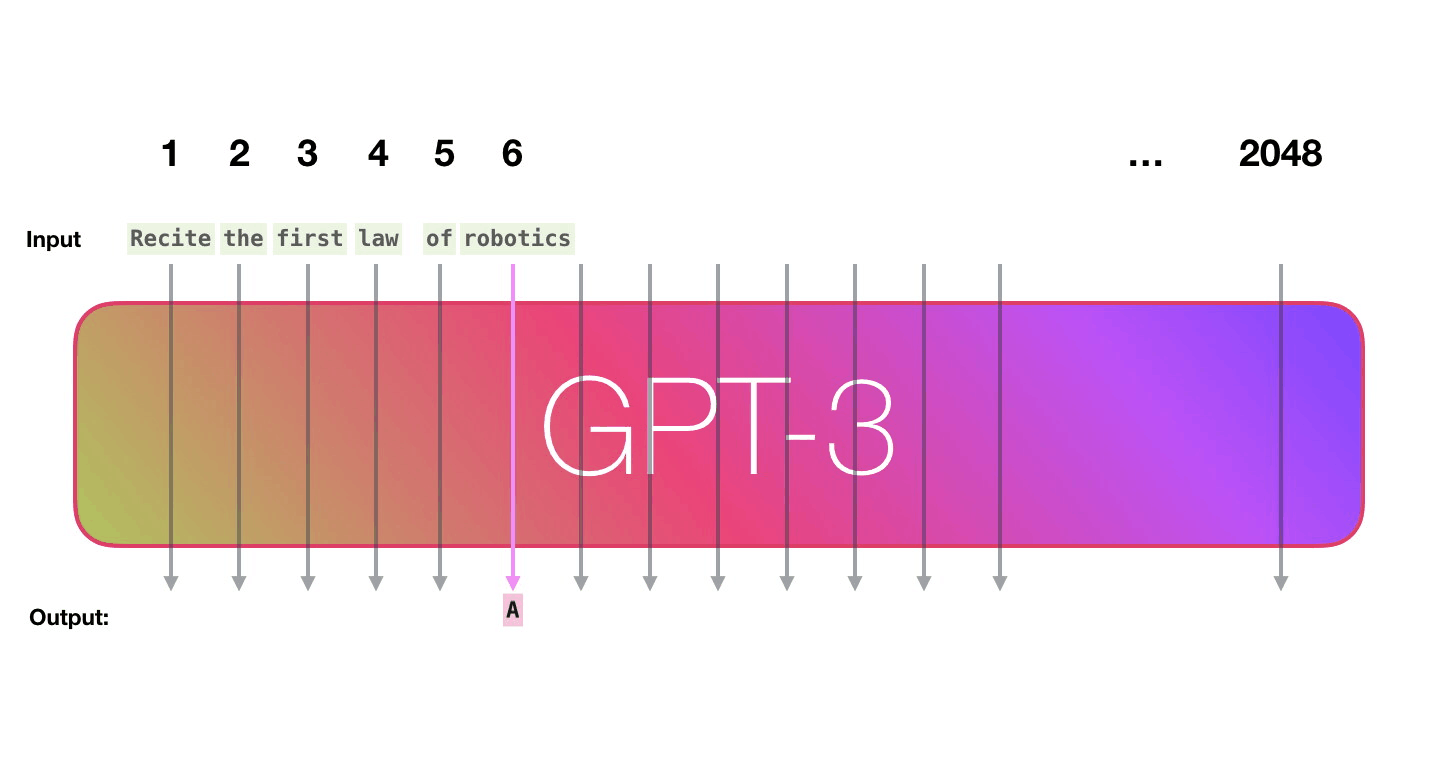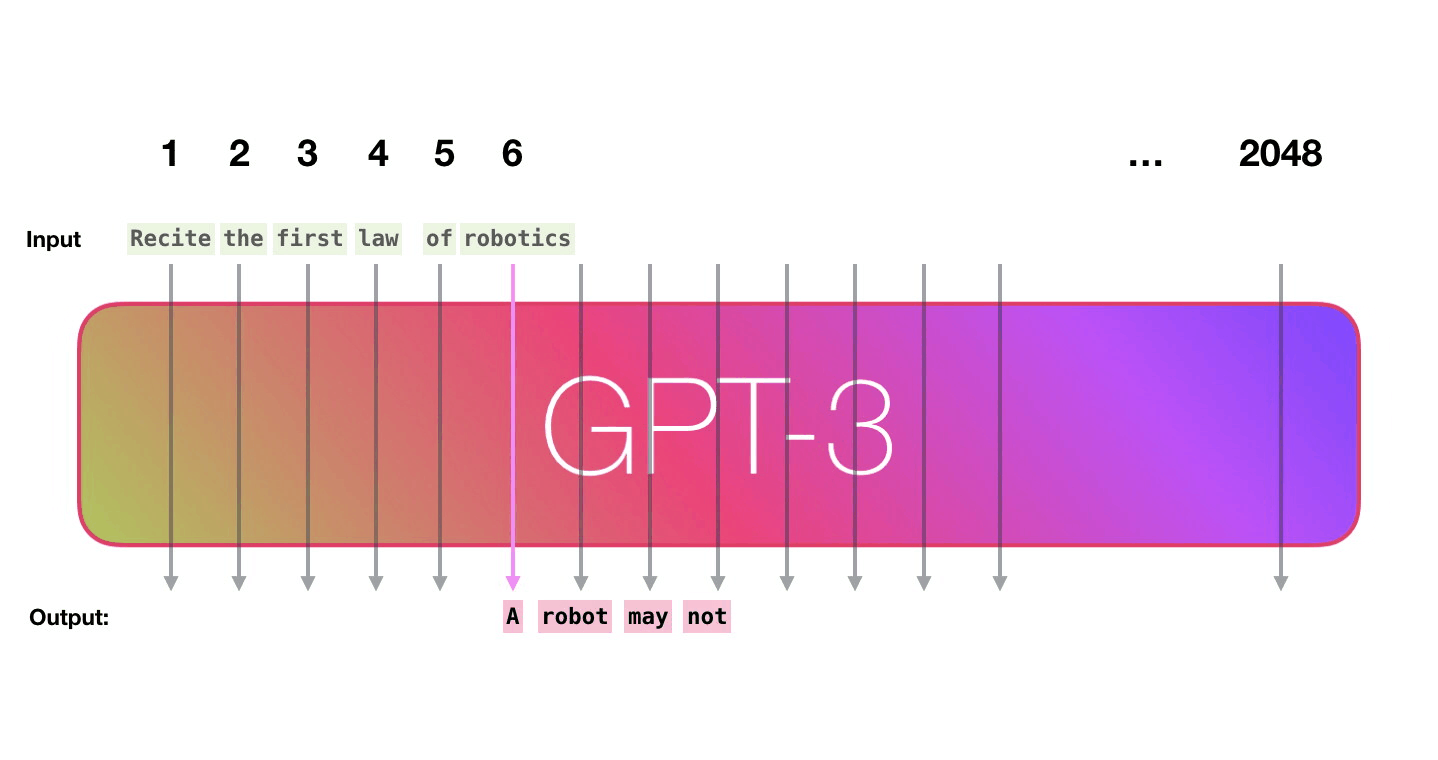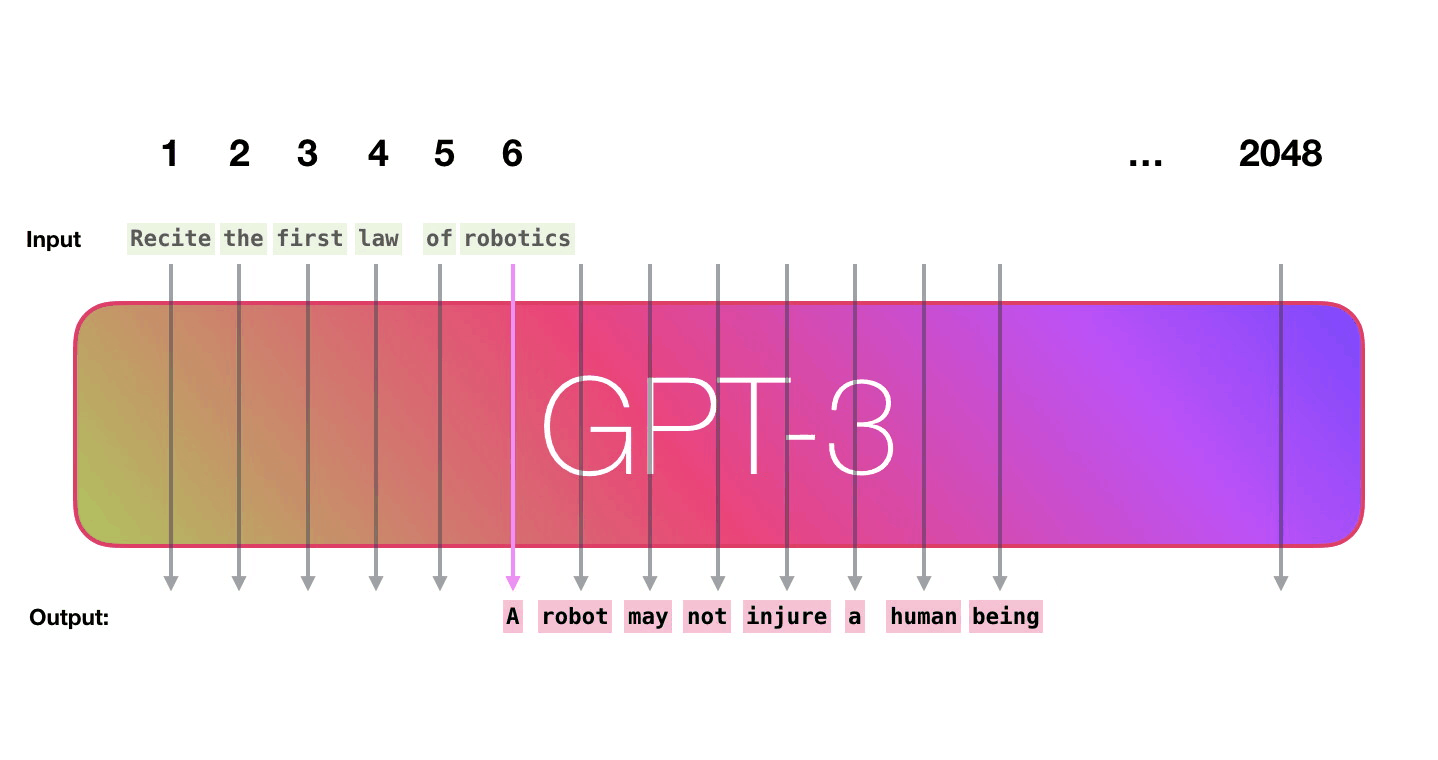
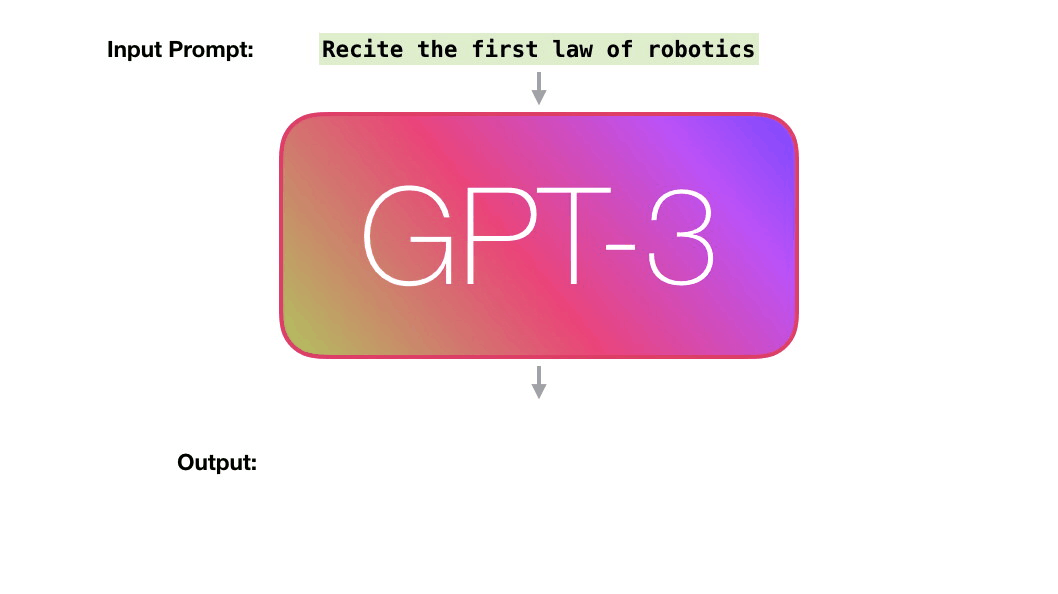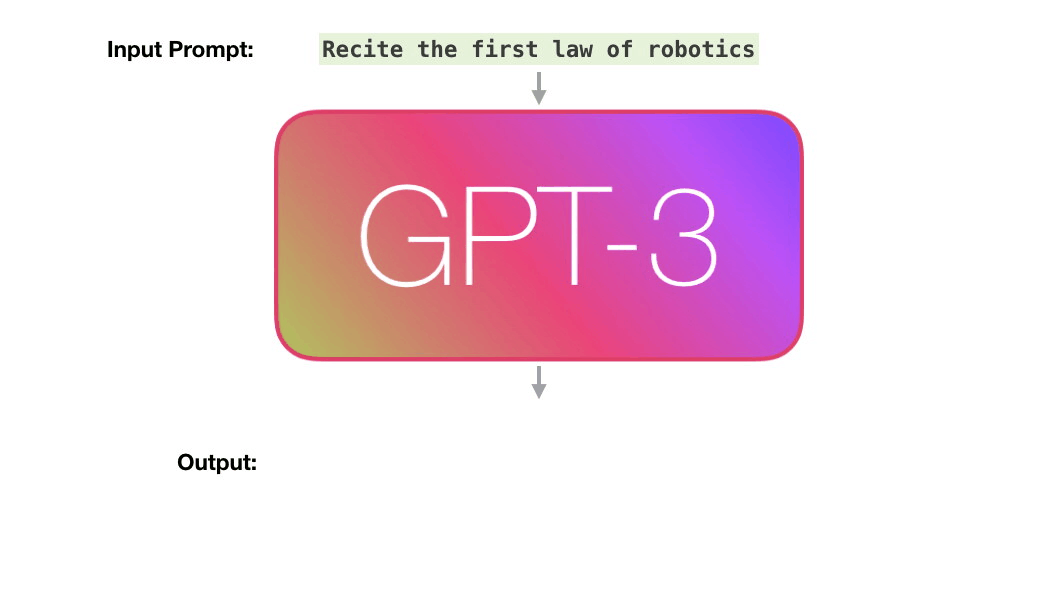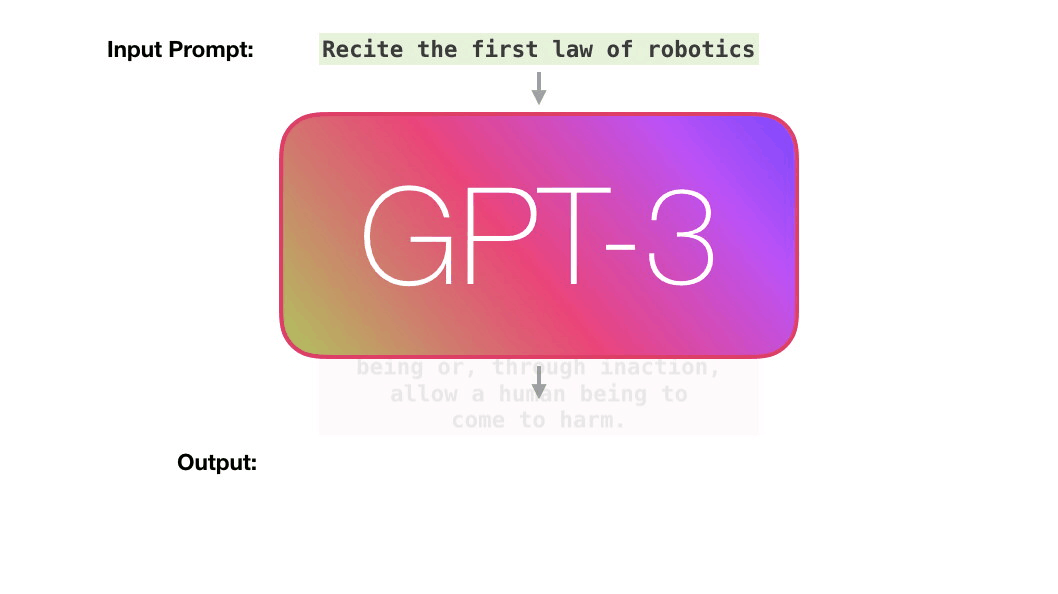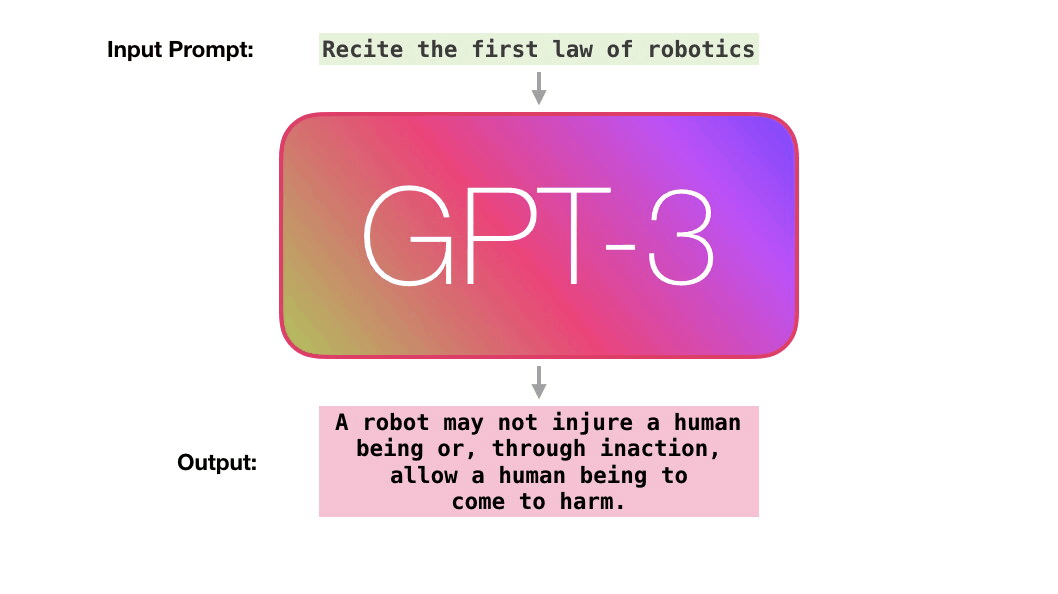
. «robotics» «A»?
:
- ( ).
- .
- .
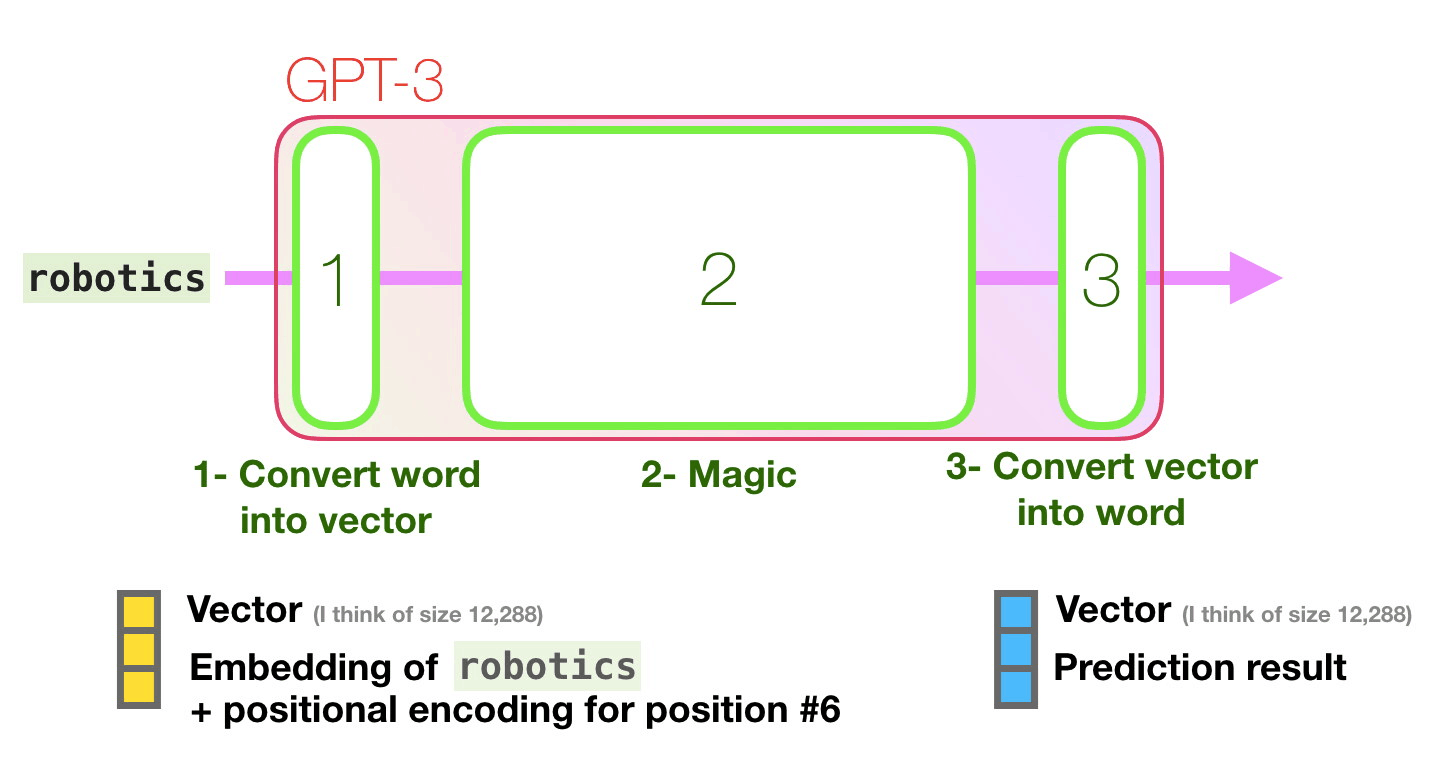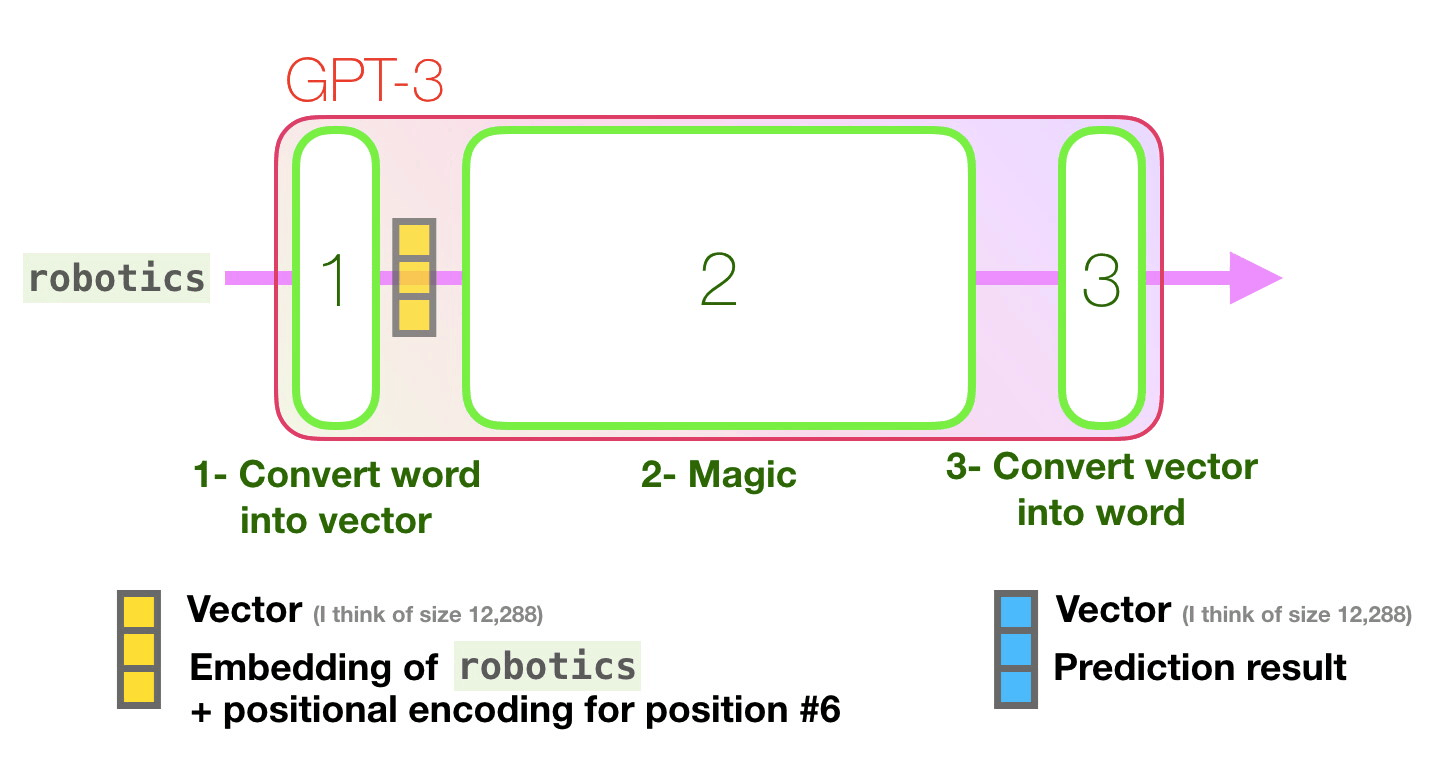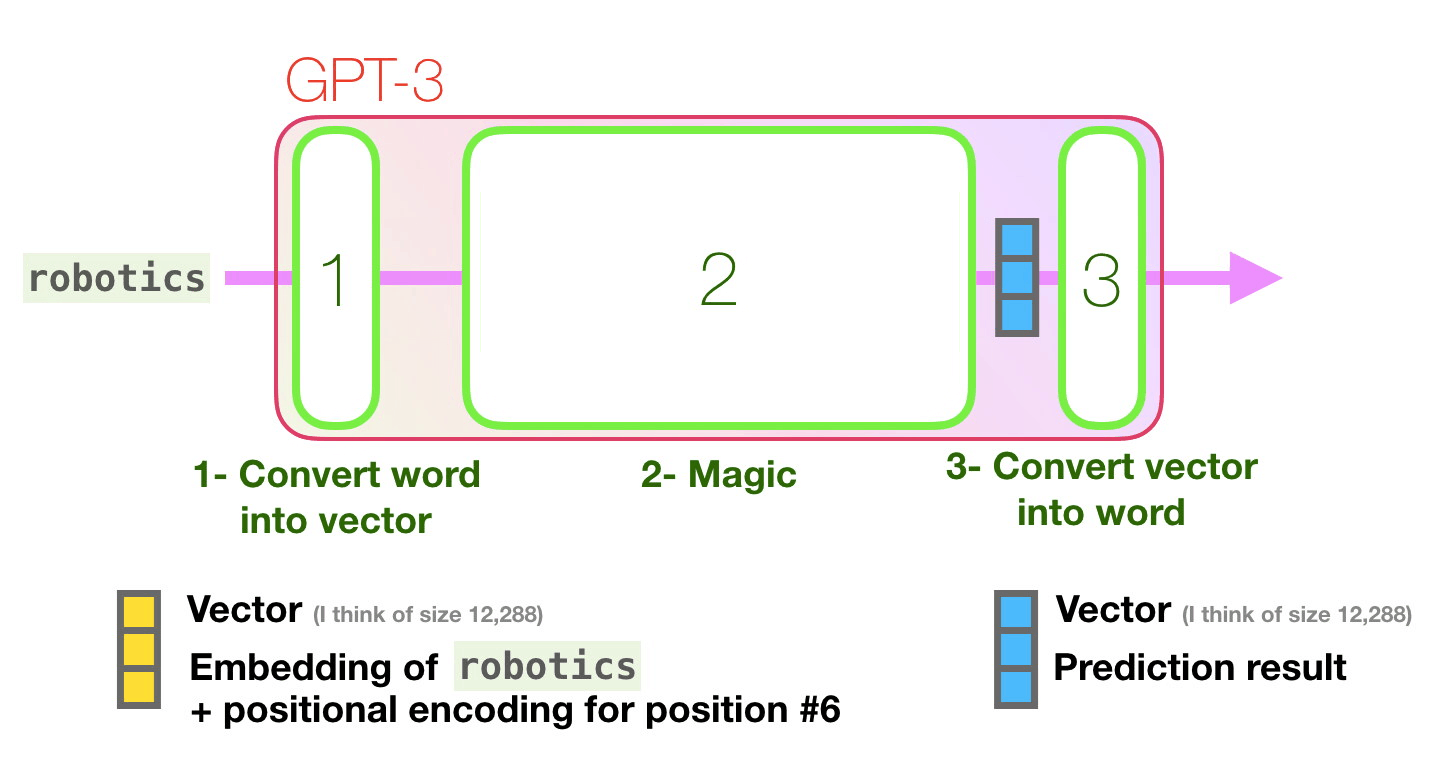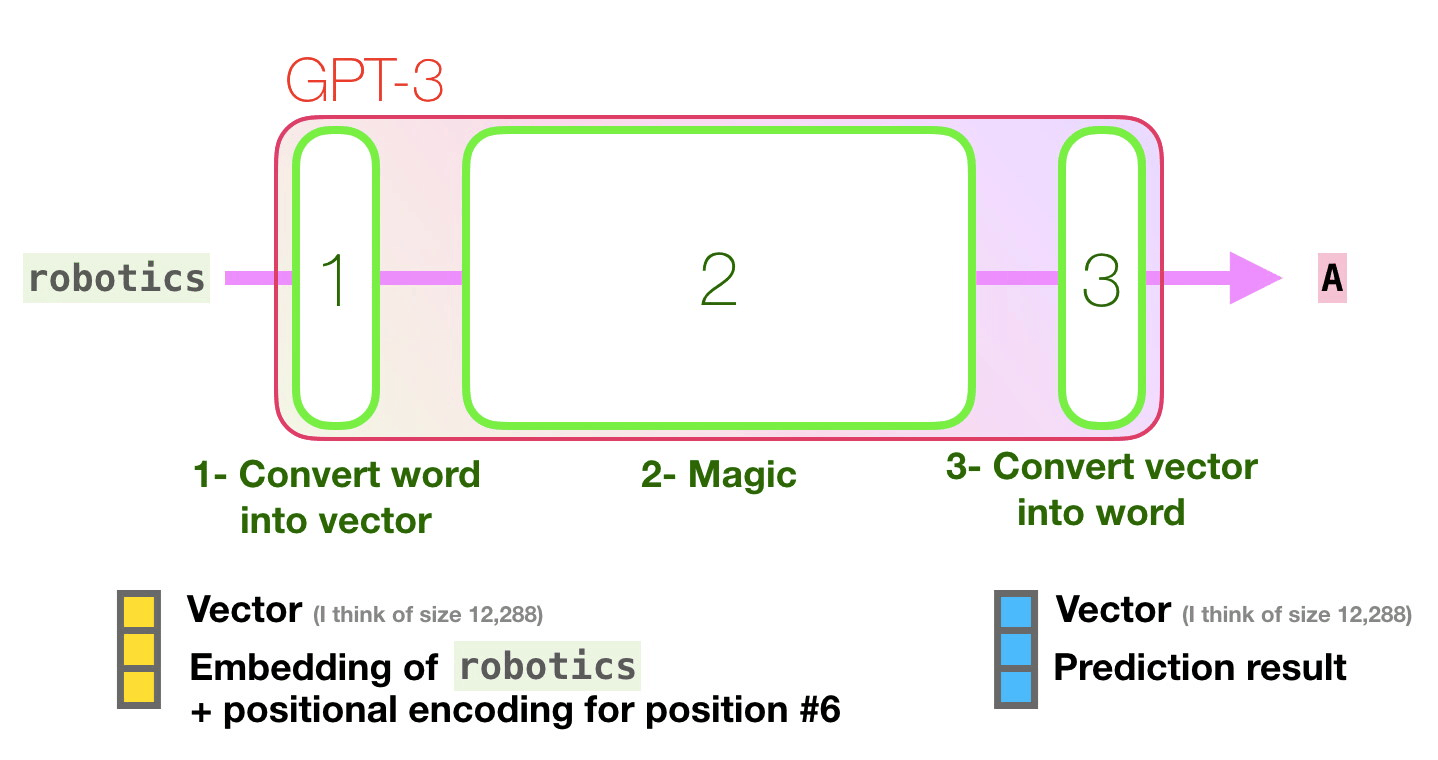
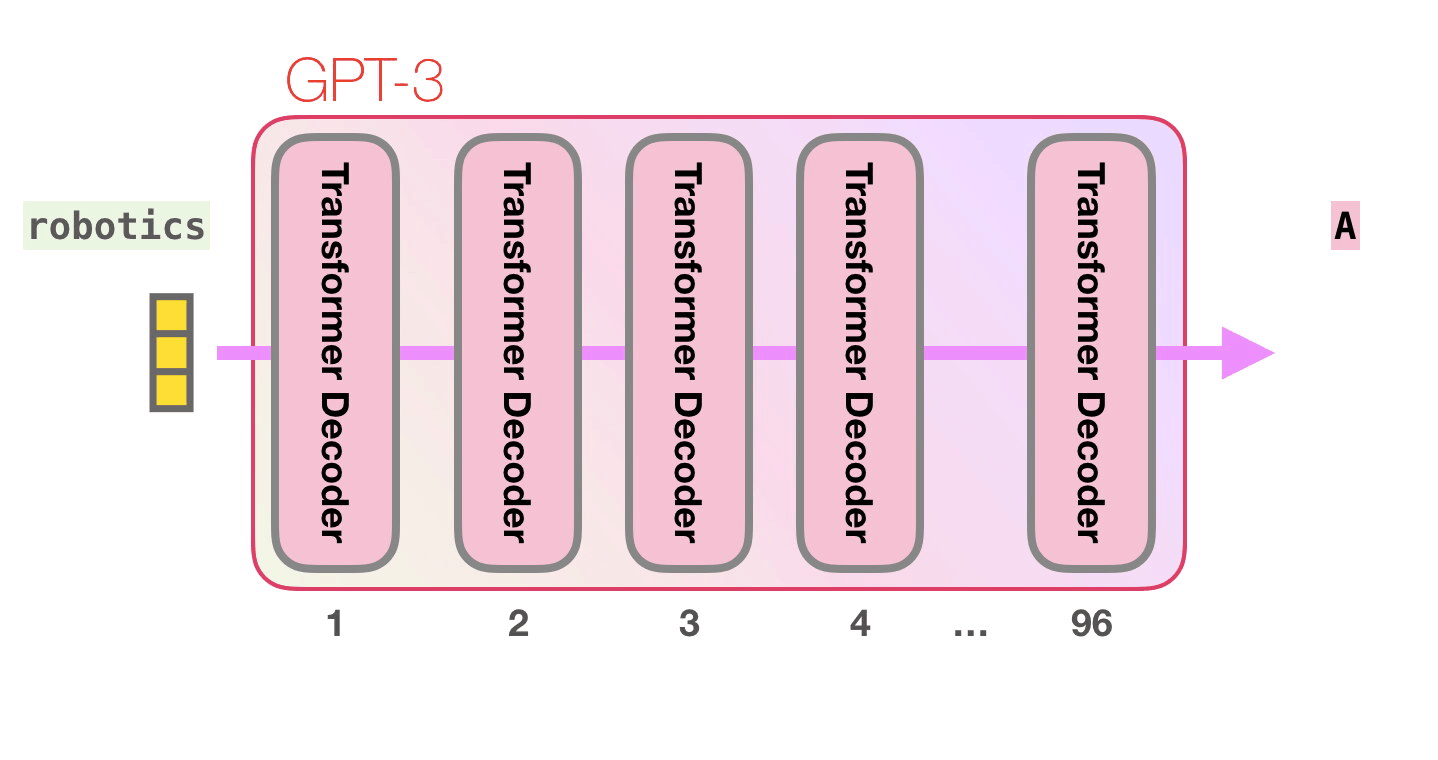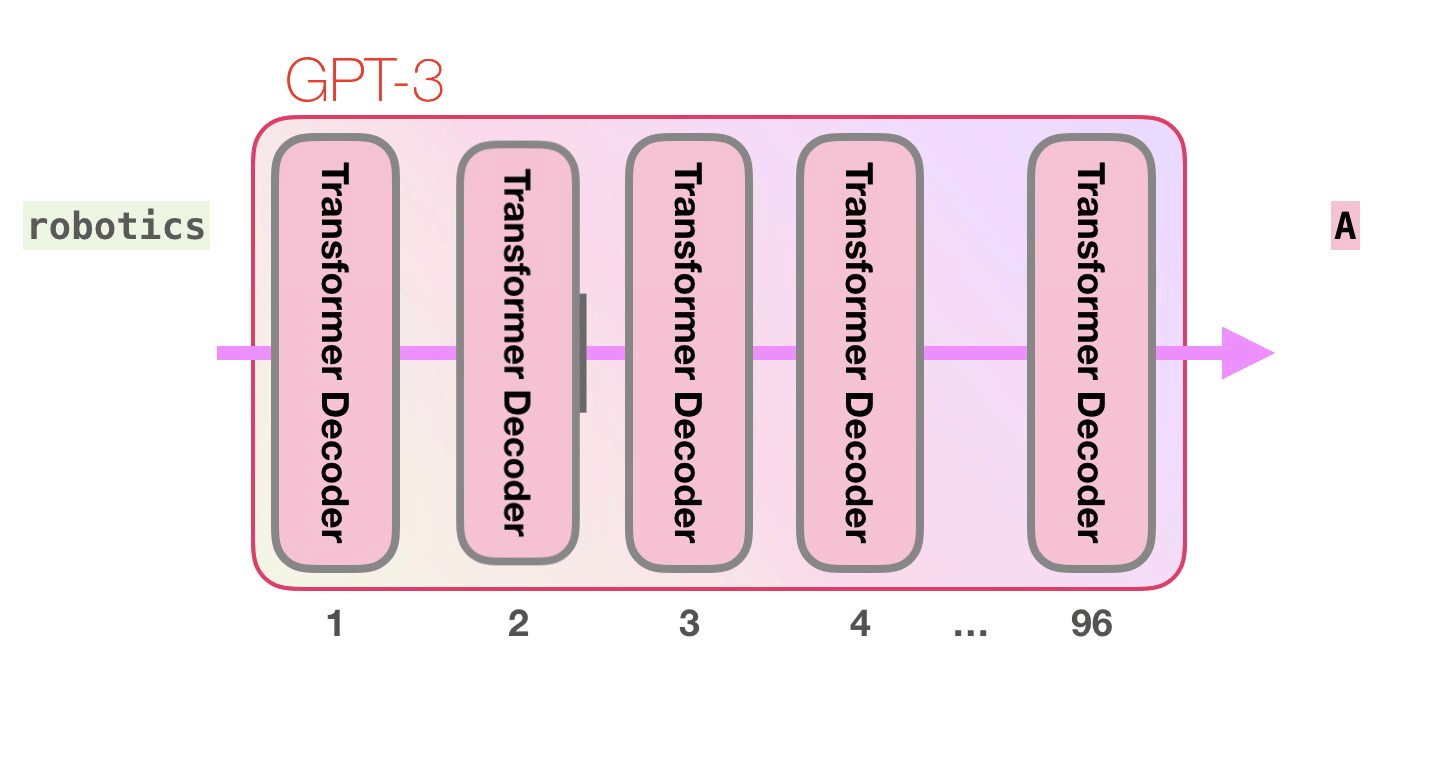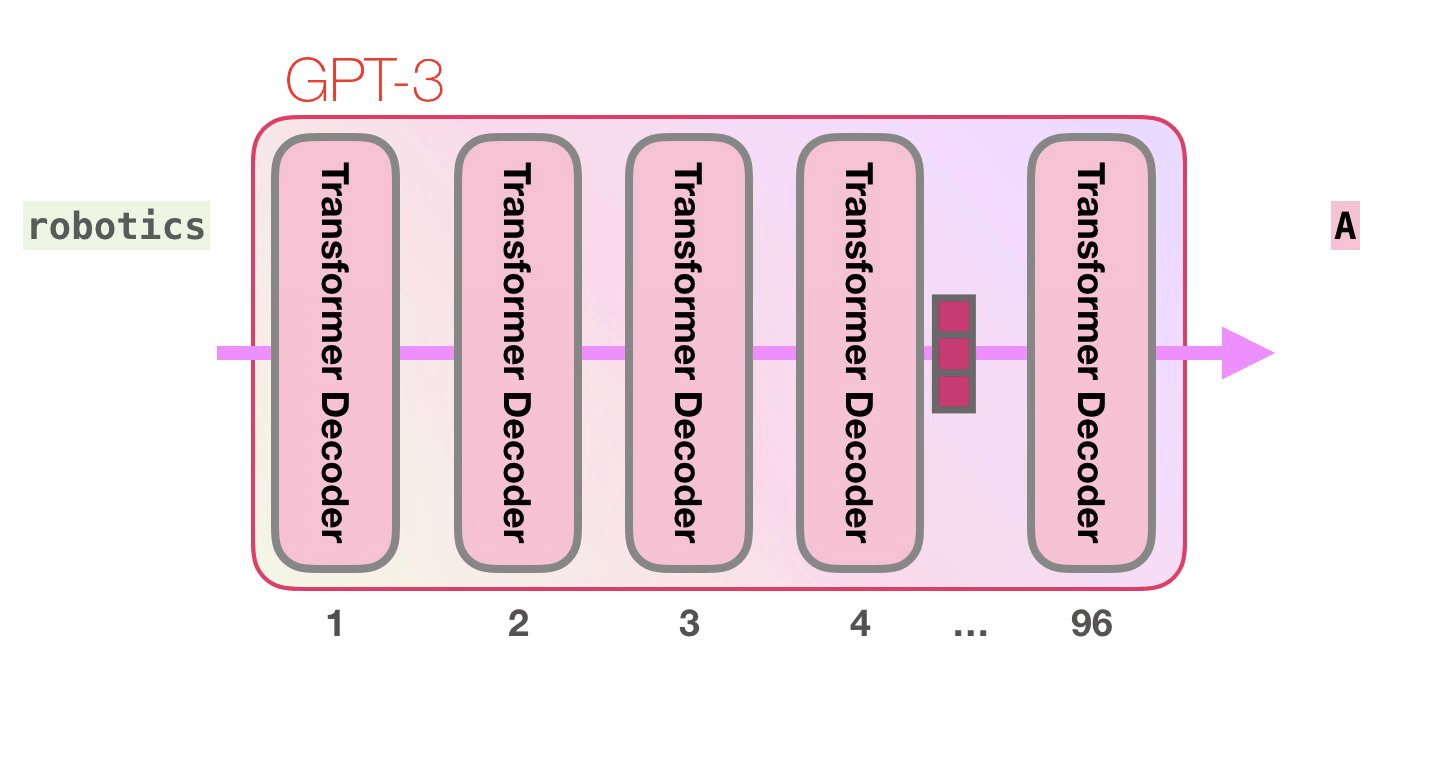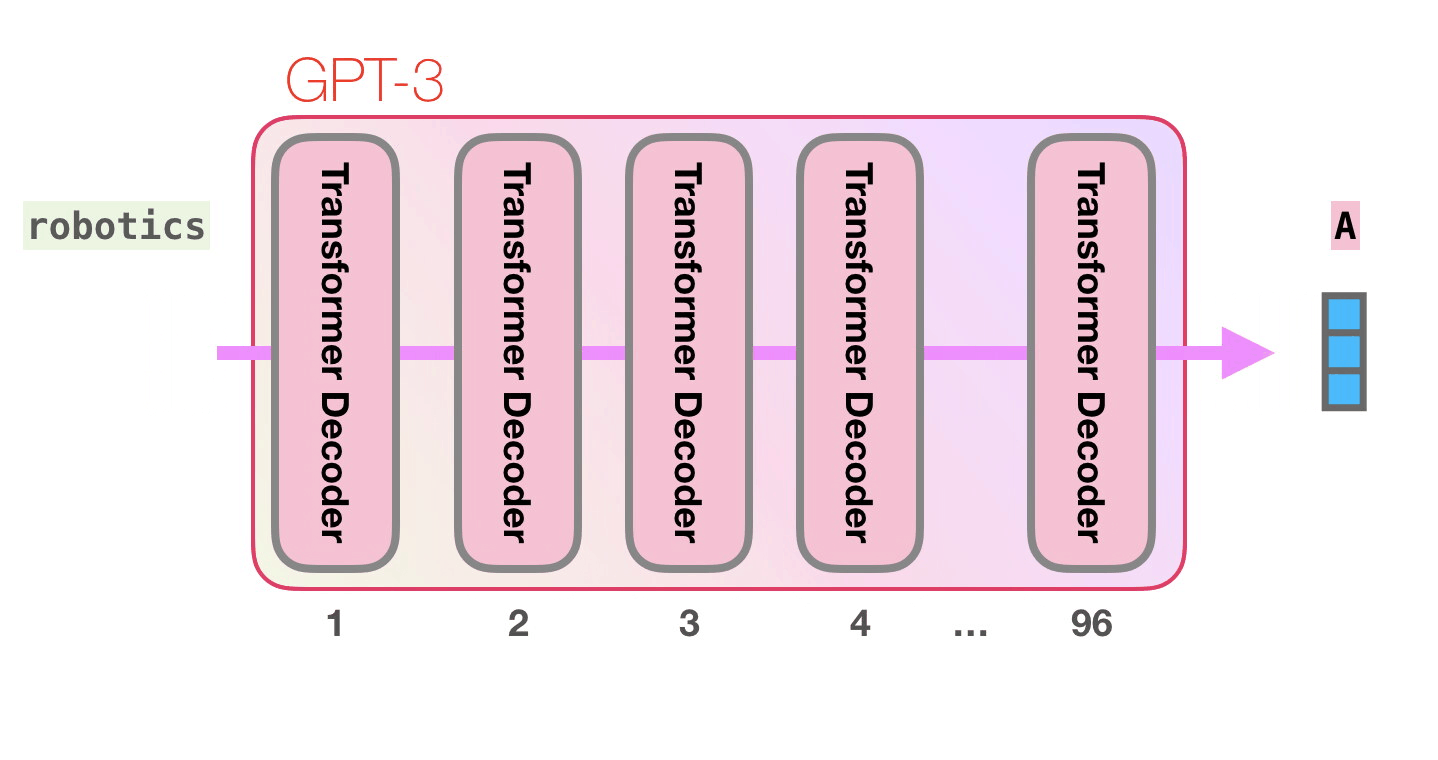
GPT-3 96 .
? «» « » (deep learning).
1.8 . «». :
, , GTP-2 .
GPT-3 (dense) (sparse) (self-attention).
«Okay human» GPT-3. , . : , . .
React ( ), , => . React , , .
最初の例と説明が、例を結果から分離する特別なトークンとともにモデルの入力に追加されたと想定できます。

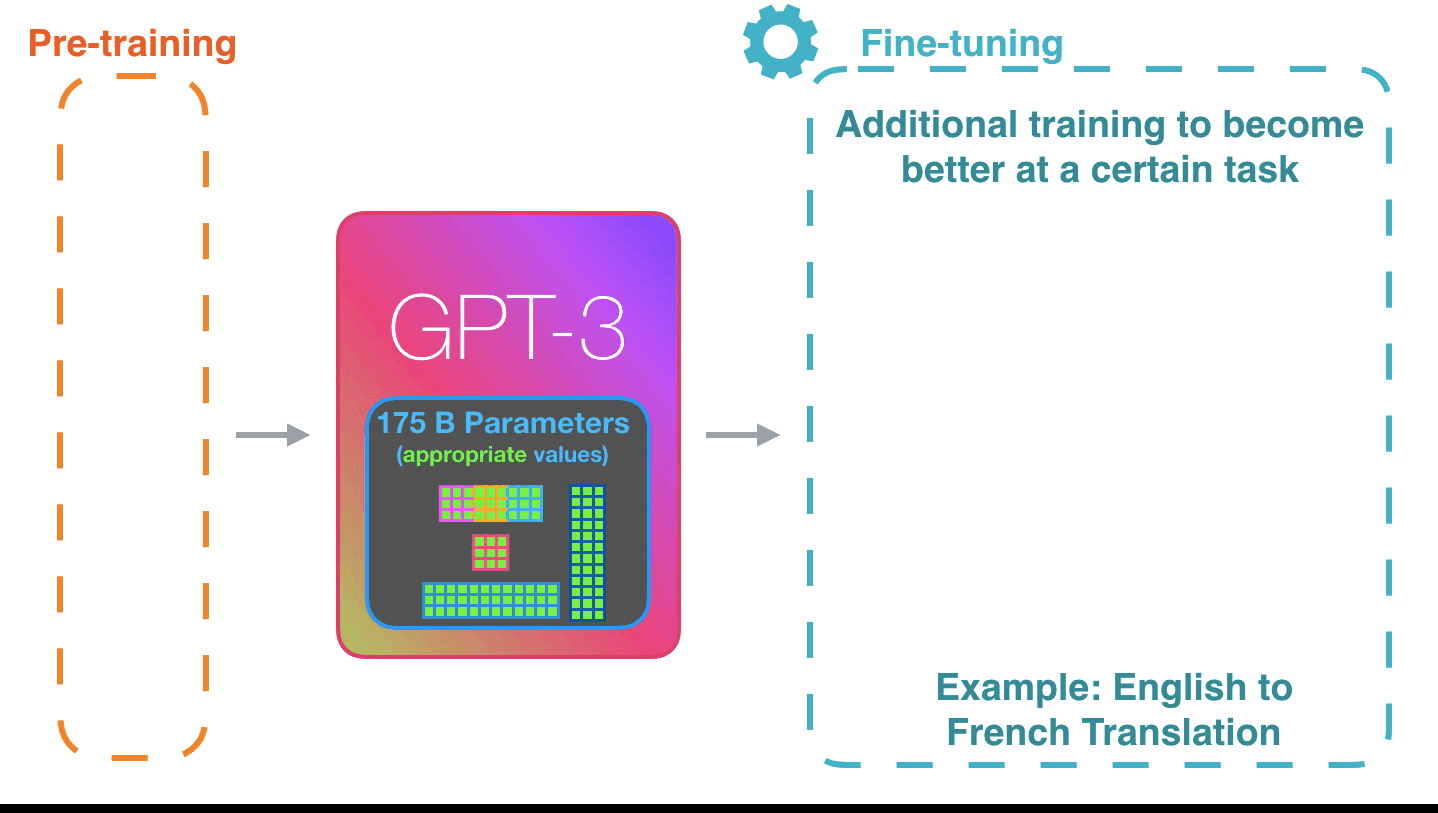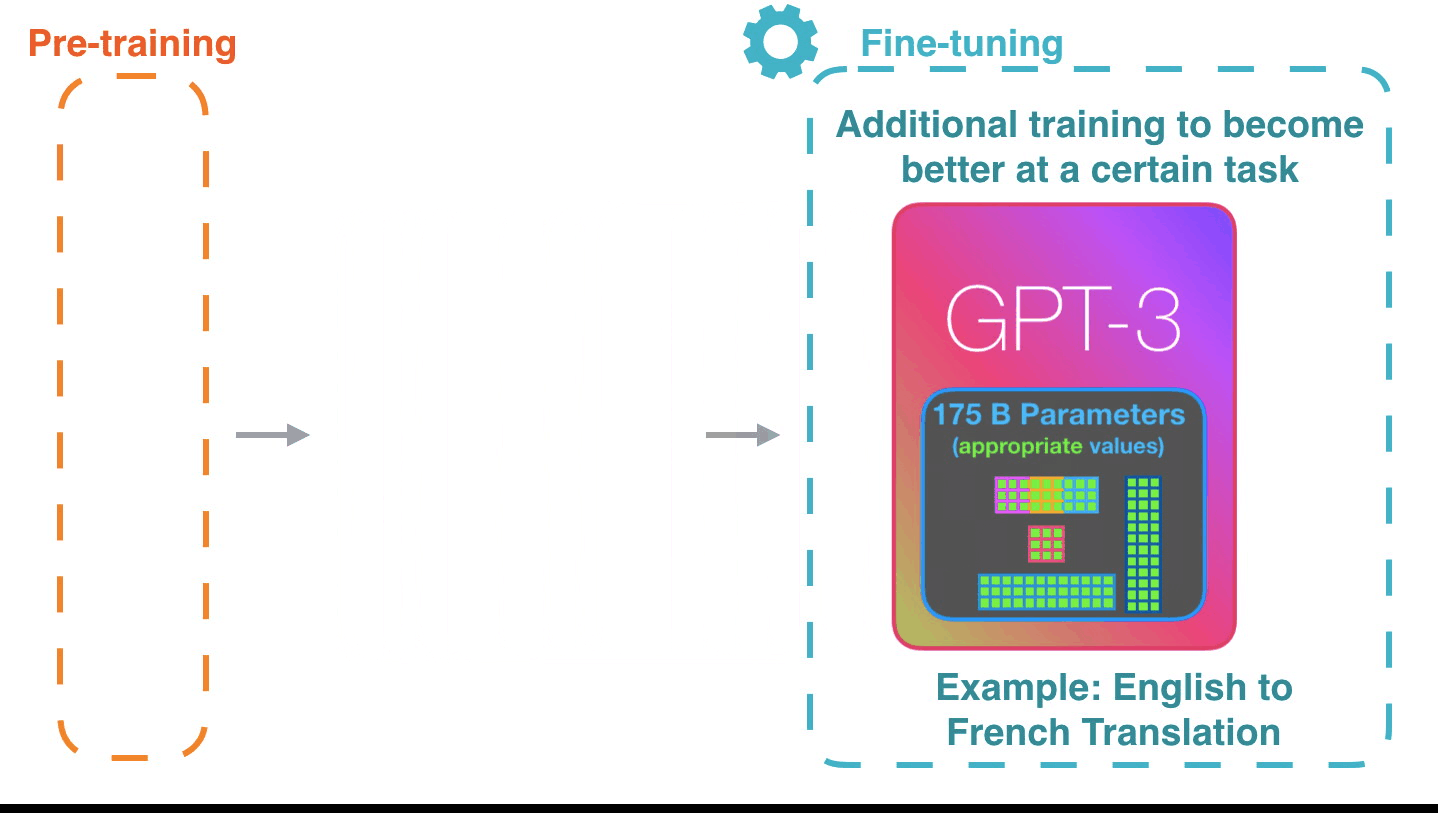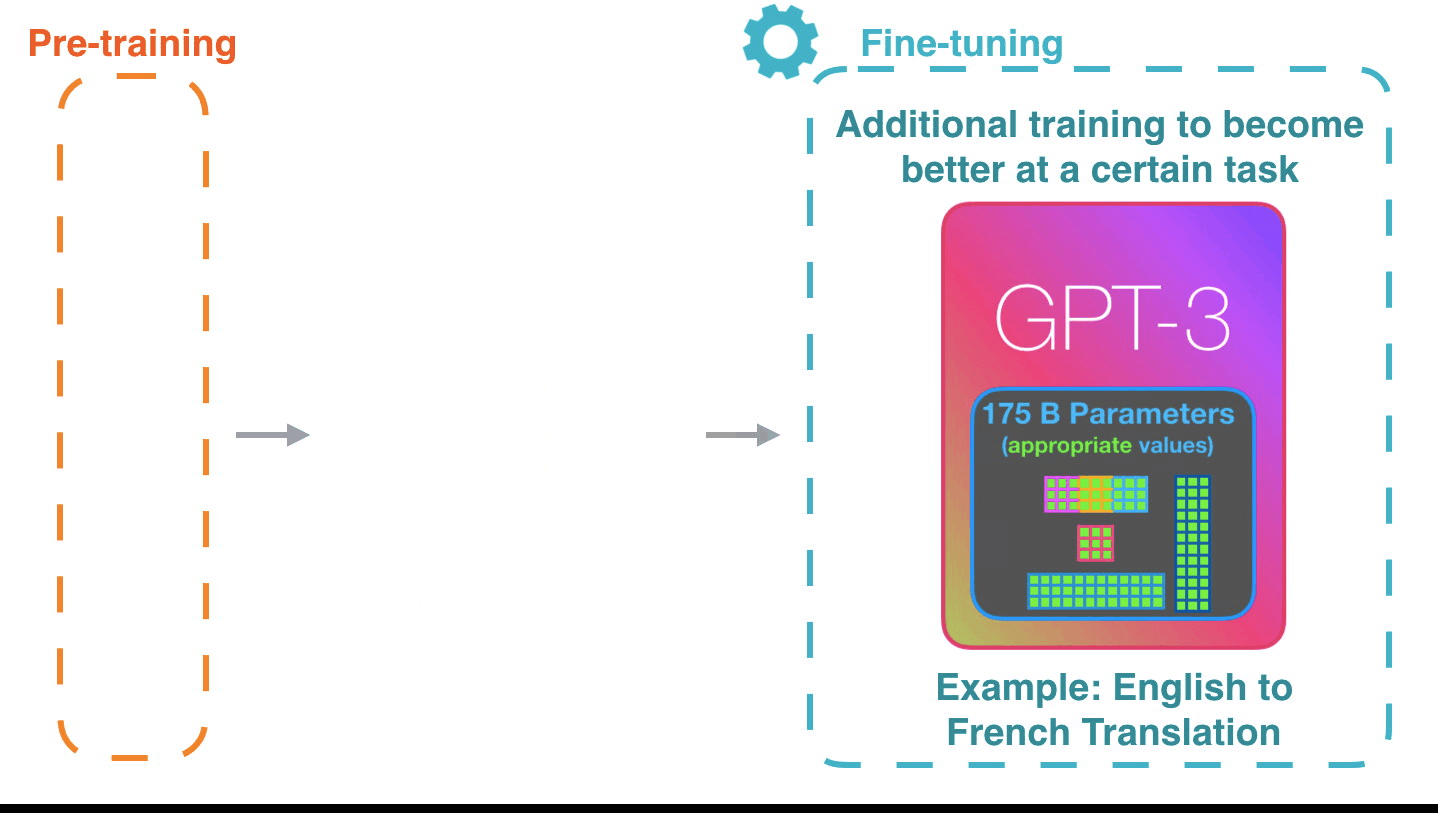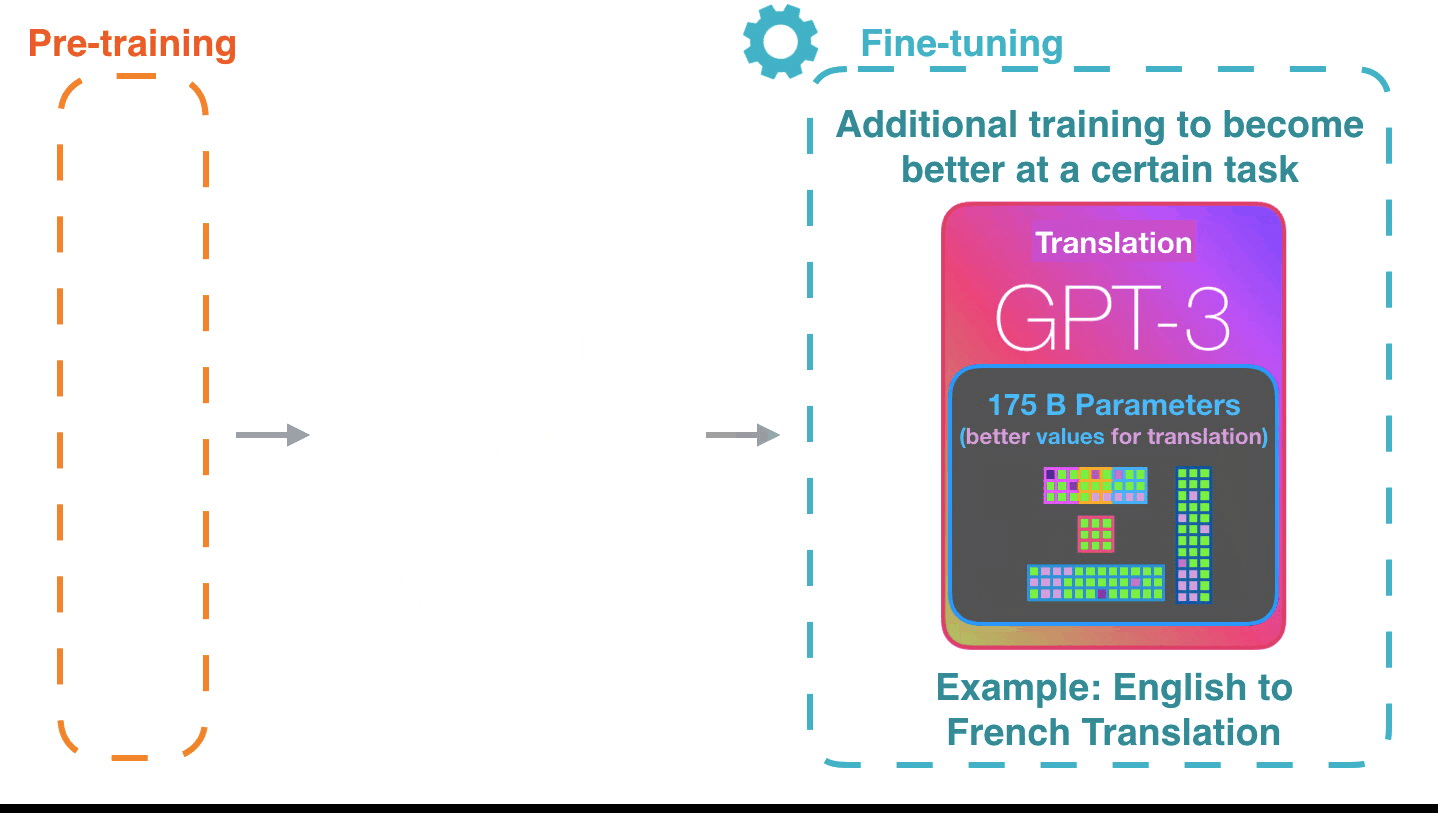
それが機能する方法は印象的です。GPT-3の微調整が完了するのを待つ必要があります。そして、その可能性はさらに驚くべきものになるでしょう。
微調整は、特定のタスクのパフォーマンスを向上させるために、モデルの重みを更新するだけです。
著者
- 原作-ジェイAlammar
- 翻訳-エカテリーナスミルノワ
- 編集とレイアウト-セルゲイShkarin