
音声検査のタスクの1つは、オーディオ録音の信頼性と信頼性を確立することです。つまり、録音の編集、歪み、および変更の兆候を特定することです。記録の信憑性を確立するために、つまり記録に影響が及ばなかったと判断するために、それを実施するという任務がありました。しかし、何千、さらには何十万ものオーディオ録音を分析する方法は?
AIメソッドは、NewTechAuditWebサイトの記事「PROCESSINGAUDIOWITH FFMPEG 」で説明した、オーディオを操作するためのユーティリティと同様に、私たちの助けになります。
オーディオの変化はどのように表示されますか?変更されたファイルと変更されていないファイルをどのように区別できますか?
そのような兆候はいくつかありますが、最も簡単なのは、ファイルの編集に関する情報を特定し、その変更日を分析することです。これらのメソッドはOS自体を使用して簡単に実装できるため、これらのメソッドについては詳しく説明しません。ただし、編集に関する情報を非表示または変更できる資格のあるユーザーが変更を加えることができます。その場合、次のように、より複雑な方法が使用されます。
- 輪郭のシフト;
- 録音されたオーディオのスペクトルプロファイルを変更する。
- 一時停止の出現;
- と他の多く。
そして、これらの複雑な響きの方法はすべて、特別に訓練された専門家によって実行されます-Praat、Speech Analyzer SIL、ELANなどの特殊なソフトウェアを使用する音声鏡技師。
専門家は、スペクトルプロファイルを使用して、つまりそのケプストラル係数を分析することにより、オーディオを分析します。専門家の経験を生かし、同時に既製のコードを使用して、タスクに適合させます。
それで、行うことができる多くの変更があります、どのように選択しますか?
オーディオファイルに加えることができる可能な変更の種類のうち、オーディオからパーツを切り取るか、パーツを切り取ってから元のパーツを同じ期間のピースに置き換えることに関心があります。いわゆるカット/コピーの変更です。ノイズリダクションの観点からファイルを編集したり、トーン周波数を変更したりすることは、情報を隠すリスクを伴いません。
そして、これらの同じカット/コピーをどのように識別しますか?それらは何かと比較されるべきですか?
それは非常に簡単です-FFmpegユーティリティの助けを借りて、ファイルからランダムな期間の一部を切り取り、ランダムな場所で、元のファイルと「切り取った」ファイルの小さな脳のスペクトログラムを比較します。
それらを表示するコード:
import numpy as np
import librosa
import librosa.display
import matplotlib.pyplot as plt
def make_spek(audio):
n_fft = 2048
y, sr = librosa.load(audio)
ft = np.abs(librosa.stft(y[:n_fft], hop_length = n_fft+1))
spec = np.abs(librosa.stft(y, hop_length=512))
spec = librosa.amplitude_to_db(spec, ref=np.max)
mel_spect = librosa.feature.melspectrogram(y=y, sr=sr, n_fft=2048, hop_length=1024)
mel_spect = librosa.power_to_db(mel_spect, ref=np.max)
librosa.display.specshow(mel_spect, y_axis='mel', fmax=8000, x_axis='time');
plt.title('Mel Spectrogram');
plt.colorbar(format='%+2.0f dB');
plt.show();
make_spek('./audio/original.wav')# './audio/original.wav' ソースからデータセットを準備し、FFmpegユーティリティコマンドを使用してファイルを切り取ります。
ffmpeg -i oroginal.wav -ss STARTTIME -to ENDTIME -acodec copy cut.wav ここで、STARTTIMEとENDTIMEは、カットフラグメントの開始と終了です。そして、コマンドを使用して:
ffmpeg -iconcat:"part_0.wav|part_1.wav |part_2.wav" -codeccopyconcat.wavファイルの一部を結合して、part_1.wavを元の部分と挿入します(FFmpegコマンドをpythonでラップする方法については、FFmpegに関する記事を参照してください)。
:ここでは、元のファイルは、0.2から2.5秒のオーディオのカットアウト、および0.2から2.5秒のオーディオのカットアウトした後、このオーディオファイルの同様の期間のオーディオ断片に挿入されたファイルのチョークスペクトログラムされているの-スペクトログラムチョークされている
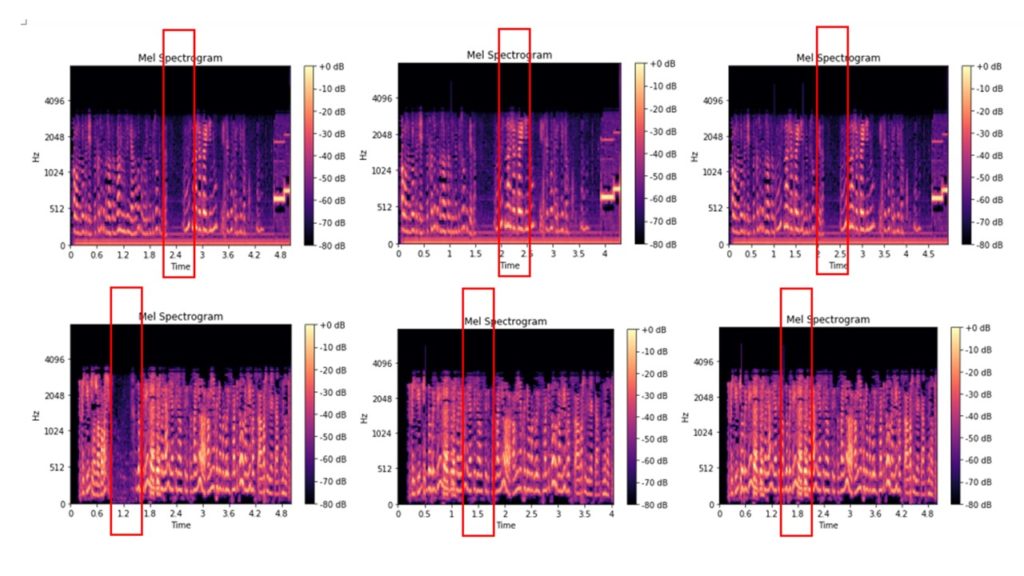
いくつかの画像は視覚的にも区別でき、他の画像はほとんど同じに見えます。結果の画像をフォルダに配布し、画像分類のモデルをトレーニングするための入力データとして使用します。フォルダー構造:
model.py #
/input/train/original/ #
/input/train/cut_copy/ # 私たちにとって、変更されたオーディオファイルが追加されたか短縮されたかは関係ありません。すべての結果を良いもの、つまり変更のないファイルと悪いものに分けます。したがって、バイナリ分類の古典的な問題を解決します。ニューラルネットワークを使用して分類し、Kerasパッケージの操作例から既製のニューラルネットワークを操作するためのコードを取得します。
#
from keras.models import Sequential
from keras.layers import Flatten
from keras.layers import Dense
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
#
classifier = Sequential()
classifier.add(Conv2D(32, (3, 3), input_shape = (64, 64, 3), activation = 'relu'))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Conv2D(32, (3, 3), activation = 'relu'))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Flatten())
classifier.add(Dense(units = 128, activation = 'relu'))
classifier.add(Dense(units = 1, activation = 'sigmoid'))
classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
#
from keras.preprocessing.image import ImageDataGenerator as img
train_datagen = img(rescale = 1./255,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True)
test_datagen = img(rescale = 1./255)
training_set = train_datagen.flow_from_directory('input/train',
target_size = (64, 64),
batch_size = 32,
class_mode = 'binary')
test_set = test_datagen.flow_from_directory('input/test',
target_size = (64, 64),
batch_size = 32,
class_mode = 'binary')
classifier.fit_generator(
training_set,
steps_per_epoch = 8000,
epochs = 25,
validation_data = test_set,
validation_steps = 2000)さらに、モデルがトレーニングされた後、私たちはその助けを借りて分類を実行します
import numpy as np
from keras.preprocessing import image
test_image = image.load_img('dataset/prediction/original_or_corrupt.jpg', target_size = (64, 64))
test_image = image.img_to_array(test_image)
test_image = np.expand_dims(test_image, axis = 0)
result = classifier.predict(test_image)
training_set.class_indices
ifresult[0][0] == 1:
prediction = 'original'
else:
prediction = 'corrupt'出力では、オーディオファイルの分類-'original '/' corrupt 'を取得します。変更されていないファイルと変更が加えられたファイル。
複雑な外観の処理を簡単に実行できることをもう一度証明しました。AIメソッドの最も難しいメカニズムではなく、既製のソリューションを使用し、オーディオの変更を確認しました。さて、私たちは探偵の専門家でした。