私はDependencyInjectorの作成者です。これは、Pythonの依存関係注入フレームワークです。
これは、DependencyInjectorを使用してアプリケーションを構築するための最も信頼のおけるガイドです。過去のチュートリアルでは、構築する方法を網羅フラスコを使用したWebアプリケーション、AiohttpとREST APIを、そしてAsyncioでデーモンを監視依存性の注入を使用しました。
今日は、コンソール(CLI)アプリケーションを構築する方法を示したいと思います。
また、よくある質問への回答を用意し、追記を公開します。
マニュアルは次の部分で構成されています。
完成したプロジェクトはGithubにあります。
開始するには、次のものが必要です。
- Python 3.5+
- 仮想環境
また、依存関係の注入の原理を一般的に理解していることが望ましいです。
何を構築しますか?
映画を探すCLI(コンソール)アプリケーションを構築します。それをMovieListerと呼びましょう。
Movie Listerはどのように機能しますか?
- 映画のデータベースがあります
- 各フィルムについて、次の情報がわかっています。
- 名前
- 発行年
- 監督の名前
- データベースは2つの形式で配布されます。
- Csvファイル
- Sqliteデータベース
- アプリケーションは、次の基準を使用してデータベースを検索します。
- 監督の名前
- 発行年
- 他のデータベース形式は将来追加される可能性があります
Movie Listerは、依存関係の挿入と制御の反転に関するMartinFowlerの記事で使用されているサンプルアプリケーションです。
MovieListerアプリケーションのクラス図は
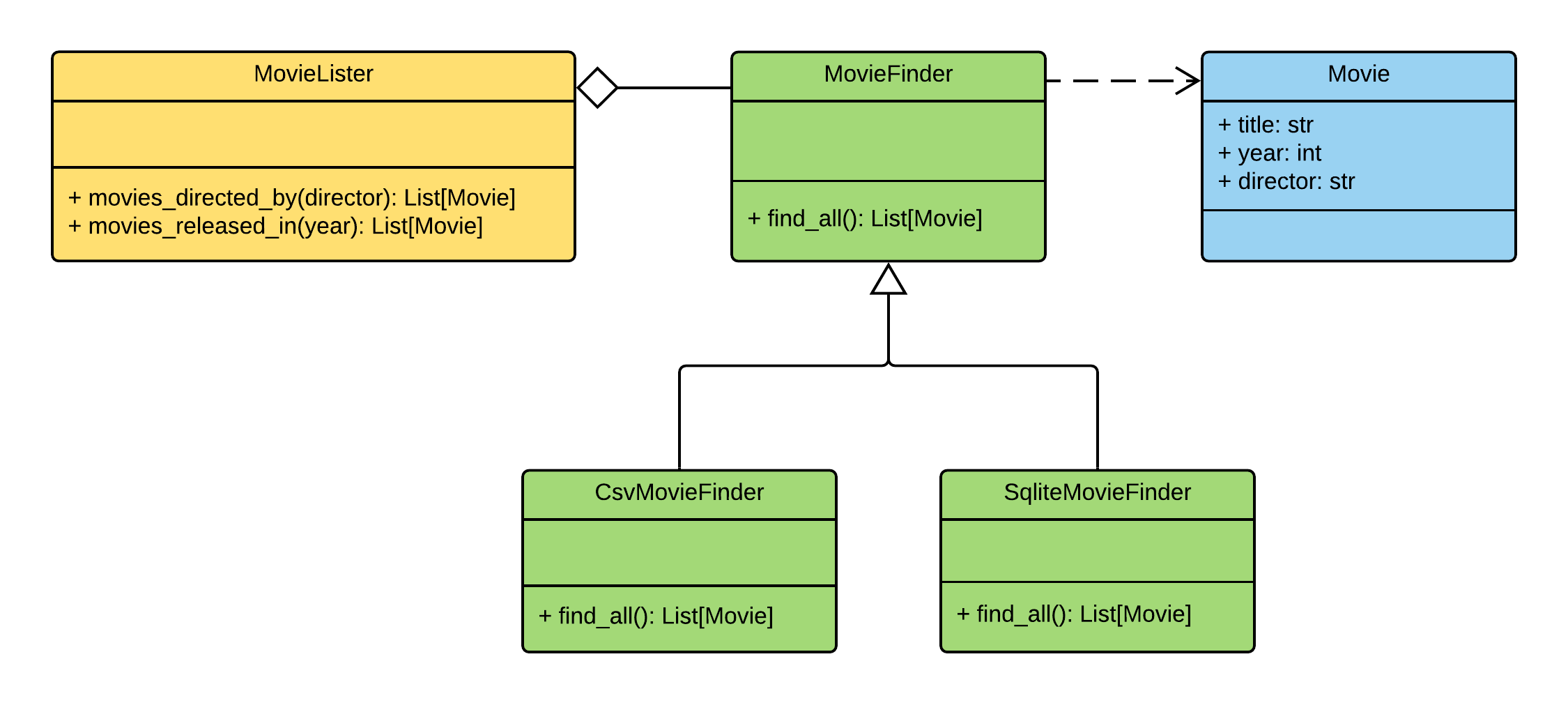
次のようになります。クラス間の責任は次のように分散されます。
MovieLister-検索を担当MovieFinder-データベースからデータを抽出する責任がありますMovie-エンティティクラス「ムービー」
環境の準備
環境の準備から始めましょう。
まず、プロジェクトフォルダと仮想環境を作成する必要があります。
mkdir movie-lister-tutorial
cd movie-lister-tutorial
python3 -m venv venv
次に、仮想環境をアクティブ化します。
. venv/bin/activate
環境の準備ができています。それでは、プロジェクトの構造に取り掛かりましょう。
プロジェクト構造
このセクションでは、プロジェクトの構造を整理します。
現在のフォルダに次の構造を作成しましょう。今のところ、すべてのファイルを空のままにします。
初期構造:
./
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ └── containers.py
├── venv/
├── config.yml
└── requirements.txt
依存関係のインストール
依存関係をインストールする時が来ました。次のようなパッケージを使用します。
dependency-injector-依存関係注入フレームワークpyyaml-構成の読み取りに使用されるYAMLファイルを解析するためのライブラリpytest-テストフレームワークpytest-cov-テストによってコードカバレッジを測定するためのヘルパーライブラリ
次の行をファイルに追加しましょう
requirements.txt:
dependency-injector
pyyaml
pytest
pytest-cov
そして、ターミナルで実行します。
pip install -r requirements.txt
依存関係のインストールが完了しました。フィクスチャに移ります。
備品
このセクションでは、フィクスチャを追加します。テストデータはフィクスチャと呼ばれます。
テストデータベースを作成するスクリプトを作成します。プロジェクトのルートに
ディレクトリ
data/を追加し、その中にファイルを追加しますfixtures.py。
./
├── data/
│ └── fixtures.py
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ └── containers.py
├── venv/
├── config.yml
└── requirements.txt
次に、編集
fixtures.py:
"""Fixtures module."""
import csv
import sqlite3
import pathlib
SAMPLE_DATA = [
('The Hunger Games: Mockingjay - Part 2', 2015, 'Francis Lawrence'),
('Rogue One: A Star Wars Story', 2016, 'Gareth Edwards'),
('The Jungle Book', 2016, 'Jon Favreau'),
]
FILE = pathlib.Path(__file__)
DIR = FILE.parent
CSV_FILE = DIR / 'movies.csv'
SQLITE_FILE = DIR / 'movies.db'
def create_csv(movies_data, path):
with open(path, 'w') as opened_file:
writer = csv.writer(opened_file)
for row in movies_data:
writer.writerow(row)
def create_sqlite(movies_data, path):
with sqlite3.connect(path) as db:
db.execute(
'CREATE TABLE IF NOT EXISTS movies '
'(title text, year int, director text)'
)
db.execute('DELETE FROM movies')
db.executemany('INSERT INTO movies VALUES (?,?,?)', movies_data)
def main():
create_csv(SAMPLE_DATA, CSV_FILE)
create_sqlite(SAMPLE_DATA, SQLITE_FILE)
print('OK')
if __name__ == '__main__':
main()
それでは、ターミナルで実行してみましょう。
python data/fixtures.py
スクリプトは
OK成功すると出力されます。
私たちは、そのファイルを確認
movies.csvし、movies.dbディレクトリに登場しましたdata/:
./
├── data/
│ ├── fixtures.py
│ ├── movies.csv
│ └── movies.db
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ └── containers.py
├── venv/
├── config.yml
└── requirements.txt
フィクスチャが作成されます。続けましょう。
コンテナ
このセクションでは、アプリケーションの主要部分であるコンテナを追加します。
コンテナを使用すると、アプリケーションの構造を宣言的なスタイルで記述することができます。これには、すべてのアプリケーションコンポーネントとその依存関係が含まれます。すべての依存関係は明示的に指定されます。プロバイダーは、アプリケーションコンポーネントをコンテナーに追加するために使用されます。プロバイダーは、コンポーネントの寿命を制御します。プロバイダーを作成する場合、コンポーネントは作成されません。オブジェクトの作成方法をプロバイダーに指示し、必要に応じてすぐに作成します。あるプロバイダーの依存関係が別のプロバイダーである場合、依存関係のチェーンに沿って呼び出されます。
編集しましょう
containers.py:
"""Containers module."""
from dependency_injector import containers
class ApplicationContainer(containers.DeclarativeContainer):
...
コンテナはまだ空です。次のセクションでプロバイダーを追加します。
別の関数を追加しましょう
main()。彼女の責任は、アプリケーションを実行することです。今のところ、彼女はコンテナを作成するだけです。
編集しましょう
__main__.py:
"""Main module."""
from .containers import ApplicationContainer
def main():
container = ApplicationContainer()
if __name__ == '__main__':
main()
コンテナは、アプリケーションの最初のオブジェクトです。他のすべてのオブジェクトを取得するために使用されます。
csvの操作
次に、csvファイルを操作するために必要なすべてのものを追加しましょう。
必要なもの:
- エッセンス
Movie - 基本クラス
MovieFinder - その実装
CsvMovieFinder - クラス
MovieLister
各コンポーネントを追加した後、それをコンテナに追加します。パッケージに
ファイル
entities.pyを作成しますmovies。
./
├── data/
│ ├── fixtures.py
│ ├── movies.csv
│ └── movies.db
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ ├── containers.py
│ └── entities.py
├── venv/
├── config.yml
└── requirements.txt
中に次の行を追加します。
"""Movie entities module."""
class Movie:
def __init__(self, title: str, year: int, director: str):
self.title = str(title)
self.year = int(year)
self.director = str(director)
def __repr__(self):
return '{0}(title={1}, year={2}, director={3})'.format(
self.__class__.__name__,
repr(self.title),
repr(self.year),
repr(self.director),
)
次に
Movie、コンテナにファクトリを追加する必要があります。このためには、providersからのモジュールが必要ですdependency_injector。
編集しましょう
containers.py:
"""Containers module."""
from dependency_injector import containers, providers
from . import entities
class ApplicationContainer(containers.DeclarativeContainer):
movie = providers.Factory(entities.Movie)
省略記号(...)を削除することを忘れないでください。コンテナにはすでにプロバイダーが含まれているため、不要になりました。
の作成に移りましょう
finders。パッケージに
ファイル
finders.pyを作成しますmovies。
./
├── data/
│ ├── fixtures.py
│ ├── movies.csv
│ └── movies.db
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ ├── containers.py
│ ├── entities.py
│ └── finders.py
├── venv/
├── config.yml
└── requirements.txt
中に次の行を追加します。
"""Movie finders module."""
import csv
from typing import Callable, List
from .entities import Movie
class MovieFinder:
def __init__(self, movie_factory: Callable[..., Movie]) -> None:
self._movie_factory = movie_factory
def find_all(self) -> List[Movie]:
raise NotImplementedError()
class CsvMovieFinder(MovieFinder):
def __init__(
self,
movie_factory: Callable[..., Movie],
path: str,
delimiter: str,
) -> None:
self._csv_file_path = path
self._delimiter = delimiter
super().__init__(movie_factory)
def find_all(self) -> List[Movie]:
with open(self._csv_file_path) as csv_file:
csv_reader = csv.reader(csv_file, delimiter=self._delimiter)
return [self._movie_factory(*row) for row in csv_reader]
それでは
CsvMovieFinder、コンテナに追加しましょう。
編集しましょう
containers.py:
"""Containers module."""
from dependency_injector import containers, providers
from . import finders, entities
class ApplicationContainer(containers.DeclarativeContainer):
config = providers.Configuration()
movie = providers.Factory(entities.Movie)
csv_finder = providers.Singleton(
finders.CsvMovieFinder,
movie_factory=movie.provider,
path=config.finder.csv.path,
delimiter=config.finder.csv.delimiter,
)
あなたは
CsvMovieFinder、工場への依存性を持っていますMovie。ファイルからデータを読み取るときにCsvMovieFinderオブジェクトを作成するため、ファクトリが必要Movieです。工場を通過するために、属性を使用します.provider。これはプロバイダー委任と呼ばれます。movie依存関係としてファクトリを指定すると、ファクトリcsv_finderが作成されたときに呼び出されCsvMovieFinder、オブジェクトがインジェクションとして渡されMovieます。属性.providerをインジェクションとして使用すると、プロバイダー自体によって渡されます。
また
csv_finder、いくつかの構成オプションにも依存しています。onfigurationこれらの依存関係を渡すためのプロバイダーを追加しました。
値を設定する前に、構成パラメーターを使用しました。これは、プロバイダーが機能する原則ですConfiguration。
最初にを使用し、次に値を設定します。
次に、構成値を追加しましょう。
編集しましょう
config.yml:
finder:
csv:
path: "data/movies.csv"
delimiter: ","
値は構成ファイルに設定されます。関数
main()を更新して、その場所を示しましょう。
編集しましょう
__main__.py:
"""Main module."""
from .containers import ApplicationContainer
def main():
container = ApplicationContainer()
container.config.from_yaml('config.yml')
if __name__ == '__main__':
main()
に行きましょう
listers。パッケージに
ファイル
listers.pyを作成しますmovies。
./
├── data/
│ ├── fixtures.py
│ ├── movies.csv
│ └── movies.db
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ ├── containers.py
│ ├── entities.py
│ ├── finders.py
│ └── listers.py
├── venv/
├── config.yml
└── requirements.txt
中に次の行を追加します。
"""Movie listers module."""
from .finders import MovieFinder
class MovieLister:
def __init__(self, movie_finder: MovieFinder):
self._movie_finder = movie_finder
def movies_directed_by(self, director):
return [
movie for movie in self._movie_finder.find_all()
if movie.director == director
]
def movies_released_in(self, year):
return [
movie for movie in self._movie_finder.find_all()
if movie.year == year
]
更新し
containers.pyます:
"""Containers module."""
from dependency_injector import containers, providers
from . import finders, listers, entities
class ApplicationContainer(containers.DeclarativeContainer):
config = providers.Configuration()
movie = providers.Factory(entities.Movie)
csv_finder = providers.Singleton(
finders.CsvMovieFinder,
movie_factory=movie.provider,
path=config.finder.csv.path,
delimiter=config.finder.csv.delimiter,
)
lister = providers.Factory(
listers.MovieLister,
movie_finder=csv_finder,
)
すべてのコンポーネントが作成され、コンテナに追加されます。
最後に、関数を更新します
main()。
編集しましょう
__main__.py:
"""Main module."""
from .containers import ApplicationContainer
def main():
container = ApplicationContainer()
container.config.from_yaml('config.yml')
lister = container.lister()
print(
'Francis Lawrence movies:',
lister.movies_directed_by('Francis Lawrence'),
)
print(
'2016 movies:',
lister.movies_released_in(2016),
)
if __name__ == '__main__':
main()
すべての準備が整いました。それでは、アプリケーションを起動しましょう。
ターミナルで実行してみましょう:
python -m movies
次のように表示されます。
Francis Lawrence movies: [Movie(title='The Hunger Games: Mockingjay - Part 2', year=2015, director='Francis Lawrence')]
2016 movies: [Movie(title='Rogue One: A Star Wars Story', year=2016, director='Gareth Edwards'), Movie(title='The Jungle Book', year=2016, director='Jon Favreau')]
私たちのアプリケーションは、の映画のデータベースで動作します
csv。また、フォーマットサポートを追加する必要がありますsqlite。これについては、次のセクションで扱います。
sqliteの操作
このセクションでは、別のタイプを追加します
MovieFinder- SqliteMovieFinder。
編集しましょう
finders.py:
"""Movie finders module."""
import csv
import sqlite3
from typing import Callable, List
from .entities import Movie
class MovieFinder:
def __init__(self, movie_factory: Callable[..., Movie]) -> None:
self._movie_factory = movie_factory
def find_all(self) -> List[Movie]:
raise NotImplementedError()
class CsvMovieFinder(MovieFinder):
def __init__(
self,
movie_factory: Callable[..., Movie],
path: str,
delimiter: str,
) -> None:
self._csv_file_path = path
self._delimiter = delimiter
super().__init__(movie_factory)
def find_all(self) -> List[Movie]:
with open(self._csv_file_path) as csv_file:
csv_reader = csv.reader(csv_file, delimiter=self._delimiter)
return [self._movie_factory(*row) for row in csv_reader]
class SqliteMovieFinder(MovieFinder):
def __init__(
self,
movie_factory: Callable[..., Movie],
path: str,
) -> None:
self._database = sqlite3.connect(path)
super().__init__(movie_factory)
def find_all(self) -> List[Movie]:
with self._database as db:
rows = db.execute('SELECT title, year, director FROM movies')
return [self._movie_factory(*row) for row in rows]
プロバイダー
sqlite_finderをコンテナーに追加し、プロバイダーの依存関係として指定しますlister。
編集しましょう
containers.py:
"""Containers module."""
from dependency_injector import containers, providers
from . import finders, listers, entities
class ApplicationContainer(containers.DeclarativeContainer):
config = providers.Configuration()
movie = providers.Factory(entities.Movie)
csv_finder = providers.Singleton(
finders.CsvMovieFinder,
movie_factory=movie.provider,
path=config.finder.csv.path,
delimiter=config.finder.csv.delimiter,
)
sqlite_finder = providers.Singleton(
finders.SqliteMovieFinder,
movie_factory=movie.provider,
path=config.finder.sqlite.path,
)
lister = providers.Factory(
listers.MovieLister,
movie_finder=sqlite_finder,
)
プロバイダー
sqlite_finderは、まだ定義していない構成オプションに依存しています。構成ファイルを更新しましょう:
編集
config.yml:
finder:
csv:
path: "data/movies.csv"
delimiter: ","
sqlite:
path: "data/movies.db"
完了。確認しよう。
ターミナルで実行します:
python -m movies
次のように表示されます。
Francis Lawrence movies: [Movie(title='The Hunger Games: Mockingjay - Part 2', year=2015, director='Francis Lawrence')]
2016 movies: [Movie(title='Rogue One: A Star Wars Story', year=2016, director='Gareth Edwards'), Movie(title='The Jungle Book', year=2016, director='Jon Favreau')]
私たちのアプリケーションは、両方のデータベース形式をサポートしています
csvとsqlite。フォーマットを変更する必要があるたびに、コンテナ内のコードを変更する必要があります。これは次のセクションで改善します。
プロバイダーセレクター
このセクションでは、アプリケーションをより柔軟にします。
あなた間のスイッチにコードを変更することはもはや必要
csvとsqliteフォーマット。環境変数に基づいてスイッチを実装しますMOVIE_FINDER_TYPE。
- ときに
MOVIE_FINDER_TYPE=csvアプリケーションが使用していますcsv。 - ときに
MOVIE_FINDER_TYPE=sqliteアプリケーションが使用していますsqlite。
プロバイダーがこれをお手伝いします
Selector。構成オプション(ドキュメント)に基づいてプロバイダーを選択します。
編集しましょう
containers.py:
"""Containers module."""
from dependency_injector import containers, providers
from . import finders, listers, entities
class ApplicationContainer(containers.DeclarativeContainer):
config = providers.Configuration()
movie = providers.Factory(entities.Movie)
csv_finder = providers.Singleton(
finders.CsvMovieFinder,
movie_factory=movie.provider,
path=config.finder.csv.path,
delimiter=config.finder.csv.delimiter,
)
sqlite_finder = providers.Singleton(
finders.SqliteMovieFinder,
movie_factory=movie.provider,
path=config.finder.sqlite.path,
)
finder = providers.Selector(
config.finder.type,
csv=csv_finder,
sqlite=sqlite_finder,
)
lister = providers.Factory(
listers.MovieLister,
movie_finder=finder,
)
プロバイダーを作成し、プロバイダー
finderの依存関係として指定しましたlister。プロバイダーfinderは、プロバイダーcsv_finderとsqlite_finder実行時にプロバイダーを選択します。選択は、スイッチの値によって異なります。
スイッチは構成オプション
config.finder.typeです。その値がcsvキーからプロバイダーによって使用される場合csv。同様にsqlite。
次に
config.finder.type、環境変数から値を読み取る必要がありますMOVIE_FINDER_TYPE。
編集しましょう
__main__.py:
"""Main module."""
from .containers import ApplicationContainer
def main():
container = ApplicationContainer()
container.config.from_yaml('config.yml')
container.config.finder.type.from_env('MOVIE_FINDER_TYPE')
lister = container.lister()
print(
'Francis Lawrence movies:',
lister.movies_directed_by('Francis Lawrence'),
)
print(
'2016 movies:',
lister.movies_released_in(2016),
)
if __name__ == '__main__':
main()
完了。
ターミナルで次のコマンドを実行します。
MOVIE_FINDER_TYPE=csv python -m movies
MOVIE_FINDER_TYPE=sqlite python -m movies
各コマンドの出力は次のようになります。
Francis Lawrence movies: [Movie(title='The Hunger Games: Mockingjay - Part 2', year=2015, director='Francis Lawrence')]
2016 movies: [Movie(title='Rogue One: A Star Wars Story', year=2016, director='Gareth Edwards'), Movie(title='The Jungle Book', year=2016, director='Jon Favreau')]
このセクションでは、プロバイダーについて知りました
Selector。このプロバイダーを使用すると、アプリケーションをより柔軟にすることができます。スイッチの値は、構成ファイル、辞書、その他のプロバイダーなど、任意のソースから設定できます。
ヒント:
別のプロバイダーからの構成値をオーバーライドすると、ホットリスタートなしでアプリケーションに構成のオーバーロードを実装できます。
これを行うには、プロバイダーの委任とを使用する必要があります.override()。
次のセクションでは、いくつかのテストを追加します。
テスト
最後に、いくつかのテストを追加しましょう。パッケージに
ファイル
tests.pyを作成しますmovies。
./
├── data/
│ ├── fixtures.py
│ ├── movies.csv
│ └── movies.db
├── movies/
│ ├── __init__.py
│ ├── __main__.py
│ ├── containers.py
│ ├── entities.py
│ ├── finders.py
│ ├── listers.py
│ └── tests.py
├── venv/
├── config.yml
└── requirements.txt
それに次の行を追加します。
"""Tests module."""
from unittest import mock
import pytest
from .containers import ApplicationContainer
@pytest.fixture
def container():
container = ApplicationContainer()
container.config.from_dict({
'finder': {
'type': 'csv',
'csv': {
'path': '/fake-movies.csv',
'delimiter': ',',
},
'sqlite': {
'path': '/fake-movies.db',
},
},
})
return container
def test_movies_directed_by(container):
finder_mock = mock.Mock()
finder_mock.find_all.return_value = [
container.movie('The 33', 2015, 'Patricia Riggen'),
container.movie('The Jungle Book', 2016, 'Jon Favreau'),
]
with container.finder.override(finder_mock):
lister = container.lister()
movies = lister.movies_directed_by('Jon Favreau')
assert len(movies) == 1
assert movies[0].title == 'The Jungle Book'
def test_movies_released_in(container):
finder_mock = mock.Mock()
finder_mock.find_all.return_value = [
container.movie('The 33', 2015, 'Patricia Riggen'),
container.movie('The Jungle Book', 2016, 'Jon Favreau'),
]
with container.finder.override(finder_mock):
lister = container.lister()
movies = lister.movies_released_in(2015)
assert len(movies) == 1
assert movies[0].title == 'The 33'
それでは、テストを開始してカバレッジを確認しましょう。
pytest movies/tests.py --cov=movies
次のように表示されます。
platform darwin -- Python 3.8.3, pytest-5.4.3, py-1.9.0, pluggy-0.13.1
plugins: cov-2.10.0
collected 2 items
movies/tests.py .. [100%]
---------- coverage: platform darwin, python 3.8.3-final-0 -----------
Name Stmts Miss Cover
------------------------------------------
movies/__init__.py 0 0 100%
movies/__main__.py 10 10 0%
movies/containers.py 9 0 100%
movies/entities.py 7 1 86%
movies/finders.py 26 13 50%
movies/listers.py 8 0 100%
movies/tests.py 24 0 100%
------------------------------------------
TOTAL 84 24 71%
.override()プロバイダー方式を使用しましたfinder。プロバイダーはモックによってオーバーライドされます。プロバイダーに連絡すると、finderオーバーライドするモックが返されます。
作業は完了です。それでは要約しましょう。
結論
依存関係注入の原則を使用してCLIアプリケーションを構築しました。依存関係インジェクターを依存関係インジェクションフレームワークとして使用しました。
Dependency Injectorで得られる利点は、コンテナーです。
アプリケーションの構造を理解または変更する必要がある場合、コンテナは成果を上げ始めます。コンテナを使用すると、すべてのアプリケーションコンポーネントとその依存関係が一箇所で明示的に定義されるため、これは簡単です。
"""Containers module."""
from dependency_injector import containers, providers
from . import finders, listers, entities
class ApplicationContainer(containers.DeclarativeContainer):
config = providers.Configuration()
movie = providers.Factory(entities.Movie)
csv_finder = providers.Singleton(
finders.CsvMovieFinder,
movie_factory=movie.provider,
path=config.finder.csv.path,
delimiter=config.finder.csv.delimiter,
)
sqlite_finder = providers.Singleton(
finders.SqliteMovieFinder,
movie_factory=movie.provider,
path=config.finder.sqlite.path,
)
finder = providers.Selector(
config.finder.type,
csv=csv_finder,
sqlite=sqlite_finder,
)
lister = providers.Factory(
listers.MovieLister,
movie_finder=finder,
)
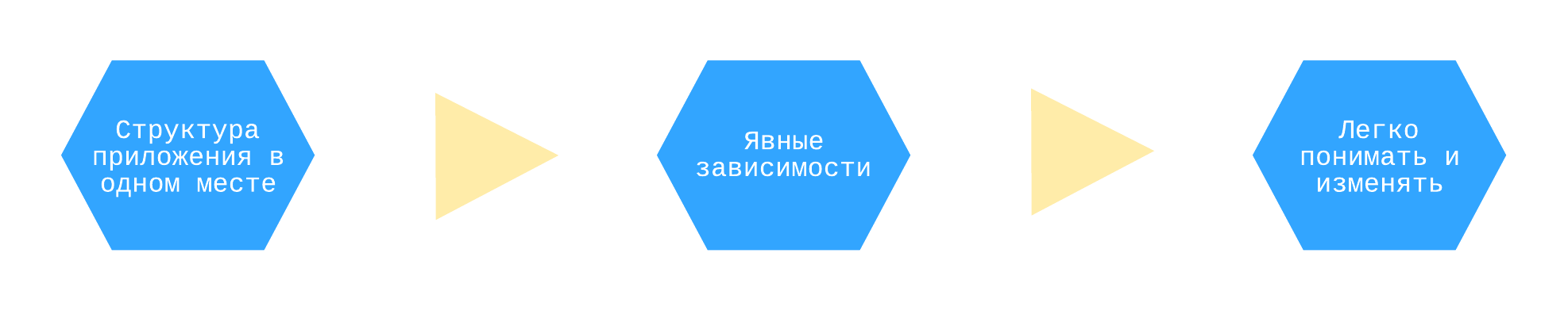
アプリケーションのマップとしてのコンテナー。あなたは常に何が何に依存するかを知っています。
PS:質問と回答
前のチュートリアルへのコメントでは、「なぜこれが必要なのか」、「なぜフレームワークが必要なのか」、「フレームワークは実装にどのように役立つのか」というクールな質問がありました。
私は答えを用意しました:
依存関係の注入とは何ですか?
- 結合を減らし、凝集力を高めるのが原理です
なぜ依存関係の注入を使用する必要があるのですか?
- コードがより柔軟で、理解しやすく、テストしやすくなります
- それがどのように機能するかを理解したり、変更したりする必要がある場合は、問題が少なくなります
依存関係インジェクションの適用を開始するにはどうすればよいですか?
- 依存関係の注入の原則に従ってコードを書き始めます
- すべてのコンポーネントとその依存関係をコンテナに登録します
- コンポーネントが必要な場合は、コンテナから取得します
なぜこのためのフレームワークが必要なのですか?
- 独自のフレームワークを作成しないためには、フレームワークが必要です。オブジェクト作成コードは複製され、変更が困難になります。これを回避するには、コンテナが必要です。
- フレームワークはあなたにコンテナとプロバイダーを提供します
- プロバイダーはオブジェクトの存続期間を制御します。工場、シングルトン、構成オブジェクトが必要になります
- コンテナはプロバイダーのコレクションとして機能します
いくら払っていますか?
- コンテナ内の依存関係を明示的に指定する必要があります
- これは追加の作業です
- プロジェクトが成長し始めると、配当金の支払いが開始されます
- または完了後2週間(どのような決定をしたか、プロジェクトの構造は何かを忘れた場合)
ディペンデンシーインジェクターのコンセプト
さらに、フレームワークとしてのDependencyInjectorの概念についても説明します。
依存関係インジェクターは、次の2つの原則に基づいています。
- 明示的は暗黙的(PEP20)よりも優れています。
- コードで魔法をかけないでください。
Dependency Injectorは他のフレームワークとどのように異なりますか?
- 自動リンクはありません。フレームワークは依存関係を自動的にリンクしません。イントロスペクション、引数名および/またはタイプによるリンクは使用されません。「明示的は暗黙的(PEP20)よりも優れている」からです。
- アプリケーションコードを汚染しません。アプリケーションは、依存関係インジェクターを認識せず、独立しています。
@injectデコレータ、注釈、パッチ、その他の魔法のトリックはありません。
Dependency Injectorは、単純な契約を提供します。
- オブジェクトを収集する方法をフレームワークに示します
- フレームワークはそれらを収集します
依存関係インジェクターの強みは、そのシンプルさとわかりやすさにあります。これは、強力な原則を実装するためのシンプルなツールです。
次は何ですか?
興味があるが躊躇している場合は、次のことをお勧めし
ます。このアプローチを2か月間試してください。彼は直感的ではありません。慣れて感じるには時間がかかります。プロジェクトがコンテナ内の30以上のコンポーネントに成長すると、メリットが明確になります。気に入らなくても、多くを失うことはありません。あなたがそれを好きなら、重要な利点を手に入れてください。
コメントでフィードバックを受け取り、質問に答えていただければ幸いです。