前書き
こんにちは、Habr!
多くの人が前の部分を気に入ったので、私は再びブーストドキュメントの半分をシャベルして、何か書くべきものを見つけました。boost.asioの周りのようにboost.computeの周りにそのような興奮がないのは非常に奇妙です。結局のところ、このライブラリはクロスプラットフォームであり、GPUおよびCPUで並列コンピューティングと対話するための便利な(c ++のフレームワーク内の)インターフェイスも提供します。
すべての部品
- パート1
- パート2
コンテンツ
- 非同期操作
- カスタム機能
- さまざまなモードでのさまざまなデバイスの速度の比較
- 結論
非同期操作
それははるかに速いように見えますか?計算名義のコンテナでの作業をスピードアップする1つの方法は、非同期関数を使用することです。 Boost.computeは、いくつかのツールを提供します。これらのうち、関数の使用を制御するためのcompute :: futureクラスと、配列をコピーまたは入力するためのcopy_async()、fill_async()関数。もちろん、イベントを操作するためのツールもありますが、それらを考慮する必要はありません。以下は、上記のすべてを使用する例です。
auto device = compute::system::default_device();
auto context = compute::context::context(device);
auto queue = compute::command_queue(context, device);
std::vector<int> vec_std = {1, 2, 3};
compute::vector<int> vec_compute(vec_std.size(), context);
compute::vector<int> for_filling(10, context);
int num_for_fill = 255;
compute::future<void> filling = compute::fill_async(for_filling.begin(),
for_filling.end(), num_for_fill, queue); //
compute::future<void> copying = compute::copy_async(vec_std.begin(),
vec_std.end(), vec_compute.begin(), queue); //
filling.wait();
copying.wait();
ここで説明する特別なことは何もありません。最初の3行は必要なクラスの標準初期化であり、次にコピー用の2つのベクトル、塗りつぶし用のベクトル、その変数は前のベクトルを塗りつぶし、直接塗りつぶしとコピーの関数をそれぞれ入力します。次に、それらの実行を待ちます。
STLのstd :: futureを使用した人にとって、ここではすべてが同じですが、名前が異なるだけで、std :: async()の類似物はありません。
計算用のカスタム関数
前のパートでは、独自のメソッドを使用してデータセットを処理する方法について説明することを説明しました。これを行うには、マクロを使用する方法、make_function_from_source <>()を使用する方法、ラムダ式用の特別なフレームワークを使用する方法の3つを数えました。
最初のオプションであるマクロから始めます。まず、サンプルコードを添付してから、その仕組みを説明します。
BOOST_COMPUTE_FUNCTION(float,
add,
(float x, float y),
{ return x + y; });
最初の引数は戻り値のタイプであり、次に関数の名前、その引数、および関数の本体です。さらにaddという名前で、この関数は、たとえば、compute :: transform()関数で使用できます。このマクロの使用は通常のラムダ式と非常に似ていますが、機能しないことを確認しました。
2番目の、おそらく最も難しい方法は、最初の方法と非常に似ています。前のマクロのコードを調べたところ、2番目の方法を使用していることがわかりました。
compute::function<float(float)> add = compute::make_function_from_source<float(float)>
("add", "float add(float x, float y) { return x + y; }");
ここでは、一見したところよりもすべてが明白です。make_function_from_source()関数は、2つの引数のみを使用します。1つは関数の名前で、もう1つはその実装です。関数が宣言された後は、マクロ実装後と同じように使用できます。
さて、最後のオプションはラムダ式フレームワークです。使用例:
compute::transform(com_vec.begin(),
com_vec.end(),
com_vec.begin(),
compute::_1 * 2,
queue);
4番目の引数として、最初のベクトルの各要素に2を掛けたいことを示します。すべてが非常に単純で、適切に実行されます。
ブール式も同様に指定できます。たとえば、compute :: count_if()メソッドでは次のようになります。
std::vector<int> source_std = { 1, 2, 3 };
compute::vector<int> source_compute(source_std.begin() ,source_std.end(), queue);
auto counter = compute::count_if(source_compute.begin(),
source_compute.end(),
compute::lambda::_1 % 2 == 0,
queue);
したがって、配列内のすべての偶数をカウントしました。counterは1に等しくなります。
さまざまなモードでのさまざまなデバイスの速度の比較
さて、この記事で最後に書きたいのは、さまざまなデバイスとさまざまなモード(CPUのみ)でのデータ処理速度の比較です。この比較は、一般にコンピューティングと並列コンピューティングにGPUを使用することが理にかなっている場合に証明されます。
次のようにテストします。すべてのデバイスにcomputeを使用して、1億個のfloat値の配列をソートするためにcompute :: sort()関数を呼び出します。シングルスレッドモードをテストするには、同じサイズの配列でstd :: sortを呼び出します。デバイスごとに、クロノ標準ライブラリを使用して時間をミリ秒単位で記録し、すべてをコンソールに出力します。
結果は次のとおりです

。1000個の値に対してのみ同じことを行います。今回はマイクロ秒単位になります。

今回は、シングルスレッドモードのプロセッサが誰よりも進んでいました。このことから、この種の操作は、本当に大きなデータに関してのみ行う価値があると結論付けます。
もう少しテストをしたいので、余弦、平方根、二乗を計算するテストをしてみましょう。
コサインの計算では、その差は非常に大きくなります(GPUは1つのスレッドでCPUより60倍高速に実行されます)。
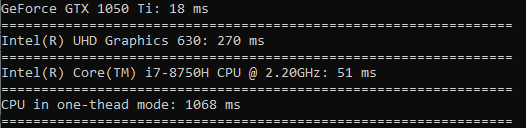
平方根は、ソートとほぼ同じ速度で計算されます。
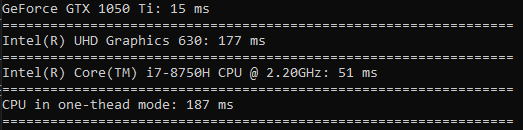
二乗に費やされる時間は、並べ替えよりもさらにわずかです(GPUはわずか3.5倍高速です)。

結論
したがって、この記事を読んだ後、非同期関数を使用して配列をコピーして埋める方法を学びました。独自の関数を使用してデータの計算を実行する方法を学びました。また、並列コンピューティングにGPUまたはCPUを使用する価値がある場合、および1つのスレッドで処理できる場合も明確にわかりました。
お時間をいただき、ありがとうございました。
皆さんお元気で!