GoogleSheets→Node.js→GoogleCharts→名刺サイト→検索のトップ3氏名+専門分野
表のデータに基づいて、自動的に生成される出版物に関する情報を名刺サイトに追加することにしました。私が欲しいもの:
- GoogleChartsのタイムラインにある出版物の最新の要約。
- googleテーブルからhtmlバージョンの名刺への出力データと記事へのリンクの自動生成。
- 将来的に一部の古いサイトが閉鎖されることが懸念されるため、すべてのサイトの記事のPDFバージョン。
あなたはそれがどのように起こったかをここで見ることができます。生データを保存するためにBootstrap、Google Charts、およびGoogleSheetsを使用してNode.jsプラットフォームに実装されます。
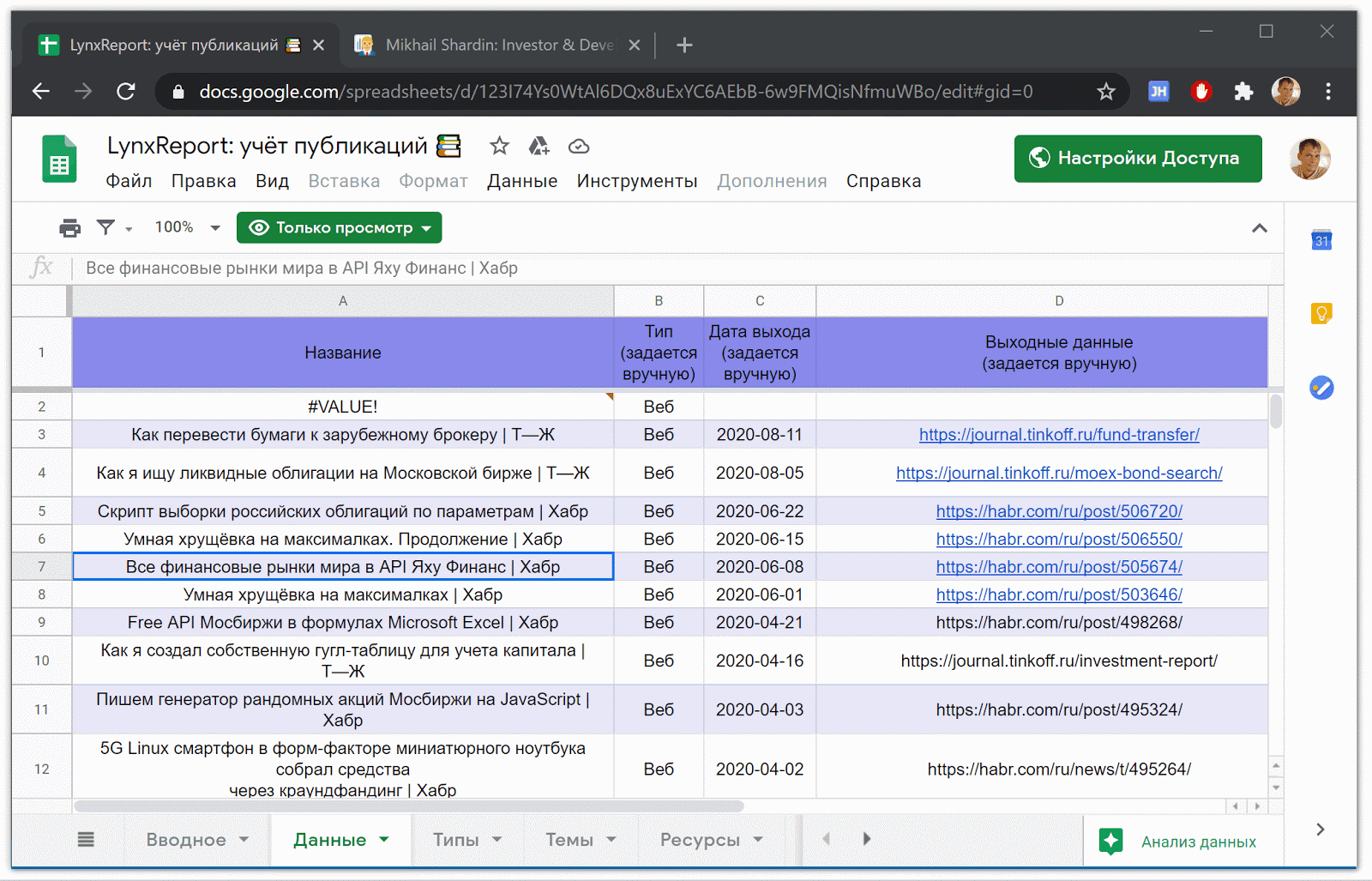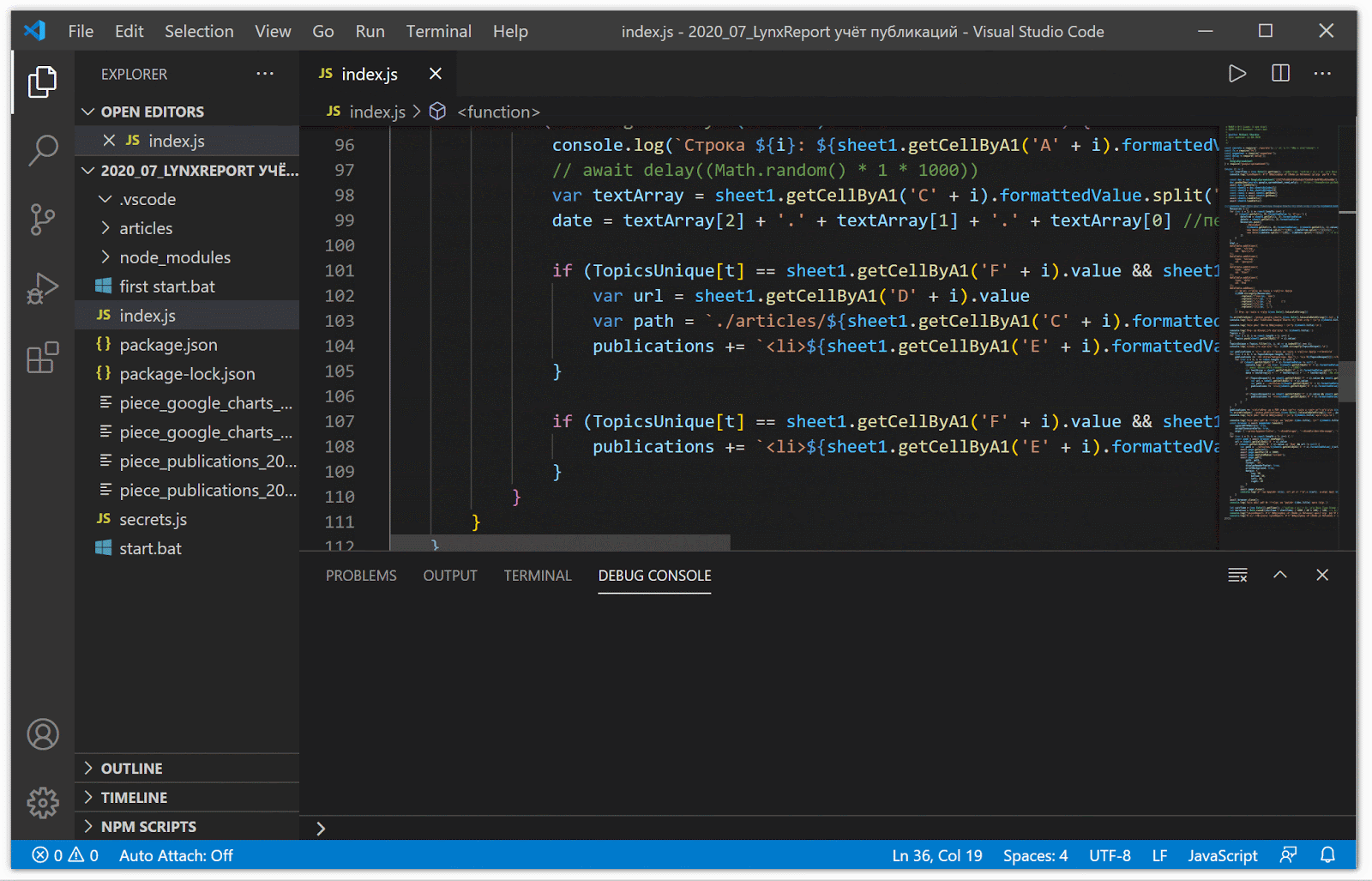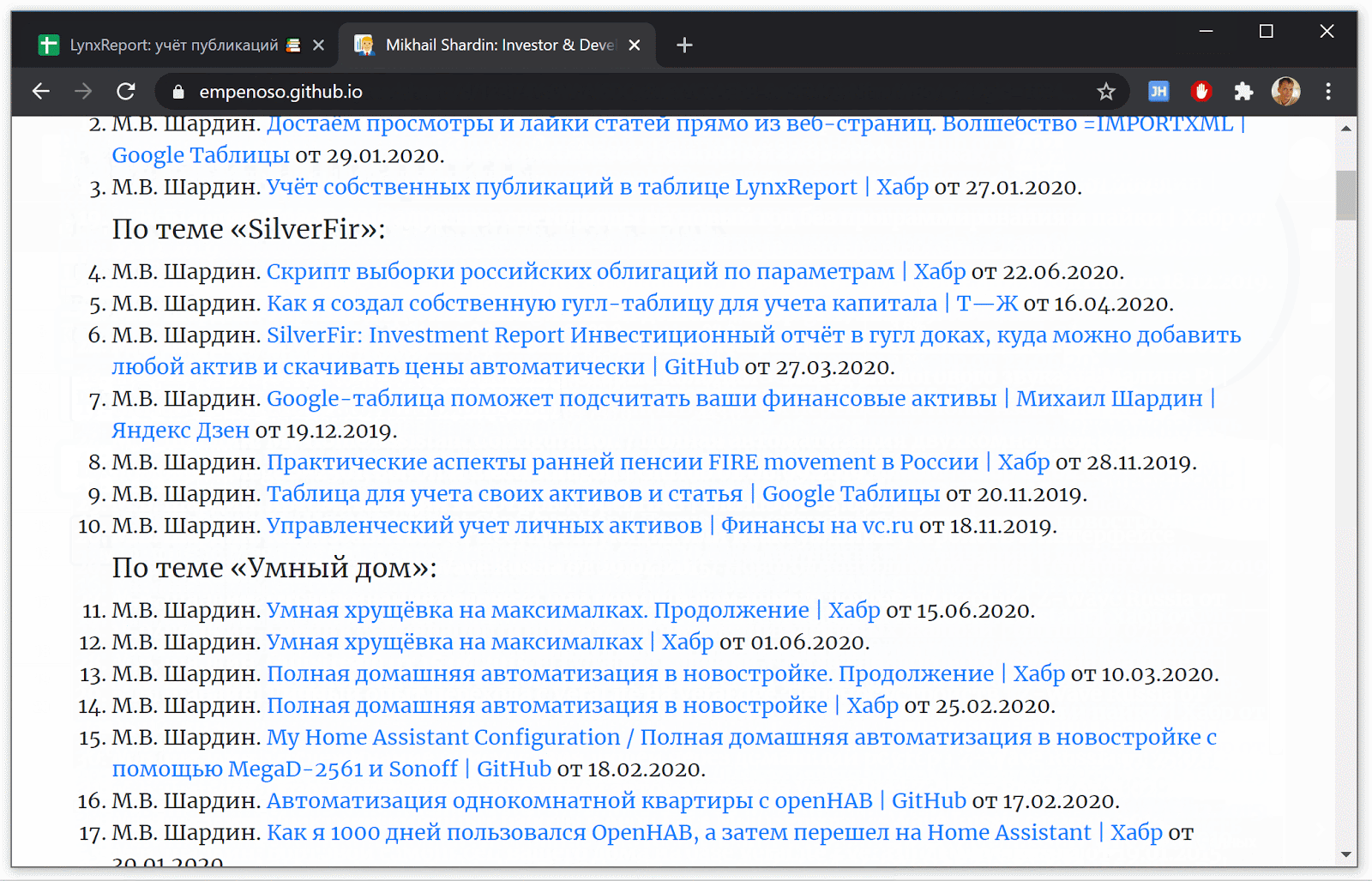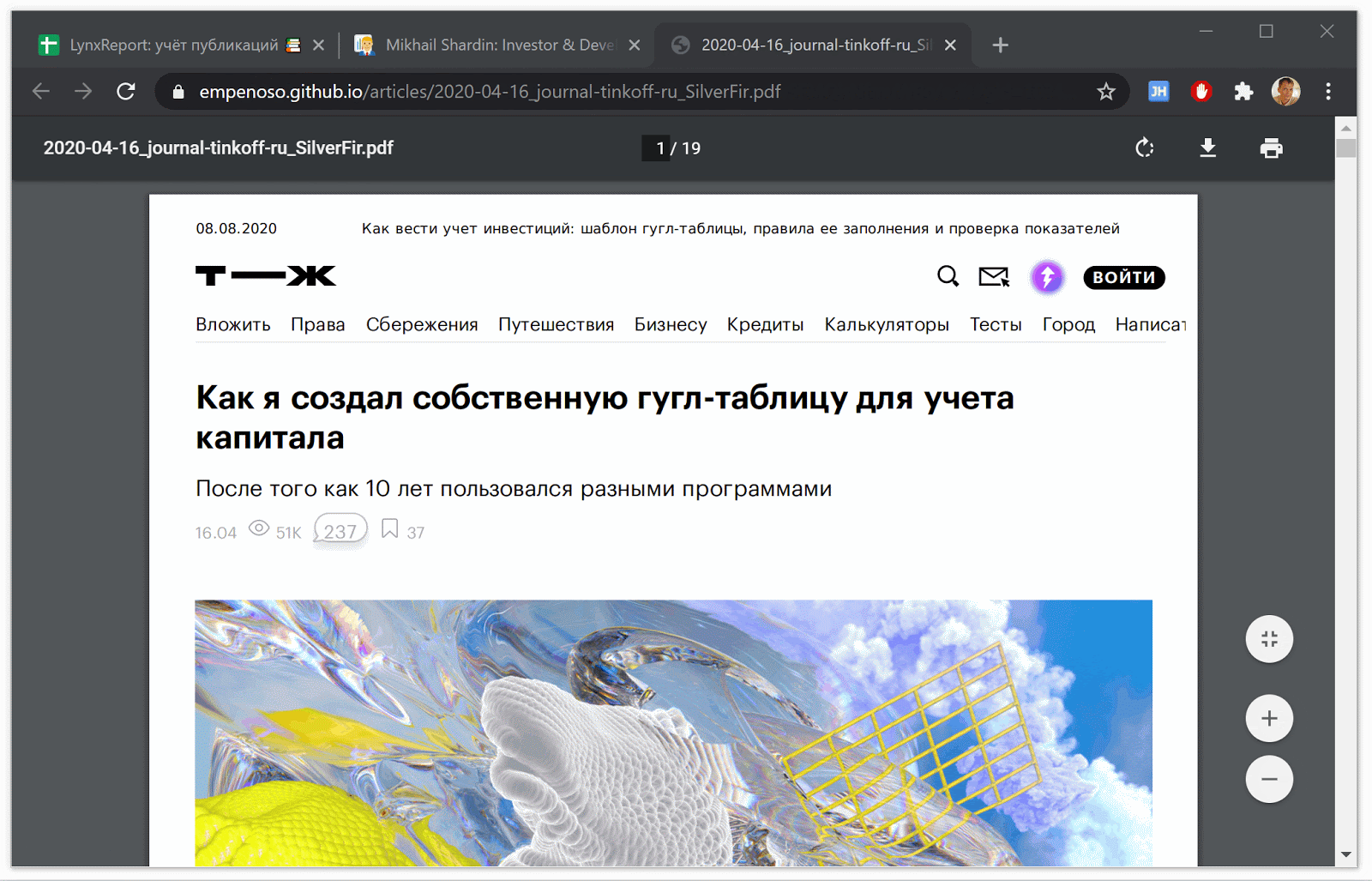
GoogleSpreadsheetの出版物に関する生データ
Google Spreadsheet LynxReport:出版物の会計には、出版物のすべてのソースデータと分析が含まれています。記事への新しいリンクを手動で入力して、[データ]タブの情報を最新の状態に保ちます。残りの部分は、ほとんどが自動的にダウンロードされます。LynxReport
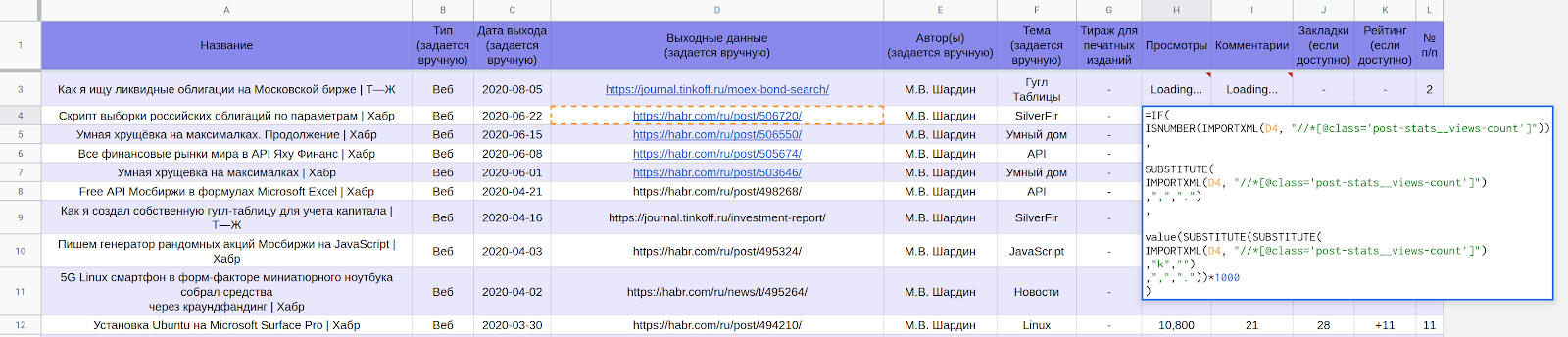
テーブルの一部:初期データを使用したパブリケーションのアカウンティング
ビューとコメントの実際のデータは、式を介してロードされます。
たとえば、Googleテーブルのセル内のHabrページからのビュー数を取得するには、次の式を使用します。
=IF(
ISNUMBER(IMPORTXML(D6, "//*[@class='post-stats__views-count']"))
,
SUBSTITUTE(
IMPORTXML(D6, "//*[@class='post-stats__views-count']")
,",",".")
,
value(SUBSTITUTE(SUBSTITUTE(
IMPORTXML(D6, "//*[@class='post-stats__views-count']")
,"k","")
,",","."))*1000
)
フォーミュラは最速のオプションではなく、数百のポジションを獲得するには約30分待つ必要があります。ダウンロードが完了すると、下のスクリーンショットのようにすべての番号が表示されます。それらは、人気のあるトピックとそうでないトピックに対する回答を提供します。LynxReport

テーブルの一部:分析による投稿
スプレッドシートからデータを読み取り、Googleチャート形式に変換する
このピボットデータをGoogleスプレッドシートから名刺サイトに変換するには、データをGoogleChartsタイムライン形式に変換する必要がありました。ビジネスカードサイト

でのGoogleチャートの結果のタイムライン このようなチャートを正しく描画するには、データを次のように整理する必要があります。html形式のビジネスカードサイトでのGoogleチャートのデータ すべての変換を自動的に実行するには、Node.jsで利用可能なスクリプトを作成しました。 GitHubで。 Node.jsに慣れていない場合は、前回の記事で、さまざまなシステムでスクリプトを使用する方法について詳しく説明しました。

- ウィンドウズ
- マックOS
- Linux
こちらの手順に リンクしてください。原理は似ています。目的のデータ形式に変換し、サイトから記事のpdfバージョンを生成するため

のスクリプトの作業(すべての行が即座に処理されます-このビデオを記録するために特別に遅延を設定します)
自動モードでGoogleテーブルからデータを読み取るために、キー認証を使用します。
あなたは、このキーを取得することができますグーグルでプロジェクト管理コンソール:資格の

Googleのクラウドプラットフォームでの
スクリプトの完了後に、HTMLグラフのデータとオンラインの記事のすべてのPDFコピーを持つ2つのテキストファイルを生成する必要があります。
テキストファイルから名刺サイトのhtmlコードにデータをインポートします。
サイトからの記事のpdfコピーの生成
Puppeteer を使用して、記事の現在のビューとすべてのコメントをpdf形式で保存します。
遅延を設定しない場合、リスト上の数十の記事をわずか数分でpdfファイルとして保存できます。
また、一部のサイト(たとえば、-)にコメントをロードするには、遅延が必要です。
結果
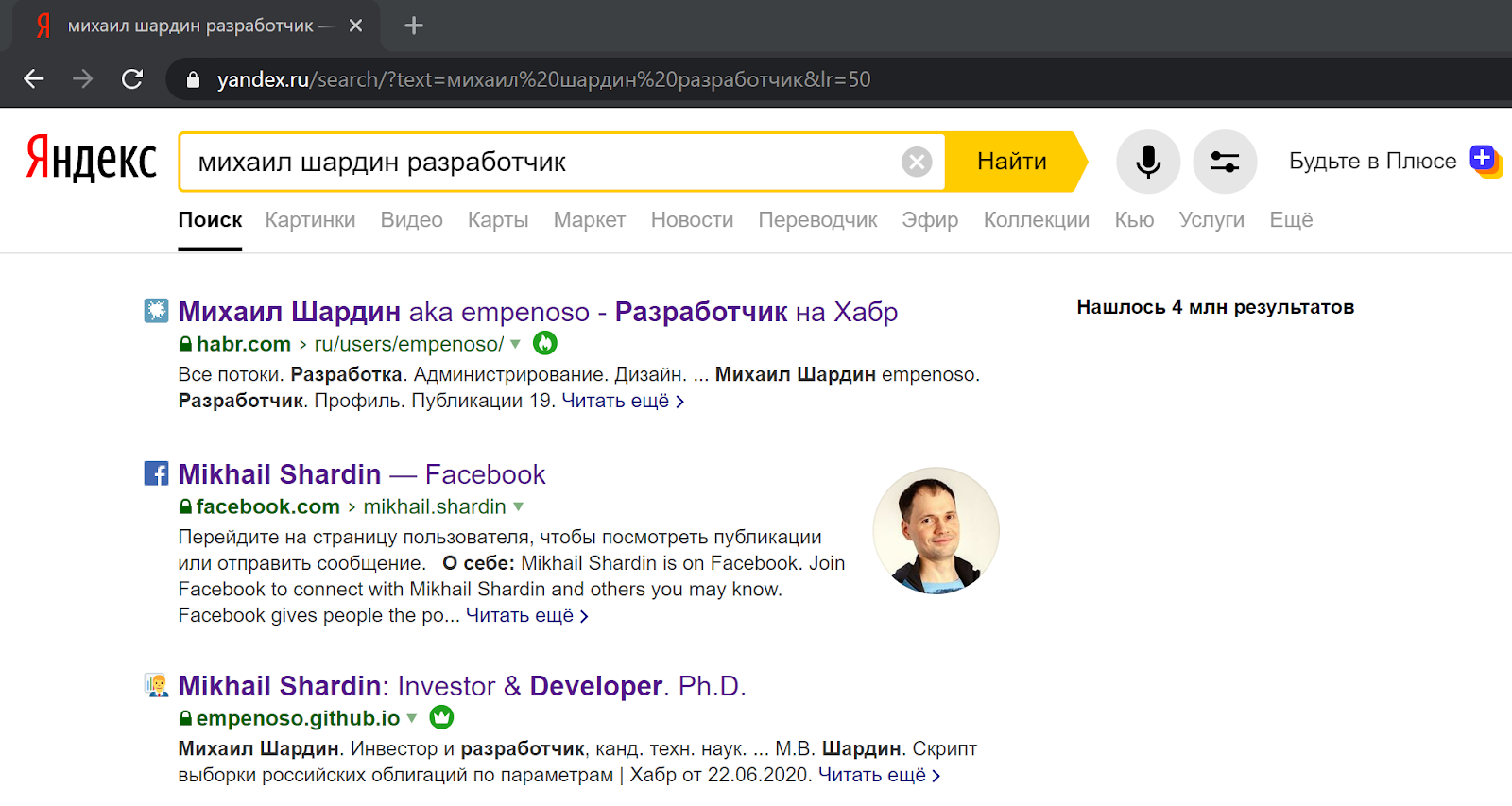
スクリプトの作成は検索アルゴリズムとの一致を高めるために開始されたため、検索を使用して結果を評価できます。
名前と姓で検索+どちらの場合も専門分野の表示は、私の記事や名刺サイトへのリンクを返します:Yandex検索
結果の場合:Google検索 結果の場合: 名刺がempenoso.github.ioの場合、別のドメイン名を登録する価値があるかどうかを判断できません。そしてそれは検索のトップラインにありますか?

結論の代わりに
- おそらく、この記事は誰かに彼がインターネット上でどのように見えるかについて考えさせるでしょう。
- おそらく、この記事は誰かが出版物の会計と組織を確立するのに役立つでしょう。
- スクリプトのソースコードはGitHubにあります。
投稿者:Mikhail Shardin
2020年8月17日