
前書き
機械学習には、さまざまな好みに応じて、それらが開催されるプラットフォームだけでなく、多くのコンテストがあります。しかし、コンテストのテーマが人間の言語とその処理である場合はそれほど多くありません。そのような競争がロシア語に関連していることはさらに少ないです。私は最近、Mail.ruのML BootCampプラットフォームでの中国からロシアへのマシン翻訳コンテストに参加しました。競争力のあるプログラミングの経験があまりなく、検疫のおかげで5月の休暇をすべて自宅で過ごしたことが、なんとか1位になりました。この記事では、これについてだけでなく、言語や、あるタスクを別のタスクに置き換えることについても説明します。
第1章決して中国語を話さない
このコンテストの著者は、中国とロシアのペアの大企業からの翻訳でさえ、より人気のあるペアよりも大幅に遅れているため、汎用の機械翻訳システムを作成することを提案しました。しかし、検証はニュースとフィクションで行われたため、ニュースコーパスと本から学ぶ必要があることが明らかになりました。転送を評価するためのメトリックは、標準のBLEUでした。このメトリックは、人間の翻訳と機械の翻訳を比較し、大まかに言えば、見つかった一致の数に基づいて、100ポイントスケールでテキストの類似性を推定します。ロシア語はその形態が豊富であるため、このメトリックは、単語形成の方法が少ない言語(たとえば、ロマンス言語-フランス語、イタリア語など)よりも、翻訳すると常に著しく低くなります。
機械学習を扱う人なら誰でも、それが主にデータとそのクリーニングに関するものであることを知っています。コーパスを探し始めると同時に、機械翻訳の荒野を理解しましょう。だから、白いマントで...
第2章PonTiy Pi Lat
血まみれの裏地が付いた白いマント、シャッフルする騎兵隊の歩き方で、私たちは平行したロシアと中国の軍団の背後にある検索エンジンに乗り込みます。後で理解するように、私たちが見つけたものは十分ではありませんが、今のところ私たちの最初の発見を見てみましょう(私は見つけてクリーンアップしたデータセットを収集し、それらをパブリックドメインに置きました[1]):
OPUSは非常に大きく、言語的に多様なコーパスです。その例を見てみましょう。
「私たちが経験したこと、あなたが経験したことよりもさらに奇妙なこと...»
我与她的比你的经历经历分離奇多了
」それについてお話しします。»
我给你讲讲今段经历...
」私が生まれた小さな町…」
我出生那座小镇..。
名前が示すように、これらは主に映画やテレビシリーズのサブタイトルです。TEDサブタイトルは同じタイプに属しており、解析とクリーニングを行った後、完全に並列のコーパスになります。
これは罰では当社の過去の実験がどうなったかである:WikiMatrixは、さまざまな言語のインターネットページ(いわゆる一般的なクロール)からのレーザーで整列されたテキストですが、私たちのタスクではそれらは少なく、奇妙に見えます。
这就是关于我们印象中的惩戒措施的不为人知的一面
若者は、いつでも、彼らが停止することができることを恐れている拘留され、検索。
年轻人总是担心随时会被截停、搜身和捕捕
そして路上だけでなく、自分の家でも、
無论是在街上更是在家
Zbranki(ウクライナ語データ検索の最初の段階の後、私たちのモデルに疑問が生じます。ツールとは何ですか?また、タスクにアプローチする方法は何ですか?MIPTのStepic [2]で
ですが
、彼は暑认。しかし、知っているだけなら早くしたほうがいいです!
斋戒対来你们更好、如果你们知道。
彼はこの声明を拒否し
ました。
とても気に入ったNLPコースがあります。これは、オンラインで利用する場合に特に便利です。このコースでは、セミナーで機械翻訳システムも理解されており、自分で作成します。 Colabでトレーニングした後、ゼロから作成されたネットワークが、ドイツ語のテキストに応じて適切なロシア語の翻訳を作成したことを嬉しく思います。アテンションメカニズムを備えたトランスのアーキテクチャに基づいてモデルを構築しましたが、これはかつて画期的なアイデアになりました[3]。
当然、最初に考えたのは「モデルに異なる入力データを与えるだけ」で、すでに勝っています。しかし、中国の学童なら誰でも知っているように、中国のスクリプトにはスペースがなく、モデルは入力としてトークンのセットを受け入れます。これはその中の単語です。jiebaのようなライブラリは、中国語のテキストをある程度の精度で単語に分割できます。モデルに単語のトークン化を埋め込み、見つかったコーパスで実行すると、約0.5のBLEUが得られました(スケールは100ポイントです)。
第3章機械の翻訳と公開
OpenMNT に基づいた公式ベースライン(シンプルだが実用的なソリューション例)がコンテストに提案されました。これは、ツイスト用の多くのハイパーパラメータを備えたオープンソースの翻訳学習ツールです。このステップでは、モデルをトレーニングして推測してみましょう。 40時間のGPUトレーニングを無料で提供するkaggleプラットフォームでトレーニングします[4]。
なお、この時点では参加者が少なかったため、入場後すぐに上位5位に入ることもあり、その理由もありました。ソリューションの形式は、推論プロセス中にフォルダーがマウントされるドッカーコンテナーであり、モデルは1つから読み取り、別の答えを入力する必要がありました。公式のベースラインが開始されず(私は個人的にすぐに組み立てなかった)、重みがなかったので、私は自分で収集してパブリックドメインに置くことにしました[5]。その後、参加者は、ソリューションを正しく組み立て、一般的にドッカーを手伝うように要求して申請を開始しました。道徳的な、コンテナは今日の開発の標準であり、それらを使用し、あなたの人生を調整し、簡素化します(誰もが最後の声明に同意するわけではありません)。
ここで、前の手順で見つかったボディにさらにいくつか追加してみましょう。
1つ目は、国連会議からの法的文書の膨大なコーパスです。ちなみに、この組織のすべての公式言語で利用可能であり、提案に従って調整されています。2つ目は、中国と英語という1つの特徴を備えた直接のニュースコーパスであるため、さらに興味深いものです。英語からロシア語への最新の機械変換は非常に高品質であり、Amazon Translate、Google Translate、Bing、Yandexが使用されているため、この事実は気になりません。完全を期すために、何が起こったかの例を示します。
国連文書
.
它是一个低成本平台运转寿命较长且能在今后进一步发展。
.
报告特别详细描述了由参加者自己拟订的若干与该地区有关并涉及整个地区的项目计划。
UM-Corpus
Facebookは、1月初旬にLittle EyeLabsを購入する契約を締結しました。
1月初脸书完成了对リトル・アイ研究所的收购は、
バンガロールの4つのエンジニアは、年間約リトル・アイ研究所を立ち上げ半前
一年半以前四位工程师在班加罗尔创办了
当社は、モバイルアプリケーションのためのソフトウェアツールを構築します間$ 10〜$ 1,500万の費用がかかります。
该公司开发移动应用软件工具、这次交易价值1000年到1500万美元、
つまり、新しい要素は、OpenNMT +高品質のエンクロージャー+ BPEです(BPEのトークン化についてはこちらをご覧ください)。トレーニングを行い、コンテナに組み立て、デバッグ/クリーニングと標準的なトリックを行った後、BLEU 6.0を取得します(スケールはまだ100ポイントです)。
第4章平行原稿は燃えない
これまで、モデルを段階的に改善してきましたが、最大のメリットは、検証ドメインの1つであるニュースコーパスの使用によるものです。ニュースに加えて、一連の文献を入手するのもいいでしょう。 -それは人気のシステムで中国語の書籍の機械翻訳を提供できないことが明らかになったかなりの時間を過ごしたNastasiaは、のようなものになりNostosi FilipaunyとRogozhin - Rogoレンを。キャラクターの名前は通常、作品全体のかなり大きな割合を占めており、これらの名前はまれであることが多いため、モデルがそれらを一度も見たことがない場合は、正しく翻訳できない可能性があります。私たちは本から学ばなければなりません。
ここでは、翻訳のタスクをテキストの配置のタスクに置き換えます。私自身、言語や本や物語の並行テキストを勉強するのが好きなので、この部分が最も好きだったとすぐに言わなければなりません。私の意見では、これは最も生産的な学習方法の1つです。アラインメントにはいくつかのアイデアがありましたが、最も生産的なのは、文をベクトル空間に変換し、コンプライアンスの候補間の余弦距離を計算することでした。何かをベクトルに変換することを埋め込みと呼びます。この場合、それは文の埋め込みです。この目的に適したライブラリがいくつかあります[6]。結果を視覚化すると、ロシア語の複雑な文が中国語で2つか3つに翻訳されることが多いため、中国語のテキストが少しずれていることがわかります。
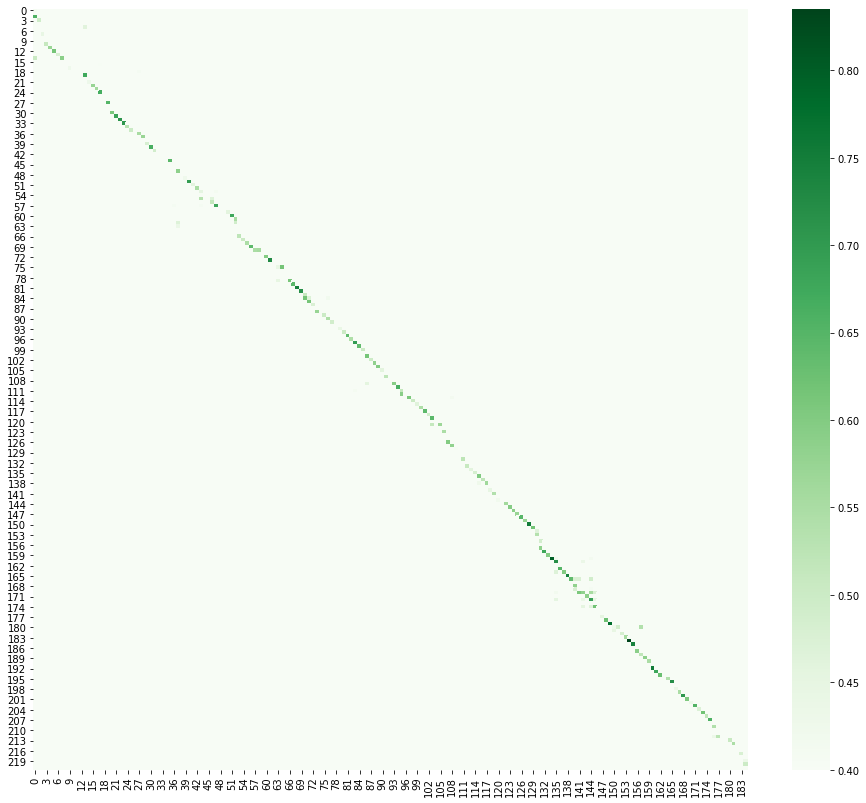
インターネット上で可能なすべてのものを見つけ、自分たちで本を平準化したら、それらをコーパスに追加します。
彼はスーツ、靴の色で、高価なグレーのスーツに外国人だった。
他穿一身昂贵的灰色西装、脚上的外国皮鞋也与西装颜色十分协调。
彼は有名な絞った、彼の耳の中に灰色のベレー帽を黒で杖を実施プードルヘッド。
头上一顶近無檐软箱望向一旁、圧到耳耳、、そう得整、人那么俏皮矫健他腋下顶夹着一根手杖、手杖顶端
彼女は40歳以上に見えます。
看模的年纪在四十開外。
新しい建物でトレーニングした後、BLEUはパブリックデータセットで20に、プライベートデータセットで19.7に成長しました。それはまた、検証からの作業が明らかにトレーニングに入ったという事実においても役割を果たしました。実際には、これは決して行われるべきではなく、リークと呼ばれ、メトリックは指標ではなくなります。
結論
機械変換は、ヒューリスティックおよび統計的手法からニューラルネットワークおよびトランスフォーマーへと長い道のりを歩んできました。このトピックに慣れる時間を見つけることができてうれしいです、それは間違いなくコミュニティからの細心の注意に値します。興味深いコミュニケーションと新しいアイデアを提供してくれたコンテストの作者と他の参加者に感謝します!
[1]ロシアと中国の並行コーパス
[2] MIPTからの自然言語処理に関するコース
[3]画期的な記事注意が必要なすべてです
[4] kaggleでの学習例を含むラップトップ
[5]パブリックドッカーベースライン
[6]多言語文のライブラリ埋め込み