
特定の領域専用のASICは、ムーアの法則を「再開」し、汎用CPUの制限を克服する1つの方法です。今では、マイクロエレクトロニクスの開発にとって非常に有望な分野です。 Google、Amazon、その他の企業には独自のプロジェクトがあります。たとえば、GoogleはGoogle TPU Tensor Processorsを作成し、AmazonデータセンターはARMコアでAWSGravitonチップを実行します。
前者はニューラルネットワーク用のASICであり、後者は計算集約型のワークロードで価格とパフォーマンスの比率を最適化するための汎用64ビットARMです。
最近活発な実験が行われている別のクラスの汎用ASICは、スマートネットワークカード(SmartNIC)の一種であるデータ処理専用のコプロセッサ(データ処理ユニット、DPU)です。この種のいくつかの例は、Nvidia BlueField 2、Fungible、PensandoDSC-25です。
彼らはどんな人ですか?それらはどのタスクに適していますか?見てみましょう。

SmartNICとは
従来のネットワークカード(NIC)は、イーサネットコントローラーとして動作するように設計された特殊用途の集積回路(ASIC)上に構築されています。多くの場合、これらのマイクロ回路は二次機能を実行するように設計されています。たとえば、MellanoxConnectXコントローラーは高速Infinibandプロトコルもサポートします。これらは優れた特殊チップですが、機能を変更することはできません。
単純なネットワークカードとは異なり、SmartNICを使用すると、ユーザーは追加のソフトウェアをコントローラーにダウンロードできます。つまり、ハードウェアを購入した後です。これにより、ASICの機能が拡張または変更されます。手順は、スマートフォンを購入してさまざまなアプリケーションをインストールするのと少し似ています。
これを可能にするために、SmartNICは従来のNICよりも多くの処理能力と追加のメモリを必要とします。より強力なマルチコアARMプロセッサ、特殊なネットワークプロセッサ(フロー処理コア、FPC)のインストール、およびフィールドプログラマブルゲートアレイ(FPGA)について説明しています。
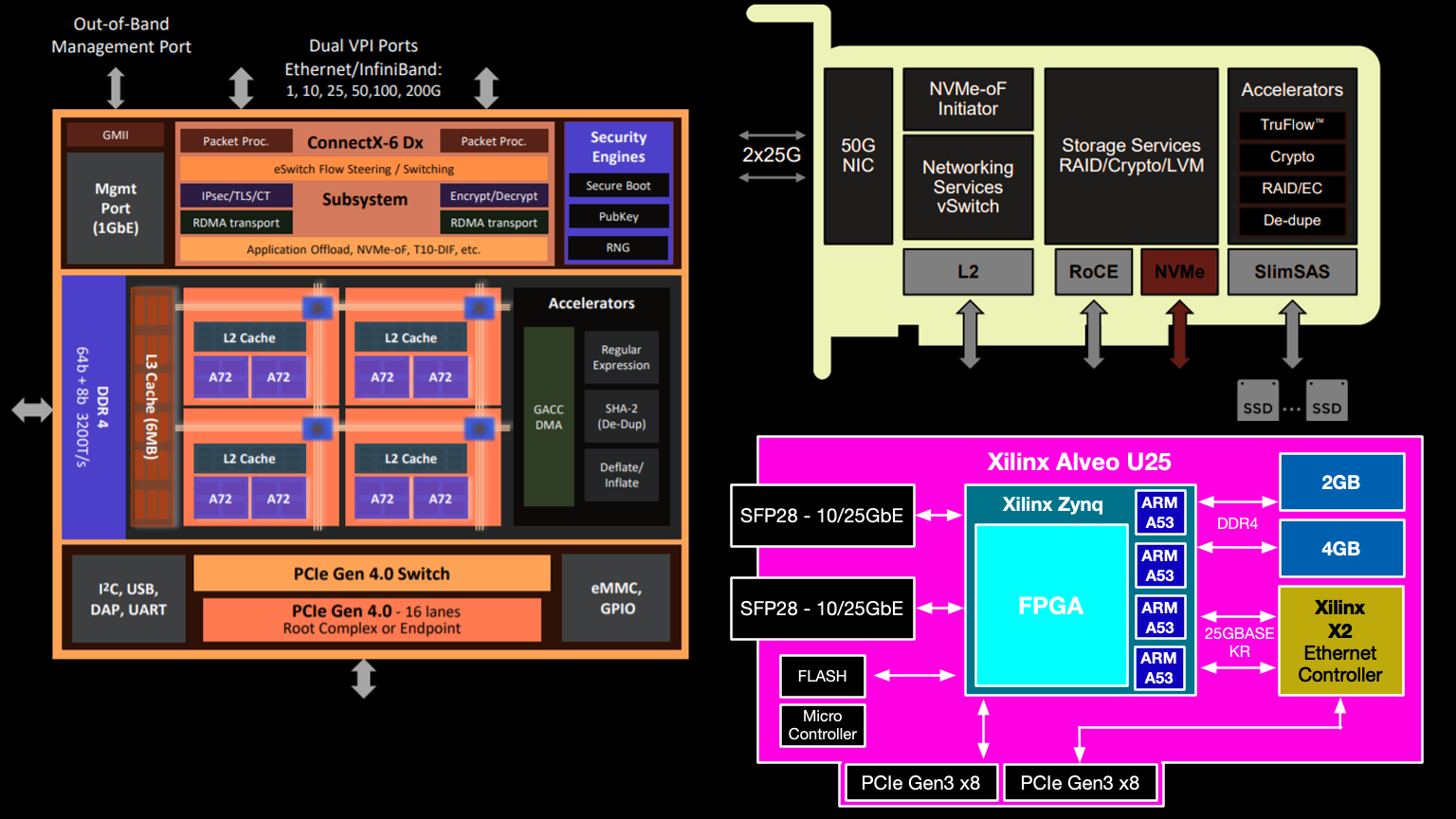
ザイリンクス
AlveoU25 Schematic SmartNICには、多くの場合、制御層用に個別のARMコアがあり、一部のボードでは、変更されたLinuxカーネルをロードできます。これらの専用ARMコアは、残りの計算モジュールに負荷を分散し、統計とログを収集し、SmartNICの状態を監視します。直接ネットワークトラフィックはそれらを通過しません。
DPUはどのようなタスクに適していますか?
データコプロセッサ(DPU)は、NVMeまたはNVMe over Fabrics(NVMe-oF)機能を追加するSmartNICの一般的な拡張機能です。このようなボードを使用すると、中央プロセッサをアンロードして、すべてのI / Oタスクを引き継ぐことができます。
たとえば、Broadcom NetXtreme-SBCM58800マイクロプロセッサのSmartNICデバイスについて考えてみます。プログラム可能なネットワークカードとして機能し、(NVMe-oF)をサポートします。
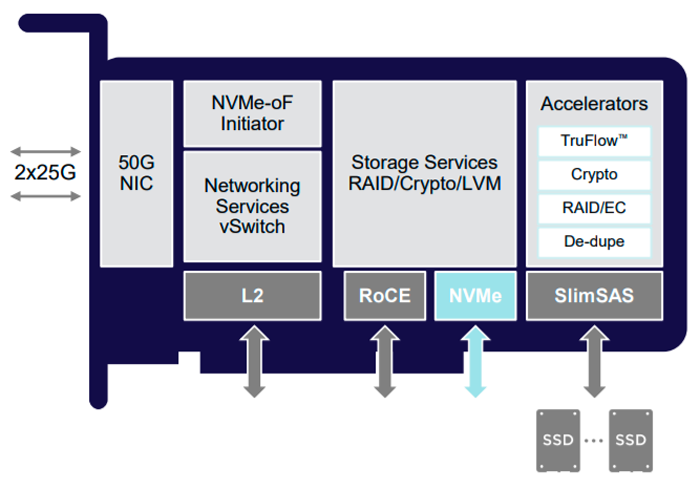
BCM58800マイクロプロセッサに基づくBroadcomStingrayカードのアーキテクチャ
Broadcom Stingrayには、3GHzで8つのARMv8 A72コアがあります。これは、SmartNIC上のARMの中でおそらく最高のクロック速度です。ネットワークカードには、最大16GBのDDR4メモリが付属しています。ハードウェアレベルで
最大90Gbpsの暗号化がサポートされ、一部のデータ処理機能がサポートされます。重複排除。RAID5およびRAID 6からエンコードが削除されます。この図は、TruFlowアクセラレータも示しています。これは、Open vSwitch(OvS)などを含むネットワーク操作のハードウェアアクセラレーションのためのBroadcom独自のテクノロジーです。
Nvidia BlueField 2
Nvidiaは伝統的にグラフィックアクセラレータを専門としてきましたが、今年は専門のチップメーカーであるMellanoxの70億ドルの買収を完了したため、現在、新しい分野であるデータセンターのHPC市場を真剣にターゲットにしています。
Mellanoxは、スマートネットワークカード開発のパイオニアの1つであり、データ処理ユニット(DPU)として販売されているBlueField 2ボードは、現在、主要製品と見なされています。
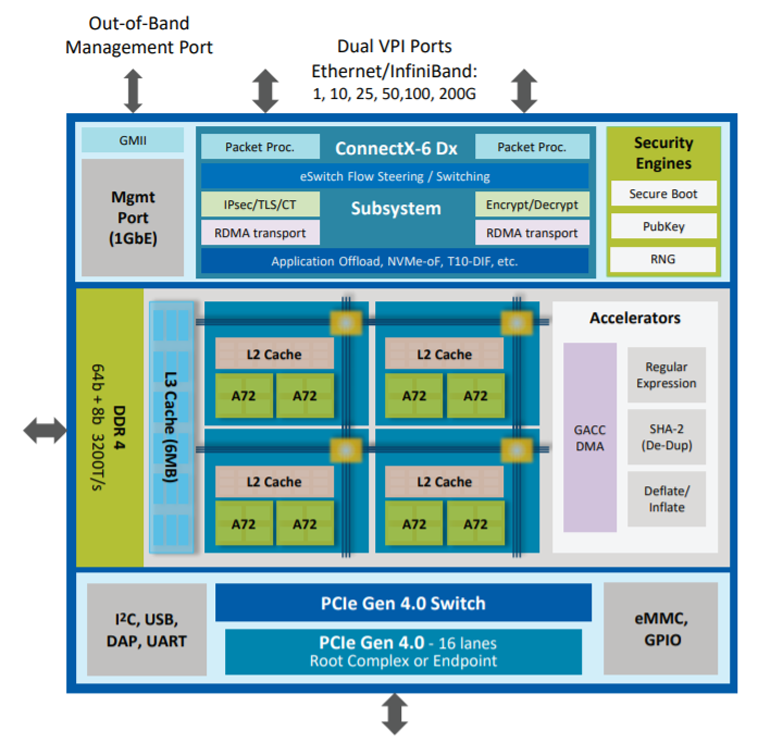
Nvidia / Mellanox BlueField 2アーキテクチャ
主要なDPUアプリケーション:
- 仮想クラウドとハードウェアクラウド。
- 仮想マシンのNVMeストレージ。
- ネットワーク機能仮想化(NFV)アプリケーション。
- ディープパケットインスペクション(DPI)などの情報セキュリティアプリケーション。
- エッジコンピューティング用のマイクロサーバー

Nvidia / Mellanox BlueField
28つのARMv8 A72コアのアレイ、DDR4メモリコントローラー、デュアルポートイーサネットまたはInfiniBandネットワークアダプター(100Gbpsで2つまたは200Gbpsで1つ)、およびさまざまな機能を高速化するための専用ASICを備えています。正規表現、SHA-2ハッシュなど。
ペンサンド
SmartNIC分野の新しいスタートアップの1つはPensandoで、いわゆる分散サービスカードを市場に提供しています。これらはPensando DSC-25(企業サーバー用)とPensando DSC-100(クラウドプロバイダー用)です。

PensandoDSC-25およびPensandoDSC-100
主な製品はPensandoDSC-25です。これは、データ処理用の1つのP4(Capri)DPU、追加のARMコア、および選択した機能用のハードウェアアクセラレータを備えたカードです。

Pensando DSC-25回路
メインのDPUコアとARMコアは、共通の相互接続バスを介してPCIeコントローラーとRAMのアレイ(最大4 GB)に接続されています。
個々のハードウェアアクセラレータは、ここではサービス処理オフロードと呼ばれます。Mellanoxカードと同様に、暗号化、ディスク処理、およびその他のタスクを処理します。
ファンジブル
Fungibleの高レベルアーキテクチャ
もう1つの新進気鋭のスタートアップであるFungibleは、 2016年にDPUという用語を作り出したと主張しています。同社はF1DPUと呼ばれるプロセッサを発表しましたが、これらのチップの実際のアーキテクチャは不明です。Fungibleは、上の図のように、現時点では一般的なスキームのみを示すことができます。一部の専門家は、Fungibleが単に誇大広告の用語DPUを使用してベンチャー資本投資を引き付けているのではないかという疑いを表明しています。ちなみに、すでに5億ドルがさまざまなラウンドで投資されています。
次は何ですか?
最近、DPUの概念について多くの誇大宣伝があります。このレビューでは、この市場に参入しようとしているすべての企業(Intel、ザイリンクスなど)が言及されているわけではありません。
事実、SmartNICの概念は長い間存在しており、GoogleやAmazonなどの大企業は独自の内部ソリューションを開発して実装しています。同時に、サードパーティのプレーヤーで埋め尽くされた市場が形成されました。
第2世代のFPGAベースのSmartNICが登場しています。ユーザーがプログラム可能なゲートアレイテクノロジーは成熟し、SmartNICの基盤テクノロジーになりました。 10年前、市場は文字通りグラフィックアクセラレータで溢れていました。これは、ハードウェアアクセラレーションテクノロジーの最初の重要な波でした。 FPGAが300万の論理ブロックマークを超えた今、これらのチップは、ネットワークトラフィック、メモリ、ストレージ、およびコンピューティングコアを処理するために他のビルディングブロックと緊密に統合されています。 SmartNICとFPGAテクノロジーは互いに完全に補完し合っています。
このような背景から、ハードウェアアクセラレータの第2の波が予想されます。次に、3番目の要素であるDPUがCPU + GPUセットに追加されます。データコプロセッサは、サーバープロセッサをインフラストラクチャタスクから解放します。調査によると、高度に仮想化された環境では、OvSトランザクションなどのネットワークプロセスがホストのCPU時間の30%以上を消費する可能性があります。別のモジュールで行われるディスク操作、暗号化、DPI、および複雑なルーティングを想像してみてください。これにより、CPUから負荷のかなりの部分が削除される可能性があります。
PensandoやFungibleのようなスタートアップは、ザイリンクス、インテル、ブロードコム、Nvidiaなどのテクノロジーリーダーとその革新に直面しています。これは常に見るのが楽しい技術的な競争です。