int main()
{
int n = 500000000;
int *a = new int[n + 1];
for (int i = 0; i <= n; i++)
a[i] = i;
for (int i = 2; i * i <= n; i++)
{
if (a[i]) {
for (int j = i*i; j <= n; j += i) {
a[j] = 0;
}
}
}
delete[] a;
return 0;
}これは特に実験用のシンプルなアプリケーションで、Eratosthenesのふるいを使用して素数を検索します。ソリューションを20回実行し、各実行のユーザー時間を計算してみましょう。
テストベンチの説明
i7-8750H @ 2,20
32 RAM
O:
Ubuntu 18.04.4
5.3.0-53-generic
32 RAM
O:
Ubuntu 18.04.4
5.3.0-53-generic
最適化前の実行時間のばらつき:
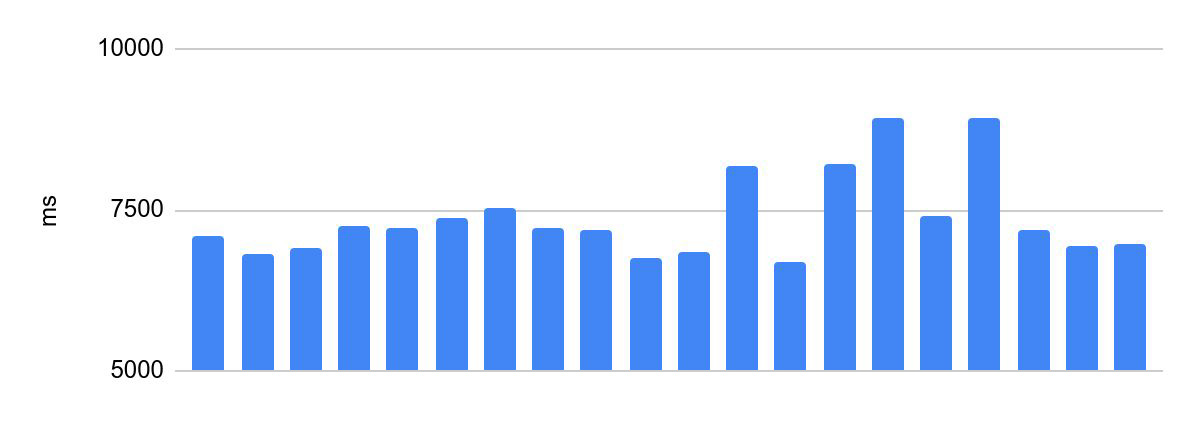
最も速い実行と最も遅い実行の差は2230ミリ秒です。
これは、オリンピックのプログラミングには受け入れられません。参加者のコードの実行時間は、彼のソリューションの成功の基準の1つであり、競争の条件の1つであり、賞品の分配はこれに依存します。したがって、このようなシステムには重要な要件があります。つまり、同じコードに対して同じ検証時間が必要です。以下では、これをコード実行の一貫性と呼びます。
実行時間を調整してみましょう。
コアの分離
明白なことから始めましょう。プロセスはコアをめぐって競合するため、ソリューションを実行するためにコアを何らかの方法で分離する必要があります。さらに、ハイパースレッドを有効にすると、オペレーティングシステムは、1つの物理プロセッサコアを2つの別個の論理コアとして定義します。コアを公平に分離するには、ハイパースレッドを無効にする必要があります。これは、BIOS設定で実行できます。
すぐに使用できるLinuxカーネルは、カーネルisolcpusを分離するための起動フラグをサポートしています。このフラグをgrub設定のGRUB_CMDLINE_LINUX_DEFAULTに追加します:/ etc / default / grub。例:
GRUB_CMDLINE_LINUX_DEFAULT="... isolcpus=0,1"
update-grubを実行し、システムを再起動します。
すべてが期待どおりに見えます-最初の2つのカーネルはシステムによって使用されません:

分離されたカーネルから始めましょう。CPUアフィニティ構成を使用すると、プロセスを特定のコアにバインドできます。これを行うにはいくつかの方法があります。たとえば、ポルトコンテナでソリューションを実行してみましょう(カーネルはcpu_set引数を使用して選択されます)。
portoctl exec test command='sudo stress.sh' cpu_set=0オフトップ:QEMU-KVMを使用して本番環境でソリューションを実行します。この記事では、見やすくするためにポルトコンテナを使用しています。
隣接するカーネルをロードせずに、ソリューション専用のカーネルで起動する:

違いは375ミリ秒です。良くなりましたが、それでも多すぎます。
Tyunimのパフォーマンス
ストレステストを試してみましょう。どれ?私たちのタスクは、すべてのコアに複数のスレッドをロードすることです。これはいくつかの方法で行うことができます。
- 多くのスレッドを作成し、それぞれのスレッドで何かを数え始める簡単なアプリケーションを作成します。
- :
cat /dev/zero | pbzip2 -c > /dev/null. pbzip2 — bzip2. - stress
stress --cpu 12.
ソリューション専用のコアを使用して起動し、隣接するコアに負荷をかけます

。違いは1354ミリ秒で、負荷がない場合より1秒長くなります。明らかに、分離されたカーネルで実行しているにもかかわらず、負荷が実行時間に影響を与えました。ある瞬間に実行時間が減少したことがわかります。一見すると、これは直感に反します。負荷が増えると、パフォーマンスも向上します。
本番環境では、この動作(実行時間が負荷の下で変動し始めるとき)は、発火するのに非常に苦痛になる可能性があります。この場合の負荷はどのくらいですか?参加者からの一連の決定。ほとんどの場合、主要な競技会やオリンピックで行われます。
その理由は、Intel TurboBoostが負荷の下でアクティブ化されるためです。これは周波数を上げるためのテクノロジーです。無効にします。私のスタンドでは、SpeedStepもオフにしました..。AMDプロセッサの場合、Turbo CoreCool'n'Quietをオフにする必要があります。上記はすべてBIOSで実行されます。主なアイデアは、プロセッサ周波数を自動的に制御するものを無効にすることです。
Turbo Boostを無効にして、隣接するコアにロードする分離コアで実行する:

見た目は良好ですが、違いは252ミリ秒です。そして、それはまだ多すぎます。
オフトップ:平均実行時間が約25%減少したことに注目してください。日常生活では、障害のあるテクノロジーは優れています。
コアの競合をなくし、コアの周波数を安定させました。今では何も影響しません。では、違いはどこから来るのでしょうか?
NUMA
不均一なメモリアクセス、または不均一なメモリアーキテクチャ、「不均一なメモリアーキテクチャ」。 NUMAシステム(つまり、従来、最新のマルチプロセッサコンピュータ)では、各プロセッサにローカルメモリがあり、これは全体の一部と見なされます。各プロセッサは、そのローカルメモリと他のプロセッサのローカルメモリ(リモートメモリ)の両方にアクセスできます。不均一性は、ローカルメモリへのアクセスが著しく高速になることです。
そのような凹凸のせいで、演奏時間はまさに「歩く」。実行を特定のnumaノードにバインドして修正しましょう。これを行うには、numaノードをportoコンテナ構成に追加します。
portoctl exec test command='stress.sh' cpu_set="node 0" cpu_set=0Turbo Boostが無効になっている分離コアで実行し、NUMA構成と隣接コアの負荷:
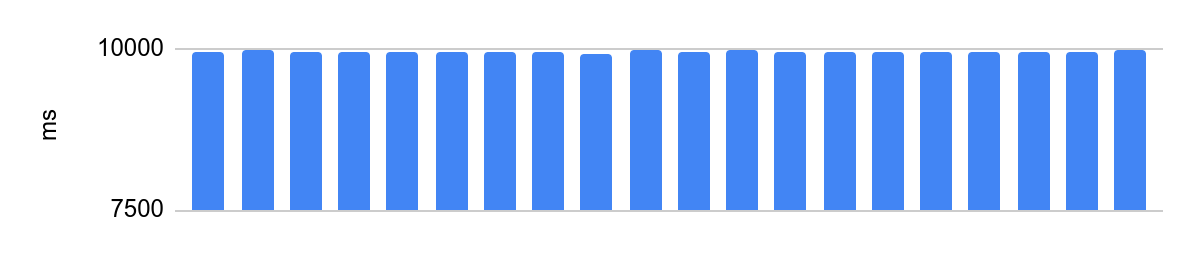
差は48ミリ秒で、プロセッサの最適化を無効にした後の平均実行時間は10秒です。10秒で48msは、0.5%のエラーに相当し、非常に良好です。
重要なネタバレ
isolcpusについてもう少し
isolcpusフラグには問題があります。一部のシステムスレッドは、引き続き分離されたカーネルにスケジュールできます。
したがって、本番環境では、このフラグの拡張機能を備えたパッチ付きカーネルを使用します。したがって、スレッドのスケジューリングが発生するときに、フラグを考慮してカーネルを選択します。
, 3.18. kthread_run, . CPU, isolcpus.
— slave_cpus , .
— slave_cpus , .
今後の計画
プール
一方の決定的なマシンが他方よりも強力である場合、コア分離の微調整は役に立ちません。その結果、実行時間に大きな違いが生じます。したがって、異種環境について考える必要があります。これまで、私たちは単に異質性をサポートしていませんでした。決定マシンのフリート全体に同じハードウェアが装備されています。しかし、近い将来、異なるハードウェアを同種のプールに分割し始め、各コンテストは同じハードウェアを備えた同じプール内で開催されます。
クラウドへの移行
システムの新しい課題は、Yandex.Cloudで起動する必要があることです。今日の基準では、鉄のサーバーは信頼性が低く、移動が必要ですが、小包の実行の一貫性を維持することが重要です。ここでは、技術的な可能性がまだ調査されています。極端な場合、クラウドマシンは厳密な実行時間を必要としないソリューションを実行できるという考えがあります。したがって、鉄製の機械の負荷を軽減し、一貫性が必要なソリューションのみを扱います。別のオプションがあります。最初にクラウドで小包をチェックし、制限時間に達していない場合は、実際のハードウェアで再チェックします。
統計の収集
すべての調整を行った後でも、プロセッサは必然的に抑制されます。悪影響を減らすために、ソリューションを並行して実行し、結果を比較して、異なる場合は再チェックを開始します。さらに、決定的なマシンの1つが絶えず劣化している場合、これはサービスを停止して理由に対処するための言い訳です。
結論
コンテストには特殊性があります。すべては、単にコードを実行して結果を取得することであるように思われるかもしれません。この記事では、このプロセスの1つの小さな側面のみを明らかにしました。サービスのすべてのレイヤーにこのようなものがあります。