について学んだ後、私はこの最適化をさまざまな数学的構造とそれらに定義された演算子に一般化することにしました。
KMathは、Kotlinのコンテキスト指向プログラミングを多用する数学およびコンピューター代数のライブラリです。KMathは、数学エンティティ(数値、ベクトル、行列)とそれらに対する操作を分離します。これらは、オペランドのタイプに対応する代数Algebra <T>という別個のオブジェクトとして提供されます。
import scientifik.kmath.operations.*
ComplexField {
(i pow 2) + Complex(1.0, 3.0)
}したがって、JVMの最適化を考慮して、バイトコードジェネレーターを作成した後、任意の数学オブジェクトの高速計算を取得できます。Kotlinでそれらの操作を定義するだけで十分です。
API
まず、式のAPIを開発してから、言語の文法と構文ツリーに進む必要がありました。また、より直感的なインターフェイスを提示するために、式自体に代数を定義するという巧妙なアイデアも思いつきました。
式API全体のベースはExpression <T>インターフェイスであり、これを実装する最も簡単な方法は、指定されたパラメーターまたはネストされた式などからinvokeメソッドを直接定義することです。最も遅いとはいえ、同様の実装が参照としてルートモジュールに統合されました。
interface Expression<T> {
operator fun invoke(arguments: Map<String, T>): T
}より高度な実装は、すでにMSTに基づいています。これらが含まれます:
- MST通訳、
- MSTクラスジェネレータ。
文字列からMSTに式を解析するためのAPIは、多かれ少なかれ最終的なJVMコードジェネレーターと同様に、KMathdevブランチですでに利用可能です。
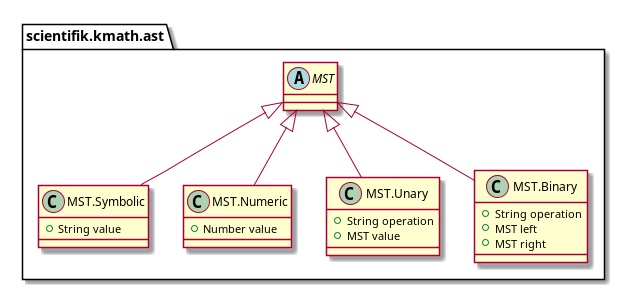
MSTに移りましょう。現在、MSTには4種類のノードがあります。
- ターミナル:
- シンボル(つまり変数)
- 数字;
- unary操作;
- バイナリ操作。
それを使って最初にできることは、バイパスして、利用可能なデータから結果を計算することです。ターゲット代数に操作のID(たとえば、「+」)と引数(たとえば、1.0および1.0)を渡すことにより、この操作が定義されている場合の結果を期待できます。それ以外の場合、評価されると、式は例外を除いて分類されます。

MSTを操作するために、式言語に加えて、代数もあります。たとえば、MstField:
import scientifik.kmath.ast.*
import scientifik.kmath.operations.*
import scientifik.kmath.expressions.*
RealField.mstInField { number(1.0) + number(1.0) }() // 2.0上記のメソッドの結果は、Expression <T>の実装であり、呼び出されると、mstInFieldに渡された関数を評価することによって取得されたツリーをトラバースします。
コードの生成
しかし、それだけではありません。トラバースするときに、ツリーパラメータを好きなように使用でき、アクションの順序や操作の多様性について心配する必要はありません。これは、バイトコードを生成するために使用されるものです。
kmath-astでのコード生成は、JVMクラスのパラメーター化されたアセンブリです。入力はMSTおよびターゲット代数であり、出力は式<T>インスタンスです。
対応するクラス、AsmBuilder、およびその他のいくつかの拡張機能は、ObjectWebASM上にバイトコードを強制的に構築するためのメソッドを提供します。これらにより、MSTトラバーサルとクラスアセンブリがきれいに見え、40行未満のコードで済みます。
式「2 * x」に対して生成されたクラスについて考えてみます。バイトコードから逆コンパイルされたJavaソースコードが表示されます。
package scientifik.kmath.asm.generated;
import java.util.Map;
import scientifik.kmath.asm.internal.MapIntrinsics;
import scientifik.kmath.expressions.Expression;
import scientifik.kmath.operations.RealField;
public final class AsmCompiledExpression_1073786867_0 implements Expression<Double> {
private final RealField algebra;
public final Double invoke(Map<String, ? extends Double> arguments) {
return (Double)this.algebra.add(((Double)MapIntrinsics.getOrFail(arguments, "x")).doubleValue(), 2.0D);
}
public AsmCompiledExpression_1073786867_0(RealField algebra) {
this.algebra = algebra;
}
}最初に、invokeメソッドがここで生成されました。ここでは、オペランドが順番に配置され(ツリーの奥深くにあるため)、次にadd呼び出しが行われます。呼び出し後、対応するブリッジメソッドが記録されました。次に、代数フィールドとコンストラクターが記述されました。場合によっては、定数をクラス定数のプールに単純に入れることができない場合、定数フィールドであるjava.lang.Object配列も書き込まれます。
ただし、多くのエッジケースと最適化のため、ジェネレータの実装はかなり複雑です。
代数への呼び出しの最適化
代数から操作を呼び出すには、そのIDと引数を渡す必要があります。
RealField { binaryOperation("+", 1.0, 1.0) } // 2.0ただし、このような呼び出しはパフォーマンスの点でコストがかかります。呼び出すメソッドを選択するために、RealFieldは比較的高価なtableswitchステートメントを実行します。また、ボクシングについても覚えておく必要があります。したがって、すべてのMST操作はこの形式で表すことができますが、直接呼び出すことをお勧めします。
RealField { add(1.0, 1.0) } // 2.0Algebra <T> 実装のメソッドへの操作IDのマッピングに関する特別な規則はないため、たとえば「+」がaddメソッドに対応するように手動で記述されたクラッチを挿入する必要がありました。同じ名前、必要な引数の数、およびそれらのタイプを持つ操作IDのメソッドを見つけることができる場合の好ましい状況もサポートされています。
private val methodNameAdapters: Map<Pair<String, Int>, String> by lazy {
hashMapOf(
"+" to 2 to "add",
"*" to 2 to "multiply",
"/" to 2 to "divide",
...private fun <T> AsmBuilder<T>.findSpecific(context: Algebra<T>, name: String, parameterTypes: Array<MstType>): Method? =
context.javaClass.methods.find { method ->
...
nameValid && arityValid && notBridgeInPrimitive && paramsValid
}もう1つの大きな問題はボクシングです。同じRealFieldをコンパイルした後に取得されるJavaメソッドシグネチャを見ると、次の2つのメソッドがあります。
public Double add(double a, double b)
// $FF: synthetic method
// $FF: bridge method
public Object add(Object var1, Object var2)もちろん、ボックス化とボックス化解除を気にせずにブリッジメソッドを呼び出す方が簡単です。add (T、T):Tメソッドを正しく実装するために、タイプの消去のためにここに表示されました。記述子のタイプTは実際にjava.langに消去されました。.Object。戻り値がボークサイトであるため、
2つのdoubleから直接addを呼び出すことも理想的ではありません(これについてはYouTrack Kotlin(KT-29460)で説明されていますが、入力オブジェクトの2つのキャストをせいぜいjava.langに保存するために呼び出す方がよいでしょう。.Numberとその箱から出して2倍にする。
この問題を解決するのに最も時間がかかりました。ここでの難しさは、プリミティブメソッドの呼び出しを作成することではなく、スタック上でプリミティブタイプ(doubleなど)とそのラッパー(java.lang.Doubleなど)の両方を組み合わせて、適切な場所にボックスを挿入する必要があるという事実です(たとえば、java.lang.Double.valueOf)およびunboxing(doubleValue)-バイトコードの命令タイプを操作する必要はまったくありませんでした。
入力した抽象化をバイトコードの上に掛けるというアイデアがありました。これを行うには、ObjectWeb ASMAPIをさらに深く掘り下げる必要がありました。 Kotlin / JVMバックエンドに目を向け、StackValueクラスを詳細に調べました。(バイトコードの型付きフラグメント。最終的にはオペランドスタックで何らかの値を受け取ることになります)、タイプユーティリティを理解しました。これにより、バイトコードで使用可能な型(プリミティブ、オブジェクト、配列)を簡単に操作し、ジェネレータを書き直すことができます。その使用で。スタック上の値をボックス化するかボックス化解除するかという問題は、次の呼び出しで予期されるタイプを格納するArrayDequeを追加することで解決されました。
internal fun loadNumeric(value: Number) {
if (expectationStack.peek() == NUMBER_TYPE) {
loadNumberConstant(value, true)
expectationStack.pop()
typeStack.push(NUMBER_TYPE)
} else ...?.number(value)?.let { loadTConstant(it) }
?: error(...)
}結論
最終的に、ObjectWebASMを使用してKMathのMST式を評価するコードジェネレーターを作成することができました。バイトコードは線形であり、ノードの選択と再帰に時間を浪費しないため、単純なMSTトラバーサルでのパフォーマンスの向上はノードの数に依存します。たとえば、ノードが10個の式の場合、生成されたクラスとインタープリターを使用した評価の時間差は19〜30%です。
私が遭遇した問題を調べた後、私は次の結論を出しました。
- ASMの機能とユーティリティをすぐに調べる必要があります。これらは開発を大幅に簡素化し、コードを読みやすくします(Type、InstructionAdapter、GeneratorAdapter)。
- MaxStack , , — ClassWriter COMPUTE_MAXS COMPUTE_FRAMES;
- ;
- , , , ;
- , — , , ByteBuddy cglib.
読んでくれてありがとう。
記事の著者:
Yaroslav Sergeevich Postovalov、MBOU「Lyceum№130にちなんで名付けられました アカデミーLavrentyev」、VoytishekアントンVatslavovichのリーダーシップの下で、数学的モデリングの研究室のメンバー
タチアナAbramova、研究者の核物理学実験の方法の研究室ではJetBrainsの研究。