
大きなテクスチャの問題
巨大なテクスチャをレンダリングするというアイデア自体は新しいものではありません。100万メガピクセルの巨大なテクスチャをロードし、それを使用してオブジェクトを描画する方が簡単なように思われます。しかし、いつものように、ニュアンスがあります:
- グラフィックAPIは、テクスチャの最大サイズの幅と高さを制限します。ハードウェアとドライバーの両方に依存する可能性があります。今日の最大サイズは32768x32768ピクセルです。
- これらの制限に達したとしても、32768x32768RGBAテクスチャは4ギガバイトのビデオメモリを必要とします。ビデオメモリは高速で、幅の広いバス上にありますが、比較的高価です。したがって、通常はシステムメモリよりも少なく、ディスクメモリよりもはるかに少なくなります。
1.大きなテクスチャの最新のレンダリング
画像が限界に収まらないため、解決策は自然にそれ自体を示唆します-それを断片(タイル)に分割するだけです:

このアプローチのさまざまなバリエーションが分析ジオメトリにまだ使用されています。これは普遍的なアプローチではありません。CPUで重要な計算が必要です。各タイルは個別のオブジェクトとして描画されます。これにより、オーバーヘッドが追加され、バイリニアテクスチャフィルタリングを適用する可能性が排除されます(タイルの境界間に目に見える線が表示されます)。ただし、テクスチャサイズの制限は、テクスチャ配列によって回避できます。はい、このテクスチャの幅と高さはまだ制限されていますが、追加のレイヤーが表示されています。レイヤーの数にも制限がありますが、2048を頼りにできます、火山の仕様は256しか約束していませんが、1060 GTXビデオカードでは、32768 * 32768 * 2048ピクセルを含むテクスチャを作成できます。8テラバイトを要し、ビデオメモリがそれほど多くないため、作成することはできません。ハードウェア圧縮ブロックBC1を適用すると、そのようなテクスチャは「たった」1テラバイトしか占有しません。それでもビデオカードには収まりませんが、それをどうするかについてさらに説明します。
そのため、元の画像を細かく分割します。しかし、今ではタイルごとに個別のテクスチャではなく、すべてのタイルを含む巨大なテクスチャ配列内のピースになります。各チャンクには独自のインデックスがあり、すべてのチャンクは順番に配置されます。最初に列、次に行、次にレイヤーで:
テストテクスチャのソースに関する小さな逸脱
たとえば、ここから地球の画像を撮りました。元のサイズ43200x2160を65536x32768に増やしました。もちろん、これは詳細を追加しませんでしたが、1つのテクスチャレイヤーに収まらない必要な画像を取得しました。次に、512 x 256ピクセルのタイルが得られるまで、バイリニアフィルタリングを使用して再帰的に半分に減らしました。次に、結果のレイヤーを512x256タイルにビートします。それらをBC1に圧縮し、ファイルに順番に書き込みました。このようなもの:
その結果、21845タイルで構成される1,431,633,920バイトのファイルが得られました。512 x256のサイズはランダムではありません。512 x 256 BC1圧縮イメージは正確に65536バイトです。これは、この記事の主人公であるスパースイメージのブロックサイズです。タイルサイズはレンダリングにとって重要ではありません。
大きなテクスチャをペイントするためのテクニックの説明
そこで、タイルが列/行/レイヤーに順番に配置されたテクスチャ配列をロードしました。
次に、このテクスチャを描画するシェーダーは次のようになります。
layout(set=0, binding=0) uniform sampler2DArray u_Texture;
layout(location = 0) in vec2 v_uv;
layout(location = 0) out vec4 out_Color;
int lodBase[8] = { 0, 1, 5, 21, 85, 341, 1365, 5461};
int tilesInWidth = 32768 / 512;
int tilesInHeight = 32768 / 256;
int tilesInLayer = tilesInWidth * tilesInHeight;
void main() {
float lod = log2(1.0f / (512.0f * dFdx(v_uv.x)));
int iLod = int(clamp(floor(lod),0,7));
int cellsSize = int(pow(2,iLod));
int tX = int(v_uv.x * cellsSize); //column index in current level of detail
int tY = int(v_uv.y * cellsSize); //row index in current level of detail
int tileID = lodBase[iLod] + tX + tY * cellsSize; //global tile index
int layer = tileID / tilesInLayer;
int row = (tileID % tilesInLayer) / tilesInWidth;
int column = (tileID % tilesInWidth);
vec2 inTileUV = fract(v_uv * cellsSize);
vec2 duv = (inTileUV + vec2(column,row)) / vec2(tilesInWidth,tilesInHeight);
out_Color = texelFetch(u_Texture,ivec3(duv * textureSize(u_Texture,0).xy,layer),0);
}
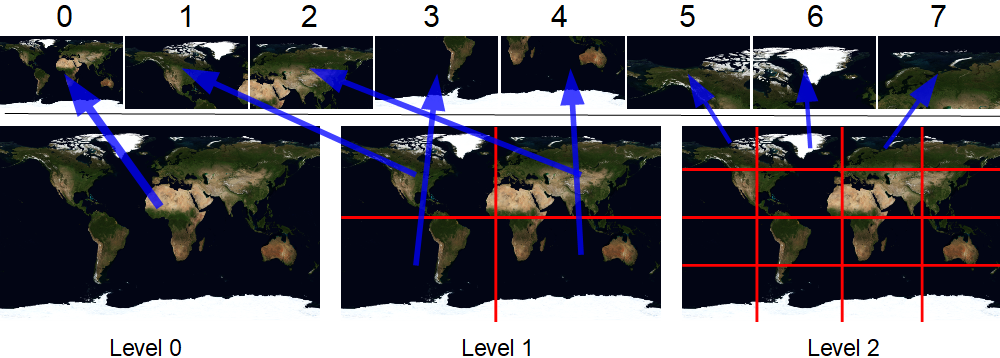
このシェーダーを見てみましょう。まず、選択する詳細レベルを決定する必要があります。素晴らしい関数dFdxがこれを助けてくれます。大幅に簡略化するために、渡された属性が隣接するピクセルで大きくなる値を返します。デモでは、0..1の範囲のテクスチャ座標を持つ平らな長方形を描画します。この長方形の幅がXピクセルの場合、dFdx(v_uv.x)は1 / Xを返します。したがって、最初のレベルのタイルは、dFdx == 1/512でピクセルごとに分類されます。 2番目は1 / 1024、3番目は1/2048などです。詳細レベル自体は次のように計算できます:log2(1.0f /(512.0f * dFdx(v_uv.x)))。それから部分的な部分を切り取りましょう。次に、レベル内の幅/高さのタイルの数を数えます。
例を使用して残りの計算を考えてみましょう:

ここで、lod = 2、u = 0.65、v = 0.37
です。lodは2に等しいため、cellsSizeは4に等しくなります。写真は、このレベルが16タイル(4行4列)で構成されていることを示しています-すべてが正しいです。
tX = int(0.65 * 4)= int(2.6)= 2
tY = int(0.37 * 4)= int(1.48)= 1
つまり、レベル内では、このタイルは3番目の列と2番目の行にあります(ゼロからのインデックス付け)。
フラグメントのローカル座標も必要です(図の黄色の矢印)。元のテクスチャ座標に行/列のセル数を掛けて小数部分をとるだけで簡単に計算できます。上記の計算では、それらはすでに存在しています-0.6と0.48。
次に、このタイルのグローバルインデックスが必要です。このために、lodBaseの事前計算された配列を使用します。以前のすべての(小さい)レベルにあったタイルの数の値をインデックスで保存します。レベル内のタイルのローカルインデックスを追加します。たとえば、lodBase [2] + 1 * 4 + 2 = 5 + 4 + 2 = 11であることがわかります。これも正しいです。
グローバルインデックスがわかったら、テクスチャ配列でタイルの座標を見つける必要があります。これを行うには、幅と高さに収まるタイルの数を知る必要があります。彼らの製品は、レイヤーに収まるタイルの数です。この例では、簡単にするために、これらの定数をシェーダーコードで直接ステッチしました。次に、テクスチャ座標を取得し、そこからテクセルを読み取ります。sampler2DArrayがサンプラーとして使用されることに注意してください。したがって、texelFetch 3番目の座標であるレイヤー番号に3成分ベクトルを渡します。
テクスチャが完全にロードされていません(部分的な常駐画像)
上で書いたように、巨大なテクスチャは多くのビデオメモリを消費します。さらに、このテクスチャから使用されるピクセルの数は非常に少なくなります。問題の解決策-パーシャルレジデンシーテクスチャは2011年に登場しました。その本質は簡単です-タイルは物理的にメモリにないかもしれません!同時に、仕様はアプリケーションがクラッシュしないことを保証し、すべての既知の実装はゼロが返されることを保証します。また、この仕様では、拡張機能がサポートされている場合、保証されているブロックサイズ(バイト単位)がサポートされることが保証されています(64キロバイト)。テクスチャ内のビルディングブロックの解像度は、次のサイズに関連付けられています。
| TEXEL SIZE(ビット) | ブロック形状(2D) | ブロック形状(3D) |
|---|---|---|
| ?4ビット? | ?512×256×1 | サポートしません |
| 8ビット | 256×256×1 | 64×32×32 |
| 16ビット | 256×128×1 | 32×32×32 |
| 32ビット | 128×128×1 | 32×32×16 |
| 64ビット | 128×64×1 | 32×16×16 |
| 128ビット | 64×64×1 | 16×16×16 |
実際、4ビットテクセルに関する仕様には何もありませんが、vkGetPhysicalDeviceSparseImageFormatPropertiesを使用していつでもそれらについて知ることができます。
VkSparseImageFormatProperties sparseProps;
ermy::u32 propsNum = 1;
vkGetPhysicalDeviceSparseImageFormatProperties(hphysicalDevice, VK_FORMAT_BC1_RGB_SRGB_BLOCK, VkImageType::VK_IMAGE_TYPE_2D,
VkSampleCountFlagBits::VK_SAMPLE_COUNT_1_BIT, VkImageUsageFlagBits::VK_IMAGE_USAGE_SAMPLED_BIT | VkImageUsageFlagBits::VK_IMAGE_USAGE_TRANSFER_DST_BIT
, VkImageTiling::VK_IMAGE_TILING_OPTIMAL, &propsNum, &sparseProps);
int pageWidth = sparseProps.imageGranularity.width;
int pageHeight = sparseProps.imageGranularity.height;
このようなまばらなテクスチャの作成は、通常のものとは異なります。
まず、VkImageCreateInfoのフラグでVK_IMAGE_CREATE_SPARSE_BINDING_BITおよびVK_IMAGE_CREATE_SPARSE_RESIDENCY_BITを指定する必要があります。次に、
メモリを介して結合する必要はありません。vkGetImageMemoryRequirementsを
使用して、使用できるメモリの種類を確認する必要があります。また、テクスチャ全体をロードするために必要なメモリ量もわかりますが、この数字は必要ありません。 代わりに、アプリケーションレベルで、同時に表示できるタイルの数を決定する必要がありますか?
一部のタイルをロードした後、他のタイルは不要になったため、アンロードされます。デモでは、空に指を向けて、124個のタイルにメモリを割り当てました。無駄に聞こえますが、完全にロードされたテクスチャの1.4GBに対して、わずか50メガバイトです。また、ステージングのために、ホストにメモリ(バッファ)を割り当てる必要があります。
const int sparseBlockSize = 65536;
int numHotPages = 512; //
VkMemoryRequirements memReqsOpaque;
vkGetImageMemoryRequirements(device, mySparseImage, &memReqsOpaque); // memoryTypeBits. -
VkMemoryRequirements image_memory_requirements;
image_memory_requirements.alignment = sparseBlockSize ; //
image_memory_requirements.size = sparseBlockSize * numHotPages;
image_memory_requirements.memoryTypeBits = memReqsOpaque.memoryTypeBits;
このようにして、一部のパーツのみがロードされる巨大なテクスチャが作成されます。次のようになります。

タイル管理
以下では、タイルという用語を使用してテクスチャの一部(図の濃い緑色と灰色の正方形)を示し、ページという用語をビデオメモリに事前に割り当てられた大きなブロックの一部(図の薄緑色と水色の長方形)を示します。
このようなまばらなVkImageを作成した後、シェーダーのVkImageViewを介して使用できます。もちろん、これは役に立ちません。サンプリングはゼロを返し、データはありませんが、通常のVkImageとは異なり、何も落ちず、デバッグレイヤーは誓約しません。ビデオメモリを節約するため、このテクスチャへのデータはロードするだけでなく、アンロードする必要があります。
各ブロックのドライバーによるメモリの割り当てを提供するOpenGLアプローチは、私には正しくないようです。はい、ブロックサイズが固定されているため、賢くて高速なアロケーターが使用されている可能性があります。これは、火山のまばらな居住テクスチャの例で同様のアプローチが使用されているという事実によって示唆されています。ただし、いずれの場合も、ページの大きな線形ブロックを選択し、アプリケーション側で、これらのページを特定のテクスチャタイルにバインドして、データで埋めるのが遅くなることはありません。
したがって、スパーステクスチャのインターフェイスには、次のようなメソッドが含まれます。
void CommitTile(int tileID, void* dataPtr); // 64
void FreeTile(int tileID);
void Flush();
最後の方法は、タイルの充填/解放をグループ化するために必要です。タイルを一度に1つずつ更新すると、フレームごとに1回だけ、非常にコストがかかります。それらを順番に整理してみましょう。
//void CommitTile(int tileID, void* dataPtr)
int freePageID = _getFreePageID();
if (freePageID != -1)
{
tilesByPageIndex[freePageID] = tileID;
tilesByTileID[tileID] = freePageID;
memcpy(stagingPtr + freePageID * pageDataSize, tileData, pageDataSize);
int pagesInWidth = textureWidth / pageWidth;
int pagesInHeight = textureHeight / pageHeight;
int pagesInLayer = pagesInWidth * pagesInHeight;
int layer = tileID / pagesInLayer;
int row = (tileID % pagesInLayer) / pagesInWidth;
int column = tileID % pagesInWidth;
VkSparseImageMemoryBind mbind;
mbind.subresource.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
mbind.subresource.mipLevel = 0;
mbind.subresource.arrayLayer = layer;
mbind.extent.width = pageWidth;
mbind.extent.height = pageHeight;
mbind.extent.depth = 1;
mbind.offset.x = column * pageWidth;
mbind.offset.y = row * pageHeight;
mbind.offset.z = 0;
mbind.memory = optimalTilingMem;
mbind.memoryOffset = freePageID * pageDataSize;
mbind.flags = 0;
memoryBinds.push_back(mbind);
VkBufferImageCopy copyRegion;
copyRegion.bufferImageHeight = pageHeight;
copyRegion.bufferRowLength = pageWidth;
copyRegion.bufferOffset = mbind.memoryOffset;
copyRegion.imageExtent.depth = 1;
copyRegion.imageExtent.width = pageWidth;
copyRegion.imageExtent.height = pageHeight;
copyRegion.imageOffset.x = mbind.offset.x;
copyRegion.imageOffset.y = mbind.offset.y;
copyRegion.imageOffset.z = 0;
copyRegion.imageSubresource.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
copyRegion.imageSubresource.baseArrayLayer = layer;
copyRegion.imageSubresource.layerCount = 1;
copyRegion.imageSubresource.mipLevel = 0;
copyRegions.push_back(copyRegion);
return true;
}
return false;
まず、空きブロックを見つける必要があります。これらの同じページの配列を調べて、スタブ番号-1を含む最初のページを探します。これが無料ページのインデックスになります。 memcpyを使用して、ディスクからステージングバッファにデータをコピーします。ソースは、特定のタイルのオフセットを持つメモリマップファイルです。さらに、タイルのIDによって、テクスチャ配列内のタイルの位置(x、y、レイヤー)を考慮します。
次に、最も興味深い部分が始まります-VkSparseImageMemoryBind構造を入力します。ビデオメモリをタイルにバインドするのは彼女です。その重要なフィールドは次のとおり
です。メモリ。これはVkDeviceMemoryオブジェクトです。すべてのページにメモリを事前に割り当てました。
memoryOffset。これは、必要なページへのバイト単位のオフセットです。
次に、ステージングバッファからこの新しくバインドされたメモリにデータをコピーする必要があります。これは、vkCmdCopyBufferToImageを使用して行われます。
一度に多くのセクションをコピーするので、この場所では、コピーする場所と場所の説明を含む構造のみを入力します。ここで、bufferOffsetは重要です。これは、ステージングバッファにすでにあるオフセットを示します。この場合、ビデオメモリのオフセットと一致しますが、戦略は異なる場合があります。たとえば、タイルをホット、ウォーム、コールドに分割します。ホットなものはビデオメモリにあり、ウォームなものは操作メモリにあり、コールドなものはディスクにあります。その場合、ステージングバッファーを大きくすることができ、オフセットが異なります。
//void FreeTile(int tileID)
if (tilesByTileID.count(tileID) > 0)
{
i16 hotPageID = tilesByTileID[tileID];
int pagesInWidth = textureWidth / pageWidth;
int pagesInHeight = textureHeight / pageHeight;
int pagesInLayer = pagesInWidth * pagesInHeight;
int layer = tileID / pagesInLayer;
int row = (tileID % pagesInLayer) / pagesInWidth;
int column = tileID % pagesInWidth;
VkSparseImageMemoryBind mbind;
mbind.memory = optimalTilingMem;
mbind.subresource.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
mbind.subresource.mipLevel = 0;
mbind.subresource.arrayLayer = layer;
mbind.extent.width = pageWidth;
mbind.extent.height = pageHeight;
mbind.extent.depth = 1;
mbind.offset.x = column * pageWidth;
mbind.offset.y = row * pageHeight;
mbind.offset.z = 0;
mbind.memory = VK_NULL_HANDLE;
mbind.memoryOffset = 0;
mbind.flags = 0;
memoryBinds.push_back(mbind);
tilesByPageIndex[hotPageID] = -1;
tilesByTileID.erase(tileID);
return true;
}
return false;
ここで、メモリをタイルから切り離します。これを行うには、メモリVK_NULL_HANDLEを割り当てます。
//void Flush();
cbuff = hostDevice->CreateOneTimeSubmitCommandBuffer();
VkImageSubresourceRange imageSubresourceRange;
imageSubresourceRange.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
imageSubresourceRange.baseMipLevel = 0;
imageSubresourceRange.levelCount = 1;
imageSubresourceRange.baseArrayLayer = 0;
imageSubresourceRange.layerCount = numLayers;
VkImageMemoryBarrier bSamplerToTransfer;
bSamplerToTransfer.sType = VK_STRUCTURE_TYPE_IMAGE_MEMORY_BARRIER;
bSamplerToTransfer.pNext = nullptr;
bSamplerToTransfer.srcAccessMask = 0;
bSamplerToTransfer.dstAccessMask = VK_ACCESS_TRANSFER_WRITE_BIT;
bSamplerToTransfer.oldLayout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL;
bSamplerToTransfer.newLayout = VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL;
bSamplerToTransfer.srcQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bSamplerToTransfer.dstQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bSamplerToTransfer.image = opaqueImage;
bSamplerToTransfer.subresourceRange = imageSubresourceRange;
VkSparseImageMemoryBindInfo imgBindInfo;
imgBindInfo.image = opaqueImage;
imgBindInfo.bindCount = memoryBinds.size();
imgBindInfo.pBinds = memoryBinds.data();
VkBindSparseInfo sparseInfo;
sparseInfo.sType = VK_STRUCTURE_TYPE_BIND_SPARSE_INFO;
sparseInfo.pNext = nullptr;
sparseInfo.waitSemaphoreCount = 0;
sparseInfo.pWaitSemaphores = nullptr;
sparseInfo.bufferBindCount = 0;
sparseInfo.pBufferBinds = nullptr;
sparseInfo.imageOpaqueBindCount = 0;
sparseInfo.pImageOpaqueBinds = nullptr;
sparseInfo.imageBindCount = 1;
sparseInfo.pImageBinds = &imgBindInfo;
sparseInfo.signalSemaphoreCount = 0;
sparseInfo.pSignalSemaphores = nullptr;
VkImageMemoryBarrier bTransferToSampler;
bTransferToSampler.sType = VK_STRUCTURE_TYPE_IMAGE_MEMORY_BARRIER;
bTransferToSampler.pNext = nullptr;
bTransferToSampler.srcAccessMask = 0;
bTransferToSampler.dstAccessMask = VK_ACCESS_SHADER_READ_BIT;
bTransferToSampler.oldLayout = VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL;
bTransferToSampler.newLayout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL;
bTransferToSampler.srcQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bTransferToSampler.dstQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bTransferToSampler.image = opaqueImage;
bTransferToSampler.subresourceRange = imageSubresourceRange;
vkQueueBindSparse(graphicsQueue, 1, &sparseInfo, fence);
vkWaitForFences(device, 1, &fence, true, UINT64_MAX);
vkResetFences(device, 1, &fence);
vkCmdPipelineBarrier(cbuff, VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT, VK_PIPELINE_STAGE_TRANSFER_BIT, 0, 0, nullptr, 0, nullptr, 1, &bSamplerToTransfer);
if (copyRegions.size() > 0)
{
vkCmdCopyBufferToImage(cbuff, stagingBuffer, opaqueImage, VkImageLayout::VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL, copyRegions.size(), copyRegions.data());
}
vkCmdPipelineBarrier(cbuff, VK_PIPELINE_STAGE_TRANSFER_BIT, VK_PIPELINE_STAGE_FRAGMENT_SHADER_BIT, 0, 0, nullptr, 0, nullptr, 1, &bTransferToSampler);
hostDevice->ExecuteCommandBuffer(cbuff);
copyRegions.clear();
memoryBinds.clear();
主な作業はこの方法で行われます。その呼び出しの時点で、VkSparseImageMemoryBindとVkBufferImageCopyを持つ2つの配列がすでにあります。vkQueueBindSparseを呼び出すための構造を入力し、それを呼び出します。これは(Vulkanのほとんどすべての関数のように)ブロッキング関数ではないため、実行されるまで明示的に待機する必要があります。このために、最後のパラメーターがVkFenceに渡され、その実行が待機されます。実際、私の場合、このフェンスを待ってもプログラムのパフォーマンスにはまったく影響しませんでした。しかし、理論的には、ここで必要です。
タイルにメモリを付けたら、写真を記入する必要があります。これは、vkCmdCopyBufferToImage関数を使用して実行されます。
レイアウトを使用してデータをテクスチャに入力できますVK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL、およびレイアウトVK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMALのシェーダーにそれらを取得します。したがって、2つの障壁が必要です。であることに注意してくださいVK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL我々はより厳密に翻訳しVK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL、ないからVK_IMAGE_LAYOUT_UNDEFINED。テクスチャの一部のみを塗りつぶしているので、以前に塗りつぶした部分を失わないことが重要です。
これがその仕組みのビデオです。 1つのテクスチャ。 1つのオブジェクト。何万ものタイル。
舞台裏に残っているのは、どのタイルをロードする時間で、どのタイルをアンロードするかを実際に見つける方法をアプリケーションで決定する方法です。新しいアプローチの利点を説明するセクションで、ポイントの1つは、複雑なジオメトリを使用できることでした。同じテストで、私自身、最も単純な正射投影と長方形を使用します。そして、私は分析的にタイルのIDを数えます。スポーツマンらしくない。
実際、表示されているタイルのIDは2回カウントされます。分析的にはCPUで、正直に言ってフラグメントシェーダーで。フラグメントシェーダーからそれらを拾ってみませんか?しかし、それはそれほど単純ではありません。これは2番目の記事になります。