プロジェクトは成長し、ライブラリは現在、ロシアの自然言語を処理するすべての基本的なタスクを解決しています。トークンと文へのセグメンテーション、形態学的および構文的分析、レンマ化、名前付きエンティティの抽出です。

ニュース記事の場合、すべてのタスクの品質は既存のソリューションと同等またはそれ以上です。..。たとえば、NatashaはDeeppavlov BERT NER(F1 PER 0.97、LOC 0.91、ORG 0.85)よりも1パーセントポイント悪いNERタスクに対処し、モデルの重量は75分の1(27MB)で、CPU上で2倍高速(25記事/秒)で実行されます。 )GPUのBERTNERより。
プロジェクトには9つのリポジトリがあり、Natashaライブラリはそれらを1つのインターフェイスに結合します。この記事では、新しいツールについて説明し、それらを既存のソリューション(Deeppavlov、SpaCy、UDPipe)と比較します。

このロングリードの前に、natasha.github.ioに一連の投稿がありました。以下のテキストのサイズに不安がある場合は、ナターシャプロジェクトの歴史についてのチューブストリームの最初の20分間をご覧ください。短い説明があります:
- ナターシャ-ロシア語用の高品質コンパクトNER
- Navec-ロシア語用のコンパクトな埋め込み
- コーラス-ロシア語のNLPデータセットのコレクション
- Razdel-ロシア語のテキストをトークンとオファーに分割
- Naeval-ロシア語を話すNLPのシステムの定量的比較
- Nerusは、形態、構文、名前付きエンティティのマークアップを備えた大規模な合成ロシア語データセットです。
テキストはt.me/natural_language_processingチャットからのメモとディスカッションを使用し、新しい資料へのリンクは同じ場所に表示されます。
- ナターシャがトランスフォーマーを使用していない理由。100行のBERT
- SlovnetBERTモデル
- ナターシャプロジェクトの歴史についてのチューブストリーム
- Yargyドキュメントを更新
- Yargyパーサーに関する追加リソース
もっと聞きたい人は、Datafest 2020での毎時のトークをチェックしてください、それはほとんどこの投稿をカバーしています:
コンテンツ:
- Natasha — .
- Razdel —
- Slovnet — deep learning
- Navec —
- Nerus — ,
- Corus — +
- Naeval — NLP
- Yargy- —
- Ipymarkup —
Natasha — .

以前、Natashaライブラリはロシア語のNER問題を解決し、ルールに基づいて構築され、平均的な品質とパフォーマンスを示しました。現在、ナターシャは全体として大きなプロジェクトであり、9つのリポジトリで構成されています。Natashaライブラリは、それらを1つのインターフェイスに統合し、自然なロシア語を処理する基本的なタスクを解決します。トークンと文へのセグメンテーション、事前にトレーニングされた埋め込み、形態と構文の分析、レンマ化、NERです。すべてのソリューションはニューストピックで最高の結果を示し、CPUで高速に実行されます。
ナターシャは他のコンバインライブラリに似ています:SpaCy、UDPipe、Stanza..。SpaCyはモデルを初期化して暗黙的に呼び出し、ユーザーはテキストをマジック関数
nlpに渡し、完全に解析されたドキュメントを取得します。
import spacy
# load ,
# , NER
nlp = spacy.load('...')
# ,
text = '...'
doc = nlp(text)
ナターシャのインターフェースはより冗長です。ユーザーはコンポーネントを明示的に初期化します。事前にトレーニングされた埋め込みをロードし、モデルコンストラクターに渡します。サムは、メソッドを呼び出し
segment、tag_morph、parse_syntax形態や構文の解析、トークンと需要へのセグメンテーション。
>>> from natasha import (
Segmenter,
NewsEmbedding,
NewsMorphTagger,
NewsSyntaxParser,
Doc
)
>>> segmenter = Segmenter()
>>> emb = NewsEmbedding()
>>> morph_tagger = NewsMorphTagger(emb)
>>> syntax_parser = NewsSyntaxParser(emb)
>>> text = ' , , 2019 () ...'
>>> doc = Doc(text)
>>> doc.segment(segmenter)
>>> doc.tag_morph(morph_tagger)
>>> doc.parse_syntax(syntax_parser)
>>> sent = doc.sents[0]
>>> sent.morph.print()
NOUN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
PROPN|Animacy=Inan|Case=Gen|Gender=Masc|Number=Sing
ADP
PROPN|Animacy=Inan|Case=Loc|Gender=Fem|Number=Sing
PROPN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
PROPN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
...
>>> sent.syntax.print()
┌──► nsubj
│
│ ┌► case
│ └─
│ ┌─
│ └► flat:name
┌─────┌─└───
│ │ ┌──► , punct
│ │ │ ┌► mark
│ └►└─└─ ccomp
│ │ ┌► case
│ └──►└─ obl
...
名前付きエンティティエクストラクタは、形態学的および解析の結果に依存せず、個別に使用できます。
>>> from natasha import NewsNERTagger
>>> ner_tagger = NewsNERTagger(emb)
>>> doc.tag_ner(ner_tagger)
>>> doc.ner.print()
, ,
LOC──── LOC──── PER───────
2019
LOC──────────────
()
LOC─── ORG───────────────────────────────────────
...
PER────────────
ナターシャは、見出し語処理の問題を解決使用しPymorphy2と形態素解析の結果を。
>>> from natasha import MorphVocab
>>> morph_vocab = MorphVocab()
>>> for token in doc.tokens:
>>> token.lemmatize(morph_vocab)
>>> {_.text: _.lemma for _ in doc.tokens}
{'': '',
'': '',
'': '',
'': '',
'': '',
'': '',
'': '',
',': ',',
'': '',
'': ''
...
フレーズを通常の形にするためには、個々の単語の補題を見つけるだけでは十分ではありません。ロシア外務省にとっては、ロシア外務省、ウクライナ国民主義者組織、つまりウクライナ国民主義組織であることが判明します。ナターシャは、解析の結果を使用し、単語間の関係を考慮し、名前付きエンティティを正規化します。
>>> for span in doc.spans:
>>> span.normalize(morph_vocab)
>>> {_.text: _.normal for _ in doc.spans}
{'': '',
'': '',
' ': ' ',
' ': ' ',
'': '',
' ()': ' ()',
' ': ' ',
...
ナターシャは、テキスト内の名前、組織、場所の名前を見つけます。ライブラリ内の名前については、Yargyパーサーの既成のルールのセットがあり、モジュールは正規化された名前を部分に分割し、「ViktorFedorovichYushchenko」から取得し
{first: , last: , middle: }ます。
>>> from natasha import (
PER,
NamesExtractor,
)
>>> names_extractor = NamesExtractor(morph_vocab)
>>> for span in doc.spans:
>>> if span.type == PER:
>>> span.extract_fact(names_extractor)
>>> {_.normal: _.fact.as_dict for _ in doc.spans if _.type == PER}
{' ': {'first': '', 'last': ''},
' ': {'first': '', 'last': ''},
' ': {'first': '', 'last': ''},
'': {'last': ''},
' ': {'first': '', 'last': ''}}
ライブラリには、日付、金額、住所を解析するためのルールが含まれています。これらは、ドキュメントとリファレンスブックに記載されています。
ナターシャライブラリは、教育で使用されるプロジェクトテクノロジーのデモンストレーションに最適です。モデルの重みを持つアーカイブはパッケージに組み込まれています。インストール後、何もダウンロードして構成する必要はありません。
Natashaは、他のプロジェクトライブラリを1つのインターフェイスに統合します。実際の問題を解決するには、それらを直接使用する必要があります。
- Razdel-テキストを文とトークンに分割します。
- Navec-高品質のコンパクトな埋め込み。
- Slovnet-形態、構文、NERの最新のコンパクトモデル。
- Yargy-構造化された情報を抽出するためのルールと語彙。
- Ipymarkup -NERと構文マークアップの視覚化。
- コーラス-ロシア語の公開データセットへのリンクのコレクション。
- Nerusは、名前付きエンティティ、形態、および構文の自動マークアップを備えた大きなコーパスです。
Razdel-ロシア語のテキストをトークンとオファーに分割

RazdelライブラリはNatashaプロジェクトの一部であり、ロシア語のテキストをトークンと文に分割します。Razdelリポジトリでのインストール手順、使用例、およびパフォーマンス測定。
>>> from razdel import tokenize, sentenize
>>> text = '- 0.5 (50/64 ³, 516;...)'
>>> list(tokenize(text))
[Substring(start=0, stop=13, text='-'),
Substring(start=14, stop=16, text=''),
Substring(start=17, stop=20, text='0.5'),
Substring(start=20, stop=21, text=''),
Substring(start=22, stop=23, text='(')
...]
>>> text = '''
... - " ?" - " --".
... . . . . ,
... '''
>>> list(sentenize(text))
[Substring(start=1, stop=23, text='- " ?"'),
Substring(start=24, stop=40, text='- " --".'),
Substring(start=41, stop=56, text=' . . . .'),
Substring(start=57, stop=76, text=' , ')]
最近のモデルは、セグメンテーションを気にせず、BPEを使用し、驚くべき結果を示し、GPTとBERT動物園のすべてのバージョンを覚えていることがよくあります。ナターシャは、形態と構文の解析の問題を解決します。これらは、1つの文内の別々の単語に対してのみ意味があります。したがって、私たちは責任を持ってセグメンテーションの段階に近づき、人気のあるオープンデータセット(SynTagRus、OpenCorpora、GICRYA)からマークアップを繰り返そうとします。
Razdelの速度と品質は、ロシア語の他のオープンソースソリューションと同等かそれ以上です。
| トークンセグメンテーションソリューション | 1000トークンあたりのエラー | 処理時間、秒 |
| Regexp-ベースライン | 19 | 0.5 |
| SpaCy
|
17 | 5.4 |
| NLTK
|
130 | 3.1 |
| MyStem
|
19 | 4.5 |
| モーセ
|
十一 | 1.9 |
| SegTok
|
12 | 2.1 |
| SpaCy Russian Tokenizer
|
8 | 46.4 |
| RuTokenizer
|
15 | 1.0 |
| Razdel
|
7 | 2.6 |
| 1000 | , | |
| Regexp-baseline | 76 | 0.7 |
| SegTok
|
381 | 10.8 |
| Moses
|
166 | 7.0 |
| NLTK
|
57 | 7.1 |
| DeepPavlov
|
41 | 8.5 |
| Razdel | 43 | 4.8 |
SynTagRus、OpenCorpora、GICRYA、RNCの4つのデータセットの平均エラー数。詳細については、Razdelリポジトリをご覧ください。
通常の線のベースラインが同様の品質を提供し、ロシア語用の既製のソリューションがたくさんあるのに、なぜRazdelが必要なのですか?実際、Razdelは単なるトークナイザーではなく、小さなルールベースのセグメンテーションエンジンです。セグメンテーションは基本的なタスクであり、実際によく発生します。たとえば、司法行為があり、その中の運用部分を強調表示し、それを段落に分割する必要があります。当然のことながら、既製のソリューションではそれができません。ソースコードで独自のルールを作成する方法をお読みください。さらに、自分自身をプッシュし、エンジンでトークンとオファーのトップソリューションを作成する方法について説明します。
難しさは何ですか?
ロシア語では、文は通常、ピリオド、疑問符、または感嘆符で終わります。テキストを通常の式で分割してみましょう
[.?!]\s+。このソリューションでは、1000文あたり76エラーが発生します。間違いの種類と例:
略語
... 3,000人以上の視聴者がいるプラットフォームはブロガーです。
... 17世紀の終わりからビートが彼らの上に立っていました。
…▒B.A。にちなんで名付けられたChamberMusicalTheaterでポクロフスキー。
イニシャル
V.A.▒Mozart-R.▒Straussによるオペラ「Idomeneo」に続く...
リスト
2.フィンランド領事館には美しい長い列があると思いました...
g 。ロシアの鉄道の列車のチケット...
文の終わりに、笑顔または活字の省略記号
マイナスを取り除く方法を提供する人は誰でも-そのおかげで:)▒私は見た、思慮深い...▒コンテンツが壊れてしまうので、これはもっと不快です。
引用、直接スピーチ、文末に引用マーク
-あなたは町に花嫁がいますか?」▒「誰のために花嫁がいますか?」
「それは私がそのようではないほど良いです!」▒今、翻訳中に、私はフロイトの間違いを犯しました:「idology」。
Razdelはこれらのニュアンスを考慮に入れ、エラーの数を1000文あたり76から43に減らします。
状況はトークンでも同様です。優れた基本的な解決策はregexで
[--]+|[0-9]+|[^-0-9 ]、1000トークンあたり19エラーになります。例:
分数、複雑な句読点
... 1980年代後半から1990年代初頭
...BS-▒3の質量はわずかに少ない(3▒、▒6t)
-そして彼女は▒.▒死んだ。鷹、女の子が分かりますか?▒!
Razdelは、エラー率を1000トークンあたり7に減らしています。
動作原理
システムはルールに基づいて構築されています。トークンとオファーへのセグメンテーションの原則は同じです。
候補者のコレクション
本文には、ピリオド、楕円、括弧、引用符など、文末のすべての候補が含まれています。
6.▒「私はうれしい」という回答の最も頻繁で同時に高い評価のオプション▒(13のステートメント、25ポイント)▒–承認と励ましを受ける状況▒7.▒「私は知っている」という回答では、最も典型的なものとして推定されていることは注目に値します、しかし、「私は女性です」という答えに出くわしたときだけ▒;「この人生で私を待っているのは1つの結婚だけです」▒と「遅かれ早かれ私は出産しなければなりません」▒.▒コンパイラ:V.▒P.▒ゴロビン、F.▒V.▒Zanichev、A.▒L.▒Rastorguev、R.▒V.▒Savko、I.▒I.▒Tuchkov。
トークンの場合、テキストをアトムに分割します。トークンの境界線は、アトム内を正確に通過しません。
1980年の終わりに▒-▒▒-beginning1990▒-
▒▒BS▒-▒3▒わずかに▒
小さい質量▒(▒3▒、▒6▒▒)▒▒—をマークすることが可能です。 Da▒and▒umerla▒.▒.▒.▒Got▒ligirl、▒thefalcon▒?▒!
連合
私たちは一貫して分離の候補をバイパスし、不要なものを削除します。ヒューリスティックのリストを使用します。
リストアイテム。区切り文字はピリオドまたは括弧で、左側は数字または文字
6です。▒最も頻繁であると同時に高く評価されている回答「うれしい」(13ステートメント、25ポイント)は、承認と励ましを受けている状況です。 7.▒「私は知っている」という答えの中で...
イニシャルであることは注目に値します。セパレータ-ドット、左側に1つの大文字
...V.▒P.▒Golovin、F.▒V.▒Zanichev、A.▒L.▒Rastorguev、R.▒V.▒Savko、I.▒I.▒Tuchkovによって編集されました。 ..。
セパレーターの右側にスペースはありません
...しかし、「私は女性です」という答えは一度だけです▒; 「この人生で私を待っているのは1つの結婚だけです」と「遅かれ早かれ私は出産しなければならない」という声明があります▒。
終了引用符または括弧の前に文末記号はありません。これは引用符または直接のスピーチではありません。6
。最も頻繁で高く評価されている回答は、「うれしい」です«(13ステートメント、25ポイント)▒-承認と励ましを得る状況。 ...「この人生で私を待っているのは1つの結婚だけです」そして「遅かれ早かれ私は出産しなければなりません」。
その結果、2つの区切り文字が残っているので、それらを文の終わりと見なします。
6.「私はうれしい」(13のステートメント、25のポイント)という回答の最も頻繁で同時に高く評価されている変形は、承認と励ましを受けている状況です。▒7。 「私は知っている」という答えで最も典型的なものとして評価されていることは注目に値しますが、「私は女性です」という答えに出会ったのは一度だけです。 「この人生で私を待っているのは1つの結婚だけです」、「遅かれ早かれ私は出産しなければならない」という声明があります。V.P。Golovin、F.V。Zanichev、A.L。Rastorguev、R.V。 Savko、I。I。Tuchkov
手順はトークンの場合と似ていますが、ルールが異なります。
分数または合理的な数
...(3▒、▒6t)...
複雑な句読点
-はい、死亡しました。▒.▒。鷹、女の子が分かりますか?▒!
ハイフンの周りにスペースはありません。これは直接のスピーチの始まりではありません。
1980年の終わりに▒-▒-1990年の初め
▒-▒BS▒-▒3に注意してください...
残っているものはすべてトークンの境界と見なされます。
1980年代の終わりに-x▒-始まり-1990-x▒BS
-3▒それは▒▒通知▒わずかに低い質量▒(▒3.6▒t▒)▒▒—
はい、そして死んだ。 ..▒了解▒li▒girl、▒sokol▒?!
制限事項
Razdelルールは、正しい句読点できれいに書かれたテキスト用に最適化されています。このソリューションは、ニュース記事、文学テキストでうまく機能します。ソーシャルネットワークからの投稿、電話での会話の記録では、品質が低くなります。文の間にスペースがないか、末尾にピリオドがない場合、または文が小文字で始まる場合、Razdelは間違いを犯します。ソースコードで
タスクのルールを作成する方法を読んでください。このトピックはまだドキュメントで開示されていません。
Slovnet-自然なロシア語処理のための深層学習モデリング

このプロジェクトでは、ナターシャスロブネットは、ロシア語を話すNLPの最新モデルの教育と推論に取り組んでいます。ライブラリには、名前付きエンティティを抽出し、形態と構文を解析するための高品質のコンパクトモデルが含まれています。すべてのタスクの品質は、ニューステキストのロシア語の他のオープンソリューションと同等またはそれ以上です。インストールの手順、使用例-中Slovnetリポジトリ。 NER問題の解決策がどのように配置されているかを詳しく見てみましょう。形態と構文については、すべてが類推によるものです。
2018年の終わりに、BERTに関するGoogleからの記事の後、英語のNLPで多くの進歩がありました。 2019年、DeepPavlovプロジェクトのメンバーロシア語に適応した多言語BERT、RuBERTが登場しました。CRFヘッドが上部でトレーニングされ、DeepPavlov BERTNER-ロシア語のSOTAであることが判明しました。モデルの品質は優れており、最も近い追跡者であるDeepPavlov NERの2分の1のエラーですが、サイズとパフォーマンスは恐ろしいものです。6GB-GPURAMの消費、2GB-モデルのサイズ、毎秒13記事-優れたGPUでのパフォーマンス。
2020年、Natashaプロジェクトでは、DeepPavlov BERT NERに品質を近づけることができました。モデルのサイズは、75分の1(27MB)、メモリ消費量は30分の1(205MB)、CPUの速度は2分の1(25記事/秒)でした。 )。
| ナターシャ、スロブネットNER | DeepPavlov BERT NER | |
| トークンごとのPER / LOC / ORG F1、Collection5ごとの平均、factRuEval-2016、BSNLP-2019、Gareev | 0.97 / 0.91 / 0.85 | 0.98 / 0.92 / 0.86 |
| モデルサイズ | 27MB | 2GB |
| メモリ消費 | 205MB | 6GB(GPU) |
| パフォーマンス、1秒あたりのニュース記事(1記事≈1KB) | CPUあたり25(Core i5) | 13 GPU(RTX 2080 Ti)、1 CPU |
| 初期化時間、秒 | 1 | 35 |
| ライブラリはサポートします | Python 3.5以降、PyPy3 | Python 3.6+ |
| 依存関係 | NumPy | TensorFlow |
Slovnet NERの品質は、SOTA DeepPavlov BERT NERの品質よりも1パーセントポイント低く、モデルのサイズは75分の1で、メモリ消費量は30分の1で、CPUの速度は2分の1です。Slovnetリポジトリ内のロシア語を話すNER用のSpaCy、PullEntiおよびその他のソリューションとの比較。
この結果をどのように取得しますか?短いレシピ:
Slovnet NER = Slovnet BERT NER - DeepPavlov BERT NERのアナログ+ WordCNN-CRFでの合成マークアップ(Nerus)による蒸留と量子化された埋め込み(Navec)+ NumPyでの推論用エンジン。
今順番に。計画は次のとおりです。手動で注釈を付けた小さなデータセットで、BERTアーキテクチャを使用して重いモデルをトレーニングします。ニュースコーパスでマークを付けると、大きくて汚い合成トレーニングデータセットが得られます。その上でコンパクトなプリミティブモデルをトレーニングしましょう。このプロセスは蒸留と呼ばれます。重いモデルは教師であり、コンパクトなモデルは学生です。BERTアーキテクチャはNERの問題に対して冗長であり、コンパクトモデルは重いモデルに比べて品質がそれほど低下しないと考えています。
モデル教師
DeepPavlov BERT NERは、RuBERTエンコーダーとCRFヘッドで構成されています。私たちの重い教師モデルは、マイナーな改善を加えてこのアーキテクチャを繰り返します。
すべてのベンチマークは、ニューステキストのNER品質を測定します。ニュースでRuBERTを訓練しましょう。Corusリポジトリには、ロシア語の公開ニュースコーパスへのリンク、合計12GBのテキストが含まれています。RoBERTaに関するFacebookの記事の手法を使用します:大規模な集約バッチ、動的マスク、次の文(NSP)の予測の拒否。 RuBERTは、120,000個のサブトークンの巨大な辞書を使用します。これはGoogleの多言語BERTの遺産です。最も頻度の高いニュースアイテムのサイズを50,000に減らすと、カバレッジは5%減少します。NewsRuBERTを入手する、モデルは、ニュースの偽装サブトークンをRuBERTよりも5パーセントポイント良く予測します(トップ1の63%)。Collection5の
1000件の記事用にNewsRuBERTエンコーダーとCRFヘッドをトレーニングしましょう。Slovnet BERT NERを入手し、品質はDeepPavlov BERT NERより0.5パーセントポイント優れており、モデルサイズは4分の1(473MB)、3倍高速(毎秒40記事)です。
NewsRuBERT = RuBERT + 12GBのニュース+ RoBERTaのテクノロジー+ 50K-辞書。
Slovnet BERT NER(DeepPavlov BERT NERのアナログ)= NewsRuBERT + CRFヘッド+コレクション5。
現在、BERTのようなアーキテクチャでモデルをトレーニングするには、HuggingFaceのTransformersを使用するのが通例です。トランスフォーマーは100,000行のPythonコードです。推論で損失やゴミが爆発した場合、何が悪かったのかを理解するのは困難です。さて、そこにはたくさんのコードが複製されています。RoBERTaをトレーニングしたとしても、問題を約3000行のコードにすばやくローカライズできますが、これも多くのことです。最新のPyTorchでは、Transformersライブラリはそれほど関連性がありません。
torch.nn.TransformerEncoderLayerロベルタのようなモデルコード100行を取ります。
class BERTEmbedding(nn.Module):
def __init__(self, vocab_size, seq_len, emb_dim, dropout=0.1, norm_eps=1e-12):
super(BERTEmbedding, self).__init__()
self.word = nn.Embedding(vocab_size, emb_dim)
self.position = nn.Embedding(seq_len, emb_dim)
self.norm = nn.LayerNorm(emb_dim, eps=norm_eps)
self.drop = nn.Dropout(dropout)
def forward(self, input):
batch_size, seq_len = input.shape
position = torch.arange(seq_len).expand_as(input).to(input.device)
emb = self.word(input) + self.position(position)
emb = self.norm(emb)
return self.drop(emb)
def BERTLayer(emb_dim, heads_num, hidden_dim, dropout=0.1, norm_eps=1e-12):
layer = nn.TransformerEncoderLayer(
d_model=emb_dim,
nhead=heads_num,
dim_feedforward=hidden_dim,
dropout=dropout,
activation='gelu'
)
layer.norm1.eps = norm_eps
layer.norm2.eps = norm_eps
return layer
class BERTEncoder(nn.Module):
def __init__(self, layers_num, emb_dim, heads_num, hidden_dim,
dropout=0.1, norm_eps=1e-12):
super(BERTEncoder, self).__init__()
self.layers = nn.ModuleList([
BERTLayer(
emb_dim, heads_num, hidden_dim,
dropout, norm_eps
)
for _ in range(layers_num)
])
def forward(self, input, pad_mask=None):
input = input.transpose(0, 1) # torch expects seq x batch x emb
for layer in self.layers:
input = layer(input, src_key_padding_mask=pad_mask)
return input.transpose(0, 1) # restore
class BERTMLMHead(nn.Module):
def __init__(self, emb_dim, vocab_size, norm_eps=1e-12):
super(BERTMLMHead, self).__init__()
self.linear1 = nn.Linear(emb_dim, emb_dim)
self.norm = nn.LayerNorm(emb_dim, eps=norm_eps)
self.linear2 = nn.Linear(emb_dim, vocab_size)
def forward(self, input):
x = self.linear1(input)
x = F.gelu(x)
x = self.norm(x)
return self.linear2(x)
class BERTMLM(nn.Module):
def __init__(self, emb, encoder, head):
super(BERTMLM, self).__init__()
self.emb = emb
self.encoder = encoder
self.head = head
def forward(self, input):
x = self.emb(input)
x = self.encoder(x)
return self.head(x)
これはプロトタイプではなく、コードはSlovnetリポジトリからコピーされます。トランスフォーマーは読みやすく、多くの作業を行い、Arxivを使用して記事のコードを詰め込みます。多くの場合、Pythonソースは科学記事の説明よりも明確です。
合成データセット
Lenta.ruコーパス からの700,000件の記事に重いモデルでマークを付けましょう。巨大な合成トレーニングデータセットを取得します。アーカイブは、NatashaプロジェクトのNerusリポジトリで入手できます。マークアップは非常に高品質で、F1はトークンで推定します:PER-99.7%、LOC-98.6%、ORG-97.2%。エラーのまれな例:
ORG────────────── LOC────────────────────────────
241- 4- 10-
<
LOC─── LOC──────
>.
───────────~~~~~~~~~~~
ORG────────────────────~~~~~~~~~~~~~~~~
.
LOC───
<>
~~~~~~~~ LOC──────────────────
.
~~~~ ~~~~~~ LOC───
.
LOC────
-
PER─────────────────────
M&A.
~~~
:
~~~~~~~~~~~~ORG─── LOC──
,
PER─────── LOC───
,
ORG─ LOC─────────────
.
LOC
モデル学習者
ヘビーティーチャーモデルのアーキテクチャの選択に問題はありませんでした。唯一のオプションはトランスフォーマーでした。コンパクトな学生モデルはより難しく、多くのオプションがあります。 2013年から2018年にかけて、word2vecの登場からBERTに関する記事まで、人類はNER問題を解決するための一連のニューラルネットワークアーキテクチャを考案しました。すべてに共通のスキームがあり
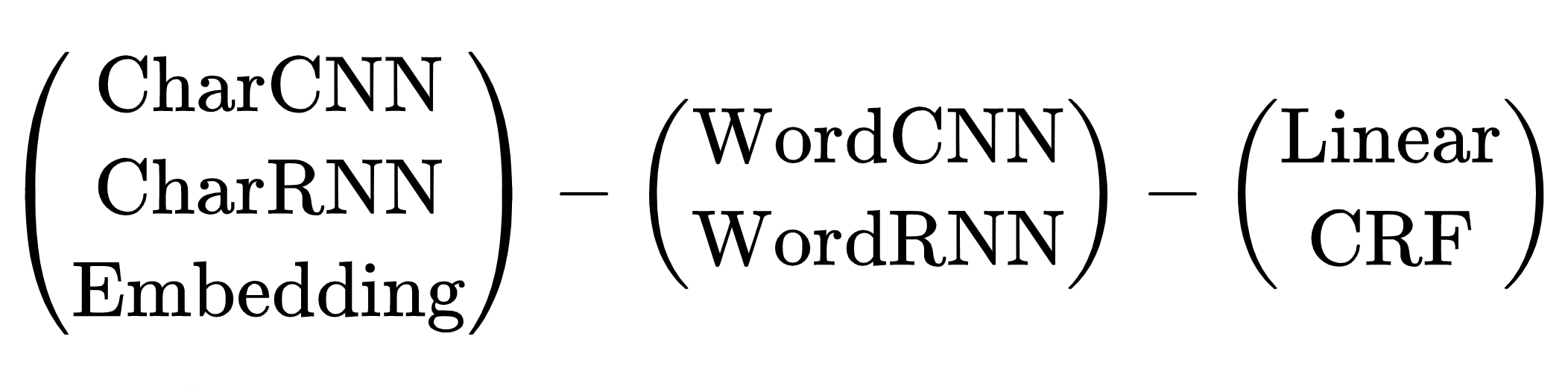
ます。NERタスクのニューラルネットワークアーキテクチャのスキーム:トークンエンコーダー、コンテキストエンコーダー、タグデコーダー。ヤン(2018)によるレビュー記事の略語の説明。
アーキテクチャには多くの組み合わせがあります。どちらを選択しますか?たとえば、(CharCNN + Embedding)-WordBiLSTM-CRFは、2019年までのロシア語のSOTAであるDeepPavlovNERに関する記事のモデル図です。
CharCNN、CharRNNのオプションをスキップします。各トークンのシンボルによって小さなニューラルネットワークを起動するのは、私たちのやり方ではなく、遅すぎます。また、WordRNNを避けたいのですが、ソリューションはCPUで機能し、各トークンのマトリックスをゆっくりと乗算する必要があります。NERの場合、線形とCRFのどちらを選択するかは条件付きです。BIOエンコーディングを使用します。タグの順序は重要です。私たちはひどいブレーキに耐えなければなりません、CRFを使用してください。1つのオプションが残っています-埋め込み-WordCNN-CRF。このモデルは大文字と小文字を区別しません。NERにとって重要なのは、「希望」は単なる単語であり、「希望」はおそらく名前です。ShapeEmbeddingを追加します-トークンのアウトラインを埋め込みます。例: "NER" -EN_XX、 "Vainovich" -RU_Xx、 "!" --PUNCT_ !、 "および" --RU_x、 "5.1" -NUM、 "ニューヨーク" --RU_Xx-Xx。Slovnet NERスキーム-(WordEmbedding + ShapeEmbedding)-WordCNN-CRF。
蒸留
巨大な合成データセットでSlovnetNERをトレーニングしましょう。結果を重いモデル教師のSlovnetBERTNERと比較してみましょう。品質は、手動でマークされたCollection5、Gareev、factRuEval-2016、BSNLP-2019で計算され、平均化されます。トレーニングサンプルのサイズは非常に重要です。250のニュース記事(サイズfactRuEval-2016)の場合、PER、LOC、LOG F1の平均は0.64、1000(コレクション5のアナログ)の平均は0.81、データセット全体の場合は0.91、Slovnet BERTNERの品質は0.92です。
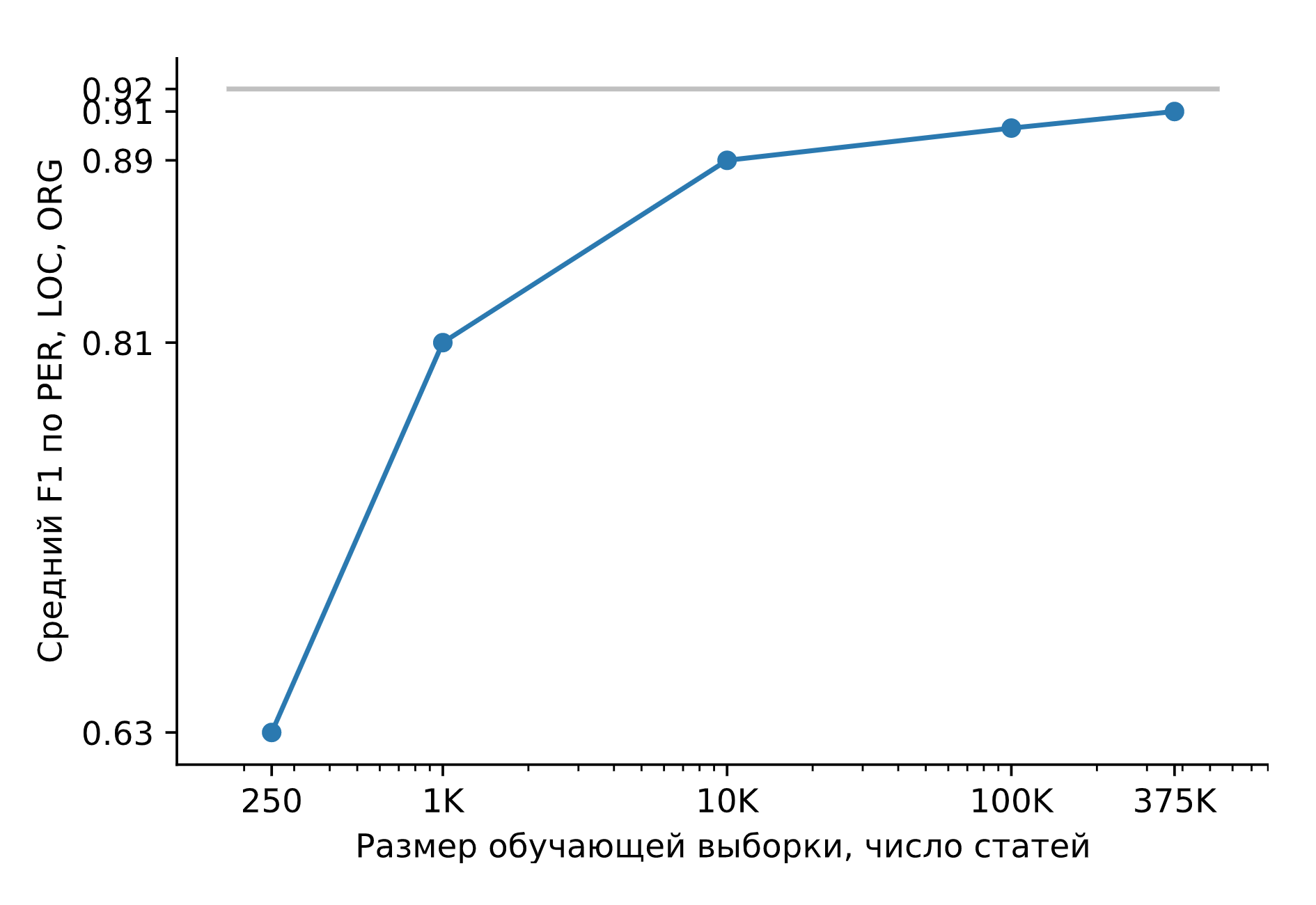
Slovnet NERの品質、合成トレーニングの例の数への依存。灰色の線-SlovnetBERTNERの品質。 Slovnet NERは、手書きの例を認識せず、合成データのみをトレーニングします。
原始的な学生モデルは、ハード教師モデルよりも1パーセントポイント悪いです。これは素晴らしい結果です。普遍的なレシピはそれ自体を示唆しています:
一部のデータを手動でマークアップします。重い変圧器を訓練します。多くの合成データを生成します。大きなサンプルで単純なモデルをトレーニングします。トランスの品質、シンプルなモデルのサイズとパフォーマンスが得られます。
Slovnetライブラリには、このレシピに従ってトレーニングされた2つのモデルがあります。SlovnetMorph-形態学的タガー、Slovnet構文-構文パーサー。Slovnet Morphは、ヘビーティーチャーモデルより2パーセントポイント遅れています。SlovnetSyntax- 5です。どちらのモデルも、ニュース記事用の既存のロシアのソリューションよりも優れた品質とパフォーマンスを備えています。
定量化
SlovnetNERのサイズは289MBです。287MBは、埋め込みのあるテーブルで占められています。このモデルは250,000行の大きな語彙を使用し、ニューステキストの単語の98%をカバーしています。量子化を使用して、300次元のフロートベクトルを100次元の8ビットベクトルに置き換えます。モデルのサイズは10分の1(27MB)になり、品質は変わりません。Navecライブラリは、量子化された事前トレーニング済みの埋め込みのコレクションであるNatashaプロジェクトの一部です。フィクションでトレーニングされたウェイトは50MBかかり、合成推定に従ってすべての静的RusVectoresモデルをバイパスします。
推論
Slovnet NERは、トレーニングにPyTorchを使用しています。 PyTorchパッケージの重量は700MBです。推測のために本番環境にドラッグしたくありません。 PyTorchは、PyPyインタープリターでも機能しません。 Slovnetはと共に使用されるYargyパーサー、のアナログYandexの富田パーサ。 PyPyを使用すると、文法の複雑さに応じて、Yargyは2〜10倍速く動作します。 PyTorchに依存しているために速度を落としたくありません。
標準的な解決策は、TorchScriptを使用するか、モデルをONNXに変換し、ONNXRuntimeで推論を行うことです。 Slovnet NERは、非標準のブロック(量子化された埋め込み、CRFデコーダー)を使用します。 TorchScriptとONNXRuntimeはPyPyをサポートしていません。
Slovnet NERはシンプルなモデルで、NumPyのすべてのブロックを手動で実装し、PyTorchによって計算された重みを使用します。少しNumPyの魔法を適用して、CNNブロック、CRFデコーダーを注意深く実装し、量子化された埋め込みを解凍するには5行かかります。CPUでの推論速度は、ONNXRuntimeおよびPyTorchの場合と同じで、Corei5では毎秒25のニュース記事があります。
この手法は、より複雑なモデルで機能します。SlovnetMorphとSlovnetSyntaxもNumPyに実装されています。Slovnet NER、Morph、Syntaxは、共通の埋め込みテーブルを共有しています。別のファイルで重みを取り出しましょう。テーブルはメモリとディスクに複製されません。
>>> navec = Navec.load('navec_news_v1_1B.tar') # 25MB
>>> morph = Morph.load('slovnet_morph_news_v1.tar') # 2MB
>>> syntax = Syntax.load('slovnet_syntax_news_v1.tar') # 3MB
>>> ner = NER.load('slovnet_ner_news_v1.tar') # 2MB
# 25 + 2 + 3 + 2 25+2 + 25+3 + 25+2
>>> morph.navec(navec)
>>> syntax.navec(navec)
>>> ner.navec(navec)
制限事項
ナターシャは、名前、トポニームの名前、組織などの標準エンティティを抽出します。このソリューションは、ニュースで優れた品質を示しています。他のエンティティやテキストの種類を操作する方法は?新しいモデルをトレーニングする必要があります。これは簡単ではありません。モデル準備の複雑さにより、コンパクトなサイズと作業速度を実現します。重い教師のモデルを製造するためのスクリプトのラップトップ、学生モデルのためのスクリプトのラップトップ、量子化された埋め込みを調製するための説明書。
Navec-ロシア語用のコンパクトな埋め込み

コンパクトなモデルは作業に便利です。それらは迅速に開始し、メモリをほとんど使用せず、より多くの並列プロセスが1つのインスタンスに適合します。
NLPでは、モデルの重みの80〜90%が埋め込みテーブルにあります。Navecライブラリは、ロシア語用に事前にトレーニングされた埋め込みのコレクションであるNatashaプロジェクトの一部です。固有の品質メトリックに関しては、RusVectoresのトップソリューションをわずかに下回っていますが、重み付きのアーカイブのサイズは5〜6倍小さく(51MB)、辞書は2〜3倍大きくなっています(500Kワード)。
| 品質* | モデルサイズ、MB | 辞書のサイズ、×10 3 | |
| ナベック | 0.719 | 50.6 | 500 |
| RusVectores | 0.638-0.726 | 220.6〜290.7 | 189-249 |
私たちは、についてお話します古き良きワードごとの埋め込み2013年にNLPに革命をもたらしました。この技術は今日でも重要です。Natashaプロジェクトでは、形態、構文の解析、および名前付きエンティティの抽出のモデルが、単語ごとのNavec埋め込みで機能し、他のオープンソリューションよりも優れた品質を示します。
RusVectores
ロシア語の場合、RusVectoresから事前にトレーニングされた埋め込みを使用するのが通例です。これらには不快な機能があります。テーブルには単語ではなく、「word_POS-tag」のペアが含まれます。ペア「oven_VERB」の場合、「cook_VERB」、「cook_VERB」、および「oven_NOUN」の場合、「hut_NOUN」、「furnace_NOUN」に類似したベクトルが必要です。
実際には、そのような埋め込みを使用することは不便です。テキストをトークンに分割するだけでは不十分です。トークンごとに、何らかの方法でPOSタグを定義する必要があります。埋め込みテーブルが膨らんでいます。「become」という1つの単語の代わりに、6:2つの妥当な「become_VERB」、「become_NOUN」、および4つの奇妙な「become_ADV」、「become_PROPN」、「become_NUM」、「become_ADJ」を格納します。250,000エントリのテーブルには195,000の一意の単語があります。
品質
セマンティック近接問題への埋め込みの品質を見積もりましょう。いくつかの単語を見てみましょう。埋め込みベクトルを見つけるたびに、余弦の類似性を計算します。同様の単語「cup」と「jug」のNavecは、「fruit」と「oven」の場合、0.49を返します--- 0.0047。類似性の参照マークを持つ多くのペアを収集し、スピアマンと私たちの答えとの相関関係を計算しましょう。
RusVectoresの作成者は、SimLex965ペアの小さく、注意深くチェックされ、改訂されたテストリストを使用します。RUSSEプロジェクトから新しいYandexLRWCとデータセットを追加しましょう:HJ、RT、AE、AE2:
| 6つのデータセットの平均品質 | 読み込み時間、秒 | モデルサイズ、MB | 辞書のサイズ、×10 3 | ||
| ナベック | hudlit_12B_500K_300d_100q |
0.719 | 1.0 | 50.6 | 500 |
news_1B_250K_300d_100q |
0.653 | 0.5 | 25.4 | 250 | |
| RusVectores | ruscorpora_upos_cbow_300_20_2019 |
0.692 | 3.3 | 220.6 | 189 |
ruwikiruscorpora_upos_skipgram_300_2_2019 |
0.691 | 5.0 | 290.0 | 248 | |
tayga_upos_skipgram_300_2_2019 |
0.726 | 5.2 | 290.7 | 249 | |
tayga_none_fasttextcbow_300_10_2019 |
0.638 | 8.0 | 2741.9 | 192 | |
araneum_none_fasttextcbow_300_5_2018 |
0.664 | 16.4 | 2752.1 | 195 |
品質は
hudlit_12B_500K_300d_100qRusVectoresソリューションと同等かそれ以上で、辞書は2〜3倍大きく、モデルサイズは5〜6倍小さくなっています。どのようにしてこの品質とサイズを手に入れましたか?
動作原理
hudlit_12B_500K_300d_100q-手袋-埋め込みのために訓練された小説の145ギガバイト。RUSSEプロジェクトからのテキストを含むアーカイブを見てみましょう。Cで元のGloVe実装を使用し、便利なPythonインターフェイスでラップしてみましょう。
なぜword2vecではないのですか?大規模なデータセットでの実験は、GloVeを使用すると高速になります。コロケーションマトリックスを計算したら、それを使用してさまざまな次元の埋め込みを準備し、最適なオプションを選択します。
なぜfastTextではないのですか?ナターシャプロジェクトでは、ニューステキストを扱います。それらにはタイプミスがほとんどなく、OOVトークンの問題は大きな辞書によって解決されます。表の250,000行は、
news_1B_250K_300d_100qニュース記事の単語の98%をカバーしています。
辞書のサイズ
hudlit_12B_500K_300d_100q-500,000エントリ、フィクションテキストの単語の98%をカバーします。ベクトルの最適な次元は300です。フロート数の500,000×300のテーブルは578MBを取り、重み付きのアーカイブのサイズhudlit_12B_500K_300d_100qは12分の1(48MB)です。それは量子化についてです。
定量化
32ビットの浮動小数点数を8ビットのコードに置き換えましょう:[-∞、-0.86)-コード0、[-0.86、-0.79)-コード1、[-0.79、-0.74)-2、…、[0.86、 ∞)-255。テーブルのサイズは4分の1(143MB)に減少します。
:
-0.220 -0.071 0.320 -0.279 0.376 0.409 0.340 -0.329 0.400
0.046 0.870 -0.163 0.075 0.198 -0.357 -0.279 0.267 0.239
0.111 0.057 0.746 -0.240 -0.254 0.504 0.202 0.212 0.570
0.529 0.088 0.444 -0.005 -0.003 -0.350 -0.001 0.472 0.635
────── ──────
-0.170 0.677 0.212 0.202 -0.030 0.279 0.229 -0.475 -0.031
────── ──────
:
63 105 215 49 225 230 219 39 228
143 255 78 152 187 34 49 204 198
163 146 253 58 55 240 188 191 246
243 155 234 127 127 35 128 237 249
─── ───
76 251 191 188 118 207 195 18 118
─── ───
データは粗くなり、異なる値-0.005と-0.003が1つのコード127、-0.030と-0.031を置き換えます-118
コードを1つではなく、3つの数字に置き換えましょう。k-meansアルゴリズムを使用して、埋め込みテーブルの数値のすべてのトリプレットを256のクラスターにクラスター化します。各トリプレットの代わりに、0から255までのコードを格納します。テーブルは3倍(48MB)減少します。 NavecはPQk-meansライブラリを使用し、マトリックスを100列に分割し、それぞれを個別にクラスター化します。合成テストの品質は1パーセントポイント低下します。k-NNのProductQuantizersの記事で量子化について明確になっています。
量子化された埋め込みは、通常のものよりも遅くなります。圧縮されたベクトルは、使用する前に解凍する必要があります。手順を慎重に実行し、Numpyマジックを適用します、PyTorchではtorch.gatherを使用します。Slovnet NERでは、埋め込みテーブルへのアクセスに合計計算時間の0.1%がかかります。Slovnetライブラリの
モジュール
NavecEmbeddingは、NavecをPyTorchモデルに統合します。
>>> import torch
>>> from navec import Navec
>>> from slovnet.model.emb import NavecEmbedding
>>> path = 'hudlit_12B_500K_300d_100q.tar' # 51MB
>>> navec = Navec.load(path) # ~1 sec, ~100MB RAM
>>> words = ['', '<unk>', '<pad>']
>>> ids = [navec.vocab[_] for _ in words]
>>> emb = NavecEmbedding(navec)
>>> input = torch.tensor(ids)
>>> emb(input) # 3 x 300
tensor([[ 4.2000e-01, 3.6666e-01, 1.7728e-01,
[ 1.6954e-01, -4.6063e-01, 5.4519e-01,
[ 0.0000e+00, 0.0000e+00, 0.0000e+00,
...Nerusは、形態、構文、名前付きエンティティのマークアップを備えた大規模な合成データセットです

Natashaプロジェクトでは、形態、構文分析、および名前付きエンティティの抽出は、Slovnet NER、Slovnet Morph、およびSlovnetSyntaxの3つのコンパクトモデルによって行われます。ソリューションの品質は、BERTアーキテクチャを備えた重いソリューションよりも1〜5パーセントポイント悪く、サイズは50〜75倍小さく、CPUの速度は2倍高速です。モデルは、形態、構文、および名前付きエンティティのCoNLL-Uマークアップを含む700,000のニュース記事のアーカイブで、巨大な合成Nerusデータセットでトレーニングされます。
# newdoc id = 0
# sent_id = 0_0
# text = - , ...
1 - _ NOUN _ Animacy=Anim|C... 7 nsubj _ Tag=O
2 _ ADP _ _ 4 case _ Tag=O
3 _ ADJ _ Case=Dat|Degre... 4 amod _ Tag=O
4 _ NOUN _ Animacy=Inan|C... 1 nmod _ Tag=O
5 _ PROPN _ Animacy=Anim|C... 1 appos _ Tag=B-PER
6 _ PROPN _ Animacy=Anim|C... 5 flat:name _ Tag=I-PER
7 _ VERB _ Aspect=Perf|Ge... 0 root _ Tag=O
8 , _ PUNCT _ _ 13 punct _ Tag=O
9 _ ADP _ _ 11 case _ Tag=O
10 _ DET _ Case=Loc|Numbe... 11 det _ Tag=O
11 _ NOUN _ Animacy=Inan|C... 13 obl _ Tag=O
12 _ PROPN _ Animacy=Inan|C... 11 nmod _ Tag=B-LOC
13 _ VERB _ Aspect=Perf|Ge... 7 ccomp _ Tag=O
14 _ ADV _ Degree=Pos 15 advmod _ Tag=O
15 _ ADJ _ Case=Nom|Degre... 16 amod _ Tag=O
16 _ NOUN _ Animacy=Inan|C... 13 nsubj _ Tag=O
17 _ ADP _ _ 18 case _ Tag=O
18 _ NOUN _ Animacy=Inan|C... 16 nmod _ Tag=O
19 , _ PUNCT _ _ 20 punct _ Tag=O
20 _ VERB _ Aspect=Imp|Moo... 0 root _ Tag=O
21 _ PROPN _ Animacy=Inan|C... 20 nsubj _ Tag=B-ORG
22 _ PROPN _ Animacy=Inan|C... 21 appos _ Tag=I-ORG
23 . _ PUNCT _ _ 20 punct _ Tag=O
# sent_id = 0_1
# text = , , , ...
1 _ ADP _ _ 2 case _ Tag=O
2 _ NOUN _ Animacy=Inan|C... 9 parataxis _ Tag=O
...Slovnet NER、Morph、Syntax-プリミティブモデル。トレーニングセットに1000の例がある場合、Slovnet NERは重いBERTアナログより11パーセントポイント遅れ、10,000の例(3ポイントの場合、500,000の場合)
は1です。Nerusは作業の結果であり、BERTアーキテクチャを備えた重いモデル:Slovnet BERT NER、Slovnet BERTモーフ、SlovnetBERT構文。 Tesla V100では、700,000件のニュース記事の処理に20時間かかります。他の研究者の時間を節約し、完成したアーカイブをオープンアクセスにします。でスペイシー-ルテニウムロシア語圏のスペイシーためNerus定性的なモデルで教える、公式リポジトリにパッチを準備します。

合成マークアップには高品質があります。形態学的タグの決定の精度は98%、構文リンクは96%です。 NERの場合、F1はトークンで推定します:PER-99%、LOC-98%、ORG-97%。品質を評価するために、SynTagRus、Collection5、およびニューススライスGramEval2020をマークアップし、参照マークアップを私たちのものと比較して、Nerusリポジトリの詳細を確認します。構文のマークアップにエラーがあるため、ループと複数のルートがあり、POSタグが構文エッジに対応しない場合があります。UniversalDependenciesのバリデーターを使用すると便利です。そのような例はスキップしてください。
PythonパッケージNerusは、マークアップをロードおよびレンダリングするための便利なインターフェイスを編成します。
>>> from nerus import load_nerus
>>> docs = load_nerus('nerus_lenta.conllu.gz')
>>> doc = next(docs)
>>> doc
NerusDoc(
id='0',
sents=[NerusSent(
id='0_0',
text='- , ...',
tokens=[NerusToken(
id='1',
text='-',
pos='NOUN',
feats={'Animacy': 'Anim',
'Case': 'Nom',
'Gender': 'Masc',
'Number': 'Sing'},
head_id='7',
rel='nsubj',
tag='O'
),
NerusToken(
id='2',
text='',
pos='ADP',
...
>>> doc.ner.print()
- ,
PER───────────── LOC───
, . ,
ORG──────── PER──────
...
>>> sent = doc.sents[0]
>>> sent.morph.print()
- NOUN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
ADP
ADJ|Case=Dat|Degree=Pos|Number=Plur
NOUN|Animacy=Inan|Case=Dat|Gender=Masc|Number=Plur
PROPN|Animacy=Anim|Case=Nom|Gender=Fem|Number=Sing
PROPN|Animacy=Anim|Case=Nom|Gender=Fem|Number=Sing
VERB|Aspect=Perf|Gender=Fem|Mood=Ind|Number=Sing
...
>>> sent.syntax.print()
┌►┌─┌───── - nsubj
│ │ │ ┌──► case
│ │ │ │ ┌► amod
│ │ └►└─└─ nmod
│ └────►┌─ appos
│ └► flat:name
┌─└─────────
│ ┌──────► , punct
│ │ ┌──► case
│ │ │ ┌► det
│ │ ┌►└─└─ obl
│ │ │ └──► nmod
└──►└─└───── ccomp
│ ┌► advmod
│ ┌►└─ amod
└►┌─└─── nsubj:pass
│ ┌► case
└──►└─ nmod
┌► , punct
┌─┌─└─
│ └►┌─ nsubj
│ └► appos
└────► . punct
インストールの手順、使用例、品質評価Nerusリポジトリインチ
コーラス-ロシア語の公開データセットへのリンクのコレクション+ダウンロード用の関数

CorusライブラリはNatashaプロジェクトの一部であり、公開ロシア語NLPデータセットへのリンクのコレクション+ローダー関数を備えたPythonパッケージです。ソースへのリンクのリスト、インストール手順、およびCorusリポジトリでの使用例。
>>> from corus import load_lenta
# Corus Lenta.ru, :
# wget https://github.com/yutkin/Lenta.Ru-News-Dataset/...
>>> path = 'lenta-ru-news.csv.gz'
>>> records = load_lenta(path) # 2, 750 000
>>> next(records)
LentaRecord(
url='https://lenta.ru/news/2018/12/14/cancer/',
title=' \xa0 ...',
text='- ...',
topic='',
tags=''
)
ロシア語の便利なオープンデータセットは非常によく隠されているため、ほとんどの人はそれらについて知りません。
の例
ニュース記事のコーパス
ニュース記事で言語モデルをトレーニングしたいので、たくさんのテキストが必要です。最初に頭に浮かぶのは、Taigaデータセットのニューススライス(〜1GB)です。多くの人がLenta.ruダンプ(2GB)について知っています。他のソースを見つけるのはより困難です。 2019年、Dialogueはヘッドラインを生成するためのコンテストを主催しました。主催者は、RIA Novostiのダンプを4年間(3.7GB)準備しました。 2018年、Yuri Baburovは、40のロシア語ニュースリソース(7.5GB)からのアップロードを公開しました。ニュースアジェンダの分析についてプロジェクトのために収集されたODS 共有アーカイブ(7GB)からのボランティア。 ではコーラスレジストリ
すべてのソースは、機能・ローダーを持っているため、これらのデータセットへのリンクは、«ニュース»タグ付け:
load_taiga_*、load_lenta、load_ria、load_buriy_*、load_ods_*。
NER
ロシア語でNERを教えたいので、注釈付きのテキストが必要です。まず、factRuEval-2016コンペティションのデータを思い出します。マークアップには欠点があります。複雑な形式、エンティティスパンの重複、あいまいな「LocOrg」カテゴリがあります。Persons-1000の後継であるNamedEntities5コレクションについて誰もが知っているわけではありません。標準フォーマットのレイアウト、スパンが交差しない、美しさ!他の3つの情報源は、ロシア語を話すNERの最も熱心なファンだけが知っています。 Rinat Gareevにメールで手紙を書き、2013年の彼の記事へのリンクを添付します。それに応じて、名前と組織がタグ付けされた250のニュース記事を受け取ります。2019年にBSNLP-2019コンペティションが開催されましたスラブ言語のNERについては、主催者に手紙を書き、さらに450のマークされたテキストを取得します。Winer氏のプロジェクトは、Wikipediaのダンプから半自動NERマークアップを作るというアイデアを思い付いた、ロシアのための大規模なダウンロードがGithubの上で使用可能です。
レジスタコーラスをロードするためのリンクと機能:
load_factru、load_ne5、load_gareev、load_bsnlp、load_wikiner。
リンクのコレクション
ブートローダーを取得してレジストリに入る前に、ソースへのリンクがチケットのセクションに蓄積されます。30個のデータセットのコレクション:タイガの新バージョン、クロールコモンから568ギガバイトロシア語のテキスト、Banki.ru CレビューとAuto.ru。調査結果を共有し、リンク付きのチケットを作成することをお勧めします。
ローダー機能
単純なデータセットのコードは、自分で簡単に作成できます。Lenta.ruダンプは整形式で、実装は簡単です。Taigaは、約1,500万のCoNLL-Uzipファイルで構成されています。ダウンロードが迅速に機能し、大量のメモリを使用せず、ファイルシステムを台無しにしないためには、混乱し、低レベルのzipファイルでの作業を慎重に実装する必要があります。
35のソースの場合、CorusPythonパッケージにはローダー関数があります。Taigaにアクセスするためのインターフェースは、Lenta.ruダンプよりも複雑ではありません。
>>> from corus import load_taiga_proza_metas, load_taiga_proza
>>> path = 'taiga/proza_ru.zip'
>>> metas = load_taiga_proza_metas(path)
>>> records = load_taiga_proza(path, metas)
>>> next(records)
TaigaRecord(
id='20151231005',
meta=Meta(
id='20151231005',
timestamp=datetime.datetime(2015, 12, 31, 23, 40),
genre=' ',
topic='',
author=Author(
name='',
readers=7973,
texts=92681,
url='http://www.proza.ru/avtor/sadshoot'
),
title=' !',
url='http://www.proza.ru/2015/12/31/1875'
),
text='... ...\n... ..\n...
)
プルリクエストを作成し、ローダー関数を送信するようにユーザーを招待します。これは、Corusリポジトリでの簡単な説明です。
Naeval-ロシア語を話すNLPのシステムの定量的比較

ナターシャは科学的なプロジェクトではなく、SOTAに勝つという目標はありませんが、パフォーマンスをあまり損なうことなく高い位置を占めるように、公開ベンチマークで品質を確認することが重要です。アカデミーと同じように、品質を測定し、数値を取得し、他の記事からタブレットを取り出し、これらの数値を自分の数値と比較します。このスキームには2つの問題があります。
- パフォーマンスを忘れてください。モデルのサイズや作業速度は比較されません。品質のみに重点が置かれています。
- コードを公開しないでください。品質指標の計算には通常、100万のニュアンスがあります。他の記事ではどの程度正確にカウントされましたか?わからない。
Naevalは、ロシアの自然言語を処理するためのオープンソースツールの品質と速度を評価するための一連のスクリプトであるNatashaプロジェクトの一部です。
| 仕事 | データセット | ソリューション |
| トークン化 | SynTagRus, OpenCorpora, GICRYA, RNC
|
SpaCy, NLTK, MyStem, Moses, SegTok, SpaCy Russian Tokenizer, RuTokenizer, Razdel
|
| SynTagRus, OpenCorpora, GICRYA, RNC
|
SegTok, Moses, NLTK, RuSentTokenizer, Razdel
|
|
| SimLex965, HJ, LRWC, RT, AE, AE2
|
RusVectores, Navec
|
|
| GramRuEval2020 (SynTagRus, GSD, Lenta.ru, Taiga)
|
DeepPavlov Morph, DeepPavlov BERT Morph, RuPosTagger, RNNMorph, Maru, UDPipe, SpaCy, Stanza, Slovnet Morph, Slovnet BERT Morph
|
|
| GramRuEval2020 (SynTagRus, GSD, Lenta.ru, Taiga)
|
DeepPavlov BERT Syntax, UDPipe, SpaCy, Stanza, Slovnet Syntax, Slovnet BERT Syntax
|
|
| NER | factRuEval-2016, Collection5, Gareev, BSNLP-2019, WiNER
|
DeepPavlov NER、DeepPavlov BERT NER、DeepPavlov Slavic BERT NER、PullEnti、SpaCy、Stanza、Texterra、Tomita、MITIE、Slovnet NER、Slovnet BERT NER
|
以下のNER問題を詳しく見てみましょう。
データセット
ロシア語を話すNERには、factRuEval-2016、Collection5、Gareev、BSNLP-2019、WiNERの5つの公開ベンチマークがあります。ソースリンクはCorusレジストリに収集されます。すべてのデータセットはニュース記事で構成され、名前の付いたサブストリング、組織の名前、およびトポニームがテキストでマークされています。何が簡単でしょうか?
すべてのソースには、異なるマークアップ形式があります。 Collection5は、Brat、Gareev、およびWiNERユーティリティのスタンドオフ形式を使用します-BIOマークアップの異なる方言、BSNLP-2019には独自の形式があり、factRuEval-2016にも独自の重要な仕様があります..。Naevalは、すべてのソースを共通の形式に変換します。マークアップはスパンで構成されます。スパン-3:エンティティタイプ、サブストリングの開始と終了。
エンティティタイプ。factRuEval-2016とCollection5は、「Kremlin」、「EU」、「USSR」のハーフネームの半組織を個別にマークします。BSNLP-2019とWiNERは、イベントの名前を強調しています:「ロシアのチャンピオンシップ」、「ブレキシット」。Naevalはいくつかのタグを適応させて削除し、参照タグPER、LOC、ORGを残します:人の名前、トポニームと組織の名前。
ネストされたスパン。実際、RuEval-2016では、スパンが重複しています。Naevalはマークアップを簡素化します。
:
, 5 Retail Group,
org_name───────
Org────────────
"", "" "",
org_descr───── org_name─ org_name─── org_name
Org──────────────────────
org_descr─────
Org─────────────────────────────────────
org_descr─────
Org──────────────────────────────────────────────────
, .
:
, 5 Retail Group,
ORG────────────
"", "" "",
ORG────── ORG──────── ORG─────
, .
モデル
Naevalは、12のオープンソースソリューションをロシアのNER問題と比較しています。すべてのツールは、Webインターフェイスを備えたDockerコンテナにラップされています。
$ docker run -p 8080:8080 natasha/tomita-algfio
2020-07-02 11:09:19 BIN: 'tomita-linux64', CONFIG: 'algfio'
2020-07-02 11:09:19 Listening http://0.0.0.0:8080
$ curl -X POST http://localhost:8080 --data \
' \
\
'
<document url="" di="5" bi="-1" date="2020-07-02">
<facts>
<Person pos="18" len="16" sn="0" fw="2" lw="3">
<Name_Surname val="" />
<Name_FirstName val="" />
<Name_SurnameIsDictionary val="1" />
</Person>
<Person pos="67" len="14" sn="0" fw="8" lw="9">
<Name_Surname val="" />
<Name_FirstName val="" />
<Name_SurnameIsDictionary val="1" />
</Person>
</facts>
</document>
一部のソリューションは、起動と構成が非常に難しいため、使用する人はほとんどいません。PullEnti、洗練されたルールベースのシステムは、2016年にfactRuEval競争の中で第一位を取りました。このツールは、C#用のSDKとして配布されています。Naevalでの作業により、PullEntiのラッパーのセットを含む別のプロジェクトが作成されました。PullentiServerはC#Webサーバーであり、pullenti-clientはPullentiServerのPythonクライアントです。
$ docker run -p 8080:8080 pullenti/pullenti-server
2020-07-02 11:42:02 [INFO] Init Pullenti v3.21 ...
2020-07-02 11:42:02 [INFO] Load lang: ru, en
2020-07-02 11:42:03 [INFO] Load analyzer: geo, org, person
2020-07-02 11:42:05 [INFO] Listen prefix: http://*:8080/
>>> from pullenti_client import Client
>>> client = Client('localhost', 8080)
>>> text = ' ' \
... ' ' \
... ' '
>>> result = client(text)
>>> result.graph
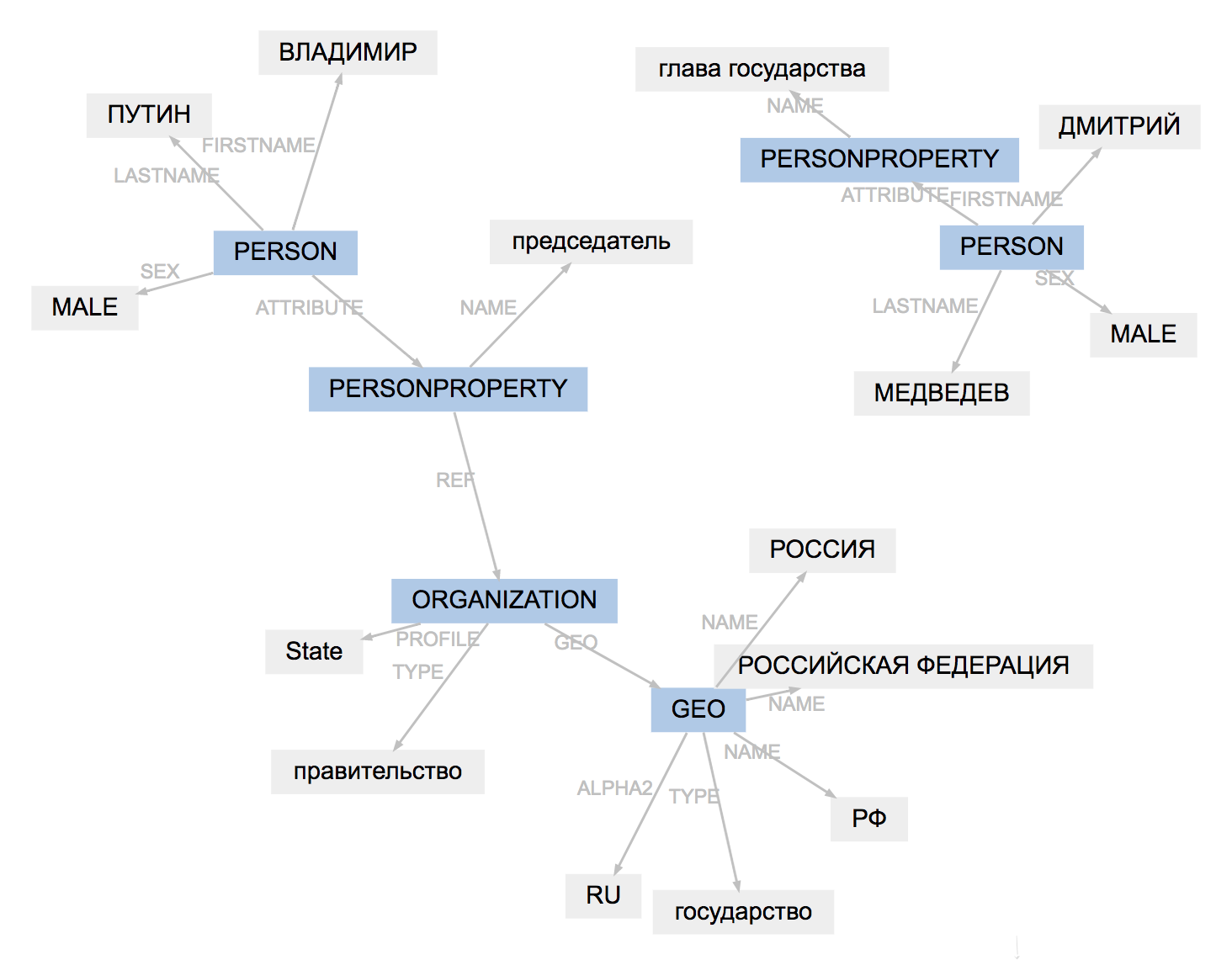
すべてのツールのマークアップ形式は少し異なります。Naevalは結果をロードし、エンティティタイプを適応させ、スパンの構造を簡素化します。
(PullEnti):
, 19
ORGANIZATION──────────
GEO─────────
PERSON────────────────
PERSONPROPERTY───────
──────────────── PERSON───────────────────────
PERSONPROPERTY──────────────
ORGANIZATION───
.
────────────────
:
, 19
ORG────── LOC─────────
PER───────────── ORG────────────
.
PER─────────────
PullEntiの作業の結果は、factRuEval-2016マークアップよりも適応が困難です。アルゴリズムはPERSONPROPERTYタグを削除し、ネストされたPERSON、ORGANIZATION、およびGEOを重複しないPER、LOC、ORGに分割します。
比較
「モデル、データセット」の各ペアについて、NaevalはトークンによるF1メジャーを計算し、品質スコアを含むテーブルを公開します。
ナターシャは科学的なプロジェクトではありません。ソリューションの実用性は私たちにとって重要です。 Naevalは、開始時間、実行速度、モデルサイズ、およびRAM消費量を測定します。リポジトリ内の結果を含むテーブル。
データセットを準備し、Dockerコンテナで20のシステムをラップし、ロシア語NLPの他の5つのタスクのメトリックを計算しました。結果は、トークン化、文へのセグメンテーション、埋め込み、形態および構文分析です。
Yargy- —

YargyパーサーはYandexのの類似体である富田パーサPython用。インストールの手順、使用例、文書Yargyリポジトリインチエンティティを抽出するためのルールは、コンテキストフリーの文法と辞書を使用して説明されています。 2年前、私はHabrに、YargyとNatashaライブラリについての記事を書き、ロシア語のNER問題の解決について話しました。プロジェクトは好評でした。 Sberbank、Interfax、RIA Novosti内の大規模プロジェクトで、Yargy-parserがTomitaに取って代わりました。たくさんの教材が登場しています。 Yandexのワークショップからの大きなビデオ、例を使って文法を開発するプロセスについて1時間半。
ドキュメントが更新され、紹介セクションとリファレンスブックを組み合わせました。最も重要なのは、クックブックが登場したことです。これは、役立つプラクティスのセクションです。これには、t.me / natural_language_processingからの最もよくある質問への回答が含まれています。
Yargyパーサーは複雑なツールです。クックブックでは、大量のルールセットを操作するときに発生する非自明なポイントについて説明しています。
Yargyラボではいくつかの大規模なサービスを実行しています。私はコードを読み直し、公開されていないクックブックに収集されたパターンを読みました。
ドキュメントを読んだ後、例を使用してリポジトリを確認すると便利です。
Natashaプロジェクトには、natasha-usageリポジトリもあります。これは、Githubで公開されているYargyパーサーユーザーのコードが行くところです。リンクの80%は教育プロジェクトですが、有益な例もあります。
- サンクトペテルブルクの地下鉄の仕事に関するフィードの分析;
- ソーシャルネットワークで住宅を配達するための広告の解析。
- 自動車タイヤの名前からの属性の抽出;
- ODSチャットのジョブチャネルからの欠員の解析。
もちろん、Yargyパーサーを使用する最も興味深いケースは、Githubで公開されていません。会社がYargyを使用している場合は、PMに連絡し、気にしない場合は、natasha.github.ioにロゴを追加してください。
Ipymarkup-名前付きエンティティのマークアップと構文上の関係の視覚化

Ipymarkupは、テキスト内のサブストリングを強調表示するために必要なプリミティブライブラリであり、NERの視覚化です。インストール手順、Ipymarkupリポジトリでの使用例。このライブラリは、displaCyおよびdisplaCy ENTに似ており、Yargyパーサーの文法をデバッグするのに非常に役立ちます。
>>> from yargy import Parser
>>> from ipymarkup import show_span_box_markup as show_markup
>>> parser = Parser(...)
>>> text = '...'
>>> matches = parser.findall(text)
>>> spans = [_.span for _ in matches]
>>> show_markup(text, spans)

Natashaプロジェクトには、解析の問題に対する解決策があります。テキスト内の単語を強調表示するだけでなく、それらの間に矢印を描く必要もありました。既成の解決策はたくさんあり、このトピックに関する科学的な記事もあります。
もちろん、既存のものはどれも登場しませんでした。ある日、私は本当に混乱し、CSSとHTMLの有名な魔法をすべて適用し、Ipymarkupに新しい視覚化を追加しました。ドックでの使用方法。
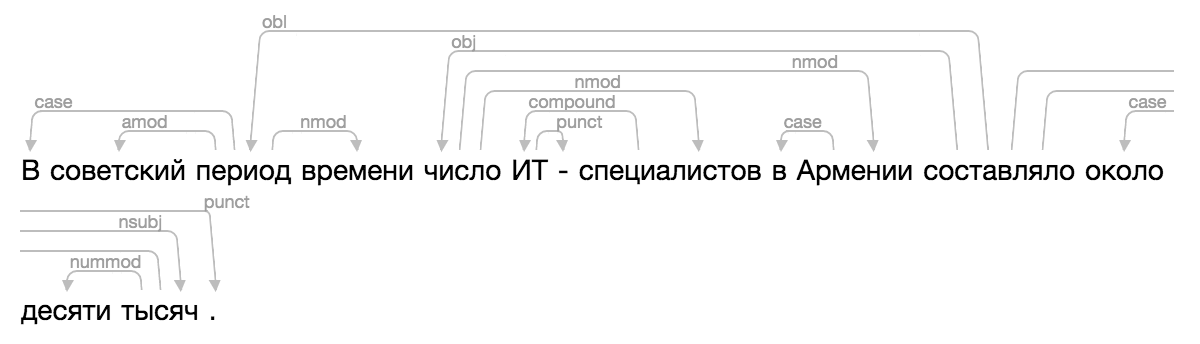
>>> from ipymarkup import show_dep_markup
>>> words = ['', '', '', '', '', '', '-', '', '', '', '', '', '', '', '.']
>>> deps = [(2, 0, 'case'), (2, 1, 'amod'), (10, 2, 'obl'), (2, 3, 'nmod'), (10, 4, 'obj'), (7, 5, 'compound'), (5, 6, 'punct'), (4, 7, 'nmod'), (9, 8, 'case'), (4, 9, 'nmod'), (13, 11, 'case'), (13, 12, 'nummod'), (10, 13, 'nsubj'), (10, 14, 'punct')]
>>> show_dep_markup(words, deps)
現在、ナターシャとネルスでは、解析の結果を確認するのに便利です。
