解析
解析とは何ですか?これは、プロセスを自動化する特別なプログラムを使用してWebサイトに投稿される情報の収集と体系化です。
解析は通常、価格分析とコンテンツ検索に使用されます。
開始
ブックメーカーからお金を集めるために、私はいくつかのサイトから特定のイベントのオッズに関する情報をすぐに受け取らなければなりませんでした。数学的な部分には立ち入りません。
シャラガでC#を勉強したので、全部書くことにしました。Stack Overflowのスタッフは、SeleniumWebDriverの使用をアドバイスしました。これは、ブラウザーの動作を制御するプログラムを開発できるようにするブラウザードライバー(ソフトウェアライブラリ)です。それが私たちに必要なものだと私は思いました。
私はライブラリをインストールし、インターネット上のガイドを見るために走りました。しばらくして、ブラウザを開いていくつかのリンクをたどることができるプログラムを書きました。
やったー!やめても、ボタンの押し方、必要な情報の入手方法は?XPathはここで私たちを助けます。
XPath
簡単に言うと、XMLおよびXHTMLドキュメント要素をクエリするための言語です。
この記事では、GoogleChromeを使用します。ただし、他の最新のブラウザは、同じではないにしても、非常によく似たインターフェイスを備えている必要があります。
現在表示しているページのコードを表示するには、F12キーを押します。

コード内のどこに要素(テキスト、画像、ボタン)があるかを確認するには、左上隅の矢印をクリックして、ページ上のこの要素を選択します。それでは、構文に移りましょう。
XPathを書き込むための標準構文:
// tagname [@ attribute = 'value']
//:現在のノードから始まるhtmlドキュメント内のすべてのノードを選択します
Tagname:現在のノードのタグ。
@:属性を選択します
属性:ノードの属性の名前。
値:属性の値。
最初は混乱するかもしれませんが、例の後、すべてが適切に機能するはずです。
いくつかの簡単な例を見てみましょう 。//input[@type
= 'text']
// label [@ id = 'l25']
// input [@ value = '4']
// a [@ href = 'www.walmart。 com ']
与えられたhtml'iのより複雑な例を考えてみましょう。
<div class ='contentBlock'>
<div class = 'listItem'>
<a class = 'link' href = 'habr.com'>
<span class='name'>habr</span>
</a>
<div class = 'textConainer'>
<span class='description'>cool site</span>
"text2"
</div>
</div>
<div class = 'listItem'>
<a class = 'link' href = 'habr.com'>
<span class='name'>habrhabr</span>
</a>
<div class = 'textConainer'>
<span class='description'>the same site</span>
"text1"
</div>
</div>
</div>XPath = // div [@ class = 'contentBlock'] // div
このXPathには次の要素が選択されます。
<div class = 'listItem'>
<div class = 'textConainer'>
<div class = 'listItem'>
<div class = 'textConainer'>XPath = // div [@ class = 'contentBlock'] / div
<div class = 'listItem'>
<div class = 'listItem'>/(ルートノードからフェッチ)と//(場所に関係なく現在のノードからノードをフェッチ)の違いに注意してください。明確でない場合は、上記の例をもう一度見てください。
// div [@ class = 'contentBlock'] / div [@ class = 'listItem'] / a [@ class = 'link'] / span [@ class = 'name']
このリクエストはこのhtmlと同じです:
// div / div / a / span
// span [@ class = 'name']
// a [@ class = 'link'] / span [@ class = 'name']
// a [@ class = 'リンク 'とhref= 'habr.com'] / span
// span [text()= 'habr' or text()= 'habrhabr']
// div [@ class = 'listItem'] // span [@ class = 'name' ]
// a [contains(href、 'habr')] / span
// span [contains(text()、 'habr')]
結果:
<span class='name'>habr</span>
<span class='name'>habrhabr</span>// span [text()= 'habr'] / parent :: a / parent :: div
Equal to
// div / div [@ class = 'listItem'] [1]
結果:
<div class = 'listItem'>parent :: -親を1レベル上に返します。次の
ような超クールな機能もあります-兄弟:: -現在の要素の後に同じレベルで多くの要素を返します。前の兄弟:: -と同様に、現在の要素の前に同じレベルの多くの要素を返します。
// span [@ class = 'name'] / follow-sibiling :: text()[1]
結果:
"text1"
"text2"今はもっとはっきりしていると思います。資料を統合するために、このサイトにアクセスして、このhtml'iのいくつかの要素を見つけるためにいくつかのリクエストを書くことをお勧めします。
<div class="item">
<a class="link" data-uid="A8" href="https://www.walmart.com/grocery/?veh=wmt" title="Pickup & delivery">
<span class="g_b">Pickup and delivery</span>
</a>
<a class="link" data-uid="A9" href="https://www.walmart.com/" title="Walmart.com">
<span class="g_b">Walmart.com</span>
</a>
</div>
<div class="item">
<a class="link" data-uid="B8" href="https://www.walmart.com/grocery/?veh=wmt" title="Savings spotlight">
<span class="g_b">Savings spotlight</span>
</a>
<a class="link" data-uid="B9" href="https://www.walmartethics.com/content/walmartethics/it_it.html" title="Walmart.com">
<span class="g_b">Walmart.com(Italian)</span>
"italian virsion"
</a>
</div>XPathとは何かがわかったので、コードの記述に戻りましょう。Habrのモデレーターはブックメーカーが好きではないため、ウォルマートのコーヒーの価格を分析します
string pathToFile = AppDomain.CurrentDomain.BaseDirectory + '\\';
IWebDriver driver = new ChromeDriver(pathToFile);
driver.Navigate().GoToUrl("https://walmart.com");
Thread.Sleep(5000);
IWebElement element = driver.FindElement(By.XPath("//button[@id='header-Header sparkButton']"));
element.Click();
Thread.Sleep(2000);
element = driver.FindElement(By.XPath("//button[@data-tl-id='GlobalHeaderDepartmentsMenu-deptButtonFlyout-10']"));
element.Click();
Thread.Sleep(2000);
element = driver.FindElement(By.XPath("//div[text()='Coffee']/parent::a"));
driver.Navigate().GoToUrl(element.GetAttribute("href"));
Thread.Sleep(10000);
List<string> names = new List<string>(), prices = new List<string>();
List<IWebElement> listOfElements =driver.FindElements(By.XPath("//div[@class='tile-content']/div[@class='tile-title']/div")).ToList();
foreach (IWebElement a in listOfElements)
names.Add(a.Text);
listOfElements = driver.FindElements(By.XPath("//div[@class='tile-content']/div[@class='tile-price']/span/span[contains(text(),'$')]")).ToList();
foreach (IWebElement a in listOfElements)
prices.Add(a.Text);
for (int i = 0; i < prices.Count; i++)
Console.WriteLine(names[i] + " " + prices[i]);Thread.Sleepは、Webページをロードする時間ができるように作成されました。
プログラムは、ウォルマートストアのウェブサイトを開き、いくつかのボタンを押し、コーヒーセクションを開き、商品の名前と価格を取得します。
Webページが非常に大きく、XPathに時間がかかるか、作成が難しい場合は、他の方法を使用する必要があります。
HTTPリクエスト
まず、コンテンツがサイトにどのように表示されるかを見てみましょう。

簡単に言うと、ブラウザは必要な情報を提供するように要求してサーバーに要求を出し、サーバーはこの情報を提供します。これはすべて、HTTPリクエストを使用して行われます。
ブラウザが特定のサイトで送信するリクエストを確認するには、このサイトを開き、F12キーを押して[ネットワーク]タブに移動し、ページをリロードします。

今、私たちが必要とする要求を見つけることは残っています。
どうやってするの? -フェッチタイプ(上の図の3番目の列)のすべてのリクエストを検討し、[プレビュー]タブを確認します。

空でない場合は、XMLまたはJSON形式である必要があります。空でない場合は、探し続けます。もしそうなら、あなたが必要とする情報がここにあるかどうか見てください。これを確認するには、何らかのJSONビューアまたはXMLビューアを使用することをお勧めします(Googleで最初のリンクを開き、[応答]タブからテキストをコピーしてビューアに貼り付けます)。必要なリクエストが見つかったら、後で検索しないように、その名前(左側の列)またはURLホスト([ヘッダー]タブ)をどこかに保存します。たとえば、ウォルマートのWebサイトでコーヒー部門が開かれている場合、リクエストが送信されます。そのリーガルはwalmart.com/cp/api/wpaで始まります。販売中のコーヒーに関するすべての情報があります。
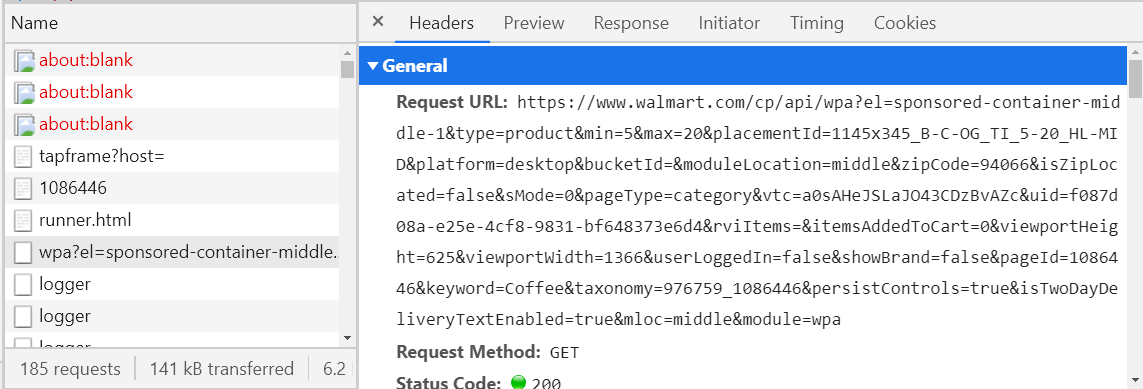
途中でこのリクエストを「偽造」してプログラムからすぐに送信し、必要な情報を数秒で受信できるようになりました。JSONまたはXMLを解析することは残っており、これはXPathを作成するよりもはるかに簡単です。しかし、多くの場合、そのような要求の形成はかなり不快なものであり(上の図のURLを参照)、成功した場合でも、場合によってはそのような応答を受け取ります。
{
"detail": "No authorization token provided",
"status": 401,
"title": "Unauthorized",
"type": "about:blank"
}ここでは、代替手段であるプロキシサーバーを使用してリクエストを模倣する際の問題を回避する方法を学習します。
プロキシサーバー
プロキシサーバーは、コンピューターとインターネットの間を仲介するデバイスです。
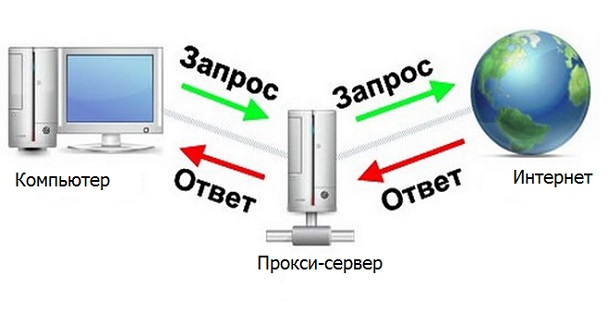
私たちのプログラムがプロキシサーバーであれば、サーバーからの必要な応答をすばやく便利に処理できると便利です。次に、そのようなチェーンブラウザ-プログラム-インターネット(解析されるサイトサーバー)があります。
幸いなことに、si Sharpには、そのようなニーズに対応する素晴らしいライブラリ、Titanium WebProxyがあります。
PServerクラスを作成しましょう
class PServer
{
private static ProxyServer proxyServer;
public PServer()
{
proxyServer = new ProxyServer();
proxyServer.BeforeResponse += OnResponse;
var explicitEndPoint = new ExplicitProxyEndPoint(IPAddress.Loopback, 8000, true);
explicitEndPoint.BeforeTunnelConnectRequest += OnBeforeTunnelConnectRequest;
proxyServer.AddEndPoint(explicitEndPoint);
proxyServer.Start();
}
private async Task OnBeforeTunnelConnectRequest(object sender, TunnelConnectSessionEventArgs e)
{
if (!e.HttpClient.Request.Url.Contains("www.walmart.com")){
e.DecryptSsl = false;
}
}
public async Task OnResponse(object sender, SessionEventArgs e)
{
if (e.HttpClient.Response.StatusCode == 200 && (e.HttpClient.Request.Method == "GET" || e.HttpClient.Request.Method == "POST"))
{
string url = e.HttpClient.Request.Url;
if (url.Contains("walmart.com/cp/api/wpa")){
Console.WriteLine(await e.GetResponseBodyAsString());
}
}
}
}それでは、それぞれの方法を個別に見ていきましょう。
public PServer()
{
proxyServer = new ProxyServer();
proxyServer.BeforeResponse += OnResponse;
var explicitEndPoint = new ExplicitProxyEndPoint(IPAddress.Loopback, 8000, true);
explicitEndPoint.BeforeTunnelConnectRequest += OnBeforeTunnelConnectRequest;
proxyServer.AddEndPoint(explicitEndPoint);
proxyServer.Start();
}proxyServer.BeforeRepsone + = OnRespone-サーバーからの応答を処理するためのメソッドを追加します。応答が到着すると自動的に呼び出されます。
explicitEndPoint -プロキシサーバー設定、
ExplicitProxyEndPoint(たIPAddress ipAddressの、int型ポート、BOOL decryptSsl =真)
たIPAddressとプロキシサーバーが実行されているポート。
decodeSsl -SSLを復号化するかどうか。つまり、decrtyptSsl = trueの場合、プロキシサーバーはすべての要求と応答を処理します。
ExplicitEndPoint.BeforeTunnelConnectRequest + = OnBeforeTunnelConnectRequest-サーバーに送信する前に要求を処理するためのメソッドを追加します。また、リクエストが送信される前に自動的に呼び出されます。
proxyServer.Start() -プロキシサーバーを「開始」します。この瞬間から、要求と応答の処理を開始します。
private async Task OnBeforeTunnelConnectRequest(object sender, TunnelConnectSessionEventArgs e)
{
if (!e.HttpClient.Request.Url.Contains("www.walmart.com")){
e.DecryptSsl = false;
}
}e.DecryptSsl = false-現在の要求と応答は処理されません。
要求またはそれに対する応答(たとえば、写真やある種のスクリプト)に関心がない場合、なぜそれを復号化するのですか?これにはかなりのリソースが費やされ、すべての要求と応答がデコードされると、プログラムは長時間動作します。したがって、現在のリクエストに関心のあるリクエストのホストが含まれていない場合、それを復号化しても意味がありません。
public async Task OnResponse(object sender, SessionEventArgs e)
{
if (e.HttpClient.Response.StatusCode == 200 && (e.HttpClient.Request.Method == "GET" || e.HttpClient.Request.Method == "POST"))
{
string url = e.HttpClient.Request.Url;
if (url.Contains("walmart.com/cp/api/wpa")) Console.WriteLine(await e.GetResponseBodyAsString());
}
}
}await e.GetResponseBodyAsString() -応答を文字列として返します。
WebDriverがプロキシサーバーに接続するには、次のように記述する必要があります。
string pathToFile = AppDomain.CurrentDomain.BaseDirectory + '\\';
ChromeOptions options = new ChromeOptions();
options.AddArguments("--proxy-server=" + IPAddress.Loopback + ":8000");
IWebDriver driver = new ChromeDriver(pathToFile, options);これで、必要な要求を処理できます。
結論
WebDriverを使用すると、ページをナビゲートしたり、ボタンをクリックしたり、通常のユーザーの動作を模倣したりできます。XPathsを使用すると、Webページから必要な情報を抽出できます。XPathが機能しない場合は、プロキシサーバーが常に役立ち、ブラウザーとサイト間の要求を傍受できます。