このツールが登場した理由とその機能について説明します。

アルゴリズムの欠如
機械学習における重要な課題の1つは、データの次元数の削減です。データサイエンティストは、結果に最大の影響を与える値をそれらの間で分離することにより、変数の数を減らします。この操作の後、機械学習モデルは必要なメモリが少なくなり、より速く、より良く機能します。以下の例は、重複する機能を削除すると、分類の精度が0.903から0.943に向上することを示しています。
>>> from sklearn.linear_model import SGDClassifier
>>> from ITMO_FS.embedded import MOS
>>> X, y = make_classification(n_samples=300, n_features=10, random_state=0, n_informative=2)
>>> sel = MOS()
>>> trX = sel.fit_transform(X, y, smote=False)
>>> cl1 = SGDClassifier()
>>> cl1.fit(X, y)
>>> cl1.score(X, y)
0.9033333333333333
>>> cl2 = SGDClassifier()
>>> cl2.fit(trX, y)
>>> cl2.score(trX, y)
0.9433333333333334次元数の削減には、機能の設計と機能の選択という2つのアプローチがあります。バイオインフォマティクスや医学などの分野では、セマンティクスを維持しながら重要な機能を強調表示できるため、後者がよく使用されます。つまり、機能の本来の意味は変わりません。ただし、最も一般的なPythonマシン学習ライブラリ(scikit-learn、pytorch、keras、tensorflow)には、機能選択メソッドの完全なセットがありません。
この問題を解決するために、ITMO大学の学生と大学院生はオープンライブラリであるITMO_FSを開発しました。チームは、情報技術およびプログラミング学部の准教授であるIvanSmetannikovのリーダーシップの下でそれに取り組んでいます。、機械学習研究所の副所長。主任開発者-機械学習とデータ分析の修士号を卒業したNikitaPilnenskiy 。今、彼は大学院に通っています。
« , . , , , (-) .
, , , . , , , ».
—
ITMO_FSはPythonで実装され、事実上の主要なデータ分析ツールと見なされているscikit-learnと互換性があります。その機能セレクターは同じパラメーターを取ります。
data: array-like (2-D list, pandas.Dataframe, numpy.array);
targets: array-like (1-D list, pandas.Series, numpy.array).このライブラリは、機能選択に対するすべての従来のアプローチ(フィルター、ラッパー、インラインメソッド)をサポートしています。その中には、SpearmanとPearsonの相関に基づくフィルター、Fit Criterion、QPFS、ヒルクライミングフィルターなどのアルゴリズムがあります。

ライブラリは、使用されている重要度の尺度に基づいて機能選択アルゴリズムを組み合わせることにより、トレーニングアンサンブルもサポートします。このアプローチにより、少ない時間でより高い予測結果を得ることができます。
類似物は何ですか
特にPythonには、機能選択アルゴリズムライブラリは多くありません。最大の1つは、アリゾナ州立大学(ASU)のエンジニアの育成と見なされています。多数のアルゴリズムをサポートしていますが、最近はほとんど更新されていません。
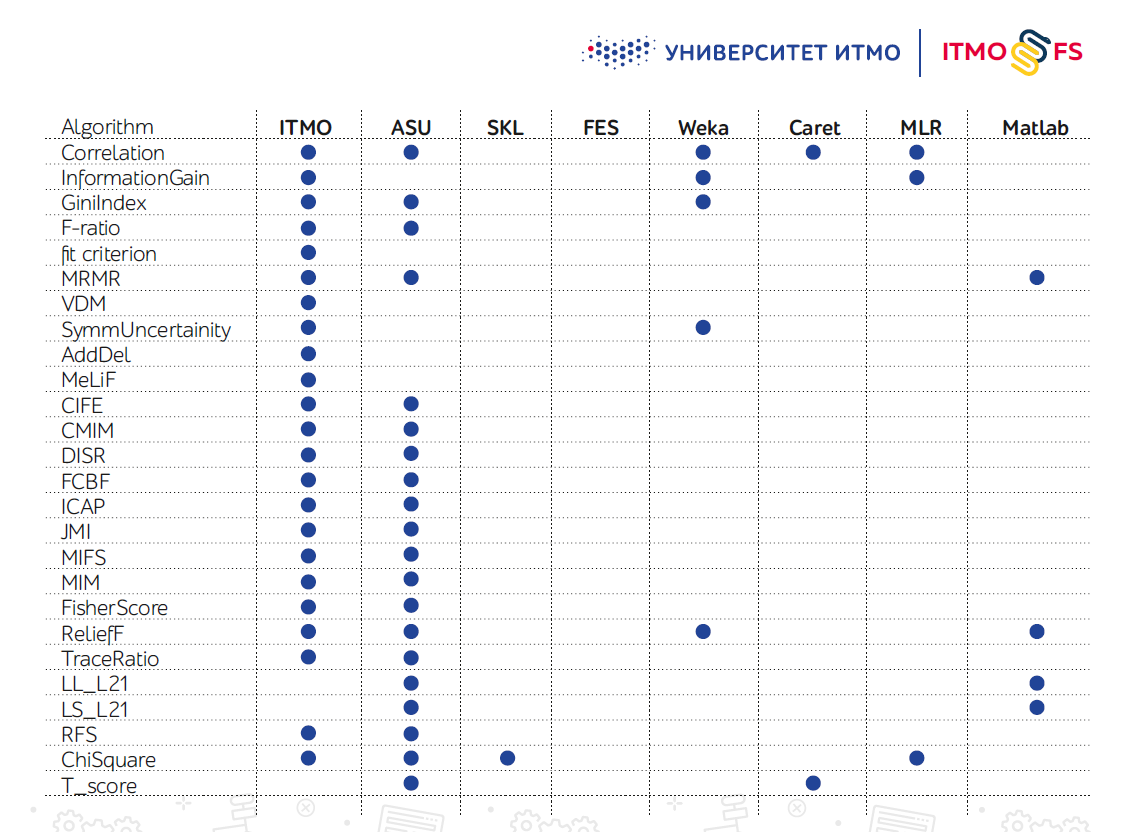
Scikit-learn自体にもいくつかの機能選択メカニズムがありますが、実際にはそれらだけでは不十分です。
「一般に、過去5〜7年間で、機能選択のためのアンサンブルアルゴリズムに焦点が移っていますが、これらは特に修正したいライブラリには含まれていません。」
-イワン・スメタニコフ
プロジェクトの見通し
ITMO_FSの作成者は、公式に互換性のあるライブラリのリストに製品を追加することにより、製品をscikit-learnと統合することを計画しています。現時点では、ライブラリにはすでにすべてのライブラリの中で最大数の機能選択アルゴリズムが含まれていますが、それらの追加は継続されます。さらにロードマップには、独自の開発を含む新しいアルゴリズムの追加があります。
より遠い計画では、ライブラリをメタ学習システムに導入し、マトリックスデータを直接操作するためのアルゴリズムを追加する(ギャップを埋める、メタ属性空間データを生成するなど)、およびグラフィカルインターフェイスを追加するタスクがあります。これと並行して、より多くの開発者が製品に興味を持ち、フィードバックを得るために、ライブラリを使用してハッカソンが開催されます。
ITMO_FSは、さまざまな癌の診断、表現型の特徴(たとえば、人の年齢)の予測モデルの構築、薬物の合成などの問題において、医学およびバイオインフォマティクスの分野での応用が期待されています。
どこでダウンロードできますか
ITMO_FSプロジェクトに興味がある場合は、ライブラリをダウンロードして実際に試すことができます。これがGitHubのリポジトリです。ドキュメントの初期バージョンは、readthedocsで入手できます。そこにインストール手順も表示されます(pipでサポートされています)。フィードバックをお待ちしております。
Habréに関するブログからの追加資料: