しかし、これらのソリューションのすべてに私が必要なものがありませんでした:
- 一元化されたインストール
- アクセス権を考慮した検索結果
- ドキュメントの内容で検索
- 形態学
そして、自分で作ることにしました。
解釈の違いや誤解を避けるために、私が持っているものを1つずつフォームに開示します。
一元化されたインストール-クライアント-サーバーの実行。上記のすべてのソリューションには、1つの基本的な問題があります。各ユーザーが独自のローカル検索インデックスを作成します。これは、ストレージボリュームが大きい場合、インデックス作成を遅らせ、マシン上のユーザーのプロファイルが大きくなり、新しい従業員が新しいマシンに到着したり移動したりする場合に一般的に不便です。
権利を考慮した検索結果(ここではすべてが単純です)結果は、ファイルリソースに対する従業員の権利に対応している必要があります。そうしないと、従業員がリソースに対する権限を持っていなくても、検索キャッシュからすべてを読み取ることができることがわかります。それは厄介になるでしょう、同意しますか?ドキュメントのコンテンツで検索-ドキュメントのテキストで検索します。ここではすべてが明白であり、私には思えますが、矛盾はありません。
形態はさらに単純です。クエリ「knife」で指定され、「knife」と「knives」、「knife」と「knife」の両方を受け取りました。これがロシア語と英語で機能することが望ましい。
問題の定式化を決定し、実装に進むことができます。
検索エンジンとしてSphinxシステムを選択し、インターフェース開発言語はC#と.netでした。その結果、プロジェクトはフランスの探偵にちなんでVidocq(Vidocq)と名付けられました。まあ、のように、それはすべてを見つけて、それだけです。
アーキテクチャ上、アプリケーションは次のようになります。
検索ロボットはファイルリソースを再帰的にクロールし、指定された拡張子のリストに従ってファイルを処理します。処理は、ファイルのコンテンツの取得、テキストの圧縮で構成されます。引用符、コンマ、余分なスペースなどがテキストから削除され、コンテンツがデータベース(MS SQL)に配置され、配置日がマークされ、ロボットが先に進みます。
Sphinsインデクサーは、受信したベースと直接連携して独自のインデックスを形成し、見つかったファイルへのポインターと、見つかったテキストフラグメントのスニペットを応答として返します。
MySQLコネクタを介してSphinxと通信するフォームがC#で開発されました。Sphinxは要求に応じてファイルの配列を提供し、次に配列は検索しているユーザーのアクセス権のためにフィルタリングされ、出力はフォーマットされてユーザーに表示されます。
ファイルに関する次の情報を保存する必要があります。
- ファイルID
- ファイル名
- ファイルへのパス
- ファイルの内容
- 拡張
- データベースに追加された日付
これはすべて1つのテーブルで行われ、検索ロボットがすべてをテーブルに追加します。追加の日付は、次のラウンドのロボットがファイルの変更日とデータベースに配置された日付を比較し、日付が異なる場合はファイルに関する情報を更新するために必要です。
次に、検索エンジン自体を設定します。構成全体については説明しません。プロジェクトアーカイブで利用できるようになりますが、要点のみを説明します。 ソースドキュメント
ベースを形成する主なリクエスト
:documents_base
{
sql_query = \
select \
DocumentId as 'Id', \
DocumentPath as 'Path', \
DocumentTitle as 'Title', \
DocumentExtention as 'Extension', \
DocumentContent as 'Content' \
from \
VidocqDocs
}レンマタイザーを介して形態を設定します。
index documents
{
source = documents
path = D:/work/VidocqSearcher/Sphinx/data/index
morphology = lemmatize_ru_all, lemmatize_en_all
}その後、ベースにインデクサーを設定して作業を確認できます。
d:\work\VidocqSearcher\Sphinx\bin\indexer.exe documents --config D:\work\VidocqSearcher\Sphinx\bin\main.conf –rotateここで、インデクサーへのパスの後に、処理されたインデックスを配置するインデックスの名前、構成へのパス、および–rotateフラグが続きます。これは、インデックス作成がオンザフライで実行されることを意味します。検索サービスが実行されている状態。インデックス作成が完了すると、インデックスは更新されたインデックスに置き換えられます。
コンソールで作業を確認します。インターフェイスとして、たとえばWebサーバーキットから取得したMySQLクライアントを使用できます。
mysql -h 127.0.0.1 -P 9306そのリクエストの後、ドキュメントからIDを選択します。もちろん、Sphinxサービス自体を開始し、すべてを正しく実行した場合は、インデックス付きドキュメントのリストを返す必要があります。
さて、コンソールは素晴らしいですが、ユーザーにコマンドの入力を強制するつもりはありませんよね?
私はこのようなフォームをスケッチしました
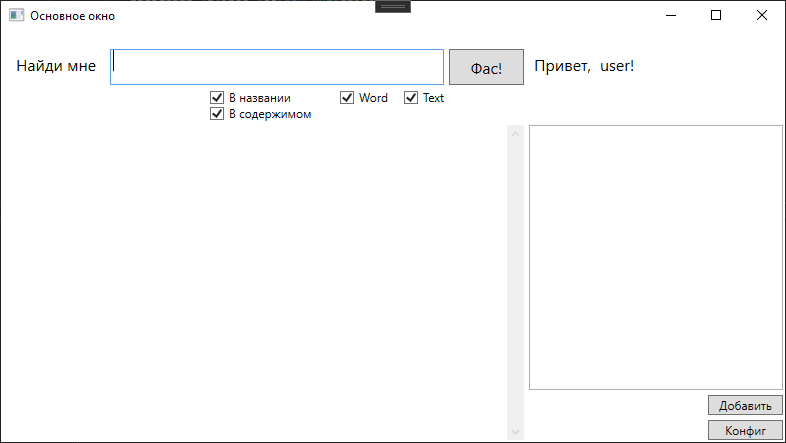
そしてここに検索結果

があります特定の結果をクリックすると、ドキュメントが開きます。
実装方法。
using MySql.Data.MySqlClient;
string connectionString = "Server=127.0.0.1;Port=9306";
var query = "select id, title, extension, path, snippet(content, '" + textBoxSearch.Text.Trim() + "', 'query_mode=1') as snippet from documents " +
"where ";
if (checkBoxTitle.IsChecked == true && checkBoxContent.IsChecked == true)
{
query += "match ('@(title,content)" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxTitle.IsChecked == false && checkBoxContent.IsChecked == true)
{
query += "match ('@content" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxTitle.IsChecked == true && checkBoxContent.IsChecked == false)
{
query += "match ('@title" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxWord.IsChecked == true && checkBoxText.IsChecked == true)
{
query += "and extension in ('.docx', '.doc', '.txt');";
}
if (checkBoxWord.IsChecked == true && checkBoxText.IsChecked == false)
{
query += "and extension in ('.docx', '.doc');";
}
if (checkBoxWord.IsChecked == false && checkBoxText.IsChecked == true)
{
query += "and extension in ('.txt');";
}はい、bydlocコードがありますが、これはMVPです。
実際には、設定されたチェックボックスに応じて、スフィンクスへのリクエストがここで形成されます。チェックボックスは、検索するファイルのタイプと検索領域を示します。
次に、リクエストはSphinxに送信され、結果が解析されます。
using (var command = new MySqlCommand(query, connection))
{
connection.Open();
using (var reader = command.ExecuteReader())
{
while (reader.Read())
{
var id = reader.GetUInt16("id");
var title = reader.GetString("title");
var path = reader.GetString("path");
var extension = reader.GetString("extension");
var snippet = reader.GetString("snippet");
bool isFileExist = File.Exists(path);
if (isFileExist == true)
{
System.Windows.Controls.RichTextBox textBlock = new RichTextBox();
textBlock.IsReadOnly = true;
string xName = "id" + id.ToString();
textBlock.Name = xName;
textBlock.Tag = path;
textBlock.GotFocus += new System.Windows.RoutedEventHandler(ShowClickHello);
snippet = System.Text.RegularExpressions.Regex.Replace(snippet, "<.*?>", String.Empty);
Paragraph paragraph = new Paragraph();
paragraph.Inlines.Add(new Bold(new Run(path + "\r\n")));
paragraph.Inlines.Add(new Run(snippet));
textBlock.Document = new FlowDocument(paragraph);
StackPanelResult.Children.Add(textBlock);
}
else
{
counteraccess--;
}
}
}
}同じ段階で、問題が生成されます。問題の各要素は、クリックするとドキュメントを開くためのイベントを含むリッチテキストボックスです。アイテムはStackPanelに配置され、その前にファイルがユーザーに対してチェックされます。したがって、ユーザーがアクセスできないファイルは出力に含まれません。
このソリューションの利点:
- インデックス作成は一元的に行われます
- アクセス権に基づく正確な表示
- ドキュメントタイプによるカスタマイズ可能な検索
もちろん、このようなソリューションを本格的に運用するには、社内でファイルアーカイブを適切に整理する必要があります。理想的には、ローミングユーザープロファイルなどを構成する必要があります。はい、SharePoint、Windows Search、そしておそらくさらにいくつかのソリューションについて知っています。次に、開発プラットフォーム、検索エンジンSphinx、Manticore、Elasticなどの選択について延々と話し合うことができます。しかし、私は少し理解できるツールで問題を解決することに興味がありました。現在MVPモードで実行されていますが、開発中です。
しかし、いずれにせよ、私はどの点を改善するか、または芽の中でやり直すことができるかについてのあなたの提案を聞く準備ができています。