
この記事の目的は、MLflowの最初の経験を共有することです。追跡サーバーからMLflowの
レビューを開始し、調査のすべての反復を続行します。次に、UDFを使用してSparkをMLflowに接続した経験を共有します。
環境
でアルファ健康、我々は彼らの健康と幸福の世話をするためにEMPOWERの人々に機械学習と人工知能を使用しています。これが、機械学習モデルが私たちが開発するデータ製品の中心である理由です。そのため、機械学習ライフサイクルのすべての側面をカバーするオープンソースプラットフォームであるMLflowに注目が集まりました。
MLflow
MLflowの主な目標は、データサイエンティストがほぼすべての機械学習ライブラリ(h2o、keras、mleap、pytorch、sklearn、tensorflow)を操作できるようにする、機械学習の上に追加のレイヤーを提供して、それを次のレベルに引き上げることです。
MLflowは、次の3つのコンポーネントを提供します。
- 追跡-実験の記録と照会:コード、データ、構成、および結果。モデル作成プロセスに従うことは非常に重要です。
- プロジェクト-任意のプラットフォーム(SageMakerなど)で実行するパッケージ形式
- モデルは、さまざまな展開ツールにモデルを送信するための一般的な形式です。
MLflow(この記事の執筆時点ではアルファ版)は、実験、再利用、展開などの機械学習ライフサイクルを管理できるオープンソースプラットフォームです。
MLflowの構成
我々が使用するだろうことをするためにMLflow全体Python環境をセットアップするには、あなたの最初の必要性を使用するには、PyEnvを(Mac上のPythonをインストールするには、見てみましょうここに)。したがって、実行に必要なすべてのライブラリをインストールする仮想環境を作成できます。
```
pyenv install 3.7.0
pyenv global 3.7.0 # Use Python 3.7
mkvirtualenv mlflow # Create a Virtual Env with Python 3.7
workon mlflow
```必要なライブラリをインストールします。
```
pip install mlflow==0.7.0 \
Cython==0.29 \
numpy==1.14.5 \
pandas==0.23.4 \
pyarrow==0.11.0
```注:UDFなどのモデルを実行するためにPyArrowを使用しています。最新バージョンが競合していたため、PyArrowバージョンとNumpyバージョンを修正する必要がありました。
トラッキングUIを起動します
MLflow Trackingを使用すると、PythonとREST APIを使用して、ログに記録し、実験にリクエストを送信できます。さらに、モデルアーティファクト(localhost、Amazon S3、Azure Blob Storage、Google Cloud Storage、またはSFTPサーバー)を保存する場所を定義できます。 Alpha HealthでAWSを使用しているため、アーティファクトのストレージとしてS3が使用されます。
# Running a Tracking Server
mlflow server \
--file-store /tmp/mlflow/fileStore \
--default-artifact-root s3://<bucket>/mlflow/artifacts/ \
--host localhost
--port 5000MLflowは、永続ファイルストレージの使用を推奨しています。ファイルストレージは、サーバーが実行および実験のメタデータを保存する場所です。サーバーを起動するときは、永続的なファイルストレージを指していることを確認してください。ここでは、実験に使用します
/tmp。
mlflowサーバーを使用して古い実験を実行する場合は、ファイルストアに存在する必要があることに注意してください。ただし、これがなくても、モデルへのパスのみが必要なため、UDFで使用できます。
注:トラッキングUIとモデルクライアントは、アーティファクトの場所にアクセスできる必要があることに注意してください。つまり、トラッキングUIがEC2インスタンスにあるという事実に関係なく、MLflowがローカルで起動される場合、アーティファクトモデルを書き込むには、マシンがS3に直接アクセスできる必要があります。
トラッキングUIはアーティファクトをS3バケットに保存します
実行中のモデル
Tracking Serverが実行されたら、モデルのトレーニングを開始できます。
例として、SklearnのMLflowの例からのワインの変更を使用します。
MLFLOW_TRACKING_URI=http://localhost:5000 python wine_quality.py \
--alpha 0.9
--l1_ration 0.5
--wine_file ./data/winequality-red.csvすでに述べたように、MLflowを使用すると、モデルのパラメーター、メトリック、およびアーティファクトをログに記録できるため、反復しながらモデルがどのように発展するかを追跡できます。この機能は非常に便利です。この方法では、トラッキングサーバーに接続するか、git hash commitログを使用して必要な反復を実行したコードを理解することにより、最適なモデルを再現できます。
with mlflow.start_run():
... model ...
mlflow.log_param("source", wine_path)
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1_ratio", l1_ratio)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
mlflow.set_tag('domain', 'wine')
mlflow.set_tag('predict', 'quality')
mlflow.sklearn.log_model(lr, "model")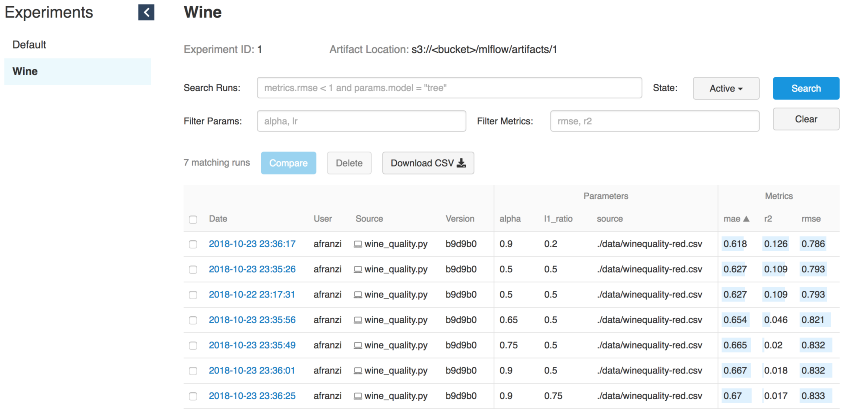
ワインの繰り返し
モデルのサーバー部分
「mlflowserver」コマンドで起動されたMLflow追跡サーバーには、起動を追跡してローカルファイルシステムにデータを書き込むためのRESTAPIがあります。「MLFLOW_TRACKING_URI」環境変数を使用して追跡サーバーアドレスを指定できます。MLflow追跡APIは、このアドレスの追跡サーバーに自動的に接続して、起動情報、ログメトリックなどを作成/取得します。モデルにサーバーを提供するには、実行中の追跡サーバー(起動インターフェイスを参照)とモデルの実行IDが必要です。
出典:ドキュメント//追跡サーバーの実行

実行ID
# Serve a sklearn model through 127.0.0.0:5005
MLFLOW_TRACKING_URI=http://0.0.0.0:5000 mlflow sklearn serve \
--port 5005 \
--run_id 0f8691808e914d1087cf097a08730f17 \
--model-path modelMLflowサーブ機能を使用してモデルをサーブするには、トラッキングUIにアクセスして、を指定するだけでモデルに関する情報を取得する必要があります
--run_id。
モデルがTrackingServerと通信すると、新しいモデルエンドポイントを取得できます。
# Query Tracking Server Endpoint
curl -X POST \
http://127.0.0.1:5005/invocations \
-H 'Content-Type: application/json' \
-d '[
{
"fixed acidity": 3.42,
"volatile acidity": 1.66,
"citric acid": 0.48,
"residual sugar": 4.2,
"chloridessssss": 0.229,
"free sulfur dsioxide": 19,
"total sulfur dioxide": 25,
"density": 1.98,
"pH": 5.33,
"sulphates": 4.39,
"alcohol": 10.8
}
]'
> {"predictions": [5.825055635303461]}Sparkからモデルを実行
追跡サーバーはモデルをリアルタイムで提供するのに十分強力であるという事実にもかかわらず、モデルをトレーニングして提供機能を使用します(ソース:mlflow // docs //モデル#ローカル)、Spark(バッチまたはストリーミング)の使用はさらに強力なソリューションです。配布アカウント。
オフライントレーニングを行ってから、出力モデルをすべてのデータに適用したとします。これは、SparkとMLflowが最高の状態を示す場所です。
PySpark + Jupyter + Sparkをインストールします
出典:はじめにPySpark-Jupyter
MLflowモデルをSparkデータフレームに適用する方法を示すには、PySparkと連携するようにJupyterノートブックを設定する必要があります。
最新の安定版インストールすることで起動しますApacheのスパークを:
cd ~/Downloads/
tar -xzf spark-2.4.3-bin-hadoop2.7.tgz
mv ~/Downloads/spark-2.4.3-bin-hadoop2.7 ~/
ln -s ~/spark-2.4.3-bin-hadoop2.7 ~/spark̀仮想環境にPySparkとJupyterをインストールします。
pip install pyspark jupyter環境変数を設定します。
export SPARK_HOME=~/spark
export PATH=$SPARK_HOME/bin:$PATH
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS="notebook --notebook-dir=${HOME}/Projects/notebooks"決定したら
notebook-dir、ノートブックを目的のフォルダーに保存できます。
PySparkからJupyterを起動
JupiterをPySparkドライバーとして設定できたので、PySparkコンテキストでJupyterノートブックを実行できるようになりました。
(mlflow) afranzi:~$ pyspark
[I 19:05:01.572 NotebookApp] sparkmagic extension enabled!
[I 19:05:01.573 NotebookApp] Serving notebooks from local directory: /Users/afranzi/Projects/notebooks
[I 19:05:01.573 NotebookApp] The Jupyter Notebook is running at:
[I 19:05:01.573 NotebookApp] http://localhost:8888/?token=c06252daa6a12cfdd33c1d2e96c8d3b19d90e9f6fc171745
[I 19:05:01.573 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 19:05:01.574 NotebookApp]
Copy/paste this URL into your browser when you connect for the first time,
to login with a token:
http://localhost:8888/?token=c06252daa6a12cfdd33c1d2e96c8d3b19d90e9f6fc171745
前述のように、MLflowはS3でモデルアーティファクトをログに記録するための機能を提供します。選択したモデルが手元にあるとすぐに、モジュールを使用してUDFとしてインポートする機会があります
mlflow.pyfunc。
import mlflow.pyfunc
model_path = 's3://<bucket>/mlflow/artifacts/1/0f8691808e914d1087cf097a08730f17/artifacts/model'
wine_path = '/Users/afranzi/Projects/data/winequality-red.csv'
wine_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = spark.read.format("csv").option("header", "true").option('delimiter', ';').load(wine_path)
columns = [ "fixed acidity", "volatile acidity", "citric acid",
"residual sugar", "chlorides", "free sulfur dioxide",
"total sulfur dioxide", "density", "pH",
"sulphates", "alcohol"
]
df.withColumn('prediction', wine_udf(*columns)).show(100, False)
PySpark-ワイン品質予測の出力
これまで、ワインデータセット全体でワイン品質予測を実行することにより、MLflowでPySparkを使用する方法について説明してきました。しかし、ScalaSparkのPythonMLflowモジュールを使用する必要がある場合はどうでしょうか。
SparkコンテキストをScalaとPythonの間で分割することにより、これもテストしました。つまり、MLflow UDFをPythonで登録し、Scalaから使用しました(はい、おそらく最善の解決策ではありませんが、私たちが持っているものです)。
Scala Spark + MLflow
この例では、Toreeカーネルを既存のJupiterに追加します。
Spark + Toree + Jupyterをインストールします
pip install toree
jupyter toree install --spark_home=${SPARK_HOME} --sys-prefix
jupyter kernelspec list
```
```
Available kernels:
apache_toree_scala /Users/afranzi/.virtualenvs/mlflow/share/jupyter/kernels/apache_toree_scala
python3 /Users/afranzi/.virtualenvs/mlflow/share/jupyter/kernels/python3
```添付のノートブックからわかるように、UDFはSparkとPySparkの間で共有されています。この部分が、Scalaを愛し、機械学習モデルを本番環境に展開したい人に役立つことを願っています。
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.{Column, DataFrame}
import scala.util.matching.Regex
val FirstAtRe: Regex = "^_".r
val AliasRe: Regex = "[\\s_.:@]+".r
def getFieldAlias(field_name: String): String = {
FirstAtRe.replaceAllIn(AliasRe.replaceAllIn(field_name, "_"), "")
}
def selectFieldsNormalized(columns: List[String])(df: DataFrame): DataFrame = {
val fieldsToSelect: List[Column] = columns.map(field =>
col(field).as(getFieldAlias(field))
)
df.select(fieldsToSelect: _*)
}
def normalizeSchema(df: DataFrame): DataFrame = {
val schema = df.columns.toList
df.transform(selectFieldsNormalized(schema))
}
FirstAtRe = ^_
AliasRe = [\s_.:@]+
getFieldAlias: (field_name: String)String
selectFieldsNormalized: (columns: List[String])(df: org.apache.spark.sql.DataFrame)org.apache.spark.sql.DataFrame
normalizeSchema: (df: org.apache.spark.sql.DataFrame)org.apache.spark.sql.DataFrame
Out[1]:
[\s_.:@]+
In [2]:
val winePath = "~/Research/mlflow-workshop/examples/wine_quality/data/winequality-red.csv"
val modelPath = "/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model"
winePath = ~/Research/mlflow-workshop/examples/wine_quality/data/winequality-red.csv
modelPath = /tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model
Out[2]:
/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model
In [3]:
val df = spark.read
.format("csv")
.option("header", "true")
.option("delimiter", ";")
.load(winePath)
.transform(normalizeSchema)
df = [fixed_acidity: string, volatile_acidity: string ... 10 more fields]
Out[3]:
[fixed_acidity: string, volatile_acidity: string ... 10 more fields]
In [4]:
%%PySpark
import mlflow
from mlflow import pyfunc
model_path = "/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model"
wine_quality_udf = mlflow.pyfunc.spark_udf(spark, model_path)
spark.udf.register("wineQuality", wine_quality_udf)
Out[4]:
<function spark_udf.<locals>.predict at 0x1116a98c8>
In [6]:
df.createOrReplaceTempView("wines")
In [10]:
%%SQL
SELECT
quality,
wineQuality(
fixed_acidity,
volatile_acidity,
citric_acid,
residual_sugar,
chlorides,
free_sulfur_dioxide,
total_sulfur_dioxide,
density,
pH,
sulphates,
alcohol
) AS prediction
FROM wines
LIMIT 10
Out[10]:
+-------+------------------+
|quality| prediction|
+-------+------------------+
| 5| 5.576883967129615|
| 5| 5.50664776916154|
| 5| 5.525504822954496|
| 6| 5.504311247097457|
| 5| 5.576883967129615|
| 5|5.5556903912725755|
| 5| 5.467882654744997|
| 7| 5.710602976324739|
| 7| 5.657319539336507|
| 5| 5.345098606538708|
+-------+------------------+
In [17]:
spark.catalog.listFunctions.filter('name like "%wineQuality%").show(20, false)
+-----------+--------+-----------+---------+-----------+
|name |database|description|className|isTemporary|
+-----------+--------+-----------+---------+-----------+
|wineQuality|null |null |null |true |
+-----------+--------+-----------+---------+-----------+
次のステップ
MLflowは執筆時点ではアルファ版ですが、かなり有望に見えます。複数の機械学習フレームワークを実行し、それらを単一のエンドポイントから使用するという単なる機能により、推奨システムが次のレベルに引き上げられます。
さらに、MLflowは、データエンジニアとデータサイエンティストの間に共通のレイヤーを作成することで、それらを近づけます。
MLflowでこの調査を行った後、Sparkパイプラインと推奨システムにMLflowを使用できると確信しています。
ファイルシステムではなく、ファイルストレージをデータベースと同期すると便利です。このようにして、同じファイルストレージを使用できる複数のエンドポイントを取得する必要があります。たとえば、Prestoの複数のインスタンスを使用しますと同じGlueメタストアを持つAthena。
要約すると、データを使った作業をより面白くしてくれたMLFlowコミュニティに感謝します。
MLflowで遊んでいる場合は、遠慮なく私たちに書いて、それをどのように使用するかを教えてください。本番環境で使用する場合はさらにそうです。
コースの詳細:
機械学習。基本的な機械学習コース
。上級コース
続きを読む: