機械学習について説明します。ニューラルネットワーク(パート1):パーセプトロンをトレーニングするプロセス
この記事では、ニューラルネットワークを使用して論理OR操作の実行をモデル化します。 XORは、ニューラルネットワーク用の一種の「HelloWorld」アプリケーションです。
この記事では、TensorFlow.jsを使用したこのようなモデリングのプロセスについて段階的に説明します。
それでは、論理OR操作用のニューラルネットワークを構築しましょう。入力では、我々は常に2つの信号X与える1及びX 2を、そして出力で、我々はニューラルネットワークを訓練するための一つの出力信号Yを受信します、我々はまた、トレーニングデータセット(図1)が必要です。

図1 - Aのトレーニングデータセットと論理和演算をモデル化するためのモデル
、セットへのニューラルネットワークのどのような構造を理解するのは、座標軸Xと座標平面上のトレーニングデータセットを想像してみましょうするには1およびX 2を(図2、左)。
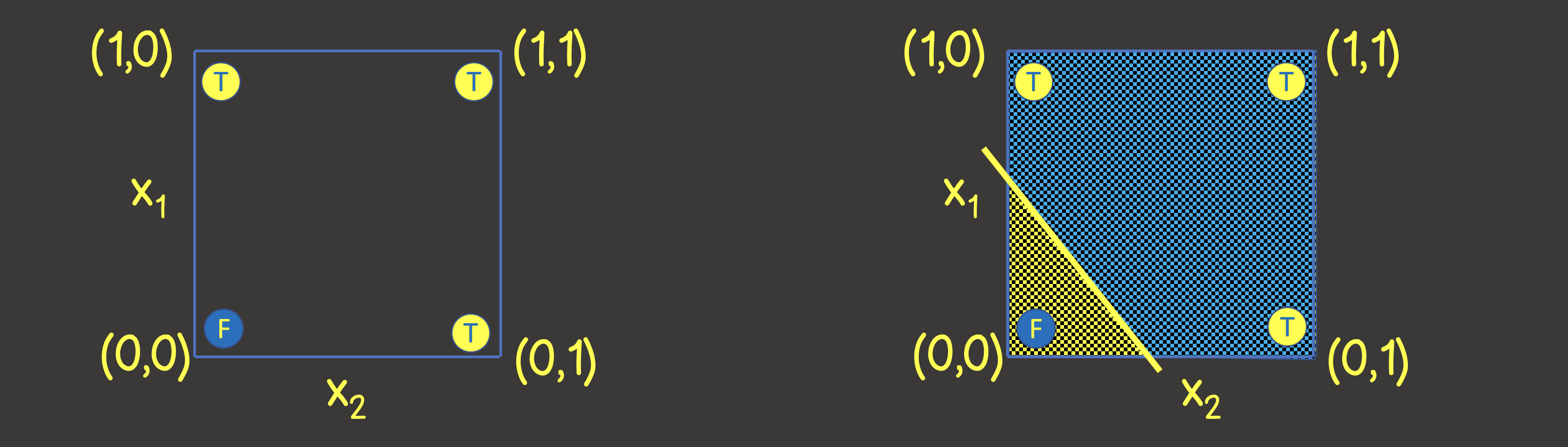
図2-論理OR操作用の座標平面上のトレーニングセット
この問題を解決するには、線の片側にすべてTRUE値があり、反対側にすべてFALSE値があるように平面を分割する線を引くだけで十分であることに注意してください(図2、右)。また、ニューラルネットワーク(パーセプトロン)内の1つのニューロンがこの目的に完全に対処できることもわかっています。その出力値は、入力信号から次のように計算されます。
これは、線の方程式の数学的表現です。
私たちの値が0から1の範囲にあるという事実を考慮して、シグモイド活性化関数も適用します。したがって、ニューラルネットワークは図3のようになります。

図3-論理OR操作をトレーニングするためのニューラルネットワークでは、
TensorFlow.jsを使用してこの問題を解決しましょう。
まず、トレーニングデータセットをテンサーに変換する必要があります。テンソルは、持つことができるデータのコンテナです軸と各軸に沿った任意の数の要素。ほとんどのテンサーは数学に精通しています-ベクトル(1軸のテンサー)、行列(2軸のテンサー-行、列)。
トレーニングデータセットを定義するために、最初の軸(軸0)は常に、使用可能なすべてのデータサンプルインスタンスが配置される軸です(図4)。
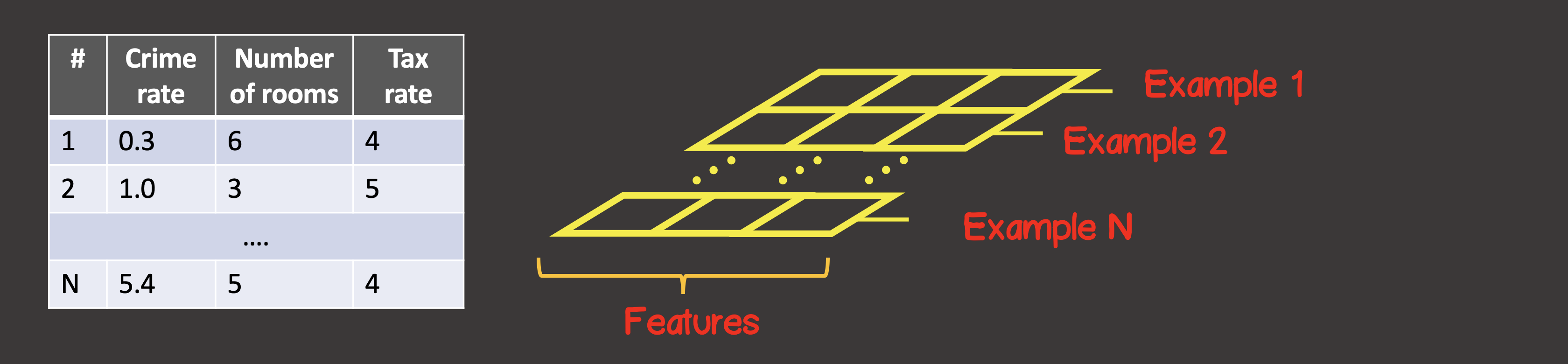
図4-テンソル構造
特定のケースでは、データサンプルのインスタンスが4つあります(図1)。これは、最初の軸に沿った入力テンソルが4つの要素を持つことを意味します。訓練サンプルの各要素は、2つの要素Xからなるベクトルである1、X 2。したがって、入力テンソルには2つの軸(マトリックス)があり、最初の軸に沿って4つの要素があり、2番目の軸に沿って-2つの要素があります。
const input = [[0, 0], [1, 0], [0, 1], [1, 1]];
const inputTensor = tf.tensor(input, [input.length, 2]);
同様に、出力をテンソルに変換します。入力信号に関しては、最初の軸に沿って4つの要素があり、各要素には1つの値を含むベクトルが含まれています。
const output = [[0], [1], [1], [1]]
const outputTensor = tf.tensor(output, [output.length, 1]);
TensorFlowAPIを使用してモデルを作成しましょう。
const model = tf.sequential();
model.add(
tf.layers.dense({ inputShape: [2], units: 1, activation: 'sigmoid' })
);
モデルの作成は、常にtf.sequential()の呼び出しから始まります。モデルの主要な構成要素はレイヤーです。ニューラルネットワーク内の必要な数のレイヤーをモデルに接続できます。ここでは、密な レイヤーを使用します。これは、次のレイヤーのすべてのニューロンが前のレイヤーのすべてのニューロンと接続していることを意味します。たとえば、2つの密なレイヤーがある場合、最初のレイヤーに ニューロン、そして2番目に- の場合、レイヤー間の接続の総数は次のようになります。 ..。
私たちの場合、ご覧のとおり、ニューラルネットワークは1つの層で構成されており、その中に1つのニューロンがあるため、単位は1に設定されます。
また、ニューラルネットワークの第1の層に、我々は設定する必要がありinputShapeを各入力インスタンスは二つの値Xのベクトルで表現されるので、1及びX 2従って、inputShape = [2] 。中間レイヤーにinputShapeを設定する必要がないことに注意してください。TensorFlowは、前のレイヤーの単位値からこの値を決定できます。
また、必要に応じて、各レイヤーにアクティベーション関数を割り当てることができます。これはシグモイド関数であると上記で判断しました。 TensorFlowで現在利用可能なアクティベーション関数はここにあります。
次に、モデルをコンパイルする必要があります(ここでAPIを参照)が、2つの必須パラメーターを設定する必要があります-これはエラー関数であり、最小値を探すオプティマイザーの種類です。
model.compile({
optimizer: tf.train.sgd(0.1),
loss: 'meanSquaredError'
});
0.1のトレーニングステップでオプティマイザーとして確率的勾配降下を設定しました。
ライブラリに実装されているオプティマイザのリスト:tf.train.sgd、tf.train.momentum、tf.train.adagrad、tf.train.adadelta、tf.train.adam、tf.train.adamax、tf.train.rmsprop。
実際には、デフォルトでは、sgdとは対照的に、モデルの収束率が最も高いadamオプティマイザーをすぐに選択できます。トレーニングの各段階での学習率は、前のステップの履歴に応じて設定され、学習プロセス全体を通じて一定ではありません。
エラー関数として、ルート平均二乗エラー関数によって与えられます。
モデルが設定され、次のステップはモデルをトレーニングするプロセスです。このため、モデルでfitメソッドを呼び出す必要があります。
async function initModel() {
// skip for brevity
await model.fit(trainingInputTensor, trainingOutputTensor, {
epochs: 1000,
shuffle: true,
callbacks: {
onEpochEnd: async (epoch, { loss }) => {
// any actions on during any epoch of training
await tf.nextFrame();
}
}
})
}
学習プロセスは100の学習ステップ(学習エポックの数)で構成されるように設定しました。また、連続する各エポックで、入力データをランダムな順序でシャッフルする必要があります(shuffle = true)。これにより、トレーニングデータセットにインスタンスがほとんどないため、モデルの収束プロセスが高速化されます(4)。
トレーニングプロセスの完了後、新しい入力信号に基づいて出力値を計算する予測メソッドを使用できます。
const testInput = generateInputs(10);
const testInputTensor = tf.tensor(testInput, [testInput.length, 2]);
const output = model.predict(testInputTensor).arraySync();
generateInputs メソッドは、座標平面を100個の正方形に分割する10x10のサンプルデータセットを生成するだけです。
完全なコードはここにあります
import React, { useEffect, useState } from 'react';
import LossPlot from './components/LossPlot';
import Canvas from './components/Canvas';
import * as tf from "@tensorflow/tfjs";
let model;
export default () => {
const [data, changeData] = useState([]);
const [lossHistory, changeLossHistory] = useState([]);
useEffect(() => {
async function initModel() {
const input = [[0, 0], [1, 0], [0, 1], [1, 1]];
const inputTensor = tf.tensor(input, [input.length, 2]);
const output = [[0], [1], [1], [1]]
const outputTensor = tf.tensor(output, [output.length, 1]);
const testInput = generateInputs(10);
const testInputTensor = tf.tensor(testInput, [testInput.length, 2]);
model = tf.sequential();
model.add(
tf.layers.dense({ inputShape:[2], units:1, activation: 'sigmoid'})
);
model.compile({
optimizer: tf.train.adam(0.1),
loss: 'meanSquaredError'
});
await model.fit(inputTensor, outputTensor, {
epochs: 100,
shuffle: true,
callbacks: {
onEpochEnd: async (epoch, { loss }) => {
changeLossHistory((prevHistory) => [...prevHistory, {
epoch,
loss
}]);
const output = model.predict(testInputTensor)
.arraySync();
changeData(() => output.map(([out], i) => ({
out,
x1: testInput[i][0],
x2: testInput[i][1]
})));
await tf.nextFrame();
}
}
})
}
initModel();
}, []);
return (
<div>
<Canvas data={data} squareAmount={10}/>
<LossPlot loss={lossHistory}/>
</div>
);
}
function generateInputs(squareAmount) {
const step = 1 / squareAmount;
const input = [];
for (let i = 0; i < 1; i += step) {
for (let j = 0; j < 1; j += step) {
input.push([i, j]);
}
}
return input;
}
次の図では、学習プロセスの一部が表示されます。

プランナーの実装:
論理演算XORのシミュレーション
この関数のトレーニングセットを図6に示します。また、論理演算ORの場合と同様に、これらのポイントを座標平面に配置し
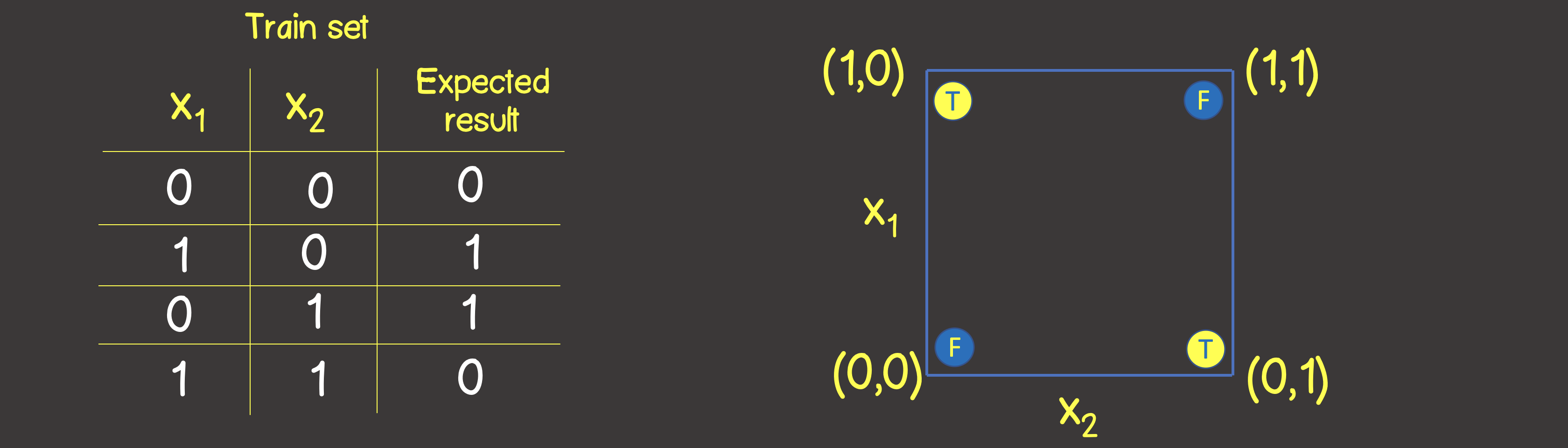
ます。図6-論理演算をモデル化するためのトレーニングデータセットとモデルEXCLUSIVE OR(XOR)
注意してください。論理OR演算とは対照的に、平面を1つの直線で分割することはできないため、一方の側にはすべてTRUE値があり、もう一方の側にはすべてFALSEがあります。ただし、これは2つの曲線を使用して行うことができます(図7)。
明らかに、この場合、レイヤー内の1つのニューロンでは不十分です。2つのニューロンを持つレイヤーが少なくとももう1つ必要です。各レイヤーは、平面上の2つの線の1つを定義します。
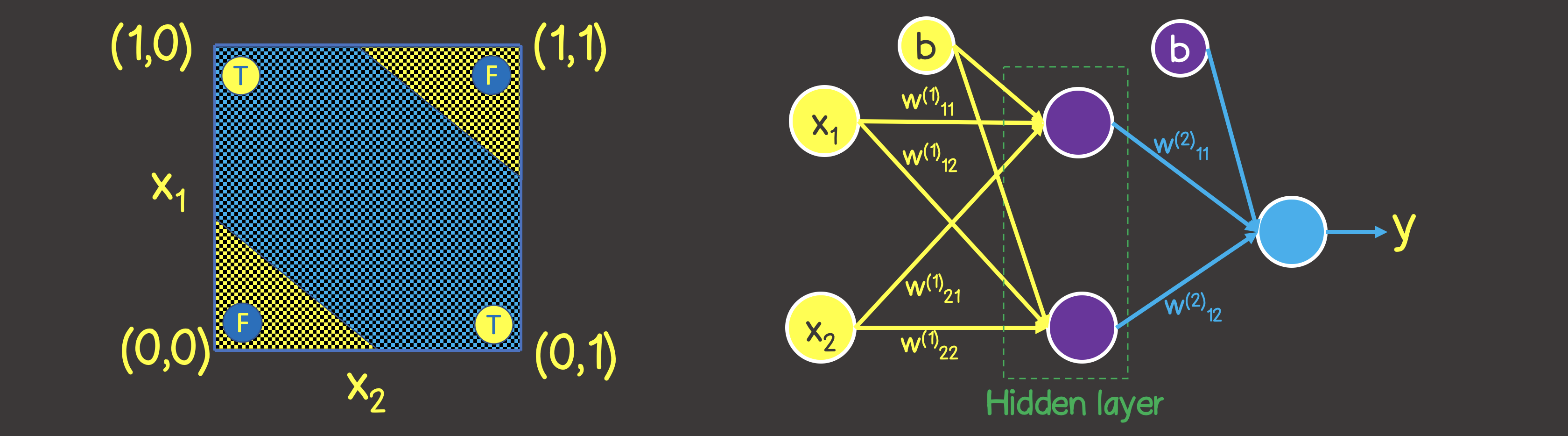
図7-論理演算のニューラルネットワークモデルEXCLUSIVEOR(XOR)
前のコードでは、いくつかの場所で変更を加える必要があります。そのうちの1つはトレーニングデータセット自体です。
const input = [[0, 0], [1, 0], [0, 1], [1, 1]];
const inputTensor = tf.tensor(input, [input.length, 2]);
const output = [[0], [1], [1], [0]]
const outputTensor = tf.tensor(output, [output.length, 1]);
2番目の場所は、図7に従って、モデルの構造が変更されたことです。
model = tf.sequential();
model.add(
tf.layers.dense({ inputShape: [2], units: 2, activation: 'sigmoid' })
);
model.add(
tf.layers.dense({ units: 1, activation: 'sigmoid' })
);
この場合の学習プロセスは次のようになります。

プランナーの実装:
次の記事のトピック
次の記事では、いくつかの機能のリストに基づいて、オブジェクトのカテゴリへの分類に関連する問題を解決する方法について説明します。