私のチームと私は、Rosbankのパートナーとのビジネス開発の方向性を代表しています。今日は、システム間の直接統合、GreenOCRに基づく画像とテキストの認識に関する人工知能、RF法、およびトレーニング用のサンプルの準備を使用して、銀行業務プロセスを自動化した成功した経験についてお話したいと思います。

それでは、始めましょう。 Rosbankには、パートナー銀行に代表される借り手の口座を開設するためのビジネスプロセスがあります。自動化までの既存のプロセスは、すべての規制要件とSociete Generale Groupの要件に従い、クライアントごとに最大20分の運用時間を要しました。このプロセスには、バックオフィスによるドキュメントのスキャンの受信、各ドキュメントへの入力の正確さのチェック、銀行の情報システム全体へのドキュメントフィールドの投稿、その他のいくつかのチェックが含まれ、最後にアカウントを開設します。これはまさに「アカウントを開く」ボタンの背後にあるプロセスです。
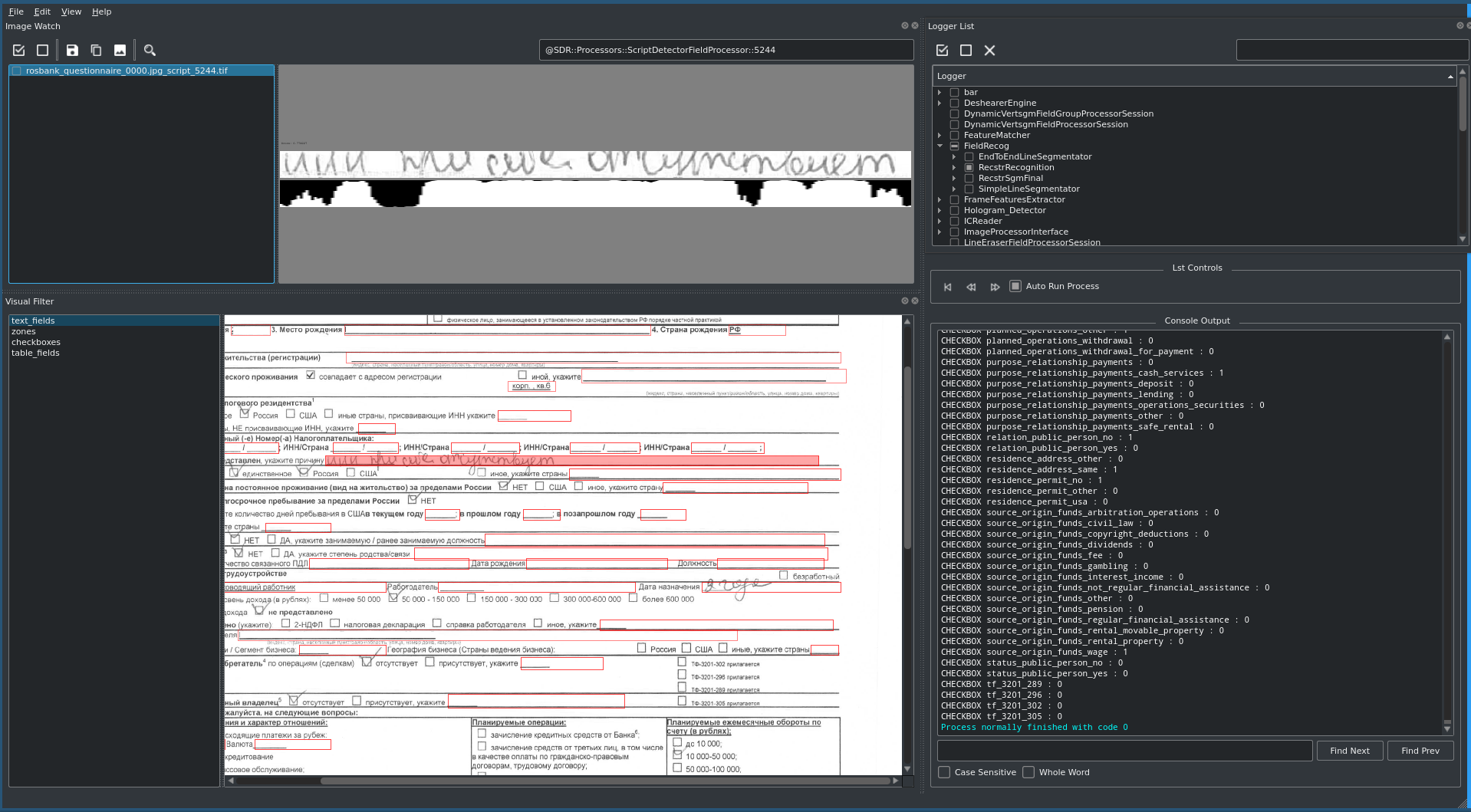
文書の主なフィールド(姓、名、後援、クライアントの生年月日など)は、受け取ったほぼすべての種類の文書に含まれており、銀行のさまざまなシステムに入力されると複製されます。最も複雑なドキュメントであるKYCアンケート(Know Your Customer-Know your customer)は、8ポイントのフォントで満たされた印刷可能なA4形式であり、約170のテキストフィールドとチェックボックス、および表形式のビューが含まれています。
私たちは何をしましたか?
私たちの主な目標は、口座開設の時間を最小限に抑えることでした。
プロセスの分析は、それが必要であることを示しました:
- 各ドキュメントの手動検証の数を減らします。
- 異なる銀行システムの同じフィールドの入力を自動化します。
- システム間のドキュメントのスキャンの移動を減らします。
問題(1)と(2)を解決するために、銀行にすでに実装されているGreenOCRベースの画像およびテキスト認識ソリューションを使用することが決定されました(作業名は「認識機能」です)。ビジネスプロセスで使用されるドキュメントの形式は標準ではないため、チームは「認識機能」の要件を作成し、ニューラルネットワーク(サンプル)をトレーニングするための例を準備するという課題に直面しました。
問題(2)と(3)を解決するには、システムとシステム間の統合を改善する必要がありました。
JuliaAleksashinaが率いる私たちのチーム
- アレクサンダーバシュコフ-内部システム開発(.Net)
- Valentina Sayfullina-ビジネス分析、テスト
- Grigory Proskurin-システム間の統合(.Net)
- Ekaterina Panteleeva-ビジネス分析、テスト
- Sergey Frolov-プロジェクト管理、モデル品質分析
- 外部ベンダーからの参加者(Philosophy.itと組み合わせたSmart Engines)
認識トレーニング
ビジネスプロセスで使用されるクライアントドキュメントのセットは次のとおりです。
- パスポート;
- 同意-印刷されたフォームA4、1リットル;
- 弁護士の権限-印刷されたフォームA4、2 l;
- KYC質問票-印刷されたフォームA4、1リットル;
まず、ドキュメントを徹底的に調査し、動的フィールドを使用した認識機能の作業だけでなく、静的テキスト、手書きデータを使用したフィールド、一般に境界に沿ったドキュメント認識などの改善を含む要件を作成しました。
パスポート認識はGreenOCRシステムのボックス機能に含まれており、変更は必要ありませんでした。
他のタイプのドキュメントについては、分析の結果、「認識機能」が返す必要のある属性と特性が特定されました。同時に、次の点を考慮する必要がありました。これにより、認識プロセスが複雑になり、使用するアルゴリズムが著しく複雑になる必要がありました。
- , . , «» ;
- 8- . , ;
- ( ) ;
- ;
- , , ;
- ;
最初は、タスクはそれほど複雑ではなく、かなり標準的に見えました。
要件->ベンダー->モデル->モデルのテスト->プロセスの開始
テストが失敗した場合、モデルは再トレーニングのためにベンダーに返されます。
毎日膨大な数のドキュメントのスキャンを受け取り、モデルをトレーニングするためのサンプルを準備することは問題ではなかったはずです。個人データのすべての処理は、連邦法「個人データに関する」N152-FZの要件に準拠する必要があります。クライアントの個人データの処理に対するクライアントの同意は、Rosbank内でのみ利用できます。モデルをトレーニングするためにクライアントのドキュメントをベンダーに転送することはできません。
問題を解決する3つの方法が検討されました。
- , , , , ;
- . , – () , ;
- () . , , , , , ;
チームで提案されたオプションを分析し、それらの実装の速度と考えられるリスクに関して、3番目のオプションを選択しました。モデルをトレーニングするためのドキュメントを模倣する方法です。このプロセスの主な利点は、可能な限り広い範囲のスキャンデバイスをカバーして、キャリブレーションとモデルの改良の反復回数を減らすことができることです。
ドキュメントテンプレートはhtml形式で実装されました。一連のテストデータとマクロが迅速かつ効率的に準備され、テンプレートに合成データが入力され、印刷が自動化されました。次に、印刷可能なフォームをpdf形式で生成し、各ファイルに一意の識別子を割り当てて、「デコーダー」から受信した応答を確認しました。
ニューラルネットワークのトレーニング、領域のマーキング、およびフォームのカスタマイズは、ベンダー側で行われました。
時間枠が限られているため、モデルのトレーニングは2つの段階に分けられました。
最初の段階では、モデルはドキュメントのタイプを認識し、ドキュメント自体の内容を「大まかに」認識するようにトレーニングされました。
要件->ベンダー->テストデータの準備->データ収集->フォーム認識のためのモデルのトレーニング->フォームのテスト->モデルのセットアップ
第2段階では各タイプのドキュメントの内容を認識するためのモデルの詳細なトレーニングがありました。第2段階でのモデルのトレーニングと実装は、次のスキームで説明できます。これは、すべてのタイプのドキュメントで同じです。
さまざまな解像度でのテストデータの準備->データの収集とベンダーへの転送->モデルのトレーニング->モデルのテスト->モデルのキャリブレーション->モデルの実装->戦闘での結果の確認->問題のケースの特定->問題のケースのシミュレーションとベンダーへの転送->テストからのステップの繰り返し
使用されたスキャナーの範囲が非常に広いにもかかわらず、モデルをトレーニングするための例では、まだ多くのデバイスが提示されていないことに注意してください。したがって、モデルの戦闘への導入はパイロットモードで行われ、その結果は自動化には使用されませんでした。パイロットモードでの作業中に取得されたデータは、さらなる分析と分析のためにデータベースにのみ記録されました。
テスト
モデルトレーニングループはベンダー側にあり、銀行のシステムに接続されていなかったため、各トレーニングサイクルの後、モデルはベンダーによって銀行に転送され、そこでテスト環境でテストされました。検証に成功した場合、モデルをトレーニング時に考慮されなかった特殊なケースを特定するために、モデルが認証環境に転送され、そこで回帰テストが行われた後、産業環境に転送されました。
銀行の境界で、データがモデルに送信され、結果がデータベースに記録されました。データ品質分析は、万能のExcelを使用して実行されました-ピボットテーブル、式を使用したロジック、およびそれらの組み合わせvlookup、hlookup、index、len、match、およびif関数による文字ごとの文字列比較を使用します。
シミュレートされたドキュメントを使用したテストにより、最大数のテストシナリオを実行し、プロセスを可能な限り自動化することができました。
まず、手動モードで、すべてのフィールドの戻り値が、各タイプのドキュメントの元の要件に準拠しているかどうかを確認しました。次に、さまざまな長さのテキストブロックを動的に埋めるときのモデルの応答を確認しました。目標は、テキストが行から行へ、およびページからページへ移動するときの応答の品質をテストすることでした。最後に、スキャンしたドキュメントの品質に応じて、フィールドの回答の品質を確認しました。モデルの最高品質のキャリブレーションには、ドキュメントの低解像度スキャンが使用されました。
最も多くのフィールドとチェックボックスを含む最も複雑なドキュメントであるKYCアンケートに特に注意を払う必要があります。彼のために、ドキュメントに記入するための特別なスクリプトが事前に準備され、自動化されたマクロが作成されました。これにより、テストプロセスを高速化し、すべての可能なデータの組み合わせをチェックし、モデルを調整するためにベンダーに迅速にフィードバックを提供することができました。
統合と内部開発
銀行のシステムの必要な改訂とシステム間の統合は事前に実行され、銀行のテスト環境に表示されました。
実現されるシナリオは、次の段階で構成されます。
- ドキュメントの受信スキャンの受け入れ。
- 受信したスキャンを「認識機能」に送信します。送信は、最大10スレッドの同期モードと非同期モードで可能です。
- 「認識機能」から応答を受信し、受信したデータを確認および検証します。
- ドキュメントの元のスキャンを銀行の電子ライブラリに保存します。
- 「認識者」から受け取ったデータを処理する銀行のシステムの開始と、その後の従業員による検証。
結果
現在、モデルのトレーニングは完了しており、銀行の実稼働環境でのビジネスプロセスのテストと実装が成功しています。実行された自動化により、アカウントを開くための平均時間を20分から5分に短縮することができました。以前は手動で実行されていた、ドキュメントデータの認識と入力のためのビジネスプロセスの面倒な段階が自動化されました。同時に、人的要因によるエラーの可能性が大幅に減少します。さらに、異なる銀行システムの同じドキュメントから取得されたデータのIDが保証されます。