
並行して実行されるクエリは、順次実行されるクエリよりも少ないCPUを使用し、高速に実行できますか?
はい!デモンストレーションでは、1つの列タイプを持つ2つのテーブルを使用します
integer。

注-テキスト形式のTSQLスクリプトは、記事の最後にあります。
デモデータの生成
#BuildInt5,000個のランダムな整数を
テーブルに挿入します(私のものと同じ値になるように、シードとWHILEループでRANDを使用します)。5,000,000レコードを

テーブルに
#Probe挿入します。

シーケンシャルプラン
次に、これらのテーブルの値の一致数をカウントするクエリを作成しましょう。MAXDOP 1ヒントを使用して、クエリが並行して実行されないようにします。
その実行計画と統計は次のとおりです。

このクエリは891ミリ秒かかり、890ミリ秒のCPUを使用します。
並行計画
ここで、MAXDOP 2を使用して同じクエリを実行してみましょう。

クエリには221ミリ秒かかり、436ミリ秒のCPUを使用します。実行時間が4分の1に短縮され、CPU使用量が半分になりました。
マジックビットマップ
並列クエリの実行がはるかに効率的である理由は、ビットマップ演算子のためです。
並列クエリの実際の実行計画を詳しく見てみましょう。

それを順次計画と比較します。

ビットマップ演算子の原理は十分に文書化されているため、ここでは、記事の最後にある文書へのリンクを含む簡単な説明のみを提供します。
ハッシュ参加
ハッシュ結合は2つのステップで行われます。
- 「構築」の段階(英語-構築)。いずれかのテーブルのすべての行が読み取られ、結合キーのハッシュテーブルが作成されます。
- 「検証」の段階(英語-プローブ)。2番目のテーブルのすべての行が読み取られ、同じ接続キーを使用して同じハッシュ関数によってハッシュが計算され、一致するバケットがハッシュテーブルで見つかります。
当然、ハッシュの衝突が発生する可能性があるため、キーの実際の値を比較する必要があります。
翻訳者のメモ:ハッシュ結合の仕組みの詳細については、ハッシュマッチ 結合の視覚化と処理の記事を参照してください。
シーケンシャルプランのビットマップ
多くの人は、ハッシュマッチがシーケンシャルリクエストであっても、常にビットマップを使用することを知りません。ただし、このような計画では、ハッシュ一致演算子の内部実装の一部であるため、明示的に表示されません。
ハッシュテーブルを作成および作成する段階でのHASHJOINは、ビットマップに1つ(または複数)のビットを設定します。その後、ビットマップを使用して、ハッシュテーブルにアクセスするオーバーヘッドなしに、ハッシュ値を効率的に照合できます。
シーケンシャルプランでは、2番目のテーブルの行ごとにハッシュが計算され、ビットマップと照合されます。ビットマップの対応するビットが設定されている場合、ハッシュテーブルに一致する可能性があるため、次にハッシュテーブルがチェックされます。逆に、ハッシュ値に対応するビットが設定されていない場合は、ハッシュテーブルに一致するものがないことを確認でき、チェックされた文字列をすぐに破棄できます。
ビットマップを構築するための比較的低いコストは、ハッシュテーブルに完全に一致するものがない文字列をチェックしないことによる時間の節約によって相殺されます。ビットマップのチェックはハッシュテーブルのチェックよりもはるかに高速であるため、この最適化は多くの場合効果的です。
並行計画のビットマップ
並列プランでは、ビットマップは個別のビットマップステートメントとして表示されます。
構築段階から検証段階に移行するとき、ビットマップは2番目の(プローブ)テーブルの側からHASHMATCHオペレーターに渡されます。少なくとも、ビットマップはJOINと交換演算子(並列処理)の前にプローブ側に渡されます。
ここで、ビットマップは、交換ステートメントに渡される前に結合条件を満たさない文字列を除外できます。
もちろん、シーケンシャルプランには交換ステートメントがないため、ビットマップをHASH JOINの外に移動しても、HASHMATCHステートメント内の「埋め込み」ビットマップに勝る追加の利点はありません。
状況によっては(並列プランのみですが)、オプティマイザーはビットマップを接続のプローブ側の平面のさらに下に移動する場合があります。
ここでの考え方は、行のフィルタリングが早ければ早いほど、ステートメント間でデータを移動するために必要なオーバーヘッドが少なくなり、一部の操作を排除できる可能性さえあるということです。
また、オプティマイザは通常、単純なフィルタを葉のできるだけ近くに配置しようとします。行をできるだけ早くフィルタリングするのが最も効率的です。ただし、ここで説明しているビットマップは、最適化が完了した後に追加されることに注意する必要があります。
最適化後にこの(静的)タイプのビットマップをプランに追加するかどうかの決定は、フィルターの予想される選択性に基づいて行われます(したがって、正確な統計が重要です)。
ビットマップフィルターの移動
ビットマップフィルターを接続のプローブ側に移動するという概念に戻りましょう。
多くの場合、ビットマップフィルターはスキャンまたはシークステートメントに移動できます。これが発生すると、プラン述語は次のようになります。

シーク述語(インデックスシークの場合)に一致するすべての行、またはインデックススキャンまたはテーブルスキャンのすべての行に適用されます。たとえば、上のスクリーンショットは、ヒープテーブルのテーブルスキャンに適用されたビットマップフィルターを示しています。
深くなる..。
ビットマップフィルターがintegerまたはbigint型の単一の列または式に基づいて構築され、integerまたはbigint型の単一の列に適用される場合、Bitmap演算子は、SeekまたはScan演算子よりもさらに先に移動できます。
述語は、上記の例のようにScanまたはSeekステートメントに引き続き表示されますが、INROW属性でマークされます。これは、フィルターがストレージエンジンに移動され、読み取られるときに行に適用されることを意味します。
この最適化では、クエリプロセッサが行を認識する前に行がフィルタリングされます。 HASH MATCHJOINに一致する文字列のみがストレージエンジンから送信されます。
この最適化が適用される条件は、SQLServerのバージョンによって異なります。たとえば、SQL Server 2005では、前に指定した条件に加えて、プローブ列をNOTNULLとして定義する必要があります。この制限は
SQLServer2008で緩和されました。INROWの最適化がパフォーマンスにどのように影響するのか疑問に思われるかもしれません。オペレーターをシークまたはスキャンにできるだけ近づけることは、ストレージエンジンでのフィルタリングと同じくらい効率的ですか?この興味深い質問には他の記事で答えます。そして、ここではMERGEJOINとNESTEDLOOPJOINについても見ていきます。
その他のJOINオプション
インデックスなしでネストされたループを使用することは悪い考えです。他のテーブルからすべての行についてテーブルの1つを完全にスキャンする必要があります-合計50億の比較。このリクエストには非常に長い時間がかかる可能性があります。
マージ参加
このタイプの物理結合にはソートされた入力が必要なため、強制的なMERGE JOINにより、その前にソートが存在します。シーケンシャルプランは次のようになり
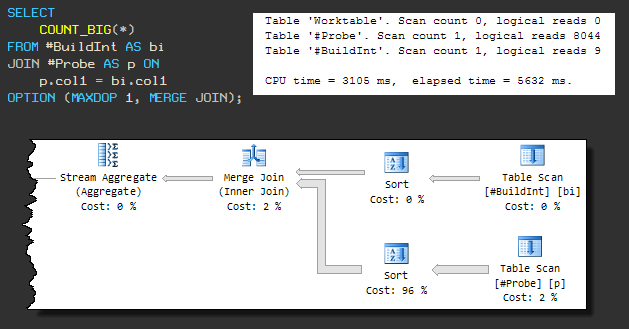
ます。クエリは3105msのCPUを使用し、合計実行時間は5632msです。
全体的な実行時間の増加は、ソート操作の1つがtempdbを使用しているためです(SQL Serverにはソートに十分なメモリがありますが)。
tempdbへのリークは、デフォルトのメモリ許可アルゴリズムが十分なメモリを事前に予約していないために発生します。これに注意を払うまで、リクエストが3105ミリ秒以内に完了しないことは明らかです。
引き続きMERGEJOINを強制しますが、並列処理を許可します(MAXDOP 2):

前に見た並列HASH JOINと同様に、ビットマップフィルターはMERGE JOINの反対側、テーブルスキャンに近い位置にあり、INROW最適化を使用して適用されます。468ミリ秒のCPUと240ミリ秒の経過時間、MERGEは、追加のソートとJOIN平行ハッシュ(JOINとほぼ同じ速度で436ミリ秒/ 221ミリ秒)。
ただし、並列MERGE JOINには1つの欠点があります。それは、ソートする行の予想数に基づいて330KBのメモリを予約することです。これらのタイプのビットマップはコスト最適化後に使用されるため、2488行のみが最下位の並べ替えを通過する場合でも、見積もりは調整されません。
ビットマップステートメントは、後続のブロッキングステートメント(たとえば、並べ替え)でのみMERGEJOINを使用してプランに表示できます。ブロッキングオペレーターは、出力する最初の行を生成する前に、必要なすべての値を入力として受け取る必要があります。これにより、JOINテーブルの行が読み取られてチェックされる前に、ビットマップが完全にいっぱいになります。
ブロッキングステートメントがMERGEJOINの反対側にある必要はありませんが、ビットマップがどちらの側で使用されるかは重要です。
インデックス付き
適切な指標が利用できる場合、状況は異なります。「ランダム」データの分布は、テーブル上に
#BuildInt一意のインデックスを作成できるようになっています。また、テーブルに#Probeは重複が含まれているため、一意でないインデックスを使用する

必要があります。この変更は、HASH JOIN(シリアルとパラレルの両方)には影響しません。HASH JOINはインデックスを使用できないため、計画とパフォーマンスは同じままです。
マージ参加
MERGE JOINは、多対多の結合操作を実行する必要がなくなり、入力に対してソート演算子を必要としなくなりました。
ブロッキングソート演算子がないということは、ビットマップを使用できないことを意味します。
その結果、MAXDOPパラメータに関係なく、シーケンシャルプランが表示され、インデックスを追加する前のパフォーマンスはパラレルプランよりも悪くなります。CPUが702ミリ秒、経過時間が704ミリ秒です。

ただし、元のシーケンシャルMERGE JOINプラン(3105ミリ秒)よりも大幅に改善されています。/ 5632ミリ秒)。これは、並べ替えが不要になり、1対多の結合パフォーマンスが向上するためです。
ネストされたループが参加します
ご想像のとおり、NESTEDLOOPのパフォーマンスは大幅に向上しています。 MERGEと同様に、JOIN、オプティマイザが使用する同時実行しないことを決定した:

これは、これまで最も効率的なプランです-のみ16msのCPUと16msの時間を過ごしましたが。
もちろん、これは、要求を完了するために必要なデータがすでにメモリにあることを前提としています。それ以外の場合、プローブテーブルの各ルックアップはランダムなI / Oを生成します。
NESTED LOOPコールドキャッシュの私のラップトップパフォーマンスでは、78ミリ秒のCPUと2152ミリ秒の経過時間がかかりました。同じ状況下で、MERGEJOINは686ミリ秒のCPUと1471ミリ秒を使用しました。ハッシュ結合-391ミリ秒のCPUと905ミリ秒。
MERGEJOINとHASHJOINは、先読みを使用した大規模な、場合によっては順次のI / Oの恩恵を受けます。
追加リソース
並列ハッシュ結合(Craig Freedman)
クエリ実行ビットマップフィルター(SQL Serverクエリ処理チーム)
Microsoft SQL Server 2000のビットマップ(MSDN記事)
ビットマップフィルターを含む実行計画の解釈(SQL Serverドキュメント)
ハッシュ結合について(SQL Serverドキュメント)
テストスクリプト
USE tempdb;
GO
CREATE TABLE #BuildInt
(
col1 INTEGER NOT NULL
);
GO
CREATE TABLE #Probe
(
col1 INTEGER NOT NULL
);
GO
-- Load 5,000 rows into the build table
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @I INTEGER = 1;
INSERT #BuildInt
(col1)
VALUES
(CONVERT(INTEGER, RAND(1) * 2147483647));
WHILE @I < 5000
BEGIN
INSERT #BuildInt
(col1)
VALUES
(RAND() * 2147483647);
SET @I += 1;
END;
-- Load 5,000,000 rows into the probe table
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @I INTEGER = 1;
INSERT #Probe
(col1)
VALUES
(CONVERT(INTEGER, RAND(2) * 2147483647));
BEGIN TRANSACTION;
WHILE @I < 5000000
BEGIN
INSERT #Probe
(col1)
VALUES
(CONVERT(INTEGER, RAND() * 2147483647));
SET @I += 1;
IF @I % 25 = 0
BEGIN
COMMIT TRANSACTION;
BEGIN TRANSACTION;
END;
END;
COMMIT TRANSACTION;
GO
-- Demos
SET STATISTICS XML OFF;
SET STATISTICS IO, TIME ON;
-- Serial
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #Probe AS p ON
p.col1 = bi.col1
OPTION (MAXDOP 1);
-- Parallel
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #Probe AS p ON
p.col1 = bi.col1
OPTION (MAXDOP 2);
SET STATISTICS IO, TIME OFF;
-- Indexes
CREATE UNIQUE CLUSTERED INDEX cuq ON #BuildInt (col1);
CREATE CLUSTERED INDEX cx ON #Probe (col1);
-- Vary the query hints to explore plan shapes
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #Probe AS p ON
p.col1 = bi.col1
OPTION (MAXDOP 1, MERGE JOIN);
GO
DROP TABLE #BuildInt, #Probe;
続きを読む: