私たちのシステムの原則
「自動」や「詐欺」などの用語を聞くと、機械学習、Apache Spark、Hadoop、Python、Airflow、およびApacheFoundationエコシステムとデータサイエンス分野の他のテクノロジーについて考えている可能性があります。これらのツールの使用には、通常は言及されていない側面が1つあると思います。使用を開始する前に、企業システムに特定の前提条件が必要です。つまり、データレイクとストレージを含むエンタープライズデータプラットフォームが必要です。しかし、そのようなプラットフォームがなくても、このプラクティスを開発する必要がある場合はどうでしょうか。以下で説明する次の原則は、効果的なアイデアを見つけるのではなく、アイデアの改善に集中できるようになるのに役立ちました。ただし、これはプロジェクトの「プラトー」ではありません。技術的および製品的観点から、計画にはまだ多くのことがあります。
原則1:ビジネス価値が最優先
私たちはすべての努力の中心にビジネス価値を置いてきました。一般に、自動分析システムはすべて、高度な自動化と技術的な複雑さを備えた複雑なシステムのグループに属しています。ゼロから作成する場合、完全なソリューションを作成するには長い時間がかかります。次に、ビジネス価値と技術的完全性を優先することにしました。実生活では、これは高度なテクノロジーをドグマとして受け入れないことを意味します。現時点で最適なテクノロジーを選択します。時間の経過とともに、いくつかのモジュールを再実装する必要があるように思われるかもしれません。私たちが受け入れたこの妥協。
原則2:拡張インテリジェンス
機械学習ソリューションの開発に深く関わっていないほとんどの人は、人を置き換えることが目標だと思うかもしれません。実際、機械学習ソリューションは完璧にはほど遠いため、特定の領域でのみ置き換えることができます。不正行為に関するデータの不均衡や、機械学習モデルの機能の完全なリストを提供できないなど、いくつかの理由でこのアイデアを最初から捨てました。対照的に、拡張インテリジェンスオプションを選択しました。これは、AIのサポートの役割に焦点を当てた人工知能の代替概念であり、認知技術は人間の知能を置き換えるのではなく、改善するように設計されているという事実を強調しています。 [1]
これを念頭に置いて、最初から完全な機械学習ソリューションを開発するには、私たちのビジネスの価値の創造を遅らせる多大な労力が必要でした。私たちは、ドメインの専門家の指導の下で、機械学習の側面が繰り返し成長するシステムを構築することを決定しました。このようなシステムを開発する際の注意点は、不正行為であるかどうかだけでなく、アナリストにケースを提供する必要があることです。一般に、顧客の行動の異常は、専門家が何らかの方法で調査して対応する必要がある疑わしいケースです。これらの記録されたケースのごく一部だけが実際に詐欺として分類できます。
原則3:豊富なインテリジェンスプラットフォーム
私たちのシステムの最も難しい部分は、システムワークフローのエンドツーエンドのチェックです。アナリストと開発者は、分析に使用されたすべてのメトリックを含む履歴データセットを簡単に取得できる必要があります。さらに、データプラットフォームは、既存のメトリックのセットに新しいメトリックを追加する簡単な方法を提供する必要があります。私たちが作成するプロセスは、ソフトウェアプロセスだけでなく、前の期間の再計算、新しいメトリックの追加、およびデータ予測の変更を容易にするはずです。これは、本番システムが生成するすべてのデータを蓄積することで実現できます。この場合、データは徐々に障害になります。使用しないデータの増加を保存して保護する必要があります。このようなシナリオでは、時間の経過とともに、データはますます無関係になります。しかし、それでもそれらを管理するための私たちの努力が必要です。私たちにとって、データの蓄積は意味がなく、別のアプローチを取ることにしました。分類するターゲットエンティティを中心にリアルタイムのデータストアを編成し、最新および現在の期間を確認できるデータのみを保存することにしました。この取り組みの課題は、システムが異種であり、複数のデータストアとソフトウェアモジュールがあり、一貫して機能するように注意深く計画する必要があることです。これにより、最新および現在の期間を確認できます。この取り組みの課題は、システムが異種であり、複数のデータストアとソフトウェアモジュールがあり、一貫して機能するように注意深く計画する必要があることです。これにより、最新および現在の期間を確認できます。この取り組みの課題は、システムが異種であり、複数のデータストアとソフトウェアモジュールがあり、一貫して機能するように注意深く計画する必要があることです。
私たちのシステムの建設的な概念
システムには、取り込みシステム、計算、BI分析、追跡システムの4つの主要コンポーネントがあります。それらは特定の分離された目的を果たし、特定の設計アプローチに従うことによってそれらを分離し続けます。
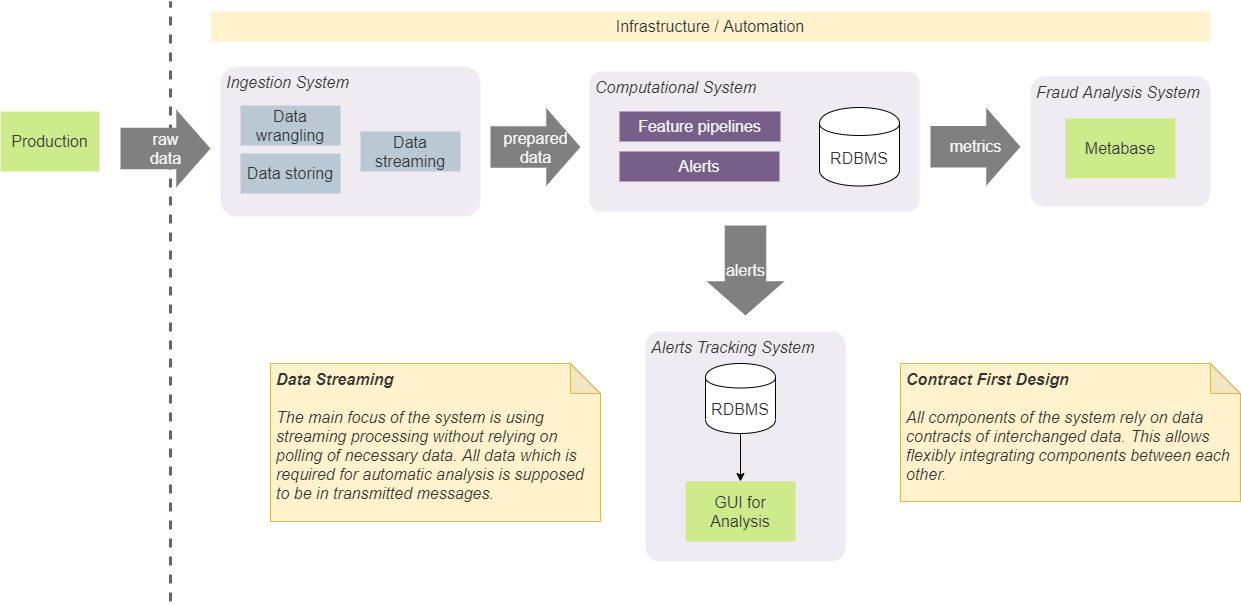
契約ベースの設計
まず、コンポーネントは、コンポーネント間で渡される特定のデータ構造(契約)のみに依存する必要があることに同意しました。これにより、コンポーネント間の統合が容易になり、コンポーネントの特定の構成(および順序)を課す必要がなくなります。たとえば、これにより、受信システムをアラート追跡システムと直接統合できる場合があります。その場合、これは合意された通知契約に従って行われます。これは、他のコンポーネントが使用できる契約を使用して、両方のコンポーネントが統合されることを意味します。入力システムから追跡システムにアラートを追加するための契約を追加することはありません。このアプローチでは、事前に決定された最小数の契約を使用する必要があり、システムと通信が簡素化されます。実際には、「ContractFirstDesign」と呼ばれるアプローチを使用して、ストリーミング契約に適用します。 [2]
システム内の状態を維持および管理すると、必然的にその実装が複雑になります。一般に、状態はどのコンポーネントからでもアクセス可能である必要があり、一貫性があり、すべてのコンポーネントに最新の値を提供し、正しい値で信頼できる必要があります。さらに、最後の状態を取得するために永続ストレージを呼び出すと、I / Oの量が増え、リアルタイムパイプラインで使用されるアルゴリズムが複雑になります。このため、状態ストレージをシステムから可能な限り完全に削除することにしました。このアプローチでは、送信されたデータブロック(メッセージ)に必要なすべてのデータを含める必要があります。たとえば、いくつかの観測の総数(特定の特性を持つ操作またはケースの数)を計算する必要がある場合、それをメモリで計算し、そのような値のストリームを生成します。依存モジュールは、パーティションとバッチを使用してストリームをエンティティに分割し、最新の値で動作します。このアプローチにより、そのようなデータ用に永続的なディスクストレージを用意する必要がなくなりました。私たちのシステムはメッセージブローカーとしてKafkaを使用しており、KSQLを使用してデータベースとして使用できます。 [3]しかし、それを使用すると、私たちのソリューションがKafkaに強く結びつくため、使用しないことにしました。私たちが採用したアプローチにより、内部システムを大幅に変更することなく、Kafkaを別のメッセージブローカーに置き換えることができます。このアプローチにより、そのようなデータ用に永続的なディスクストレージを用意する必要がなくなりました。私たちのシステムはメッセージブローカーとしてKafkaを使用しており、KSQLを使用してデータベースとして使用できます。 [3]しかし、それを使用することは私たちのソリューションをカフカに強く結び付けることになり、私たちはそれを使用しないことに決めました。私たちが採用したアプローチにより、内部システムを大幅に変更することなく、Kafkaを別のメッセージブローカーに置き換えることができます。このアプローチにより、そのようなデータ用に永続的なディスクストレージを用意する必要がなくなりました。私たちのシステムはメッセージブローカーとしてKafkaを使用しており、KSQLを使用してデータベースとして使用できます。 [3]しかし、それを使用することは私たちのソリューションをカフカに強く結び付けることになり、私たちはそれを使用しないことに決めました。私たちが採用したアプローチにより、内部システムを大幅に変更することなく、Kafkaを別のメッセージブローカーに置き換えることができます。
この概念は、ディスクストレージとデータベースを使用しないことを意味するものではありません。システムのパフォーマンスをチェックおよび分析するには、さまざまな指標と状態を表すデータの重要な部分をディスクに保存する必要があります。ここで重要な点は、リアルタイムアルゴリズムはそのようなデータから独立しているということです。ほとんどの場合、保存されたデータは、システムが生成する特定のケースと結果のオフライン分析、デバッグ、追跡に使用されます。
私たちのシステムの問題
一定のレベルまで解決した問題がいくつかありますが、より思慮深い解決策が必要です。それぞれのポイントは別々の記事の価値があるので、今のところ、ここでそれらについて言及したいと思います。
- , , .
- . , .
- IF-ELSE ML. - : «ML — ». , ML, , . , , .
- .
- (true positive) . — , . , , — . , , .
- , .
- : , () .
- 最後だが大事なことは。モデルを分析できる広範なパフォーマンス検証プラットフォームを作成する必要があります。[4]