
かなり奇妙な問題が1つあります。これは、長い間数学の民間伝承に含まれており、インタビューでもお気に入りのテストになっています。その条件は単純であり、解決策はそれ自体を示唆しているように見えますが、結論に急いではいけません。鉛筆と白紙の紙を取り、座ってそれを理解しましょう。
実際、タスクは何ですか
まったくなじみのない街に到着し、そこで最初に出会ったトラムが17番だったと想像してみてください。この街にトラムのルートがいくつあるかをどのように見積もることができますか?
簡単にするために、市内のトラムルートは1からNまでの番号でギャップなしに番号が付けられていると考えてください。最初は、同じ確率でこれらの番号のそれぞれが最初に表示されるトラム番号である可能性があります。
サンクトペテルブルクの数学者の友人であるニコライ・ニコラエヴィッチ・ヴァシリエフから「偶然の路面電車」の問題を初めて聞いた。それから彼は、彼がこの問題を話し、そしてためらうことなく答えを求めた人々の中で、ほとんどの人が番号34、つまり17から「x2」と呼んだという観察を私と共有しました。私の経験では、最も贅沢なのは私の友人の答えでした「メックマット」:17。ほんの一週間後、私は彼が彼の脳の皮質下のどこかで眠っていた可能性最大化の原理に感動したことに気づきました。わかりました。17と34、つまり「x1」と「x2」は素朴で思慮のない答えですが、正解は何ですか。一般に、この問題には1つありますか。
落とし穴とファンタジーの領域
普遍的に正しい答えの存在を疑う価値があるのはなぜですか?このアイデアは、架空ではありますが、いくつかの単純な宇宙を考えると簡単に思い浮かびます。たとえば、地球上のすべての都市に正確に30のトラムルートがあると想像してください。 「30」がこの宇宙で唯一の正解でしょうか?ここで、別の宇宙に地球上に1000の都市があり、そのうち999に30のトラムルートがあり、残りの1つに正確に17のルートがあると想像してください。今回はどちらの答えが正しいでしょうか。また、 30のルートがたくさんありますが、17のルートは1つだけですか?ルートの数を見積もる人は、現在訪れている都市が偶然に地図上で選ばれたかどうかわからないため、ここで確率論的考察を使用することは非常に難しいとすぐに言わなければなりません。または、この選択には何らかの理由があり、誰かの計算があります。
極端な数学的悲観論の原理
述べられた困難にもかかわらず、数学には私たちの問題に答えることができるという原則があり、それは最も奇妙な世界でも意味があります。
ゲームに関しては、この原則は保証された賞金の最大化と呼ばれ、
その本質を理解するために、1つの簡単な例を見てみましょう。
ゲームを想像してみてください。こぶしの1つであなたから密かに小さなオブジェクトを隠し、それを乾いたエンドウ豆にします。次に腕を前に伸ばして、このエンドウ豆がどれにあるかを推測してもらいます。非常に長いゲームをプレイする時間がありますが、最初は私があなたを打ち負かそうとしているのか、故意に屈服しようとしているのか、それともあなたの成功に無関心なのかがわかりません。あなたの目標ができるだけ多くのゲームに勝つことだとしましょう。この場合、どのような戦略に従う必要がありますか?
まず、次の4つの簡単な戦略の長所と短所を分析してみましょう。
- 常に右手を選択してください。
- 右手から始めて、最後にエンドウ豆が見つかった手を選択します。
- , , . «1» «2», , «3», «4», «5» «6» — .
- , . , «», , «» — .
戦略1)を使用することを決定し、同時に私が常に右手にエンドウ豆を隠す場合、すべてのゲームはあなたに有利に終了します。エンドウ豆を右手だけに隠すというパーティー展開のシナリオは、1)に最適だと言えます。ただし、最悪のシナリオでは、エンドウ豆を左手だけに隠すシナリオ、戦略1)では、ゲームの長さに関係なく、1つのゲームに勝つことはできません。
戦略2)は同じ「悪」に苦しんでいることは容易に推測できます。つまり、最悪のシナリオでは、次の各ゲームで左手から始めて交互に手を組むと、どれだけ長くても勝つことができません。私たちのパーティーは続きました。
それでは、リストの3番目に来る戦略に取り掛かりましょう。それを使用すると、エンドウ豆が右手に隠されているすべてのゲームで勝つ可能性は1/3になり、エンドウ豆が左手にあるゲームでは-2/3になります。3)の最悪のシナリオは、右手だけにエンドウ豆を隠す習慣がある場合であることは明らかです。ただし、この場合でも、十分に長いゲームのセットでは、それらの約3分の1が勝利に終わります。もちろん、理論的には運が悪いかもしれませんし、右手を推測することは決してありませんが、実際には、たとえば1000ゲームのゲームでは、勝利数が以下になる可能性はほとんどありません。
 、つまり、
、つまり、  、および100万ゲームのゲームでは、可能な差異の割合はさらに小さくなります。実際、戦略3)を選択することにより、パーティーのゲームの約3分の1があなたと一緒に残ることを保証します。
、および100万ゲームのゲームでは、可能な差異の割合はさらに小さくなります。実際、戦略3)を選択することにより、パーティーのゲームの約3分の1があなたと一緒に残ることを保証します。
リストの4番目の戦略を使用した場合、ゲームは興味深い機能を獲得します。実際、それはあなたにとって重要ではなくなります。今回は、エンドウ豆を右手に隠したり、左手に置いたりします。どちらの状況でも、勝つ可能性は同じであり、正確に50%になります。私がエンドウ豆を隠す場所について概説した一連の手は、あなたにとってパーティーを発展させるための最良のシナリオと最悪のシナリオの両方になるとさえ言えます。いずれにせよ、かなり長いゲームのバッチでは、それらの約半分があなたの勝利で終わるはずであることがわかります。この意味で、戦略4)は、ここですでに検討した他のすべての戦略と比較して、最大の保証を提供します。
保証されたペイオフを最大化する原則は、ゲームのすべての可能な戦略を列挙することを規定します。それぞれについて、最悪のシナリオでペイオフ値を計算し、このペイオフの金額が最大になる最適な戦略を宣言します。エンドウ豆の位置を推測するゲームでは、リストの最良のものだけでなく、最適なものが戦略番号4であることを示すことができます。本質的に、保証された勝利を最大化することは、常に最悪の事態を予想する傾向がある人々の人生の信条に似ていますが、それでもどういうわけか人生における彼らの立場を改善しようとしています。
「ランダムな」トラムの問題は最終的な形を取ります
形式主義
保証された賞金を最大化するという原則を使用するために、運命があなたとゲームをしていると想像してください:それはあなたを未知の宇宙にある未知の都市に何度も送り、そこで最初のトラムに会うまで待ってから、いくらを尋ねますこの街でも同じようにトラムルートしかありません。あなたが名前を付けた数だけが上向きと下向きの両方で本当の数と2倍未満しか異ならない場合、あなたの答えは受け入れ可能であると見なされ、ゲームはあなたに有利に終了すると見なされます。また、これは非常に長いゲームのバッチであり、一生続くと想定します。
今、質問をすることは非常に正当です:「説明されたゲームのどの戦略が、保証された許容可能な答えの最大数を提供できるという意味であなたにとって最適でしょうか?」
最も単純な戦略の詳細な分析
提起された問題との「最初の戦い」として、素朴な戦略「x1」と「x2」がどれほど優れているかを調べてみましょう。
それで、運命は私たちを別のなじみのない都市に投げ込みました。前と同じように、手紙
 この都市のトラムラインの数を示します。条件により、
この都市のトラムラインの数を示します。条件により、 前 等しい確率でルート番号になる可能性があります
前 等しい確率でルート番号になる可能性があります  、その後に最初に見つけたトラムが続きます。
、その後に最初に見つけたトラムが続きます。
戦略「x1」によると
 数のために それ自体である必要があります ..。は明らかです 二度と 、だからそれは判明することはできません もっとだった
数のために それ自体である必要があります ..。は明らかです 二度と 、だからそれは判明することはできません もっとだった  ..。したがって、私たちの見積もりは1つの場合にのみ受け入れられません。、つまり 、未満であることが判明
..。したがって、私たちの見積もりは1つの場合にのみ受け入れられません。、つまり 、未満であることが判明  ..。取得する確率 もっと少なく 奇数で50%を超えない、さらには-それらに等しい。したがって、非常に長いゲームセットで「x1」戦略を使用する場合、運命がどのようなシナリオであっても、行われた見積もりの少なくとも(約)半分が許容できることが保証されます。
..。取得する確率 もっと少なく 奇数で50%を超えない、さらには-それらに等しい。したがって、非常に長いゲームセットで「x1」戦略を使用する場合、運命がどのようなシナリオであっても、行われた見積もりの少なくとも(約)半分が許容できることが保証されます。
ここで、「x2」戦略を使用することにしたとします。この戦略のルールによると、トラムの番号を見ると
、私たちは 番号に名前を付ける  ..。前の場合のように、私たちの見積もりは決して超えません、したがって、その値が以下の場合、1つの条件下でのみ許容できないと見なされます。 ..。同じ時に、 少なくなります 、トラム番号の場合のみ 未満になります
..。前の場合のように、私たちの見積もりは決して超えません、したがって、その値が以下の場合、1つの条件下でのみ許容できないと見なされます。 ..。同じ時に、 少なくなります 、トラム番号の場合のみ 未満になります  ..。のある都市の最後のイベントの確率 4の倍数は
..。のある都市の最後のイベントの確率 4の倍数は  、そして他の都市ではさらに少ない。したがって、「x2」戦略を順守することを決定した場合、それによって、長いゲームのゲームでは、運命がどれほどひどく振る舞っても、すべての回答の少なくとも(約)3/4が受け入れられるという保証が得られます。
、そして他の都市ではさらに少ない。したがって、「x2」戦略を順守することを決定した場合、それによって、長いゲームのゲームでは、運命がどれほどひどく振る舞っても、すべての回答の少なくとも(約)3/4が受け入れられるという保証が得られます。
星へのとげを通して
最適な戦略を探している物語の主要部分に進む前に、私は問題の条件を少し修正し、
、 そして 自然なだけでなく、ゼロより大きい実際の値も取ることができるようになりました。この手順は、離散性に関連する特殊なケースの厄介な警告や退屈な列挙を取り除くために必要です。もちろん、今でも0からπまでのすべての番号のトラムがある都市を想像するのは難しいですが、これはあなたにとって必要ではありません。新しい継続的な変更における私たちの問題は、単純で非常に現実的なモデルです。
誰かが写真フィルムの長いストリップを撮ったと想像してみてください
cmと、宇宙から来る粒子がどのようにその跡を残すかを観察することにしました。実験の規模で、フィルムに当たる粒子の確率密度は、間隔全体にわたる均一な分布によって記述されます。![$ [0、\、N] $](https://habrastorage.org/getpro/habr/formulas/137/03a/73e/13703a73e2267f9a2893efebde9cbfa8.svg) ..。この実験では、実験者が距離を教えてくれますフィルムの左端と最初に登録された粒子が当たった点の間。以前と同様に、許容可能な評価を与える必要があります あなたに知られていないために 、つまり、とは異なる見積もり 上向きと下向きの両方で2回以下。以前のように、運命はあなたとゲームの長いゲームをプレイし、毎回何になるかを決定します別のゲームで。
..。この実験では、実験者が距離を教えてくれますフィルムの左端と最初に登録された粒子が当たった点の間。以前と同様に、許容可能な評価を与える必要があります あなたに知られていないために 、つまり、とは異なる見積もり 上向きと下向きの両方で2回以下。以前のように、運命はあなたとゲームの長いゲームをプレイし、毎回何になるかを決定します別のゲームで。
簡単な演習として、条件が変更されたにもかかわらず、「x1」戦略では約50%が保証され、「x2」ストラテジストでは、どのシナリオの運命が選択されたかに関係なく、それぞれ同じ約75%の許容可能な見積もりが保証されることを示します。
完璧への長い道のり
事前スクリーニング
最後に、すべての準備が完了し、このセクションでは、最適な戦略を探し始めることができます。ただし、簡単にするために、すべての戦略を検討するわけではありませんが、見積もりが行われる戦略に限定します。
次のように想像してください  どこ
どこ  間隔で定義された実数値関数はありますか
間隔で定義された実数値関数はありますか  ..。
..。
ある実験で、粒子の衝突点からフィルムの左端までの距離が次のようになったと想像してください。
 、そして別の実験では-
、そして別の実験では-  、および
、および  ..。それなら、最初の実験で2番目の実験よりもフィルムの長さの推定値を小さくするのは合理的ではないでしょうか。もしそうなら、不平等から 不平等は常に従わなければなりません
..。それなら、最初の実験で2番目の実験よりもフィルムの長さの推定値を小さくするのは合理的ではないでしょうか。もしそうなら、不平等から 不平等は常に従わなければなりません  言い換えれば、関数 厳密に増加している必要があります。価値が「近い」ものについての仮定は、それほど合理的ではありません。 そして 評価
言い換えれば、関数 厳密に増加している必要があります。価値が「近い」ものについての仮定は、それほど合理的ではありません。 そして 評価  そして
そして  また、近い必要があります、つまり、関数 連続している必要があります。
また、近い必要があります、つまり、関数 連続している必要があります。
許容できると考える回答を分析すると、別の
制限があります。
..。問題の理解において、参照してください 次の場合にのみ受け入れ可能(およびその場合のみ)  ..。距離 宇宙の粒子で照らされたスポットと写真フィルムの左端の間は、フィルムの長さを超えることはありません 、これから直接不等式を取得します。
..。距離 宇宙の粒子で照らされたスポットと写真フィルムの左端の間は、フィルムの長さを超えることはありません 、これから直接不等式を取得します。  ..。最後の不平等から、実験者から距離を学ぶことは不合理であるということになります、評価する 数 小さい ..。確かに、見積もりを増やすと 前 、ただし、過度に大きくすることは絶対にありません。 もともと許容できないほど小さかったので、そのような再定義はそれを「修正」することさえできます。したがって、最適な戦略を探す過程で、それらの機能だけを検討するだけで十分です。、すべての値
..。最後の不平等から、実験者から距離を学ぶことは不合理であるということになります、評価する 数 小さい ..。確かに、見積もりを増やすと 前 、ただし、過度に大きくすることは絶対にありません。 もともと許容できないほど小さかったので、そのような再定義はそれを「修正」することさえできます。したがって、最適な戦略を探す過程で、それらの機能だけを検討するだけで十分です。、すべての値  不平等の対象
不平等の対象
 ..。
..。
陛下の公式次
に、保証されたゲインの値を、任意の戦略に対する特定の一般的な分析公式の形式で表現しようとします。
それで、宇宙粒子の登録に関する次の実験では、長さの写真フィルム
、 -最初の粒子の(フィルム)左端からの衝撃点の除去、および  -の見積もり ..。実験を行わなければならない場合、その確率はどのくらいですか に受け入れられます ?最大の価値、それがまだ許容できると考えられる場合、 、最小は ..。
-の見積もり ..。実験を行わなければならない場合、その確率はどのくらいですか に受け入れられます ?最大の価値、それがまだ許容できると考えられる場合、 、最小は ..。
なぜなら
厳密に増加し続けている場合は、逆の関数があります  、これも厳密に増加し続けています。値の場合 どこでも不平等 、値については
、これも厳密に増加し続けています。値の場合 どこでも不平等 、値については  二重の不平等は満たされなければなりません:
二重の不平等は満たされなければなりません:  (図1)
(図1)
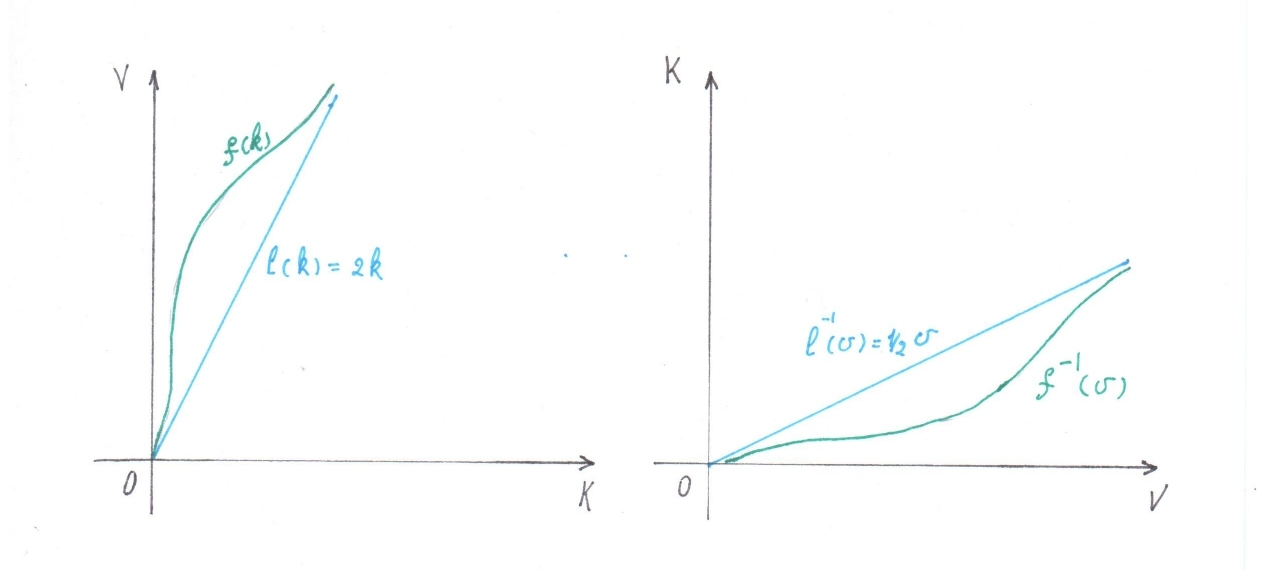
図 1
これで、最大値が簡単にわかります。
それを超えて 許容できないほど大きくなる、  ..。これは、
..。これは、 厳密に増加し、
厳密に増加し、  ..。同様に、最小値それより少ない 許容できないほど小さくなります
..。同様に、最小値それより少ない 許容できないほど小さくなります  ..。最後の2つのステートメントから、次のようになります。 に関連して受け入れられます 距離がある場合(そしてその場合のみ) 露出スポットとフィルムの左端の間は
..。最後の2つのステートメントから、次のようになります。 に関連して受け入れられます 距離がある場合(そしてその場合のみ) 露出スポットとフィルムの左端の間は  そして
そして  ..。最後のイベントの確率、私たちはそれを次のように表します
..。最後のイベントの確率、私たちはそれを次のように表します 、は次の値に等しい:
、は次の値に等しい:

またはより詳細に:

のための最悪のことは明らかなはずです
 シナリオは、そのような一連の実験であり、それぞれの写真フィルムの長さ
シナリオは、そのような一連の実験であり、それぞれの写真フィルムの長さ  値を最小化します ..。したがって、非常に長い一連の実験では、推定によって保証された許容可能な回答の割合、は次の式で与えられます。
値を最小化します ..。したがって、非常に長い一連の実験では、推定によって保証された許容可能な回答の割合、は次の式で与えられます。
![${\rho\left(f\right)={inf}_N[\ p}_{success}(f,\ N)]$](https://habrastorage.org/getpro/habr/formulas/651/948/0e3/6519480e33c57a0c12ad789adf3c4014.svg)
これで、最適な戦略を最大化する必要があると主張できます。
 、 言い換えると、
、 言い換えると、  次の場合にのみ最適になります。
次の場合にのみ最適になります。
![${inf}_N[p_{success}\left(\varphi,\ N\right)]={sup}_f\ {inf}_N[p_{success}\left(f,\ N\right)]$](https://habrastorage.org/getpro/habr/formulas/9b6/0ea/58a/9b60ea58a1fbcb61fcde97c61cbcef85.svg)
したがって、最適な推定値を見つける問題は、関数がどのように見えるかという問題に軽減されました。
表現に届ける ![$(*)\ \ \ \ \ \ inf_N\left[\frac{f^{-1}\left(2N\right)-f^{-1}\left(N/2\right)}{N}\right]$](https://habrastorage.org/getpro/habr/formulas/1ef/1a1/b93/1ef1a1b937eb456e37524750b6f483be.svg)
間隔で 定義されたすべての連続的に強く増加する関数のクラスの最大値
 そのグラフは
そのグラフは  ..。この設定では、タスクが非常に難しいように見える可能性があるというのは本当ではありませんか?これはあなたには予想外に聞こえると思いますが、答えは非常に簡単です。一緒に推測してみましょう。
..。この設定では、タスクが非常に難しいように見える可能性があるというのは本当ではありませんか?これはあなたには予想外に聞こえると思いますが、答えは非常に簡単です。一緒に推測してみましょう。
もっともらしい推論の芸術
おそらく最初に最も簡単なことは、フォームのどの機能を理解することです。
 (ここに
(ここに  -任意の実数≥2)は、式(*)に最大値を与えます。逆に 機能を果たします
-任意の実数≥2)は、式(*)に最大値を与えます。逆に 機能を果たします  、の式に代入します
、の式に代入します  、 我々は持っています:
、 我々は持っています:

ご覧のように、
に依存しません 値が大きいほど小さくなります ..。したがって、関数クラスでは、  式(*)の最大値は、すでに使い慣れている関数によって与えられます。 ..。
式(*)の最大値は、すでに使い慣れている関数によって与えられます。 ..。
距離をセンチメートルではなく、たとえばメートル、インチ、または光年で測定するとどうなるかを考えてみましょう。関数の形式はどのように変化するのでしょうか。
 最適な見積もり?
最適な見積もり?
センチメートルで見積もりましょう
フォームを持っています  、および
、および  そして
そして  -同じ量をメートルで表すと、次のようになります。
-同じ量をメートルで表すと、次のようになります。 
一般的に、長さのスケールを扱います
 と長さのスケール
と長さのスケール  これはから得られます 係数を掛ける
これはから得られます 係数を掛ける  ..。各スコア
..。各スコア スケール単位のように計算できます 、およびスケール単位 ..。なりましょう
スケール単位のように計算できます 、およびスケール単位 ..。なりましょう -スケール単位での表現 、および
-スケール単位での表現 、および  -スケール単位での表現 、次に:
-スケール単位での表現 、次に: 
最後の方程式の形式は、関数が
 そして
そして  おそらく異なる(
おそらく異なる( この場合、それは中立的な意味を持つ実変数です)。
この場合、それは中立的な意味を持つ実変数です)。
私たちと遠い宇宙文明の代表者が、長さの測定単位が異なるという理由だけで、ここで解決されている問題に対して異なる答えを受け取ることはもっともらしいと思いますか?おそらくそうではありません!したがって、それは
 および任意の機能
および任意の機能  表現を最大化する
表現を最大化する  、 関数
、 関数  また、最大化する必要があります ..。突然の場合 唯一の最適です 機能、そしてすべてのために
また、最大化する必要があります ..。突然の場合 唯一の最適です 機能、そしてすべてのために  そして アイデンティティは保持します:
そして アイデンティティは保持します:
 、それによって関数の形を見つけます :
、それによって関数の形を見つけます :
何が起こるかを見てください:私たちの多くの仮定のすべてが正しい場合、最適な機能
関数のクラスに属します 、しかし以前に、指定されたクラス内で式の最大値が 機能を付加します ..。「x2」は最適な戦略ですか?
厳密な結論:x2の最適性
わかりました、関数によって与えられた推定値について多くのヒントがあります
、が最適です。この仮説を厳密に証明し、他に最適な推定値がない条件を確立しましょう。
任意の連続的な厳密に増加する関数を取ります
不平等を満たす  、いくつか修正します
、いくつか修正します  その値の範囲から、最初に値の背後に隠されている幾何学的な意味を見つけようとします
その値の範囲から、最初に値の背後に隠されている幾何学的な意味を見つけようとします  ..。
..。

図:2
関数グラフの場合
 マークポイント
マークポイント  そして
そして  (図2)次に、それらをセグメントに接続し、次にこのセグメントの傾斜角の軸に対する接線
(図2)次に、それらをセグメントに接続し、次にこのセグメントの傾斜角の軸に対する接線  式で表されます
式で表されます 
 から ..。同じ観察結果を少し異なる方法で表現できます。このためには、セグメントが必要です。
から ..。同じ観察結果を少し異なる方法で表現できます。このためには、セグメントが必要です。 いくつかの機能のグラフのように見える
いくつかの機能のグラフのように見える  ..。インターバル内
..。インターバル内 関数 明らかに一定の導関数があり、 等しい
関数 明らかに一定の導関数があり、 等しい  -その大きさのth。
-その大きさのth。
今では、その機能を示すことはもはや難しくありません
勝てない 最大の無限大 つまり、「x2」戦略が最適です。
私は2つの予備的な発言から始めます:
 、 そう
、 そう  つまり、関数のグラフ グラフの上にない
つまり、関数のグラフ グラフの上にない 
- 値値
 に依存しません
に依存しません  と等しい
と等しい  、派生物 すべての点で等しい
、派生物 すべての点で等しい  ..。
..。
後で矛盾するように、最初に次のことを仮定しましょう
厳密に良い  ..。後者は、いくつかある場合にのみ可能です
..。後者は、いくつかある場合にのみ可能です そしてすべてのために 不平等が成り立つ:
そしてすべてのために 不平等が成り立つ:  ..。
..。
いくつかのための
 グラフ上の機能に注意してください ポイントのシーケンス
グラフ上の機能に注意してください ポイントのシーケンス 
 この破線をピースワイズ線形関数のグラフとして解釈します
この破線をピースワイズ線形関数のグラフとして解釈します  ..。順番通りに
..。順番通りに 後続の各値は前の値の4倍であるため、2つの数字が続くごとに、いくつかを見ることができます。
後続の各値は前の値の4倍であるため、2つの数字が続くごとに、いくつかを見ることができます。  そして
そして  ..。後者は、各リンクで
..。後者は、各リンクで 破線 その派生物は少なくとも ..。
破線 その派生物は少なくとも ..。
派生物以来
等しい および派生物 すべての点でもっと 少なくとも 、値に関係なく その時点で  、無制限の倍率で 遅かれ早かれ彼女のスケジュールはスケジュールよりも高くなります ..。(図3)
、無制限の倍率で 遅かれ早かれ彼女のスケジュールはスケジュールよりも高くなります ..。(図3)
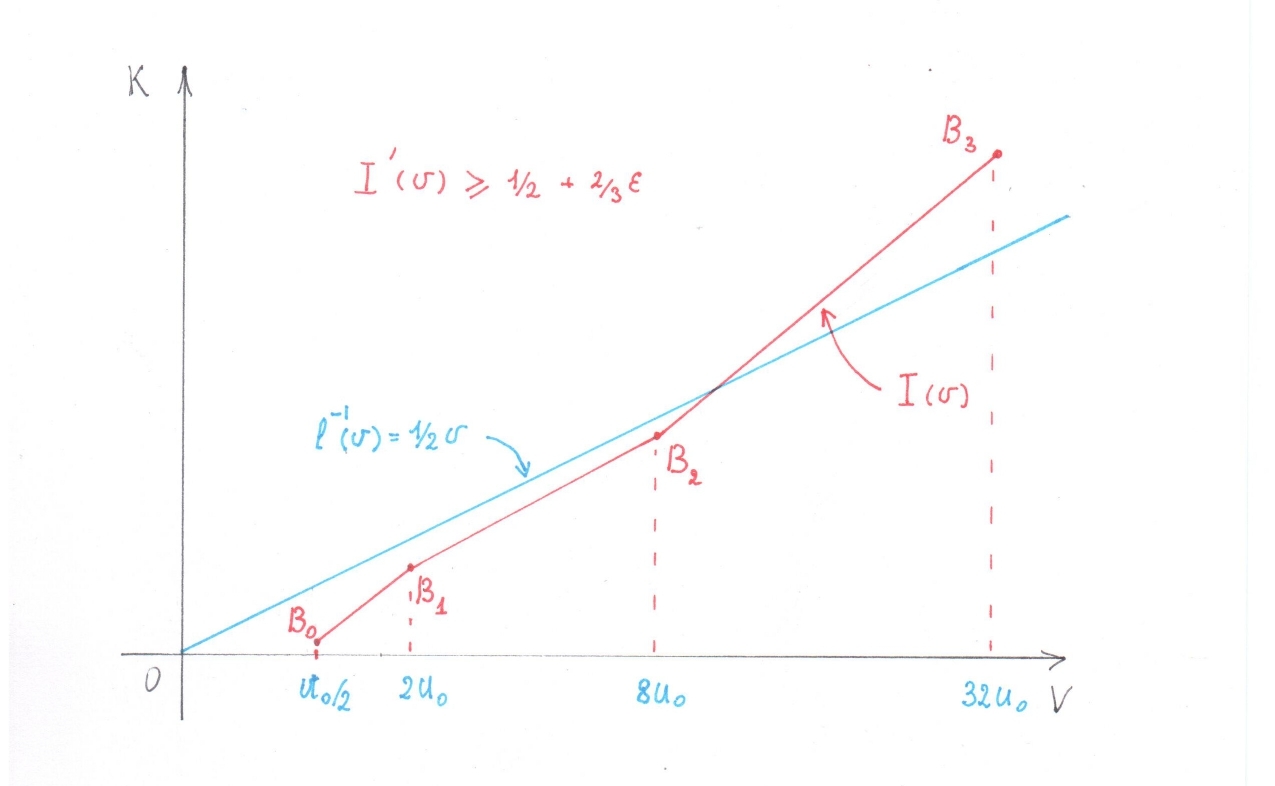
図 3
同時に、ポリラインの頂点を覚えておく必要があります
関数のグラフ上にあります したがって(備考1を参照))それら自体と破線全体がグラフより高くてはなりません ..。結果として生じる矛盾は、 最適です。
最適です。
厳密な結論:一意性
今提示した証明で、軸から無限に離れるのではなく、そのような一連の頂点に沿って破線を作成するとどうなりますか
 、その逆になります-それのために努力します 実際、これは、機能を備えた戦略を除いて、フィルムストリップの寸法が下から制限されていないすべての宇宙で証明することができます、他に最適な戦略はありません。これを見てみましょう。
、その逆になります-それのために努力します 実際、これは、機能を備えた戦略を除いて、フィルムストリップの寸法が下から制限されていないすべての宇宙で証明することができます、他に最適な戦略はありません。これを見てみましょう。
関数があるとしましょう
 、一方では最適であり、他方では
、一方では最適であり、他方では  ..。この場合、関数 と違う 、そして不平等以来
..。この場合、関数 と違う 、そして不平等以来  、次に少なくとも1つの値を見つける必要があります これで 厳密に少なくなります
、次に少なくとも1つの値を見つける必要があります これで 厳密に少なくなります  ..。なりましょう これらの値の1つ ..。上記の行動と同様に、グラフ上で ポイントのシーケンスをマークします
..。なりましょう これらの値の1つ ..。上記の行動と同様に、グラフ上で ポイントのシーケンスをマークします 
(図4)。ここでも、この破線をピースワイズ線形関数として解釈します..。以前とまったく同じ理由で、関数の導関数 各リンクで 以上になります ![$2/3\cdot{inf}_v[p_{success}\left(f,\ v\right)]$](https://habrastorage.org/getpro/habr/formulas/4df/88c/cf3/4df88ccf32bad8793bb0e0870822bb1d.svg) ..。なぜなら が最適です
..。なぜなら が最適です ![${inf}_v[p_{success}\left(f,\ v\right)]$](https://habrastorage.org/getpro/habr/formulas/c6a/1ed/5b1/c6a1ed5b1fd84e9d6567d53a4ff59295.svg) 以上でなければなりません
以上でなければなりません ![${inf}_v[p_{success}\left(l,\ v\right)]=3/4$](https://habrastorage.org/getpro/habr/formulas/d44/f8c/726/d44f8c726f1d067d36152acd4270bccc.svg) ..。最後の2つのステートメントを組み合わせると、関数の派生物が得られます。 どこよりも少ない
..。最後の2つのステートメントを組み合わせると、関数の派生物が得られます。 どこよりも少ない  ..。
..。
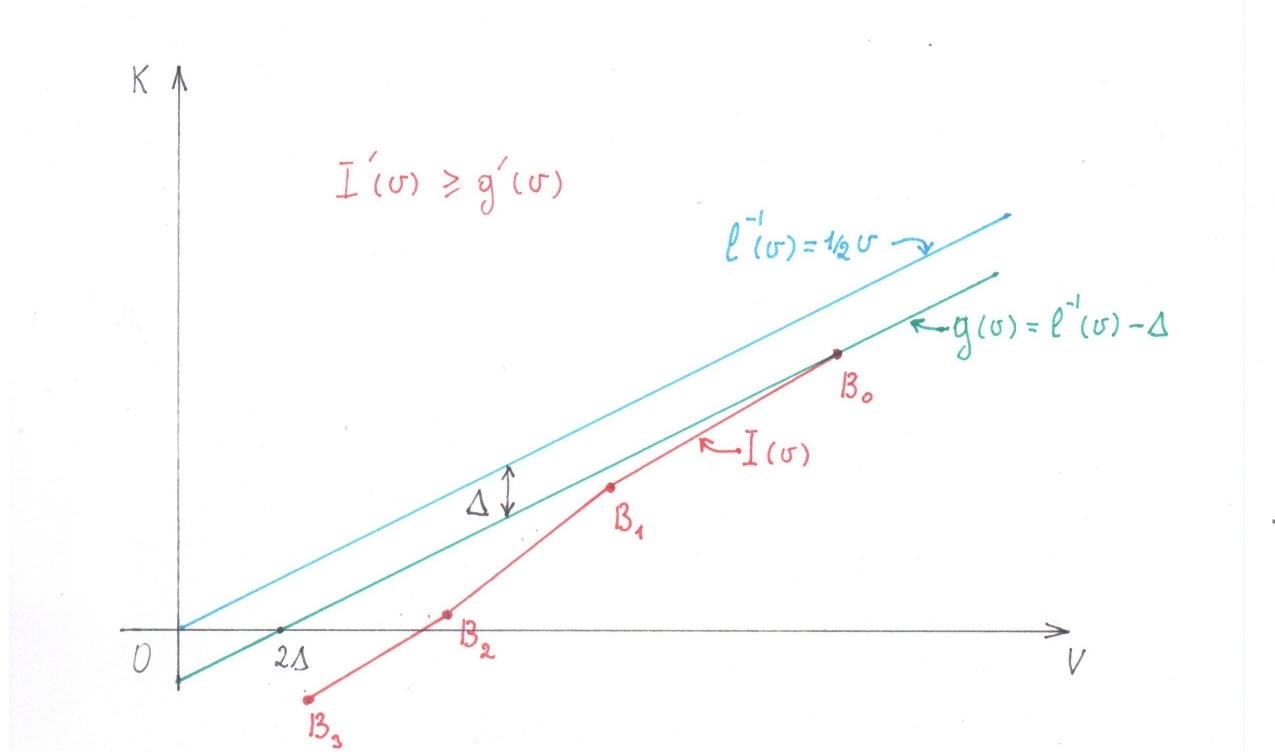
図:4
記号を示しましょう
 差
差  そして別の機能を導入します:
そして別の機能を導入します:  ..。明らかな特性の中で
..。明らかな特性の中で 次の点に注意してください。
次の点に注意してください。
- その時点で 値 関数値と一致します
- 派生物 にもかかわらず 同じで等しい
関数の値がどのように変化するかを見てみましょう。
そして 引数を減らすとき から 前  ..。最初の値 そして は同じ。派生物 間にないポイント
..。最初の値 そして は同じ。派生物 間にないポイント  派生物以上 、したがって、関数の値 値を減らすよりも遅くはない ..。リストされた事実から、間隔全体にわたって
派生物以上 、したがって、関数の値 値を減らすよりも遅くはない ..。リストされた事実から、間隔全体にわたって
 ..。
..。
なぜなら
 、その後、間隔で
、その後、間隔で  意味 負であり、 次に値 また、負である必要があります。同時にトップス 関数グラフのポイントは 、正の値のみを取ることができる関数( ポジティブに対してのみ定義 )、したがって値 負にすることはできません。このようにして得られた矛盾は、、他に最適な見積もりはありません。
意味 負であり、 次に値 また、負である必要があります。同時にトップス 関数グラフのポイントは 、正の値のみを取ることができる関数( ポジティブに対してのみ定義 )、したがって値 負にすることはできません。このようにして得られた矛盾は、、他に最適な見積もりはありません。
ディスカッションの質問
「ランダム粒子」問題の解決策を「ランダムトラム」問題の条件に個別に適合させてみてください。あなたの結果は何ですか?
フィルム
を10センチメートルより短くすることができない宇宙で「ランダム粒子」の問題を解決していると想像してみてください。これらの条件が推定することを示す
それはもはや唯一のものではありませんが、それでも最適です。たとえば、最適なものが見積もりであることを示します ..。他にどのような最適なグレードを見つけましたか?
..。他にどのような最適なグレードを見つけましたか?
対戦相手があなたを倒したくないことがわかっている場合、保証された賞金を最大化する原則について多くの不満があります。たとえば、この原則は、ゲームのパーティーが気象条件に対して、または世界の株式市場に対して「反対」に行われる場合、正当化されるとはほとんど考えられません。これらの場合の戦略の選択のどの原則を代わりに提案できますか、それらのどれが「ランダムトラム」の問題に適用できますか?
ご意見・ご感想をお待ちしております。
セージ・コワレンコ
2020
magnolia@bk.ru