研究パス
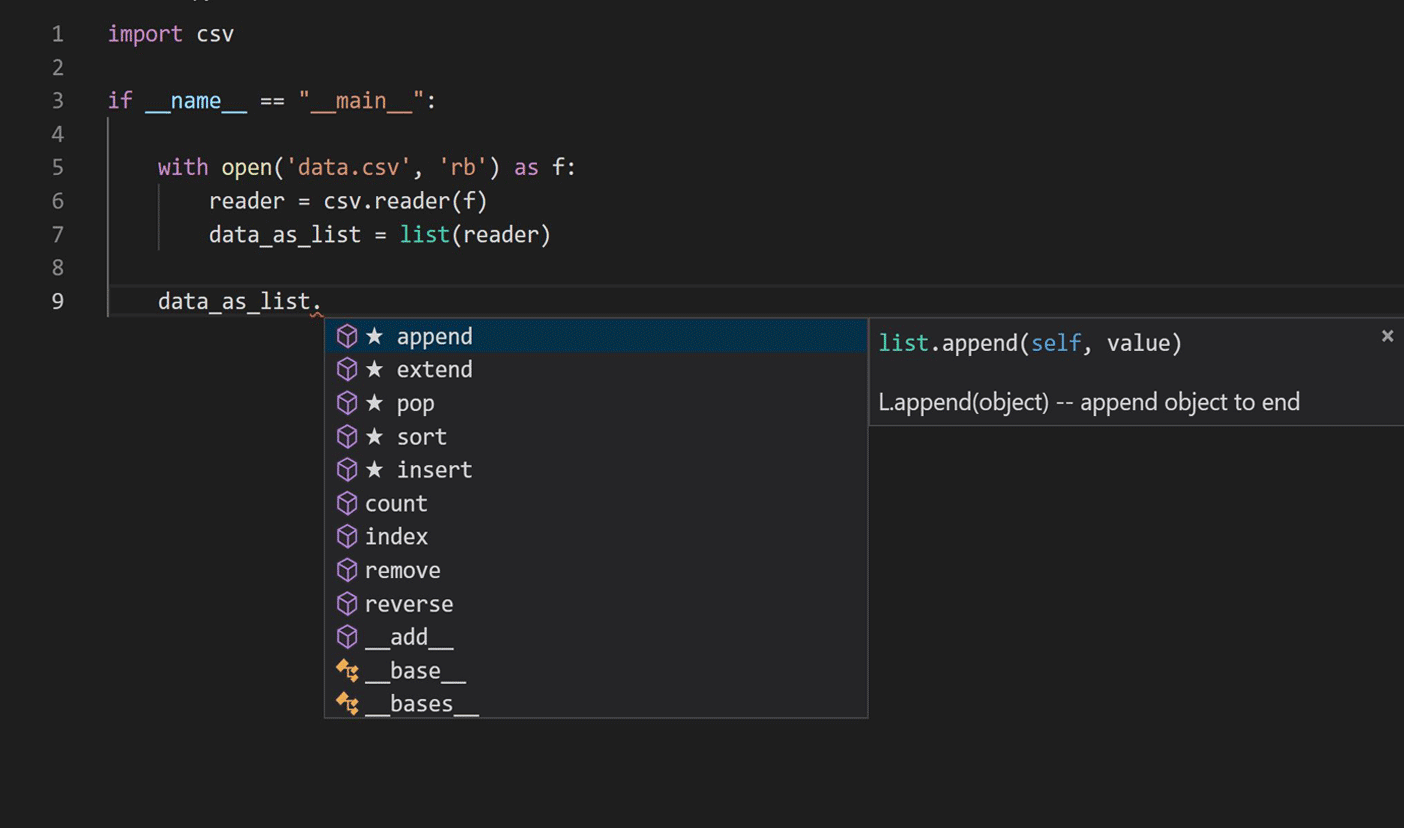
旅は、Pythonコードを学ぶための自然言語処理における言語モデリング技術の応用を研究することから始まりました。次の画像に示すように、現在のIntelliCode完了スクリプトに焦点を当てました。

主なタスクは、フラグメント(メンバー)の呼び出しに先行するコードのフラグメントを考慮に入れて、タイプの最も可能性の高いフラグメント(メンバー)を見つけることです。言い換えると、元のCコードスニペット、ボキャブラリーV、およびすべての可能なメソッドのセットM⊂Vが与えられた場合、次のように定義します。
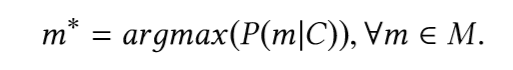
このフラグメントを見つけるには、利用可能なフラグメントの確率を予測できるモデルを構築する必要があります。
リカレントニューラルネットワーク(RNN)に基づく以前の最新のアプローチは、ソースコードのシーケンシャルな性質のみを使用し、プログラミング言語の構文とコードセマンティクスの固有の特性を利用せずに自然な言語技術を伝えようとしました。コード補完の問題の性質により、長期短期メモリ(LSTM)の有望な候補となっています。)。モデルをトレーニングするためのデータを準備するときに、メンバーアクセス式(メンバー)とモジュール関数呼び出しを含むコードスニペットに対応する部分抽象構文ツリー(AST)を使用して、リモートコードによって運ばれるセマンティクスをキャプチャしました。
ディープニューラルネットワークのトレーニングは、リソースを大量に消費するタスクであり、高性能のコンピューティングクラスターが必要です。Horovodの分散並列トレーニングフレームワークをAdamオプティマイザーとともに使用し、各ワーカーにニューラルモデル全体のコピーを保持し、トレーニングデータセットのさまざまなミニバッチを並列に処理しました。Azure MachineLearningを使用しましたモデルトレーニングとハイパーパラメータチューニングでは、GPUオンデマンドクラスターサービスにより、必要に応じてトレーニングを簡単に拡張でき、VMクラスターのプロビジョニングと管理、ジョブのスケジュール設定、結果の収集、障害の処理にも役立ちました。この表は、テストしたアーキテクチャモデルと、それぞれの精度およびモデルサイズを示しています。

モデルサイズが小さく、オフラインモデル評価中に以前の製品モデルよりもモデルの精度が20%向上したため、予測実装製造を選択しました。モデルのサイズは、実稼働環境で重要です。
モデルのアーキテクチャを次の図に示します。

LSTMを本番環境にデプロイするには、モデルの推論速度とメモリフットプリントを改善して、編集中のコード完了要件を満たす必要がありました。メモリバジェットは約50MBで、平均出力速度を50ミリ秒未満に保つ必要がありました。 IntelliCode LSTMはTensorFlowでトレーニングされており、最高のパフォーマンスを得るために推論にONNXランタイムを選択しました。 ONNXランタイムは、人気のある深層学習フレームワークと連携し、Python、C、C ++、C#、Java、JavaScriptなどの多くの言語にまたがるAPIを提供することで、さまざまなサービス環境に簡単に統合できます-.NET Coreと互換性のあるC#APIを使用しましたMicrosoft Python LanguageServerに統合します。
量子化は、低桁の数値の近似による精度の低下が許容できる場合に、モデルサイズを縮小し、パフォーマンスを向上させるための効果的なアプローチです。 ONNXランタイムによって提供されるトレーニング後のINT8量子化により、結果として大幅な改善が見られました。メモリフットプリントと推論時間は、元のモデルと比較して事前に量子化された値の約4分の1に削減され、モデルの精度は3%低下しました。モデルアーキテクチャの設計、ハイパーパラメータの調整、精度、およびパフォーマンスに関する詳細情報は、KDD2019カンファレンスで公開した研究論文に記載されています。
リリースから生産への最終段階は、新しいLSTMモデルを以前の作業モデルと比較するオンラインA / B実験を実施することでした。以下の表のオンラインA / B実験結果は、第1レベルの推奨の精度(完了リストの最初の推奨完了項目の精度)の約25%の改善と、平均逆ランク(MRR)の17%の改善を示し、新しいLSTMモデルが大幅に優れていることを確信しました。前のモデル。

Python開発者:IntelliCodeアドオンを試して、フィードバックを送ってください!
多くのチームの努力のおかげで、Visual StudioCodeのすべてのIntelliCodePythonユーザーへの最初の深層学習モデルの段階的な展開が完了しました。Visual Studio Code用のIntelliCode拡張機能の最新バージョンでは、ONNXランタイムとLSTMも統合して、完全にTypeScriptで記述された新しいPylance拡張機能と連携しました。Python開発者の場合は、IntelliCode拡張機能をインストールして、意見を共有してください。