この問題の解決策を見てみましょう。
「容量による」オブジェクトの配布
興味のない抽象化を掘り下げないために、特定のタスクの例である監視について検討します。提案された方法をあなた自身の特定のタスクに関連付けることができると確信しています。
「同等の」監視オブジェクト
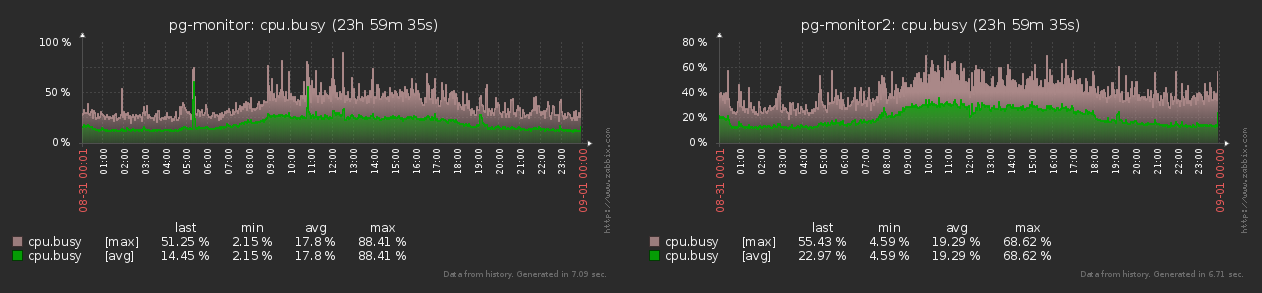
例として、Zabbixのメトリックコレクターがあります。これは、歴史的にPostgreSQLログコレクターと共通のアーキテクチャーを持っています。実際
、各監視オブジェクト(ホスト)は、zabbixに対して、ほぼ安定して、常に同じ頻度で同じメトリックのセットを生成します。
グラフからわかるように、生成されたメトリックの数の最小値と最大値の差は15%を超えません。したがって、すべてのオブジェクトが同じ「オウム」内で等しいと見なすことができます。
オブジェクト間の強い「不均衡」
以前のモデルとは異なり、監視対象のホストはログコレクターにとって均一にはほど遠いです。
たとえば、1つのホストがログに1日あたり100万のプランを生成し、さらに数万のプランを生成できます。そして、計画自体は、量と複雑さの点で、そして時間帯にわたる分布の点で非常に異なります。したがって、負荷が強く「揺れる」ことがわかります。

さて、負荷は大きく変化する可能性があるので、それを管理する方法を学ぶ必要があります...
コーディネーター
コレクターシステムをスケーリングする必要がある ことは明らかです。負荷全体を含む1つの個別のノードがいつか対応しなくなるためです。そしてこのためには、コーディネーター、つまり動物園全体を管理する人が必要です。
次のようになります。

各ワーカーは「オウムで」負荷をかけ、CPUのパーセンテージとして、定期的にマスターをリセットします。そして、これらのデータに基づいて、「アンロードされたワーカー#4に新しいホストを配置する」または「hostAをワーカー#3に転送する必要がある」などのコマンドを発行できます。
ここで、監視オブジェクトとは異なり、コレクター自体はまったく同じ「パワー」を持っていないことも覚えておく必要があります。たとえば、一方には8つのCPUコアがあり、もう一方には4つしかなく、さらに低い周波数です。また、タスクを「均等に」ロードすると、2番目のタスクは「シャットダウン」を開始し、最初のタスクはアイドル状態になります。したがって、それは続きます...
コーディネーターのタスク
実際、タスクは1つだけです。つまり、使用可能なすべてのワーカー間で負荷全体(%cpu単位)を最も均等に分散させることです。それを完全に解決できれば、コレクター全体の%cpu-load分布の均一性が自動的に得られます。
各オブジェクトが同じ負荷を生成したとしても、時間の経過とともに、一部のオブジェクトが「消滅」し、一部の新しいオブジェクトが表示されることは明らかです。したがって、状況全体を動的に管理し、常にバランスを維持できる必要があります。
動的バランシング
単純な問題(zabbix)は非常に簡単に解決できます。
- 「タスク内」の各コレクターの相対容量を計算します
- それらの間ですべてのタスクを比例的に分割します
- 労働者間で均等に分配します

しかし、ログコレクターのように、「非常に等しくない」オブジェクトの場合はどうすればよいでしょうか。
均一性評価
上記では、常に「最大限に均一な分布」という用語を使用しましたが、どちらが「より均一」である2つの分布を正式に比較するにはどうすればよいでしょうか。
数学の均一性を評価するために、標準偏差のようなものが長い間ありました。読むのが面倒な人:
S[X] = sqrt( sum[ ( x - avg[X] ) ^ 2 of X ] / count[X] )以来、労働者の数も、私たちのために異なることがコレクターのそれぞれに、負荷の広がりは、それらの間だけでなく、正規化されるべきも、全体としてのコレクターの間で。
つまり、2つのコレクターのワーカー全体の負荷の分散
[ (10%, 10%, 10%, 10%, 10%, 10%) ; (20%) ]もあまり良くありません。最初のコレクターは10%であり、2番目のコレクターは20%であり、いわば相対的な2倍であるためです。
したがって、「均一性」の一般的な推定のために、単一のメトリック距離を導入します。
d([%wrk], [%col]) = sqrt( S[%wrk] ^ 2 + S[%col] ^ 2 )モデリング
オブジェクトがいくつかある場合は、メトリックが最小になるように、ワーカー間でそれらをブルートフォースで「分解」することができます。しかし、何千ものオブジェクトがあるため、このメソッドは機能しません。しかし、コレクターがオブジェクトをあるワーカーから別のワーカーに「移動」できることはわかっています。勾配降下法を使用してこのオプションをモデル化しましょう。 メトリックの「理想的な」最小値が見つからない可能性があることは明らかですが、ローカルのものは確かです。また、負荷自体は時間の経過とともに大きく変化する可能性があるため、無限に「理想的な」ものを探す必要はまったくありません。
つまり、どのオブジェクトとどのワーカーに「移動」するのが最も効率的かを判断する必要があります。そして、それを簡単な徹底的なモデリングにしましょう:
- ( host, worker)
- host worker' «»
«» . - « »
- d «»
すべてのペアをメトリックの昇順で並べます。理想的には、最初のペアの転送を常に実装する必要があります。これにより、最小のターゲットメトリックが得られます。残念ながら、実際には、転送プロセス自体が「リソースを消費する」ため、特定の「冷却」間隔よりも頻繁に同じオブジェクトに対して実行するべきではありません。
この場合、ターゲットメトリックのみが現在の値に比べて減少する場合は、ランクごとに2番目、3番目、...のペアを取ることができます。
減少する場所がない場合-ここでは極小値です!
写真の例:

「ずっと」反復を開始する必要はまったくありません。たとえば、1分間隔で平均負荷分析を実行し、完了したら1回の転送を実行できます。
マイクロ最適化
複雑なアルゴリズムが
T() x W()あまり良くないことは明らかです。しかし、その中で、時々それをスピードアップすることができるいくつかの多かれ少なかれ明白な最適化を適用することを忘れてはなりません。
ゼロ「オウム」
オブジェクト/タスク/ホストが測定された間隔で「0個」の負荷を生成した場合、それはどこかに移動できるものではなく、考慮して分析する必要さえありません。
自己転送
ペアを生成する場合、オブジェクトがすでに配置されている同じワーカーにオブジェクトを転送する効率を評価する必要はありません。結局のところ、それはすでに
T x (W - 1)-ささいなことですが、素晴らしいです!
識別できない負荷
負荷の転送をモデル化しており、オブジェクトは単なるツールであるため、「同一の」%cpuを転送しようとしても意味がありません。オブジェクトの分布が異なっていても、メトリックの値はまったく同じままです。
つまり、タプルの単一モデル(wrkSrc、wrkDst、%cpu)を評価するだけで十分です。ええと、たとえば、小数点以下1桁まで一致する%cpu値などの「等しい」と見なすことができます。
JavaScriptの実装例
var col = {
'c1' : {
'wrk' : {
'w1' : {
'hst' : {
'h1' : 5
, 'h2' : 1
, 'h3' : 1
}
, 'cpu' : 80.0
}
, 'w2' : {
'hst' : {
'h4' : 1
, 'h5' : 1
, 'h6' : 1
}
, 'cpu' : 20.0
}
}
}
, 'c2' : {
'wrk' : {
'w1' : {
'hst' : {
'h7' : 1
, 'h8' : 2
}
, 'cpu' : 100.0
}
, 'w2' : {
'hst' : {
'h9' : 1
, 'hA' : 1
, 'hB' : 1
}
, 'cpu' : 50.0
}
}
}
};
// ""
let $iv = (obj, fn) => Object.values(obj).forEach(fn);
let $mv = (obj, fn) => Object.values(obj).map(fn);
// initial reparse
for (const [cid, c] of Object.entries(col)) {
$iv(c.wrk, w => {
w.hst = Object.keys(w.hst).reduce((rv, hid) => {
if (typeof w.hst[hid] == 'object') {
rv[hid] = w.hst[hid];
return rv;
}
// ,
if (w.hst[hid]) {
rv[hid] = {'qty' : w.hst[hid]};
}
return rv;
}, {});
});
c.wrk = Object.keys(c.wrk).reduce((rv, wid) => {
// ID -
rv[cid + ':' + wid] = c.wrk[wid];
return rv;
}, {});
}
//
let S = col => {
let wsum = 0
, wavg = 0
, wqty = 0
, csum = 0
, cavg = 0
, cqty = 0;
$iv(col, c => {
$iv(c.wrk, w => {
wsum += w.cpu;
wqty++;
});
csum += c.cpu;
cqty++;
});
wavg = wsum/wqty;
wsum = 0;
cavg = csum/cqty;
csum = 0;
$iv(col, c => {
$iv(c.wrk, w => {
wsum += (w.cpu - wavg) ** 2;
});
csum += (c.cpu - cavg) ** 2;
});
return [Math.sqrt(wsum/wqty), Math.sqrt(csum/cqty)];
};
// -
let distS = S => Math.sqrt(S[0] ** 2 + S[1] ** 2);
//
let iterReOrder = col => {
let qty = 0
, max = 0;
$iv(col, c => {
c.qty = 0;
c.cpu = 0;
$iv(c.wrk, w => {
w.qty = 0;
$iv(w.hst, h => {
w.qty += h.qty;
});
w.max = w.qty * (100/w.cpu);
c.qty += w.qty;
c.cpu += w.cpu;
});
c.cpu = c.cpu/Object.keys(c.wrk).length;
c.max = c.qty * (100/c.cpu);
qty += c.qty;
max += c.max;
});
$iv(col, c => {
c.nrm = c.max/max;
$iv(c.wrk, w => {
$iv(w.hst, h => {
h.cpu = h.qty/w.qty * w.cpu;
h.nrm = h.cpu * c.nrm;
});
});
});
// ""
console.log(S(col), distS(S(col)));
//
let wrk = {};
let hst = {};
for (const [cid, c] of Object.entries(col)) {
for (const [wid, w] of Object.entries(c.wrk)) {
wrk[wid] = {
wid
, cid
, 'wrk' : w
, 'col' : c
};
for (const [hid, h] of Object.entries(w.hst)) {
hst[hid] = {
hid
, wid
, cid
, 'hst' : h
, 'wrk' : w
, 'col' : c
};
}
}
}
// worker
let move = (col, hid, wid) => {
let w = wrk[wid]
, h = hst[hid];
let wsrc = col[h.cid].wrk[h.wid]
, wdst = col[w.cid].wrk[w.wid];
wsrc.cpu -= h.hst.cpu;
wsrc.qty -= h.hst.qty;
wdst.qty += h.hst.qty;
// "" CPU
if (h.cid != w.cid) {
let csrc = col[h.cid]
, cdst = col[w.cid];
csrc.qty -= h.hst.qty;
csrc.cpu -= h.hst.cpu/Object.keys(csrc.wrk).length;
wsrc.hst[hid].cpu = h.hst.cpu * csrc.nrm/cdst.nrm;
cdst.qty += h.hst.qty;
cdst.cpu += h.hst.cpu/Object.keys(cdst.wrk).length;
}
wdst.cpu += wsrc.hst[hid].cpu;
wdst.hst[hid] = wsrc.hst[hid];
delete wsrc.hst[hid];
};
// (host, worker)
let moveCheck = (orig, hid, wid) => {
let w = wrk[wid]
, h = hst[hid];
// -
if (h.wid == w.wid) {
return;
}
let col = JSON.parse(JSON.stringify(orig));
move(col, hid, wid);
return S(col);
};
// (hsrc,hdst,%cpu)
let checked = {};
// ( -> )
let moveRanker = col => {
let currS = S(col);
let order = [];
for (hid in hst) {
for (wid in wrk) {
// ( 0.1%) ""
let widsrc = hst[hid].wid;
let idx = widsrc + '|' + wid + '|' + hst[hid].hst.cpu.toFixed(1);
if (idx in checked) {
continue;
}
let _S = moveCheck(col, hid, wid);
if (_S === undefined) {
_S = currS;
}
checked[idx] = {
hid
, wid
, S : _S
};
order.push(checked[idx]);
}
}
order.sort((x, y) => distS(x.S) - distS(y.S));
return order;
};
let currS = S(col);
let order = moveRanker(col);
let opt = order[0];
console.log('best move', opt);
//
if (distS(opt.S) < distS(currS)) {
console.log('move!', opt.hid, opt.wid);
move(col, opt.hid, opt.wid);
console.log('after move', JSON.parse(JSON.stringify(col)));
return true;
}
else {
console.log('none!');
}
return false;
};
// -
while(iterReOrder(col));その結果、私たちの貯水池への負荷は、各瞬間にほぼ均等に分散され、出現するピークを即座に平準化します。