Pythonはかなり高レベルのプログラミングツールであり、十分に開発されたインフラストラクチャを備えており、データ分析と機械学習の分野で実績があるため、Pythonを使用して自然言語でテキストを処理すると便利です。 PythonでNLPの問題を解決するために、コミュニティによっていくつかのライブラリとフレームワークが開発されました。私たちの仕事では、PythonスクリプトJupyter Notebookを開発するためのインタラクティブなWebツール、テキスト分析のためのNLTKライブラリ、およびワードクラウドを構築するためのwordcloudライブラリを使用します。
ネットワークにはテキスト分析のトピックに関するかなりの量の資料が含まれていますが、多くの記事(ロシア語の記事を含む)では、英語でテキストを分析することが提案されています。ロシア語のテキストの分析には、NLPツールの使用に関するいくつかの詳細があります。例として、A。プーシキンによるストーリー「スノーストーム」のテキストの頻度分析を考えてみましょう。
周波数分析は、大きくいくつかの段階に分けることができます。
- データの読み込みと閲覧
- テキストのクリーニングと前処理
- ストップワードを削除する
- 単語を基本的な形に翻訳する
- テキスト内の単語の出現の統計を計算する
- 単語の人気のクラウド視覚化
スクリプトは、github.com / Metafiz / nlp - course - 20 / blob / master / Frequency - analisys - of - text.ipynb、ソース-github.com/Metafiz/nlp-course-20/blob/master/pushkinで入手できます。-metel.txt
データのロード
open組み込み関数を使用してファイルを開き、読み取りモードとエンコーディングを指定します。ファイルの内容全体を読み取り、その結果、文字列テキストを取得します。
f = open('pushkin-metel.txt', "r", encoding="utf-8")
text = f.read()
テキストの長さ(文字数)は、標準のlen関数を使用して取得できます。
len(text)
pythonの文字列は文字のリストとして表すことができるため、文字列を操作するためにインデックスアクセスとスライス操作も可能です。たとえば、テキストの最初の300文字を表示するには、次のコマンドを実行するだけです。
text[:300]
テキストの前処理(前処理)
頻度分析を実行し、テキストの主題を決定するには、句読点、余分な空白文字、および数字からテキストをクリアすることをお勧めします。これは、組み込みの文字列関数を使用する、正規の式を使用する、リスト処理を使用するなど、さまざまな方法で実行できます。
まず、文字を1つの大文字小文字に変換してみましょう。
text = text.lower()
文字列モジュールの標準の句読点文字セットを使用します。
import string
print(string.punctuation)
string.punctuationは文字列です。テキストから削除する特殊文字のセットを展開できます。ソーステキストを分析し、削除する必要のある文字を特定する必要があります。ソーステキストにある改行、タブ、その他の記号を句読点に追加しましょう(たとえば、コード\ xa0の文字)。
spec_chars = string.punctuation + '\n\xa0«»\t—…'
文字を削除するには、文字列の要素ごとの処理を使用します。元のテキスト文字列を文字に分割し、spec_charsセットにない文字のみを残して、文字のリストを再び文字列に結合します。
text = "".join([ch for ch in text if ch not in spec_chars])
指定した文字セットをソーステキストから削除する単純な関数を宣言できます。
def remove_chars_from_text(text, chars):
return "".join([ch for ch in text if ch not in chars])
特殊文字の削除と元のテキストからの数字の削除の両方に使用できます。
text = remove_chars_from_text(text, spec_chars)
text = remove_chars_from_text(text, string.digits)
テキストのトークン化
さらに処理するには、クリアされたテキストをその構成要素であるトークンに分割する必要があります。自然言語のテキスト分析では、記号、単語、文の内訳を使用します。パーティショニングプロセスはトークン化と呼ばれます。周波数分析のタスクでは、テキストを単語に分割する必要があります。これを行うには、NLTKライブラリの既製のメソッドを使用できます。
from nltk import word_tokenize
text_tokens = word_tokenize(text)
変数text_tokensは、単語(トークン)のリストです。前処理されたテキストの単語数を計算するには、トークンリストの長さを取得できます。
len(text_tokens)
最初の10ワードを表示するには、スライス操作を使用します。
text_tokens[:10]
NLTKライブラリの周波数分析ツールを使用するには、トークンのリストをこのライブラリに含まれているTextクラスに変換する必要があります。
import nltk
text = nltk.Text(text_tokens)
変数テキストのタイプを推測してみましょう。
print(type(text))
スライス操作は、このタイプの変数にも適用できます。たとえば、このアクションはテキストから最初の10個のトークンを出力します。
text[:10]
テキスト内の単語の出現の統計を計算する
FreqDist(頻度分布)クラスは、テキスト内の単語頻度分布の統計を計算するために使用されます。
from nltk.probability import FreqDist
fdist = FreqDist(text)
fdist変数を表示しようとすると、トークンとその頻度(これらの単語がテキストに表示される回数)を含む辞書が表示されます。
FreqDist({'': 146, '': 101, '': 69, '': 54, '': 44, '': 42, '': 39, '': 39, '': 31, '': 27, ...})
most_commonメソッドを使用して、最も一般的なトークンを持つタプルのリストを取得することもできます。
fdist.most_common(5)
[('', 146), ('', 101), ('', 69), ('', 54), ('', 44)]
テキスト内の単語の分布の頻度は、グラフを使用して視覚化できます。FreqDistクラスには、そのようなプロットをプロットするための組み込みのプロットメソッドが含まれています。トークンの数を示す必要があり、その頻度はチャートに表示されます。パラメータcumulative = Falseの場合、グラフはZipfの法則を示しています。十分に長いテキストのすべての単語が使用頻度の降順で並べられている場合、そのようなリストのn番目の単語の頻度はその順序番号nにほぼ反比例します。
fdist.plot(30,cumulative=False)
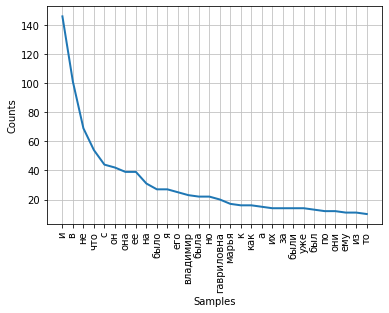
現時点では、最高周波数には、意味的負荷を持たず、単語間の意味的構文関係のみを表現する結合、前置詞、およびその他のサービス部分が含まれていることに注意してください。頻度分析の結果がテキストの主題を反映するためには、これらの単語をテキストから削除する必要があります。
ストップワードを削除する
ストップワード(またはノイズワード)には、原則として、前置詞、結合、間投、粒子、およびテキストによく見られるその他の音声部分が含まれ、サービスのものであり、意味的な負荷をかけません-それらは冗長です。
NLTKライブラリには、さまざまな言語用の既製のストップワードリストが含まれています。ロシア語の100語のリストを取得しましょう。
from nltk.corpus import stopwords
russian_stopwords = stopwords.words("russian")
ストップワードは状況に応じて変化することに注意してください。トピックが異なるテキストの場合、ストップワードは異なる場合があります。特殊文字の場合と同様に、ソーステキストを分析し、標準セットに含まれていないストップワードを特定する必要があります。
ストップワードリストは、標準の拡張方法を使用して拡張できます。
russian_stopwords.extend(['', ''])
ストップワードを削除した後、テキスト内のトークンの配布頻度は次のようになります。
fdist_sw.most_common(10)
[('', 23),
('', 20),
('', 17),
('', 9),
('', 9),
('', 8),
('', 7),
('', 6),
('', 6),
('', 6)]
ご覧のとおり、周波数分析の結果はより有益になり、テキストのメイントピックをより正確に反映しています。ただし、結果には、「vladimir」や「vladimira」などのトークンが表示されます。これらは、実際には1つの単語ですが、形式が異なります。この状況を修正するには、ソーステキストの単語をベースまたは元の形式に持っていく必要があります-ステミングまたはレンマ化を実行します。
単語の人気のクラウド視覚化
作業の最後に、テキストの頻度分析の結果を「ワードクラウド」の形式で視覚化します。
このためには、wordcloudライブラリとmatplotlibライブラリが必要です。
from wordcloud import WordCloud
import matplotlib.pyplot as plt
%matplotlib inline
ワードクラウドを構築するには、文字列を入力としてメソッドに渡す必要があります。ストップワードを前処理して削除した後にトークンのリストを変換するには、joinメソッドを使用して、区切り文字としてスペースを指定します。
text_raw = " ".join(text)
クラウドを構築するためのメソッドを呼び出しましょう。
wordcloud = WordCloud().generate(text_raw)
その結果、私たちのテキストにはそのような「ワードクラウド」

が得られます:それを見ると、作品の主題と主人公の一般的なアイデアを得ることができます。